HBase(1) 分布式、可扩展的 NoSQL 数据库
概述
以 hdfs 为数据存储的,一种分布式、可扩展的 NoSQL 数据库
数据模型:
基于 Bigtable
是一个稀疏的、分布式的、持久的多维排序 map(NoSQL、数据持久化)
表中的数据通过一个行关键字(Row Key)、一个列关键字(Column Key)以及一个时间戳(Time Stamp)进行索引,存储逻辑为(row:string, column:string, time:int64)→string(序列化的字符串)
行关键字可以是任意的字符串,表中数据根据行关键字排序(字典序),其中存储网站
www.baidu.com的存储格式为com.baidu.com,此时同一域名下的内容,可以更加快速的索引column:组织成列族,族同时也是 Bigtable 中访问控制的基本单元
时间戳:不同的数据版本通过时间戳来区分
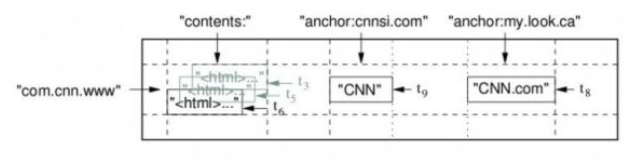
上图为一个例子,Webtable 存储了大量的网页和相关信息
HBase 使用与 Bigtable 相似的数据模型
- 用户将数据行存储在带标签的表中
- 数据行具有可排序的键和任意数量的列
- map指代key-value结构
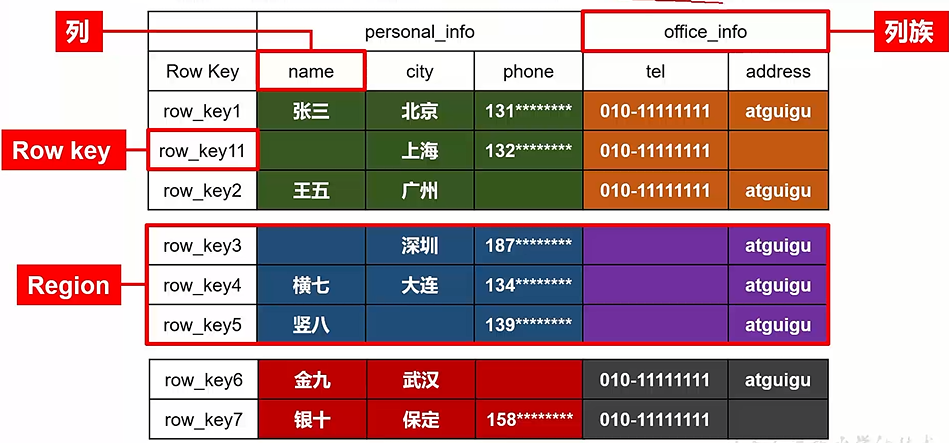
HBase逻辑结构如下(以存储一个json为例,json中每个项的key可能存在差异),按照rowkey字典序排列,不同的行具有不同的列,部分位置没有值(稀疏),数据可以按行拆分成块(称为region,存储到不同的节点),按列拆分成store,用于存储到不同的文件夹
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25{
"row_key1":{
"personal_info":{
"name":"zhangsan",
"city":"北京",
"phone":"131********"
},
"office_info":{
"tel":"010-1111111",
"address":"atguigu"
}
},
"row_key11":{
"personal_info":{
"city":"上海",
"phone":"132********"
},
"office_info":{
"tel":"010-1111111"
}
},
"row_key2":{
......
}
}
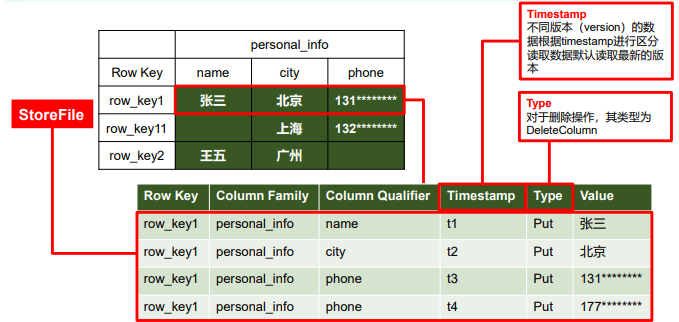
HBase物理存储:
通过key-value形式存储
key为rowkey+列族+列名+时间戳+Type(写入、删除等)
- hdfs无法修改数据,因此HBase通过时间戳区分不同版本,实现数据修改功能,例如下图的最后两列,t3和t4
- hdfs的数据不好随机删除,因此通过type和时间戳实现删除操作(比对时间戳和操作类型,得到操作顺序)
value即为数据值
数据模型:
- Namespace:类似SQL中database的概念
- 每个命名空间下有多个表
- HBase自带两个命名空间
- hbase:存放 HBase 内置的表
- default:用户默认使用的命名空间
- Table:
- HBase 定义表时只需声明列族,不声明具体的列
- 往 HBase 写入数据时,字段(具体的列)可以动态、按需指定
- Row:
- HBase 表中每行数据由一个 RowKey 和多个 Column 组成
- 查询数据时只能根据 RowKey 检索
- Column:
- HBase 中的每个列由 Column Family(列族)和 Column Qualifier(列限定符)限定,例如
info:name,info:age - 建表只需指明列族
- HBase 中的每个列由 Column Family(列族)和 Column Qualifier(列限定符)限定,例如
- Time Stamp:
- 标识数据的不同版本(version)
- 每条数据写入时,系统自动为其加上该字段,值为写入 HBase 的时间
- Cell:
- 由
{rowkey, column Family:column Qualifier, timestamp}唯一确定的单元 - cell 中数据以序列化的字节码形式存贮
- 由
- Namespace:类似SQL中database的概念
基本架构(假设存储两个表)
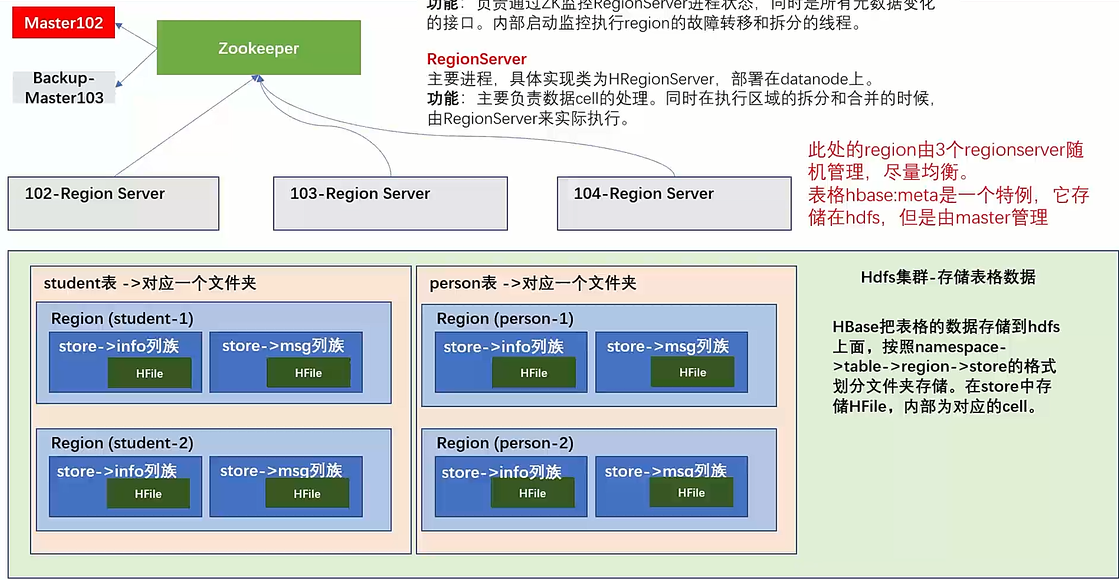 * Master:一个进程,通过zk实现分布式管理(部署在namenode上),具体实现类为HMaster
* Master:一个进程,通过zk实现分布式管理(部署在namenode上),具体实现类为HMaster
- 备用master,解决单点故障问题实现高可用
- 均衡region server
- 表格hbase:meta(元数据表)在hdfs中存储,但由master管理,接收用户对表格创建修改删除的命令并执行
- 通过 zk 监控 region 状态,看 region 是否需要进行负载均衡,故障转移和 region 的拆分
- 多个后台监控线程
- LoadBalancer 负载均衡器
- 周期性监控 region 的分布在 regionServer 上面是否均衡
- 参数 hbase.balancer.period 控制周期时间,默认5min
- CatalogJanitor 元数据管理器:定期检查和清理 hbase:meta 表中的数据(hbase是一个命名空间,见上文)
- MasterProcWAL master 预写日志处理器:master 需要执行的任务记录到预写日志 WAL 中,master故障时由 backupMaster 读取以继续完成任务
- LoadBalancer 负载均衡器
Region Server:一个进程,具体实现类为HRegionServer,将自己的进程信息注册到zk,master读取注册信息进行管理(部署在datanode上)
管理具体的数据,服务读和写操作,即,当用户通过client访问数据时,client会和HBase RegionServer 进行直接通信
负责数据 cell 的处理
拆分合并 region 的实际执行者(master 监控,regionServer 执行)
region server同样是一个服务,数据不存储在region server
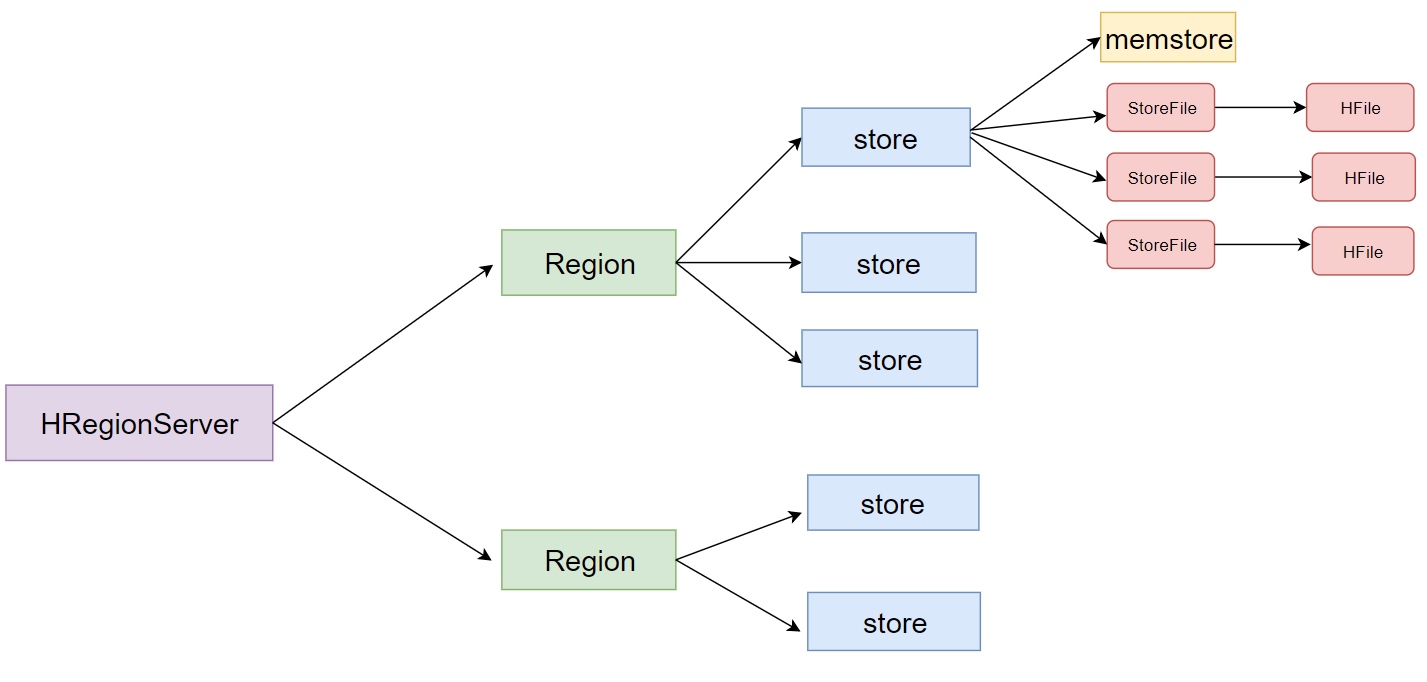
hdfs:存储数据
- 表格被切分为不同的region,再根据列族切分为store,划分出不同的文件夹,文件夹中存储HFile,即存储相应store的cell(建表时可以直接声明出来)
- DataNode存储Region Server所管理的数据
- NameNode维护所有物理数据块的metadata
zookeeper:维持整个集群的存活,保障故障自动转移
HMaster扮演了协调者的角色,Zookeeper扮演了中介的角色,而RegionServer则是HBase实际的工作者。在这样的M-Z-S(Master-Zookeeper-Slaves)体系架构下,HMaster并不真正响应客户端的读写请求,所以正常情况下实际负载并不很高
组件的协调过程:
- 多个HMaster竞争成为zookeeper上的临时节点,zookeeper将第一个创建成功的HMaster作为唯一当前active的HMaster,其他HMater进入stand by的状态。active的HMaster不断发送heartbeat给zk,stand by状态的HMaster节点监听active HMaster的故障信息。active HMaster宕机,会重新竞争新的active HMaster
- 每个region server会创建一个ephemeral node。HMaster监视这些节点来确认region server是可用的
- 如果一个region server或者active的HMaster没有发送heatbeat给zk,和zk之间的会话将会过期,zk上会删掉这个临时节点,认为这个节点发生故障,其他监听者节点会收到这个故障节点被删除的消息
- actvie的HMaster如果发现某个region server下线,会重新分配region server来恢复相应的region数据
- stand by的HMaster节点如果发现active的HMaster节点下,则会竞争上线
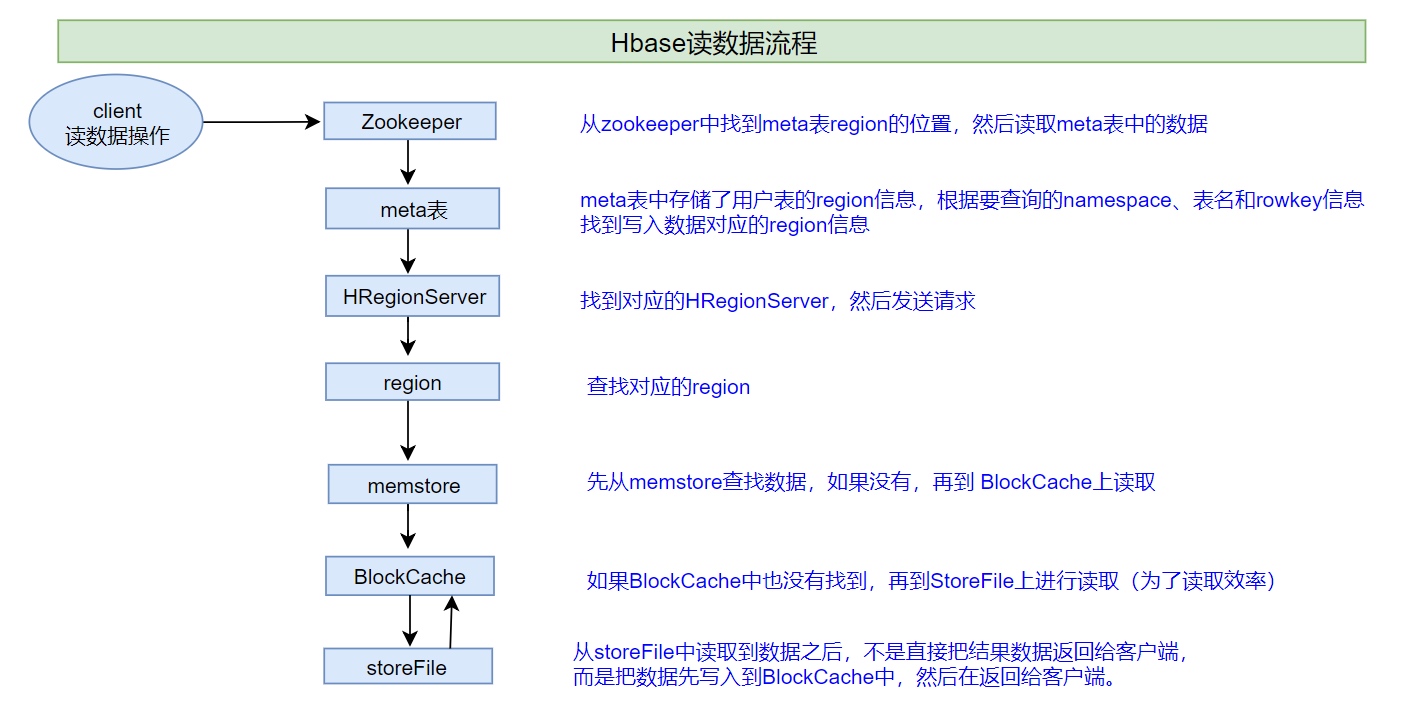
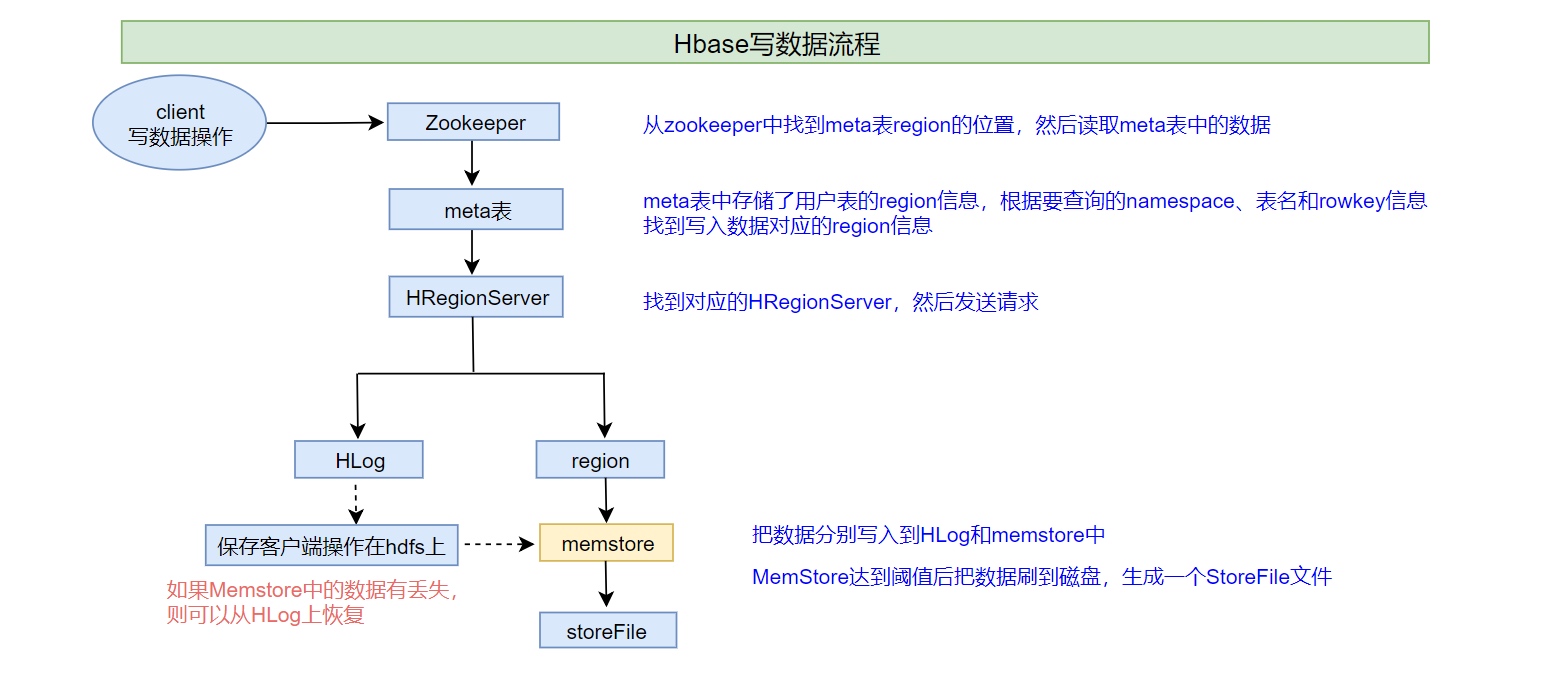
用户访问HBase
第一次访问
- 客户端从zk获取保存meta table的位置信息,并缓存这个位置信息
- 客户端查询这个保存meta table的server(应该是master,因为master保存了hbase:meta),获取要访问的row key所在的region在哪个region server上
- 客户端与负责row所在region的Region Server通信,实现对该行的读写操作
未来的读写中,客户端会根据缓存寻找相应的Region server地址。除非该Region server不再可达,这时客户端会重新访问META table并更新缓存
Shell与API
Shell
help(help 'get',获取get命令的使用说明)Namespace
- 创建:
create_namespace 'a' - 查看:
list_namespace
- 创建:
DDL(Data Definition Language)
- 建表:
- 创建表student,两个列族info和msg,info维护的版本数为5,msg维护的版本数为1:
create 'a:student', {NAME => 'info', VERSIONS => 5}, {NAME => 'msg'} - 若不指定命名空间,则默认为default;若只有一个列族,则简写:
create 'student','info'
- 创建表student,两个列族info和msg,info维护的版本数为5,msg维护的版本数为1:
- 查看表:
list、describe 'student' - 修改表:
- 增加列族和修改信息,使用覆盖的方式:
alter 'student', {NAME => 'f1', VERSIONS => 3},增加一个列族f1,维护版本数为3alter 'student', NAME => 'info', VERSIONS => 3:修改表student的列族info的维护版本数为3
- 删除(两个方式):
alter 'student', 'delete' => 'f1':删除列族f1alter 'student', NAME => 'f1', METHOD => 'delete':删除列族f1
- 增加列族和修改信息,使用覆盖的方式:
- 删除表:
- 先设置为不可用:
disable 'student' - 再删除:
drop 'student'
- 先设置为不可用:
- 建表:
DML(Data Manipulation Language)
- 写入数据:只能添加cell
put 'a:student','1001','info:age','18'——1001为rowkey,info:age为列族:列名- 如果重复写入相同的rowkey、相同列的数据,则会写入多个版本进行覆盖
- 读取数据
- get:最大范围为一行数据,可以进行列的过滤
get 'a:student','1001' , {COLUMN => ['info:name', 'info:age']},获得这一行info列族name列名的数据,返回多个cell- 读取多个版本的cell:
get 'a:student','1001' , {COLUMN => 'info:name', VERSIONS => 6}
- scan:
scan 'a:student', {STARTROW => '1001',STOPROW => '1002'},左闭右开,显示最新版本的cell
- get:最大范围为一行数据,可以进行列的过滤
- 删除数据
- delete:删除一个版本的数据,即 1 个 cell,不填写版本默认删除最新的一个版本:
delete 'a:student','1001','info:name' - deleteall:删除所有版本的数据,即为当前行当前列的多个 cell
- 数据删除时,不会将数据彻底删除,而是对数据打标记。在特定时期清理磁盘时彻底删除
- delete:删除一个版本的数据,即 1 个 cell,不填写版本默认删除最新的一个版本:
- 写入数据:只能添加cell
API
具体代码见GitHub
连接
HBase 的客户端连接由 ConnectionFactory 类创建,用户使用完成后需要手动关闭连接(
.close())推荐一个进程使用一个连接(连接较重)
对 HBase 的命令通过类的属性 Admin 和 Table 实现
- Admin:对元数据的操作(修改表格)
- Table:对表格数据的操作
由hadoop.conf.Configuration的对象作为构造方法的参数
默认使用同步连接
连接是线程安全的,但Table和Admin不是线程安全的,每个线程需要创建自己的Table和Admin对象——需要使用类单例模式,确保使用一个连接,该连接可以同时用于多个线程(使用static)
1
2
3
4
5
6
7
8
9
10
11public static Connection connection = null;
static {
// 创建 hbase 的连接
try {
// 使用配置文件的方法来传入参数(源码会读取一个名为hbase-site.xml的文件,文件放在resources目录下)
connection = ConnectionFactory.createConnection();
} catch (IOException e) {
System.out.println("连接获取失败");
e.printStackTrace();
}
}
DDL
admin和table不是线程安全的,因此不能池化或缓存,需要用到时实例化一个admin对象,用完直接close,例如:
1
2
3
4
5public void createNamespace(String namespace) throws IOException {
Admin admin = connection.getAdmin();
// ...
admin.close();
}新建的基本过程为,获取admin,创建DescriptorBuilder,创建Descriptor,关闭admin
修改的基本过程为,获取admin,获取旧的descriptor,获取旧的DescriptorBuilder,修改DescriptorBuilder,写回,关闭admin
具体代码见github
DML
- 一般过程为,获得table,实例化操作,添加操作参数,执行操作,关闭table
- 具体代码见gitHub

