《Password Cracking Using Probabilistic Context-Free Grammars》论文阅读记录
摘要
- 讨论了一种以最高概率顺序生成密码结构的新方法
- 基于先前公开的密码训练集自动创建概率上下文无关语法
- 根据语法生成单词篡改规则,并从中猜测密码
- 本文方法能够破解的密码比 JTR 多28%到129%
介绍
- 为了估计密码猜测攻击的风险,有人建议管理员主动尝试破解其系统中的密码【4】——准确性取决于能否近似对手可用的最有效工具
- 本文的方法是概率性的,并且结合了关于用户密码概率分布的可用信息,这些信息用于生成密码结构——结构可以是猜测密码本身,也可以是之后用字典单词填充的单词管理模板
- 先用一组公开的密码训练,之后在一组不同的公开密码上测试
- 与 JTR【11】进行了比较,本文方法能够多破解28%到129%的密码。其他实验也显示了类似的结果
背景
- 在离线密码恢复中,攻击者通常只拥有原始密码的散列
- 攻击者猜测原始密码的值,使用适当的密码散列算法对猜测进行哈希,并比较两个散列。匹配,则攻击者发现了原始密码。进行这些猜测最常用的两种方法是暴力破解和字典攻击
- 如果不使用加盐技术,暴力攻击可以通过使用预计算和强大的时间记忆权衡技术(
time-memory trade-off)得到显著改善【7,8】 - 字典攻击:
- 字典本身可能是单词列表的集合,这些单词列表被认为是用户用来帮助记忆密码的常见来源【9】
- 用户很少直接使用列表里的元素(例如,因为密码创建策略禁止这样做),而是以他们仍然可以容易地回忆起来的方式修改单词
- 攻击者试图复制这种频繁的密码选择方法,处理输入字典中的单词,并通过应用预先选择的篡改规则系统地生成变体
- 选择正确的单词组合规则至关重要,因为每个规则的应用都会导致大量的猜测
- 【10】使用马尔可夫模型生成可能的密码
- 生成的密码在语音上类似单词
- 结合有限状态自动机,进一步减少搜索空间和低概率字符串
- 目标为基于彩虹表的破解提供预计算支持,因此字典来自语言上可能的密码,并不是标准的字典攻击
- 本文方法可以被看作是对标准字典攻击的改进:
- 使用现有的泄露密码语料库自动导出单词篡改规则
- 使用这些规则和语料库来进一步以概率顺序导出猜测密码
- 由于对结构的概率赋值,还能够推导出更复杂的单词处理规则
概率的密码破解
- 并非所有密码的概率都相同,因此关键问题是如何计算这个概率
预处理
测量与密码字符串相关的特定模式的频率
定义字母串为$L$,数字串为$D$,特殊字符串为$S$,其下标代表对应串的长度(字母串没有区分大小写)
导出训练集中所有的类似结构和每种结构的频率
计算数字串和特殊字符串在训练集中出现的概率。例如”1“出现的概率、”12“出现的概率等(这里的概率指的是,出现次数/总出现次数,例如”1“的出现次数/”所有单个数字“出现字数)——因为用户可能使用的字母串比能够从训练集中学习的要多很多
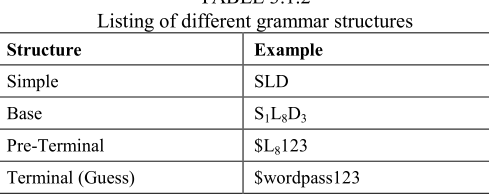
概率语法
上下文无关文法介绍(参考《编译原理》中的上下文无关文法)
从起始符号派生的字符串称为句型,一个句型的概率是推到中使用的元素的概率之积——这里导出的句型为 Pre-Terminal
例如下面这个导出的概率为 0.0975 :$S\rightarrow L_3D_1S_1 \rightarrow L_34S_1 \rightarrow L_34!$,之后字母串的替代可以查找字典中同样长度的单词实现(不给字典单词分配概率,即只以最高概率使用 Pre-Terminal,或对字典单词分配概率,如以字典中出现该长度单词的数目分配概率,这也是本文采用的两个方法)
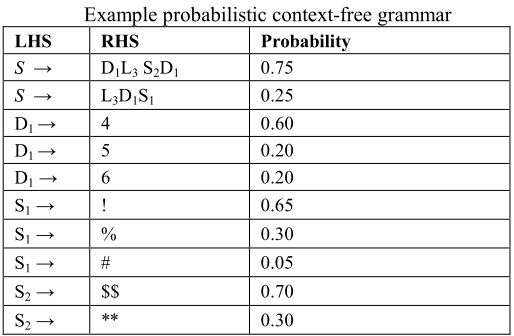
后面的方法,默认了最终的结果是一个联合概率,而且字典中单词概率和 Pre-Terminal 概率相互独立
密码生成
- 这里要考虑的问题是,对于下面这个树,应该以什么样的顺序生成子节点
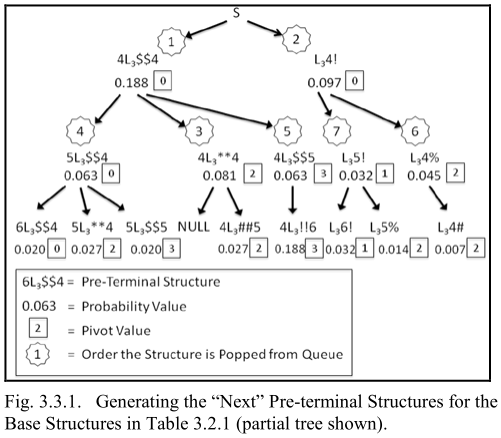
方法一:输出所有可能的末端结构和对应概率,然后排序——该步骤不能和随后的密码猜测同步,即需要输出数百 GB 的中间数据后才能开始排序
方法二:采用标准优先级队列,队首为最可能的 Pre-Terminal 结构;队列元素结构如下
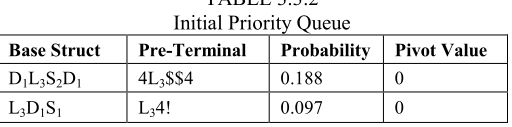 * Pivot Value的作用:当 pop 一个 Pre-Terminal 时,检查这个值,确定哪些新的 Pre-Terminal 会插入队列。用于保证没有一个 Base Struct 的所有可能 Pre-Terminal 都不重复放入队列——这个值作为索引,将大于或等于这个它的索引替换变量获得下一个 Pre-Terminal
* Pivot Value的作用:当 pop 一个 Pre-Terminal 时,检查这个值,确定哪些新的 Pre-Terminal 会插入队列。用于保证没有一个 Base Struct 的所有可能 Pre-Terminal 都不重复放入队列——这个值作为索引,将大于或等于这个它的索引替换变量获得下一个 Pre-Terminal
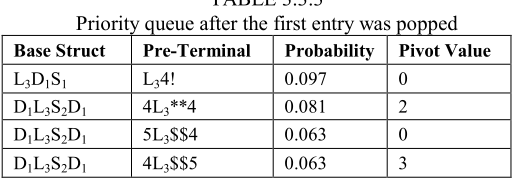
- 最初,来自每个 Base Struct 的所有最高概率 Pre-Terminal 将被插入 Pivot Value 为0的优先级队列。之后 pop 队首的结构
实验和结果
密码集
- MySpace:来自网络钓鱼攻击,共有67054个纯文本密码
- SilentWhisper:来自 SQL 注入攻击,密码非常简单,只有3.28%的密码同时包含数字和字母,共有7480个纯文本密码
- Finnish【16】:来自 SQL 注入攻击,包括很多不同的网站,共计15699个纯文本密码和22733个 MD5 哈希(纯文本密码和哈希密码分别来自多个不同的网站)
- 密码集的规模比较小
实验配置与过程
- 程序(基于C)在现有的密码列表训练
- 输入一个字典,则基于密码结构的
terminal probability和pre-terminal probability生成密码猜测 - 只需要一次训练;存储需求很低;训练与破解分离;高度可移植
- 确保本文方法和 JTR 的输入是相同的密码集
- 两组训练和测试:
- MySpace 密码分为训练和测试
- Finnish 明文密码作为训练,哈希密码进行测试
- SilentWhisper 作为测试集
- 确保测试集不含有训练密码
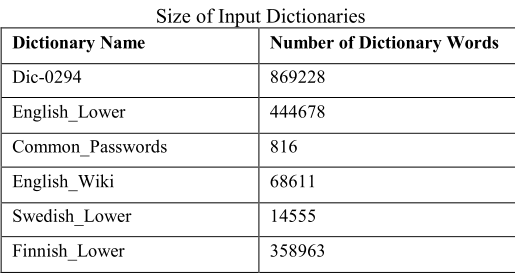
输入字典描述
本文的方法和单词列表模式下的 JTR 都是字典攻击,因此需要输入一个字典
输入字典
词典 dic-0294【9】
英语密码,芬兰语密码,瑞典密码,通用密码(均为小写,来自 JTR 网站【11】)
来自 www.wiktionary.org 的英语单词创建字典“英语维基”
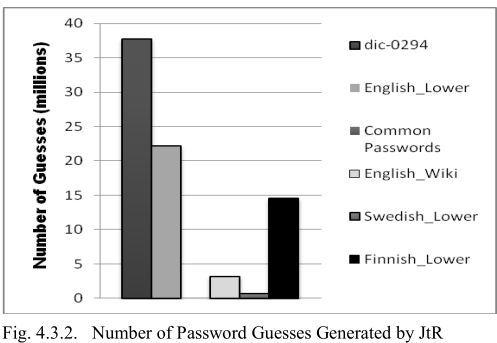
密码破解结果
在 MySpace 上训练、测试。本文的方法(以
terminal probability顺序运行)的表现最好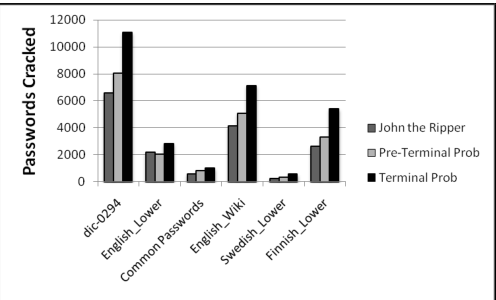
训练集和测试集不同:
- 在 Finnish 训练,在 MySpace 测试
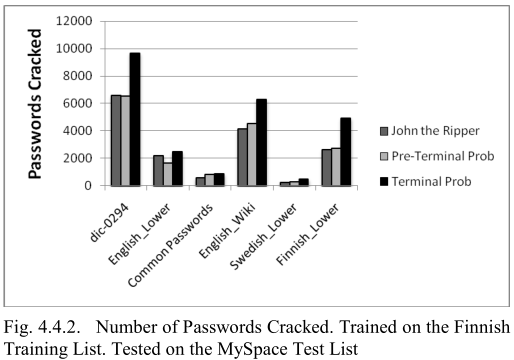
- 在 MySpace 训练,在 SilentWhisper 测试:JTR 效果更好,因为测试集非常简单,而本文的方法更多使用高级的篡改规则进行猜测——这是本文方法的局限,因为需要在相似复杂性的密码上训练
在 Finnish 训练和测试:本文的方法更好——能够在一个用户群上训练,然后成功地用它来对付另一个除了母语相同之外一无所知的群体(训练集和测试集来自不同的网站)
论文还讨论了为什么 English_Lower 字典中,本文方法的提高没有那么明显
在不同大小的 MySpace 训练,在 Myspace 测试(评估训练集大小的影响)
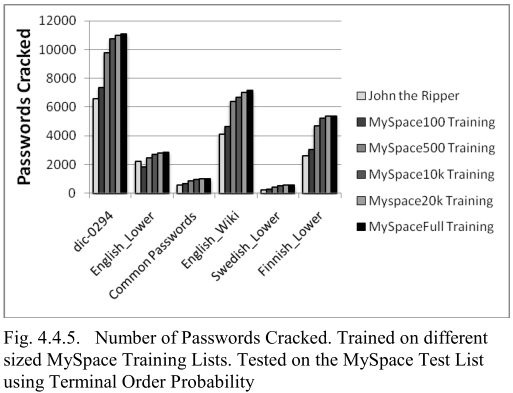
- 为防止采样偏差,对规模小的训练集进行25次测试后取平均
- 更大的训练集将更好地反映基础结构和替换值的更准确的概率
提高猜测次数:破解密码的速度确实随着猜测的增加而减慢
空间复杂度分析
略
展望
- 将字典单词插入到最终猜测的方法
- 修改基本结构,以更准确描述人们创建密码的过程——如何识别那些规则的转换
- 在训练时平滑概率,以创建训练集中不存在的 teminal value。本文方法中,如果“23”没有出现在训练集,则之后也不会生成——理想状况下应该生成,只是相对的生成概率小
- 希望能根据破解密码的相对概率,在字典攻击和有针对性地暴力攻击之间自动切换
结论
- 当通过在相关结构的密码上训练来为不同来源密码定制攻击时,本文的方法是非常有效的——例如,如果已知目标密码是满足:长度为8个字符、包含数字和特殊字符,则算法需要在满足该要求的密码上进行训练即可
- 其他结论参看摘要与介绍
参考文献
[1] U. Manber. A simple scheme to make passwords based on one-way functions much harder to crack. Computers & Security Journal, Volume 15, Issue 2, 1996, Pages 171-176. Elsevier.
[2] J. Yan, A. Blackwell, R. Anderson, and A. Grant. Password Memorability and Security: Empirical Results. IEEE Security and Privacy Magazine, Volume 2, Number 5, pages 25-31, 2004.
[3] R. V. Yampolskiy. Analyzing User Password Selection Behavior for Reduction of Password Space. Proceedings of the IEEE International Carnahan Conferences on Security Technology, pp.109-115, 2006.
[4] M. Bishop and D. V. Klein. Improving system security via proactive password checking. Computers & Security Journal, Volume 14, Issue 3, 1995, Pages 233-249. Elsevier.
[5] G. Kedem and Y. Ishihara. Brute Force Attack on UNIX Passwords with SIMD Computer. Proceedings of the 3rd USENIX Windows NT Symposium, 1999.
[6] N. Mentens, L. Batina, B. Preneel, I. Verbauwhede. Time-Memory Trade-Off Attack on FPGA Platforms: UNIX Password Cracking. Proceedings of the International Workshop on Reconfigurable Computing: Architectures and Applications. Lecture Notes in Computer Science, Volume 3985, pages 323-334, Springer, 2006.
[7] M. Hellman. A cryptanalytic time-memory trade-off. IEEE Transactions on Information Theory, Volume 26, Issue 4, pages 401-406, 1980.
[8] P. Oechslin. Making a Faster Cryptanalytic Time-Memory Trade-Off. Proceedings of Advances in Cryptology (CRYPTO 2003), Lecture Notes in Computer Science, Volume 2729, pages 617-630, 2003. Springer.
[9] A list of popular password cracking wordlists, 2005, [Online Document] [cited 2008 Oct 07] Available HTTP http://www.outpost9.com/files/WordLists.html
[10] A. Narayanan and V. Shmatikov, Fast Dictionary Attacks on Passwords Using Time-Space Tradeoff, CCS’05, November 7–11, 2005, Alexandria, Virginia
[11] John the Ripper password cracker, [Online Document] [cited 2008 Oct 07] Available HTTP http://www.openwall.com
[12] J.E. Hopcroft and J.D. Ullman, Introduction to Automata Theory, Languages, and Computation, Addison Wesley, 1979.
[13] L. R. Rabiner, A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition, Proceedings of the IEEE, Volume 77, No. 2, February 1989.
[14] N. Chomsky. Three models for the description of language. Information Theory, IEEE Transactions on, 2(3):113–124, Sep 1956.
[15] Robert McMillan, Phishing attack targets Myspace users, 2006, [Online Document] [cited 2008 Oct 07] Available HTTP http://www.infoworld.com/infoworld/article/06/10/27/HNphishingmyspace1.html.
[16] Bulletin Board Announcement of the Finnish Password List, October 2007, [Online Document] [cited 2008 Oct 07] Available HTTP http://www.bat.org/news/view_post?postid=40546&page=1&group.

