《Hands-on Machine Learning》第二部分阅读笔记(6)RNN 的注意力机制(Transformer 架构)
RNN 中的注意力机制
注意力机制
让解码器在每个时间步关注特别的(被编码器编码的)词
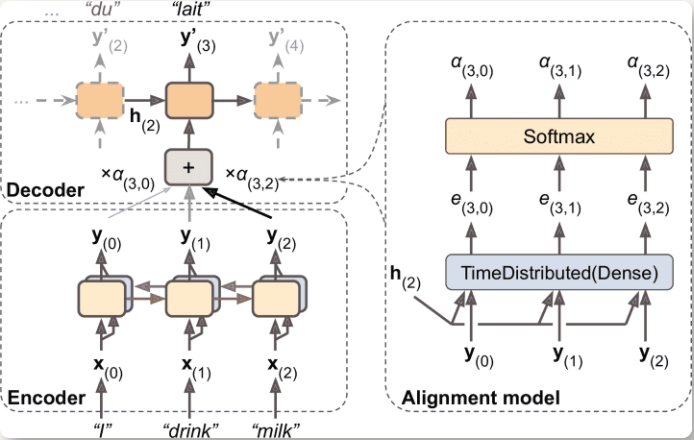
- 左边是编码器和解码器
- 将所有的输出(不只是最终隐藏态)传给解码器
- 解码器的记忆单元计算所有这些输出的加权和,以确定这一步关注哪个词
- 权重
α[t,i]是第i个编码器输出在解码器第t时间步的权重,如果权重α[3, 2]比α[3, 0]和α[3, 1]大得多,则解码器会用更多注意力关注词 2(milk) - 权重
α[t,i]用一种小型的被称为对齐模型(注意力层)的神经网络生成,注意力层与模型的其余部分联合训练,如右图所示- 一开始是 TimeDistributed(Dense),层输出一些分数,经过一个 softmax,得到每个编码器最终权重
- 一个神经元接收所有编码器的输出,加上解码器的上一个隐藏态(即
h[2]) - 称为 Bahdanau 注意力
Luong 注意力
衡量编码器的输出,和解码器上一隐藏态的相似度
计算这两个向量的点积,所有的分数(在特定的解码器时间步)通过 softmax 层,得到最终权重
将解码器单元包装进
AttentionWrapper,使用想用的注意力机制1
2
3
4attention_mechanism = tfa.seq2seq.attention_wrapper.LuongAttention(
units, encoder_state, memory_sequence_length=encoder_sequence_length)
attention_decoder_cell = tfa.seq2seq.attention_wrapper.AttentionWrapper(
decoder_cell, attention_mechanism, attention_layer_size=n_units)
三种注意力公式
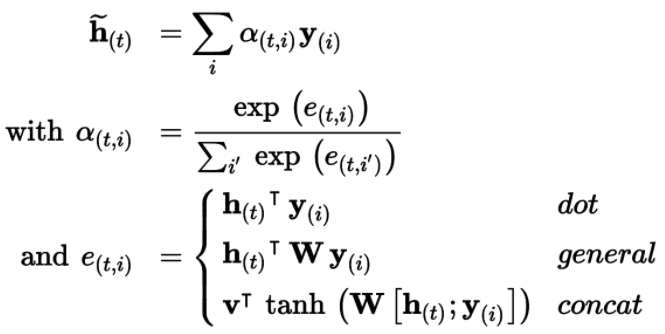
视觉注意力
- 卷积神经网络首先处理图片,生成一些特征映射,用带有注意力机制的解码器 RNN 来生成标题,每次生成一个词
- 注意力机制的一个额外的优点是更容易使人明白是什么让模型产生输出——可解释性
Transformer 架构
极大提高 NMT 性能,没有使用任何循环或卷积层,只用了注意力机制(加上嵌入层、紧密层、归一化层,和一些其它组件)
架构如下
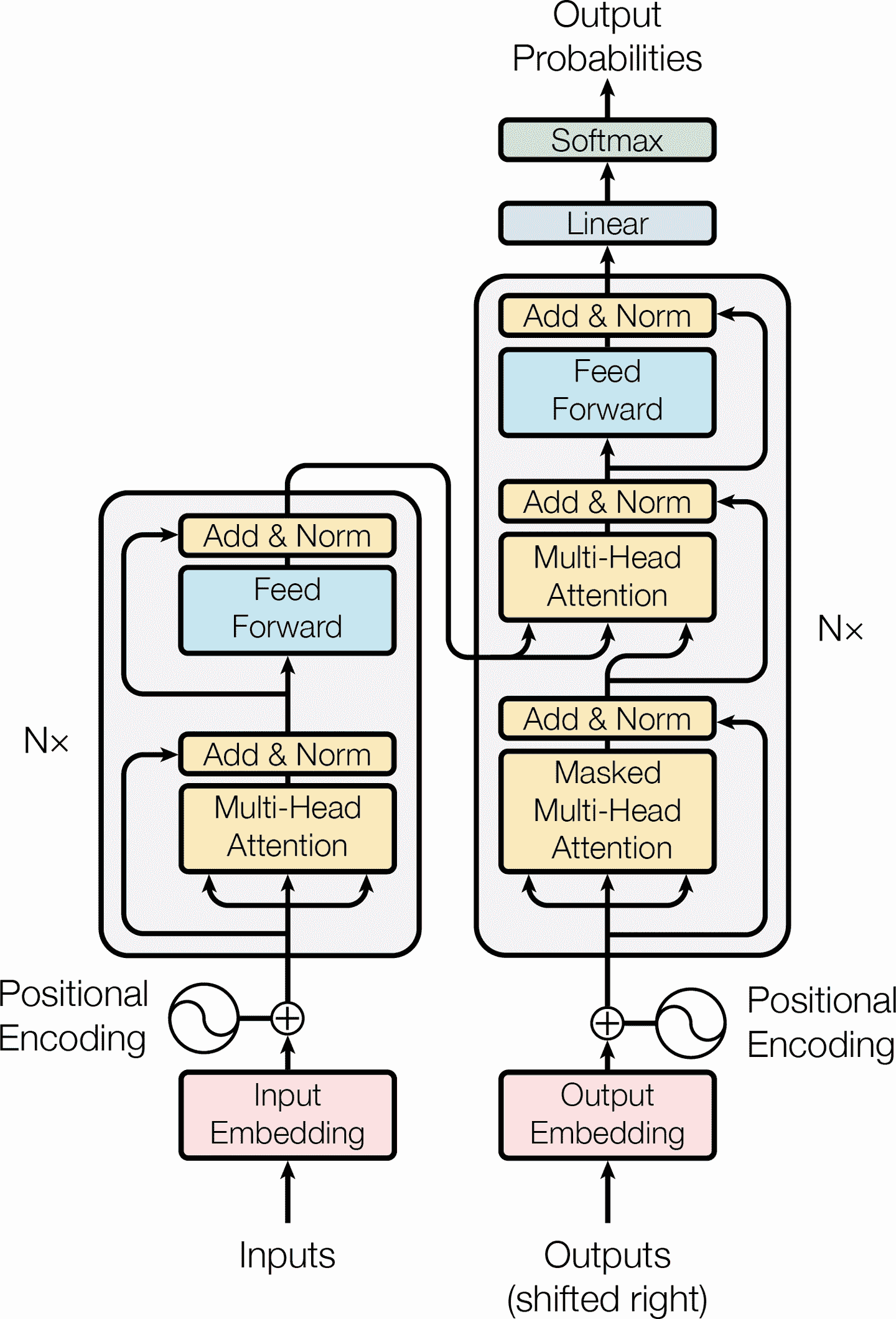
图的左边是编码器,输入是一个批次的句子,表征为序列化的单词 ID(
[批次大小, 最大输入句子长度])编码器的输出为
[批次大小, 最大输入句子长度, 512],每个单词表征为 512 维;编码器的头部叠加了N次右边是解码器,目标句子作为输入,在起点插入一个 SOS 标记;也接收编码器的输出
解码器的头部重叠了
N次,编码器的最终输出,传入给解码器重叠层中的每一个部分每个时间步,解码器输出每个下一个可能词的概率(
[批次大小, 最大输出句子长度, 词典长度])预测时,解码器不能接收目标;每一轮预测一个词(预测出来的词在下一轮输入给解码器,直到输出 EOS 标记)
两个嵌入层,
5 × N个跳连接,每个后面是一个归一化层,2 × N个“前馈”模块(由两个全连接层组成(第一个使用 ReLU 激活函数,第二个不使用激活函数)- 编码器的多头注意力层,编码每个词与句子中其它词的关系,对更相关的词付出更多注意力
- 位置嵌入类似词嵌入,表示词在句子中的位置——相对或绝对的词的位置非常重要,因此需要将位置信息以某种方式告诉 Transformer
位置嵌入
位置嵌入是一个紧密向量,对词在句子中的位置进行编码,第
i个位置嵌入添加到句子中的第i个词模型可以学习位置嵌入
TensorFlow 中没有
PositionalEmbedding层1
2
3
4
5
6
7
8
9
10
11
12class PositionalEncoding(keras.layers.Layer):
def __init__(self, max_steps, max_dims, dtype=tf.float32, **kwargs):
super().__init__(dtype=dtype, **kwargs)
if max_dims % 2 == 1: max_dims += 1 # max_dims must be even
p, i = np.meshgrid(np.arange(max_steps), np.arange(max_dims // 2))
pos_emb = np.empty((1, max_steps, max_dims))
pos_emb[0, :, ::2] = np.sin(p / 10000**(2 * i / max_dims)).T
pos_emb[0, :, 1::2] = np.cos(p / 10000**(2 * i / max_dims)).T
self.positional_embedding = tf.constant(pos_emb.astype(self.dtype))
def call(self, inputs):
shape = tf.shape(inputs)
return inputs + self.positional_embedding[:, :shape[-2], :shape[-1]]- 构造器中先计算出位置嵌入,需要知道最大句子长度,
max_steps,每个词表征的维度,max_dims - 调用
call()裁剪嵌入矩阵
- 构造器中先计算出位置嵌入,需要知道最大句子长度,
创建 Transformer 的前几层:
1
2
3
4
5
6
7
8
9embed_size = 512; max_steps = 500; vocab_size = 10000
encoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
decoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
embeddings = keras.layers.Embedding(vocab_size, embed_size)
encoder_embeddings = embeddings(encoder_inputs)
decoder_embeddings = embeddings(decoder_inputs)
positional_encoding = PositionalEncoding(max_steps, max_dims=embed_size)
encoder_in = positional_encoding(encoder_embeddings)
decoder_in = positional_encoding(decoder_embeddings)
多头注意力
收缩点积注意力层(Scaled Dot-Product Attention)
假设编码器分析输入句子
They played chess,编码器分析出They是主语,played是动词,然后用词的表征编码这些信息;假设解码器已经翻译了主语需要从输入句子取动词:解码器想查找键
verb对应的值是什么。但是,模型没有离散的标记来表示键(比如subject或verb);它只有这些(训练中学到的)信息的向量化表征所以用来查询的键,不会完美对应前面字典中的键——计算查询词和键的相似度,用 softmax 函数计算概率权重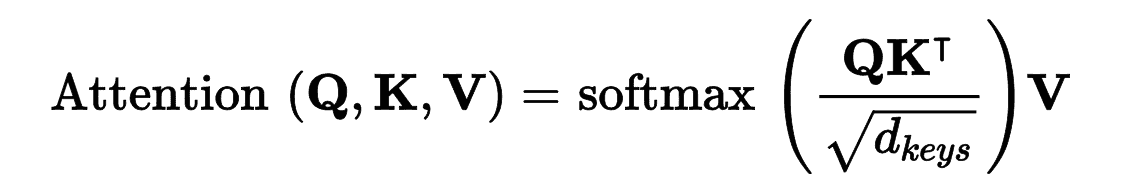
Q矩阵每行是一个查询词。它的形状是[n_queries, d_keys],n_queries是查询数,d_keys是每次查询和每个键的维度数K矩阵每行是一个键。它的形状是[n_keys, d_keys],n_keys是键和值的数量V矩阵每行是一个值。它的形状是[n_keys, d_values],d_values是每个值的数- 编码器中,公式应用到批次中的每个句子,
Q、K、V等于输入句中的词列表 - 解码器的遮挡注意力层中,这个公式会应用到批次中每个目标句上,但要用遮挡,防止每个词和后面的词比较
keras.layers.Attention层实现了缩放点积注意力,它的输入是Q、K、V,还有一个批次维度
多头注意力层
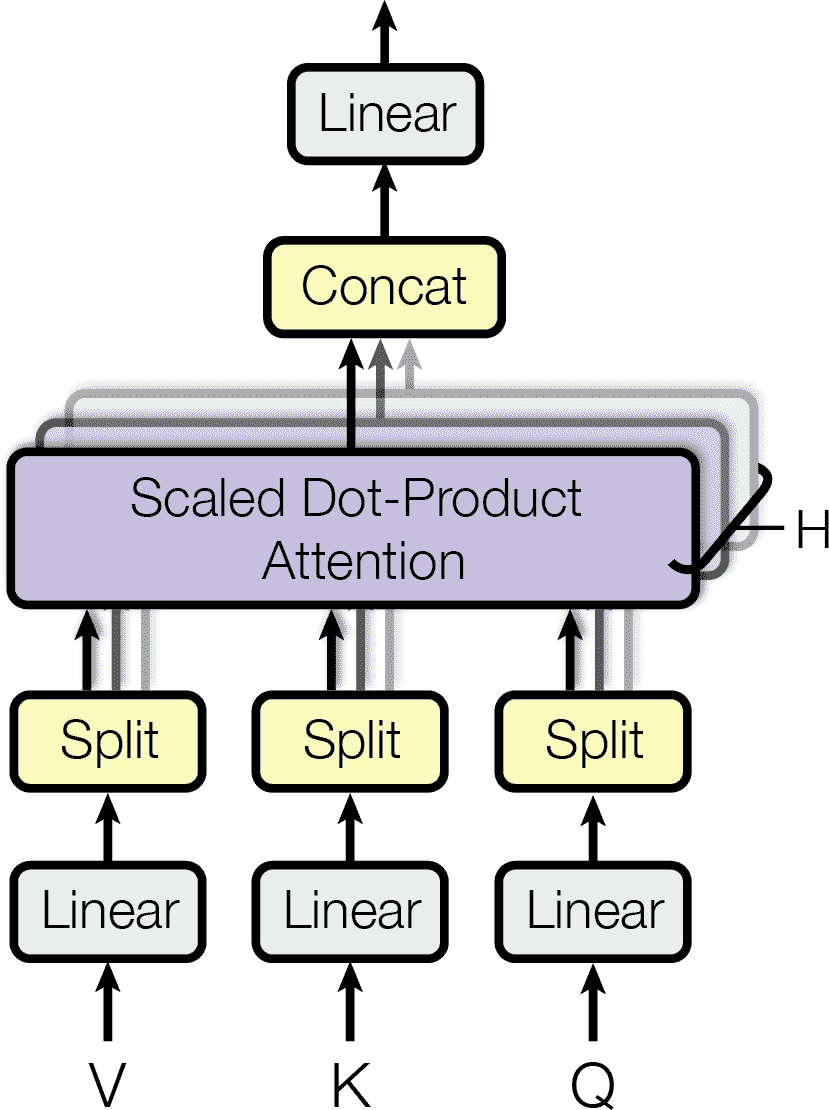
- 包括一组缩放点积注意力层,每个前面有一个值、键、查询的线性变换
- 所有输出简单连接起来,再通过一个最终的线性变换
- 让模型将词表征投影到不同的亚空间,每个关注于词特性的一个子集,缩放点积注意力做查询操作,最后将所有结果串起来,在投射到原始空间
TensorFlow 2 还没有
Transformer类或MultiHeadAttention类;可以查看 TensorFlow 教程:创建语言理解的 Transformer 模型

