《Hands-on Machine Learning》第二部分阅读笔记(7)自动编码器
自动编码器与表征学习
- 编码是自编码器在一些限制下学习恒等函数的副产品
有效的数据表征
- 自编码器查看输入信息,转换为高效的潜在表征,输出一些(希望)非常接近输入的东西
- 自编码器:
- 将输入转换为潜在表征的编码器——识别网络
- 将潜在表征转换为输出的解码器——生成网络
- 自编码器通常与 MLP 体系结构相同,但输出层神经元数量必须等于输入数量
- 输出通常被称为重建,损失函数包含重建损失
- 内部表征具有比输入数据更低的维度,自编码器被迫学习输入数据中最重要的特征,并删除不重要的特征
不完整的线性自编码器实现PCA
自编码器仅使用线性激活且损失函数是均方误差 MSE——实现主成分分析
1
2
3
4
5
6
7from tensorflow import keras
encoder = keras.models.Sequential([keras.layers.Dense(2, input_shape=[3])])
decoder = keras.models.Sequential([keras.layers.Dense(3, input_shape=[2])])
autoencoder = keras.models.Sequential([encoder, decoder])
autoencoder.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=0.1))编码器和解码器都是
Sequential模型,每个含有一个 Dense自编码器的输出等于输入
简单 PCA 不需要激活函数
可以将自编码器当做某种形式的自监督学习,即带有自动生成标签功能的监督学习
栈式自编码器
自编码器有多个隐藏层:栈式自编码器(或深度自编码器)
中央隐藏层(编码层)为中心通常是对称的
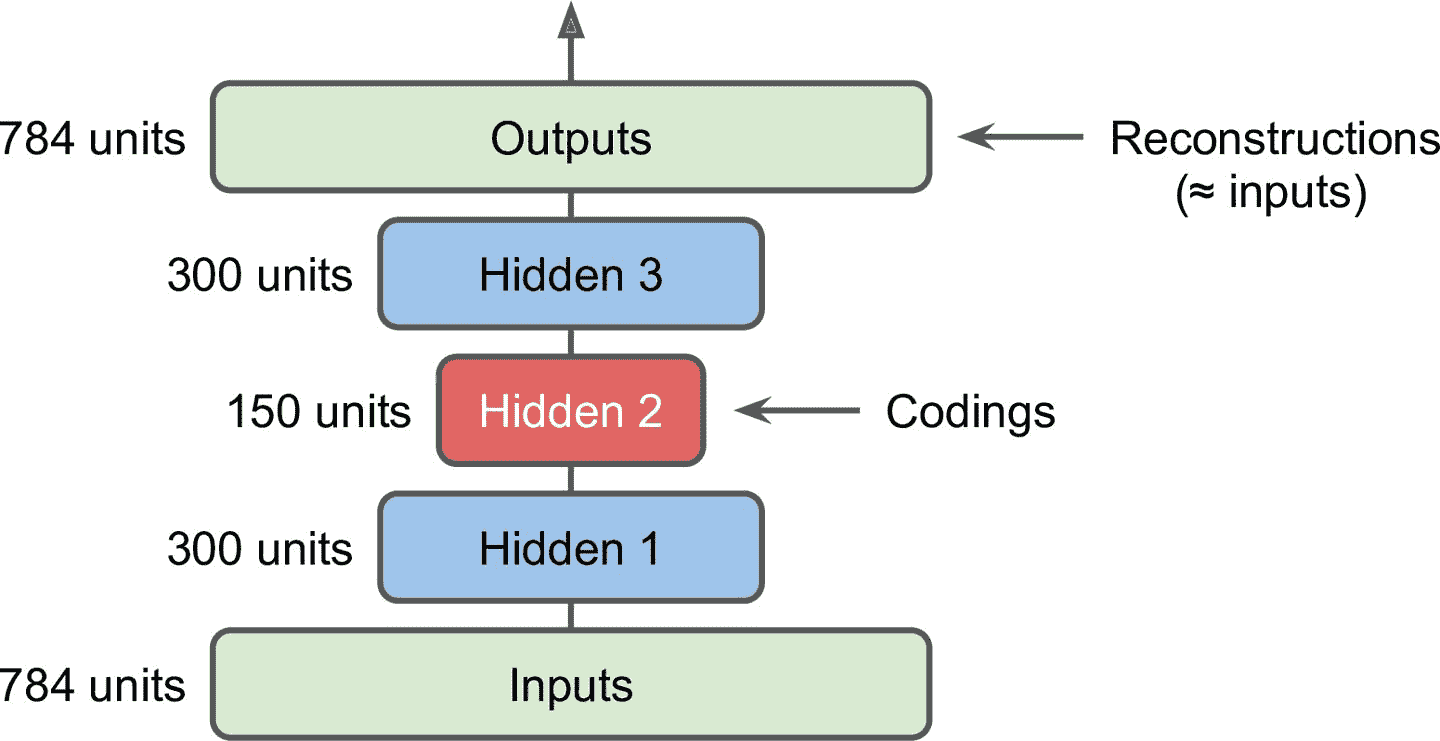
Keras 实现栈式自编码器
代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15stacked_encoder = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(100, activation="selu"),
keras.layers.Dense(30, activation="selu"),
])
stacked_decoder = keras.models.Sequential([
keras.layers.Dense(100, activation="selu", input_shape=[30]),
keras.layers.Dense(28 * 28, activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
stacked_ae = keras.models.Sequential([stacked_encoder, stacked_decoder])
stacked_ae.compile(loss="binary_crossentropy",
optimizer=keras.optimizers.SGD(lr=1.5))
history = stacked_ae.fit(X_train, X_train, epochs=10,
validation_data=[X_valid, X_valid])- 包括两个子模块:编码器和解码器
- 编码器接收
28 × 28像素的灰度图片,打平为 784 的向量,用两个 Dense 层处理 - 解码器接收编码器的输出,用两个 Dense 层处理,最后的向量转换为
28 × 28的数组,使解码器的输出和编码器的输入形状相同
可视化重建
绘制重建结果与实际的图片
1
2
3
4
5
6
7
8
9
10
11
12
13
14def plot_image(image):
plt.imshow(image, cmap="binary")
plt.axis("off")
def show_reconstructions(model, n_images=5):
reconstructions = model.predict(X_valid[:n_images])
fig = plt.figure(figsize=(n_images * 1.5, 3))
for image_index in range(n_images):
plt.subplot(2, n_images, 1 + image_index)
plot_image(X_valid[image_index])
plt.subplot(2, n_images, 1 + n_images + image_index)
plot_image(reconstructions[image_index])
show_reconstructions(stacked_ae)
可视化 Fashion MNIST 数据集
可以利用自编码器将数据集降维到一个合理的水平,使用另外一个降维算法做可视化
举例:栈式自编码器的编码器将维度降到 30,使用 Scikit-Learn 的 t-SNE 算法将维度降到 2 并做可视化
1
2
3
4
5
6
7from sklearn.manifold import TSNE
X_valid_compressed = stacked_encoder.predict(X_valid)
tsne = TSNE()
X_valid_2D = tsne.fit_transform(X_valid_compressed)
plt.scatter(X_valid_2D[:, 0], X_valid_2D[:, 1], c=y_valid, s=10, cmap="tab10")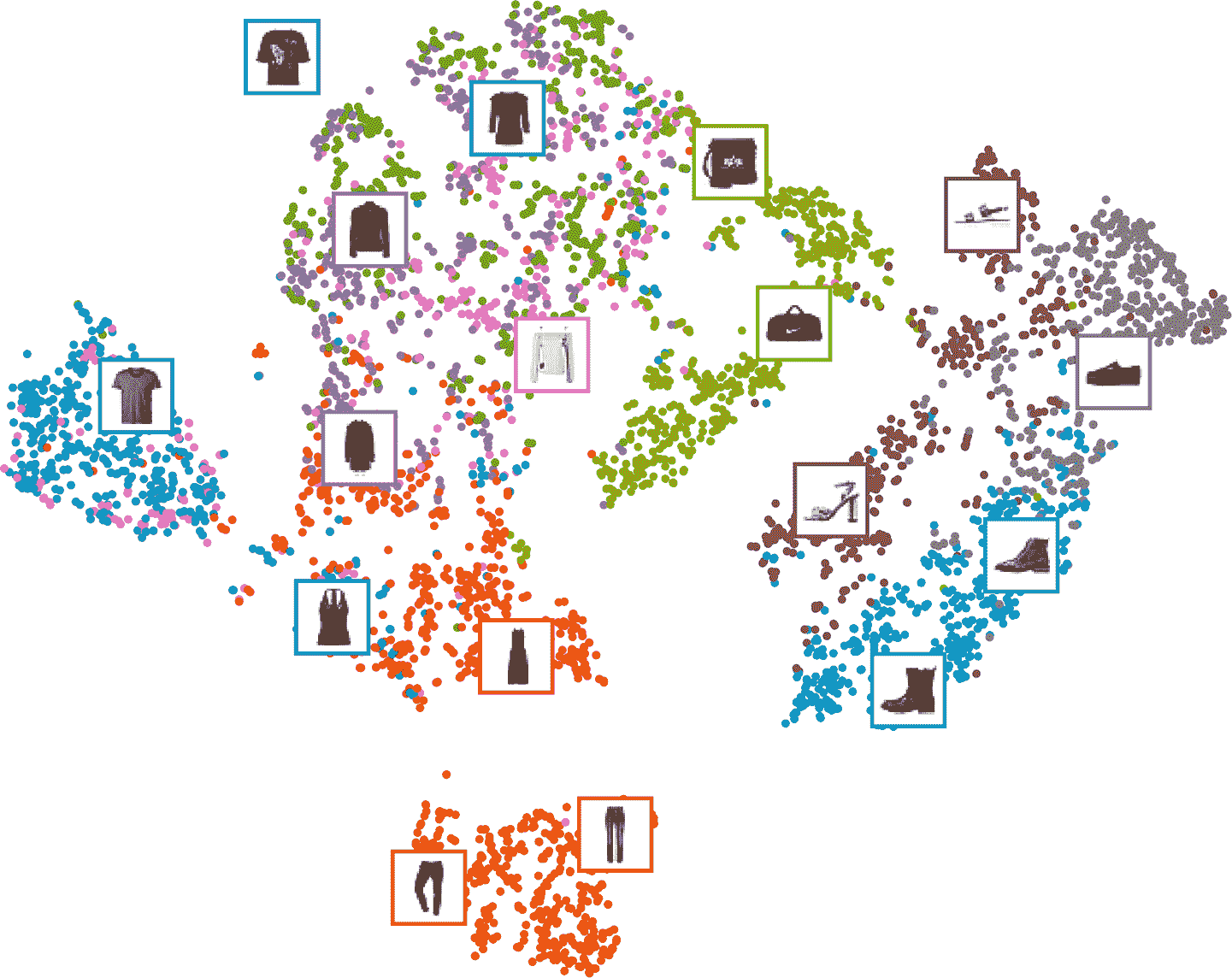
栈式自编码器实现无监督预训练
如果有一个大数据集,但大部分实例是无标签的,可以用全部数据训练一个栈式自编码器,然后使用其底层创建一个神经网络,再用有标签数据来训练
当训练分类器时,如果标签数据不足,可以冻住预训练层
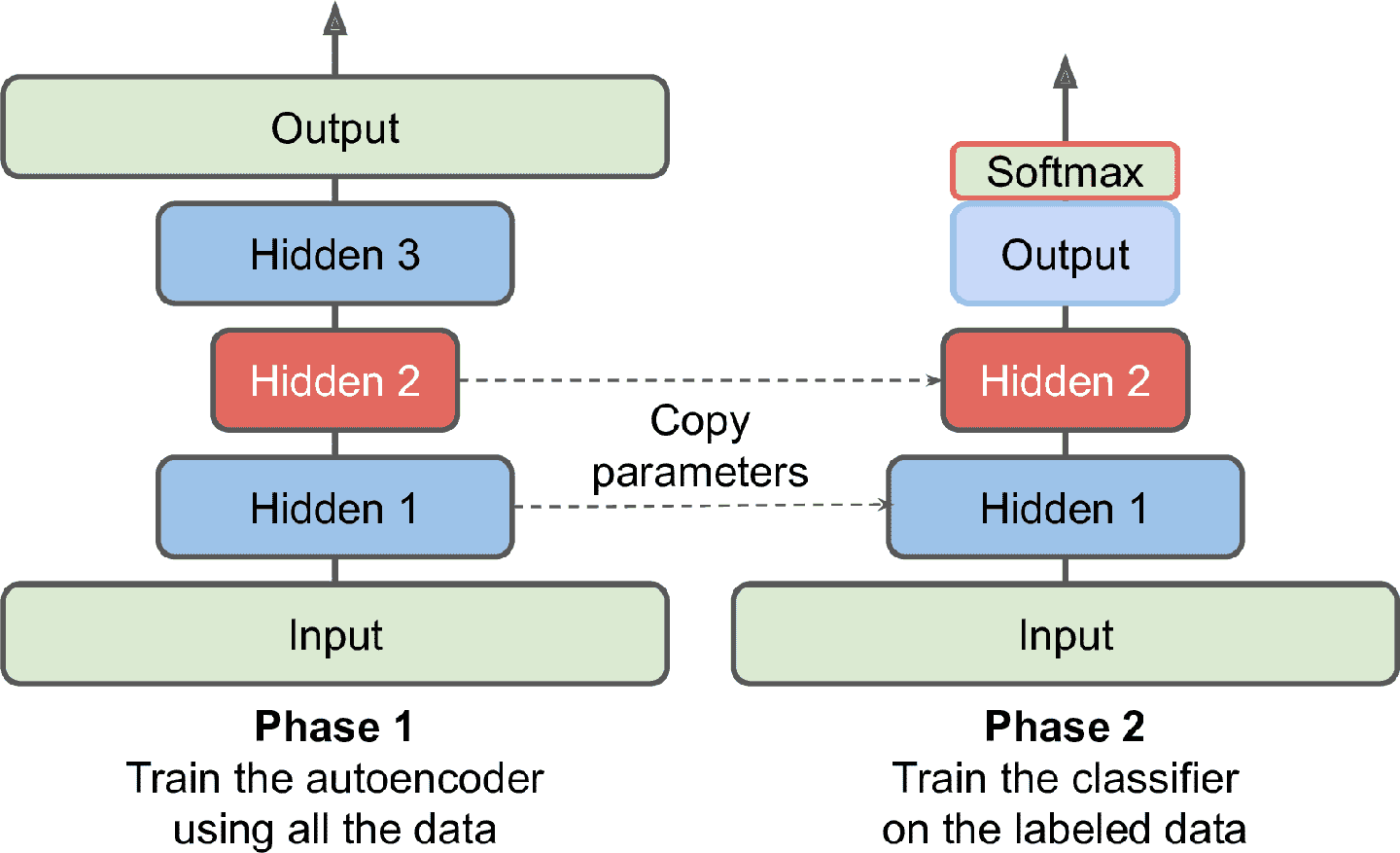
关联权重
将解码器层的权重与编码器层的权重相关联,以减半模型中的权重数量,加快训练速度,并限制过拟合的风险
W[L]表示第L层的连接权重,解码器层权重可以简单地定义为:W[N–L+1] = W[L]^T(其中L = 1, 2, ..., N/2)1
2
3
4
5
6
7
8
9
10
11
12class DenseTranspose(keras.layers.Layer):
def __init__(self, dense, activation=None, **kwargs):
self.dense = dense
self.activation = keras.activations.get(activation)
super().__init__(**kwargs)
def build(self, batch_input_shape):
self.biases = self.add_weight(name="bias", initializer="zeros",
shape=[self.dense.input_shape[-1]])
super().build(batch_input_shape)
def call(self, inputs):
z = tf.matmul(inputs, self.dense.weights[0], transpose_b=True)
return self.activation(z + self.biases)- 使用另一个 Dense 层的权重,并且做了转置(设置
transpose_b=True等同于转置第二个参数)。但使用自己的偏置向量
- 使用另一个 Dense 层的权重,并且做了转置(设置
关联
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16dense_1 = keras.layers.Dense(100, activation="selu")
dense_2 = keras.layers.Dense(30, activation="selu")
tied_encoder = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
dense_1,
dense_2
])
tied_decoder = keras.models.Sequential([
DenseTranspose(dense_2, activation="selu"),
DenseTranspose(dense_1, activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
tied_ae = keras.models.Sequential([tied_encoder, tied_decoder])
浅自编码器堆叠
一次训练一个浅自编码器,然后将所有自编码器堆叠到一个栈式自编码器
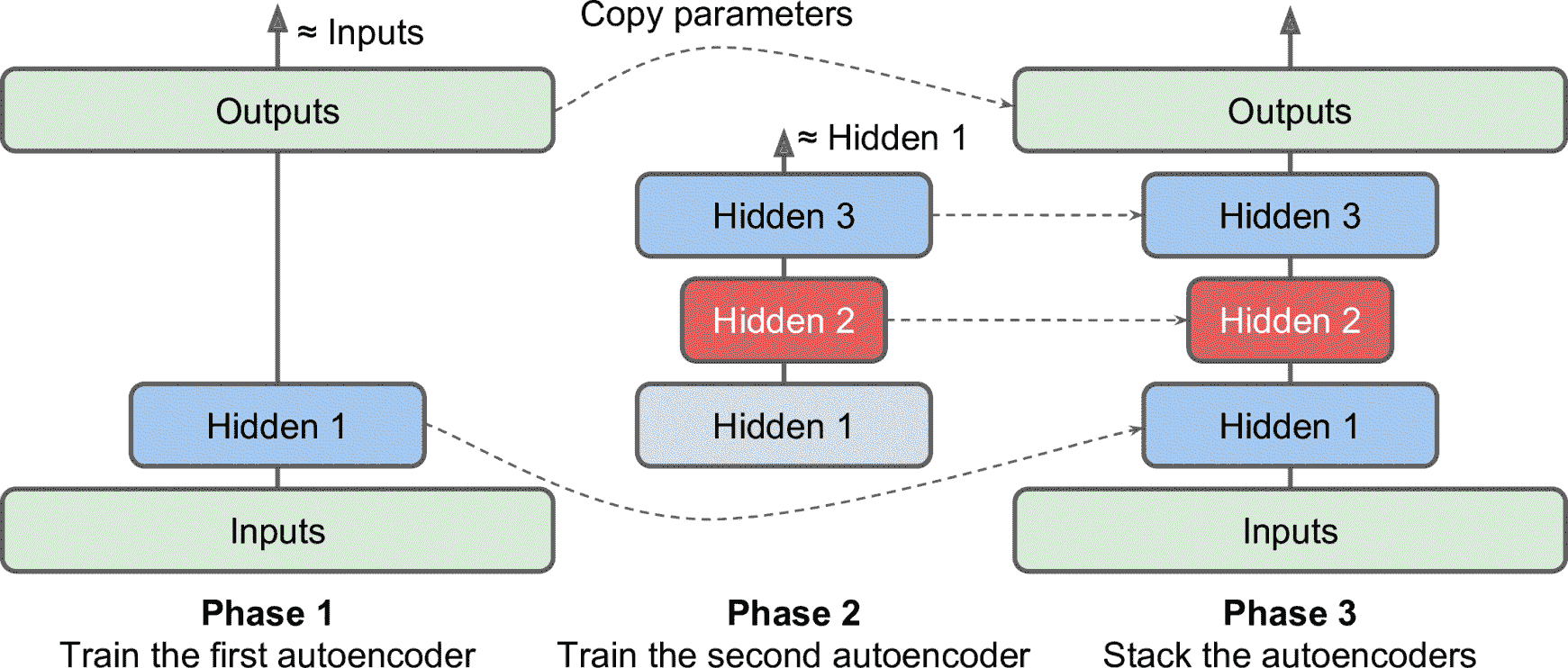
第一个自编码器学习重构输入,整个训练集训练第一个自编码器,得到一个压缩过的训练集
这个数据集训练第二个自编码器
最后把每个自编码器的隐藏层叠起,再加上输出层
卷积自编码器
用自编码器来处理图片:无监督预训练或降维
代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20conv_encoder = keras.models.Sequential([
keras.layers.Reshape([28, 28, 1], input_shape=[28, 28]),
keras.layers.Conv2D(16, kernel_size=3, padding="same", activation="selu"),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Conv2D(32, kernel_size=3, padding="same", activation="selu"),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Conv2D(64, kernel_size=3, padding="same", activation="selu"),
keras.layers.MaxPool2D(pool_size=2)
])
conv_decoder = keras.models.Sequential([
keras.layers.Conv2DTranspose(32, kernel_size=3, strides=2, padding="valid",
activation="selu",
input_shape=[3, 3, 64]),
keras.layers.Conv2DTranspose(16, kernel_size=3, strides=2, padding="same",
activation="selu"),
keras.layers.Conv2DTranspose(1, kernel_size=3, strides=2, padding="same",
activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
conv_ae = keras.models.Sequential([conv_encoder, conv_decoder])- 编码器是一个包含卷积层和池化层的常规 CNN
- 通常降低输入的空间维度(即,高和宽),同时增加深度(即,特征映射的数量)
循环自编码器
处理序列:对时间序列或文本无监督学习和降维
1
2
3
4
5
6
7
8
9
10recurrent_encoder = keras.models.Sequential([
keras.layers.LSTM(100, return_sequences=True, input_shape=[None, 28]),
keras.layers.LSTM(30)
])
recurrent_decoder = keras.models.Sequential([
keras.layers.RepeatVector(28, input_shape=[30]),
keras.layers.LSTM(100, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(28, activation="sigmoid"))
])
recurrent_ae = keras.models.Sequential([recurrent_encoder, recurrent_decoder])- 编码器是一个序列到向量的 RNN,而解码器是向量到序列的 RNN
- 解码器第一层用
RepeatVector,以保证在每个时间步将输入向量传给解码器
降噪自编码器
一种强制自编码器学习特征的方法是为其输入添加噪声,对其进行训练以恢复原始的无噪声输入
噪声可以是添加到输入的纯高斯噪声,或者可以随机关闭输入,就像丢弃
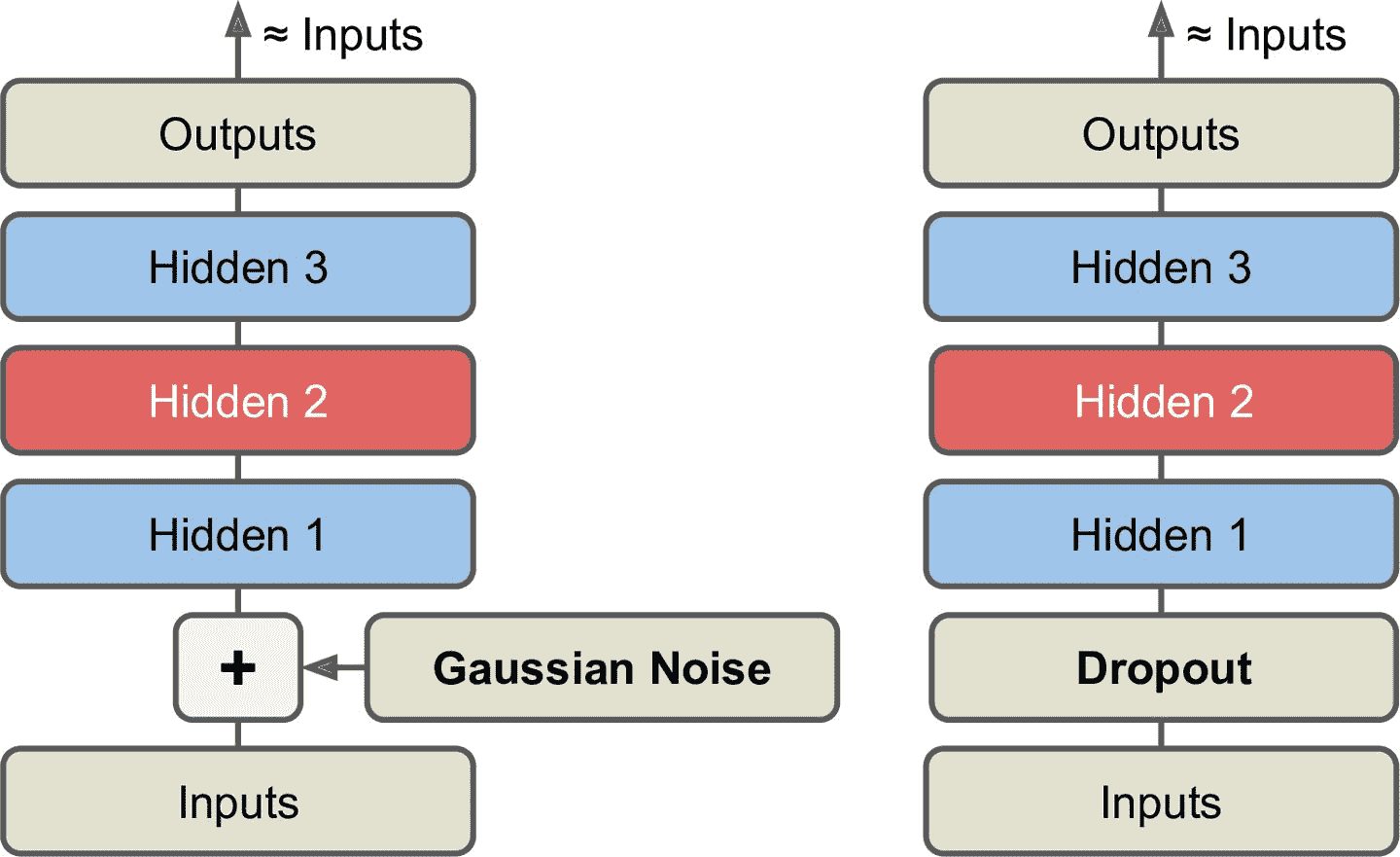
常规的栈式自编码器中添加一个应用于输入的
Dropout层(或使用GaussianNoise层)1
2
3
4
5
6
7
8
9
10
11
12dropout_encoder = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dropout(0.5),
keras.layers.Dense(100, activation="selu"),
keras.layers.Dense(30, activation="selu")
])
dropout_decoder = keras.models.Sequential([
keras.layers.Dense(100, activation="selu", input_shape=[30]),
keras.layers.Dense(28 * 28, activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
dropout_ae = keras.models.Sequential([dropout_encoder, dropout_decoder])
稀疏自编码器
良好特征提取的另一种约束是稀疏性:通过向损失函数添加适当的项,让自编码器减少编码层中活动神经元的数量,即让编码层中平均只有 5% 的活跃神经元,迫使自编码器将每个输入表示为少量激活的组合
使用 sigmoid 激活函数实现;添加一个编码层并给编码层的激活函数添加
ℓ1正则1
2
3
4
5
6
7
8
9
10
11
12sparse_l1_encoder = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(100, activation="selu"),
keras.layers.Dense(300, activation="sigmoid"),
keras.layers.ActivityRegularization(l1=1e-3)
])
sparse_l1_decoder = keras.models.Sequential([
keras.layers.Dense(100, activation="selu", input_shape=[300]),
keras.layers.Dense(28 * 28, activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
sparse_l1_ae = keras.models.Sequential([sparse_l1_encoder, sparse_l1_decoder])ActivityRegularization只是返回输入,但新增了训练损失,大小等于输入的绝对值之和(这个层只在训练中起作用)- 可以移出
ActivityRegularization,并在前一层设置activity_regularizer=keras.regularizers.l1(1e-3)
另一种更好的方法是在每次训练迭代中测量编码层的实际稀疏度,当偏移目标值,就惩罚模型
KL 散度:衡量两个离散的概率分布
P和Q距离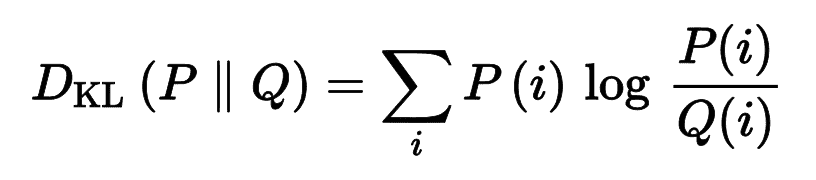
基于 KL 散度的稀疏自编码器
自定义正则器实现 KL 散度正则
1
2
3
4
5
6
7
8
9
10
11
12K = keras.backend
kl_divergence = keras.losses.kullback_leibler_divergence
class KLDivergenceRegularizer(keras.regularizers.Regularizer):
def __init__(self, weight, target=0.1):
self.weight = weight
self.target = target
def __call__(self, inputs):
mean_activities = K.mean(inputs, axis=0)
return self.weight * (
kl_divergence(self.target, mean_activities) +
kl_divergence(1\. - self.target, 1\. - mean_activities))使用正则器作为编码层的激活函数,创建稀疏自编码器
1
2
3
4
5
6
7
8
9
10
11
12kld_reg = KLDivergenceRegularizer(weight=0.05, target=0.1)
sparse_kl_encoder = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(100, activation="selu"),
keras.layers.Dense(300, activation="sigmoid", activity_regularizer=kld_reg)
])
sparse_kl_decoder = keras.models.Sequential([
keras.layers.Dense(100, activation="selu", input_shape=[300]),
keras.layers.Dense(28 * 28, activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
sparse_kl_ae = keras.models.Sequential([sparse_kl_encoder, sparse_kl_decoder])训练好稀疏自编码器,编码层中的神经元的激活大部分接近 0,所有神经元的平均激活值在 0.1 附近
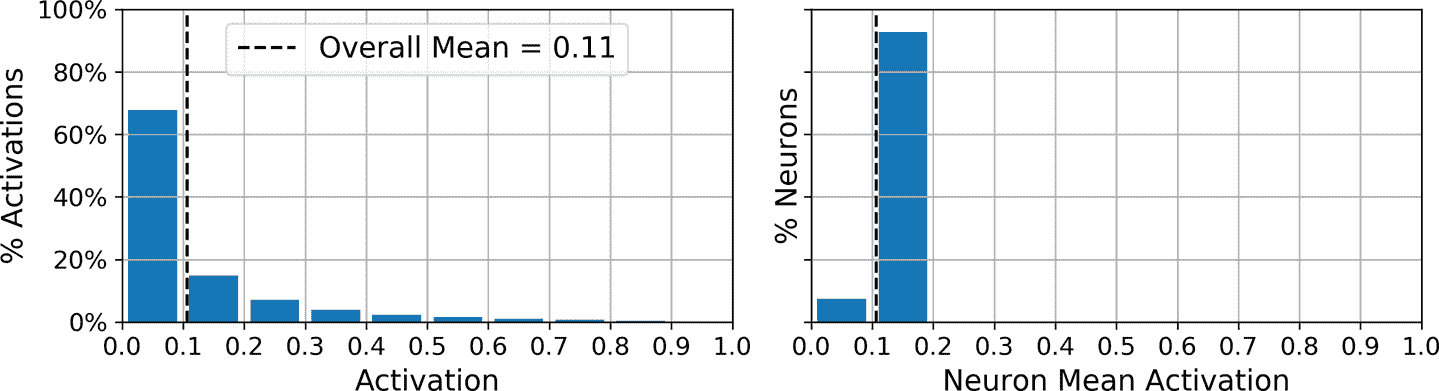
变分自编码器
是概率自编码器,即使在训练之后,它们的输出部分也是偶然确定的
是生成自编码器,可以生成看起来像从训练集中采样的新实例
不是直接为给定的输入生成编码 ,而是编码器产生平均
μ和标准差σ,然后从平均值μ和标准差σ的高斯分布随机采样实际编码;解码器正常解码采样的编码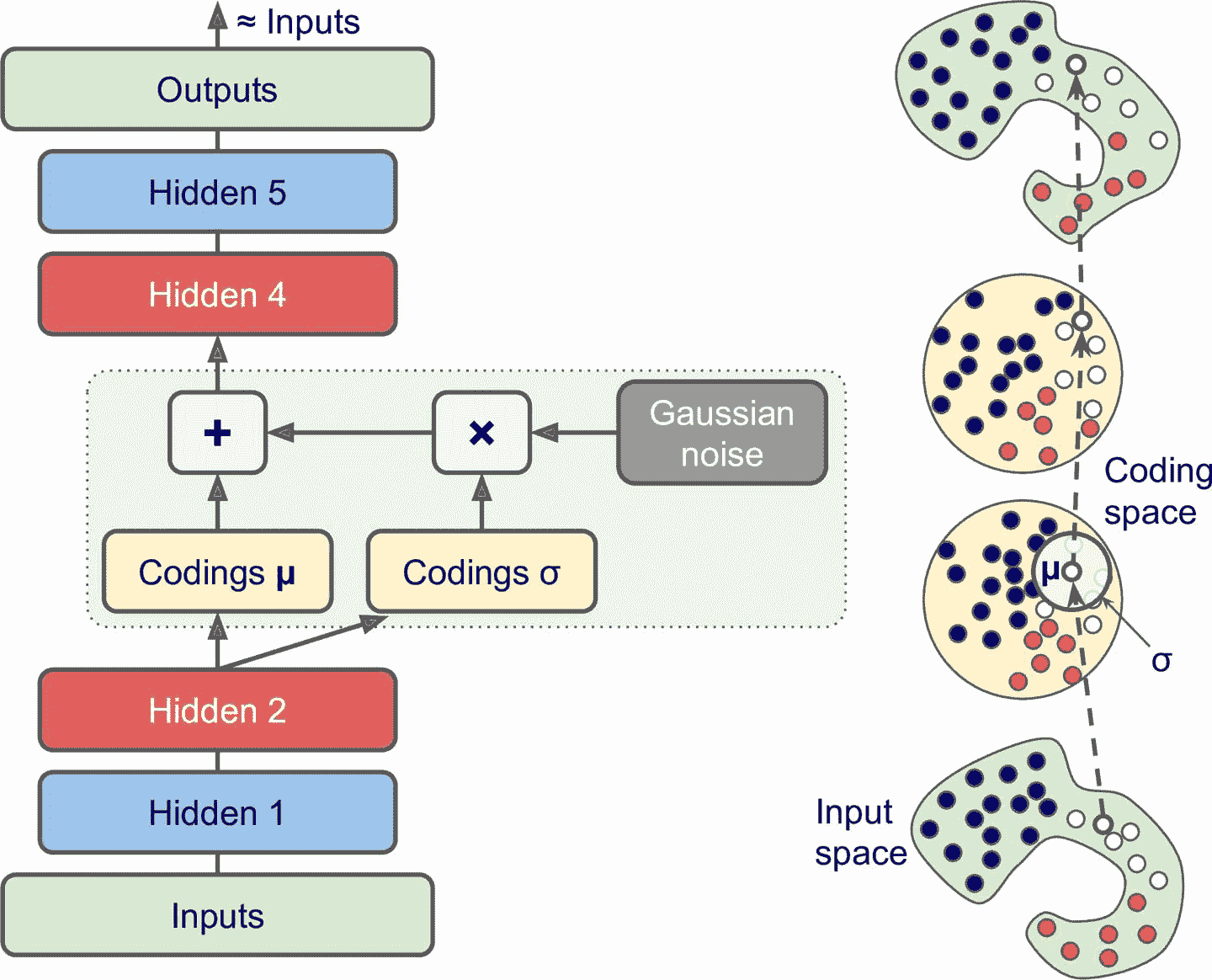
输入可能具有非常复杂的分布,但 VAE 倾向于产生看起来从简单高斯分布采样的编码
训练期间,损失函数推动编码在编码空间(也称为潜在空间)内逐渐迁移,以形成看起来像高斯点集成的云的大致(超)球形区域
损失函数
重建损失,推动自编码器重现其输入(使用交叉熵)
潜在的损失,推动自编码器使编码看起来像是从简单的高斯分布中采样
使用目标分布(高斯分布)与编码实际分布之间的 KL 散度
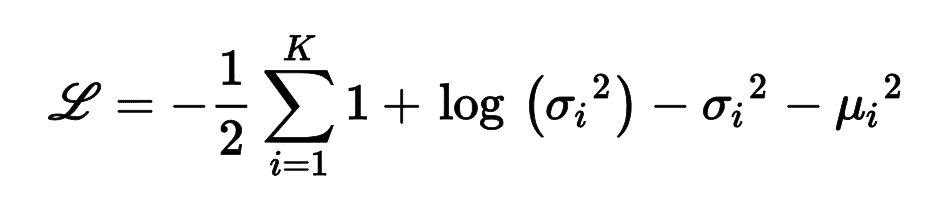
L是潜在损失,n是编码维度,μ[i]和σ[i]是编码的第i个成分的平均值和标准差。向量μ和σ是编码器的输出常见的变体是训练编码器输出
γ= log(σ^2)而不是σ,则潜在损失为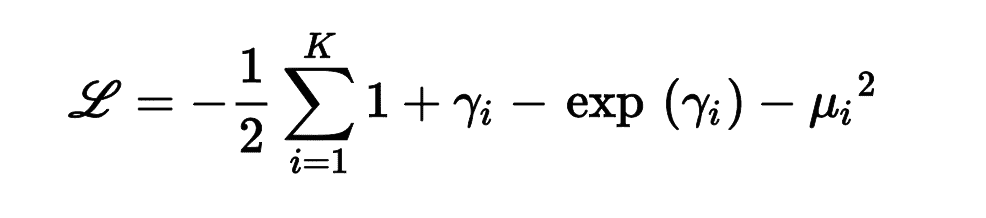
使用变体的例子:
自定义层从编码采样
1
2
3
4class Sampling(keras.layers.Layer):
def call(self, inputs):
mean, log_var = inputs
return K.random_normal(tf.shape(log_var)) * K.exp(log_var / 2) + mean- 接收两个输入:
mean (μ)和log_var (γ) K.random_normal()根据正态分布随机采样向量(形状为γ)
- 接收两个输入:
创建编码器
1
2
3
4
5
6
7
8
9
10
11codings_size = 10
inputs = keras.layers.Input(shape=[28, 28])
z = keras.layers.Flatten()(inputs)
z = keras.layers.Dense(150, activation="selu")(z)
z = keras.layers.Dense(100, activation="selu")(z)
codings_mean = keras.layers.Dense(codings_size)(z) # μ
codings_log_var = keras.layers.Dense(codings_size)(z) # γ
codings = Sampling()([codings_mean, codings_log_var])
variational_encoder = keras.Model(
inputs=[inputs], outputs=[codings_mean, codings_log_var, codings])- 输出
codings_mean(μ)和codings_log_var(γ)的 Dense 层,有同样的输入(即,第二个 Dense 层的输出) codings_mean和codings_log_var传给Sampling层variational_encoder模型有三个输出,可以用来检查codings_mean和codings_log_var的值
- 输出
创建解码器
1
2
3
4
5
6decoder_inputs = keras.layers.Input(shape=[codings_size])
x = keras.layers.Dense(100, activation="selu")(decoder_inputs)
x = keras.layers.Dense(150, activation="selu")(x)
x = keras.layers.Dense(28 * 28, activation="sigmoid")(x)
outputs = keras.layers.Reshape([28, 28])(x)
variational_decoder = keras.Model(inputs=[decoder_inputs], outputs=[outputs])创建变分自编码器
1
2
3_, _, codings = variational_encoder(inputs)
reconstructions = variational_decoder(codings)
variational_ae = keras.Model(inputs=[inputs], outputs=[reconstructions])- 忽略了编码器的前两个输出
编译:必须将潜在损失和重建损失加起
1
2
3
4
5
6
7
8latent_loss = -0.5 * K.sum(
1 + codings_log_var - K.exp(codings_log_var) - K.square(codings_mean),
axis=-1)
variational_ae.add_loss(K.mean(latent_loss) / 784.)
variational_ae.compile(loss="binary_crossentropy", optimizer="rmsprop")
history = variational_ae.fit(X_train, X_train, epochs=50, batch_size=128,
validation_data=[X_valid, X_valid])
变分自编码器流行几年后,被 GAN 超越了,后者可以生成更为真实的图片

