《Hands-on Machine Learning》第二部分阅读笔记(8)GAN
GAN与生成式学习
神经网络互相竞争,让其在竞争中进步
包括两个神经网络
- 生成器:使用随机分布作为输入(通常为高斯分布),并输出一些数据;将随机输入作为生成文件的潜在表征;生成器的作用和变分自编码器中的解码器差不多
- 判别器:从训练集取出一张图片,判断图片是真是假
判别器判断图片的真假,生成器尽力生成看起来像真图的图片
训练迭代:
- 第一阶段:训练判别器。从训练集取样一批真实图片,数量与假图片相同。假图片的标签设为 0,真图片的标签设为 1,判别器用这个有标签的批次训练一次,使用二元交叉熵损失;反向传播在只优化判别器的权重
- 第二阶段:训练生成器。生成器产生另一个批次的假图片,再用判别器来判断图片是真是假,所有标签都设为 1;冻结判别器的权重,反向传播只影响生成器
- 生成器看不到真图,但却逐渐生成出逼真的图片。只是使用了经过判别器返回的梯度
创建生成器和判别器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15codings_size = 30
generator = keras.models.Sequential([
keras.layers.Dense(100, activation="selu", input_shape=[codings_size]),
keras.layers.Dense(150, activation="selu"),
keras.layers.Dense(28 * 28, activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
discriminator = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(150, activation="selu"),
keras.layers.Dense(100, activation="selu"),
keras.layers.Dense(1, activation="sigmoid")
])
gan = keras.models.Sequential([generator, discriminator])编译模型
判别器是一个二元分类器
生成器只能通过 GAN 训练,不需要编译生成器
gan模型是一个二元分类器1
2
3discriminator.compile(loss="binary_crossentropy", optimizer="rmsprop")
discriminator.trainable = False
gan.compile(loss="binary_crossentropy", optimizer="rmsprop")Keras 只有在编译模型时才考虑
trainable属性,在gan模型上调用fit()或train_on_batch(),判别器是不可训练的。但在discriminator调用,则可以训练
自定义训练循环
创建一个
Dataset迭代1
2
3batch_size = 32
dataset = tf.data.Dataset.from_tensor_slices(X_train).shuffle(1000)
dataset = dataset.batch(batch_size, drop_remainder=True).prefetch(1)训练循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def train_gan(gan, dataset, batch_size, codings_size, n_epochs=50):
generator, discriminator = gan.layers
for epoch in range(n_epochs):
for X_batch in dataset:
# phase 1 - training the discriminator
noise = tf.random.normal(shape=[batch_size, codings_size])
generated_images = generator(noise)
X_fake_and_real = tf.concat([generated_images, X_batch], axis=0)
y1 = tf.constant([[0.]] * batch_size + [[1.]] * batch_size)
discriminator.trainable = True
discriminator.train_on_batch(X_fake_and_real, y1)
# phase 2 - training the generator
noise = tf.random.normal(shape=[batch_size, codings_size])
y2 = tf.constant([[1.]] * batch_size)
discriminator.trainable = False
gan.train_on_batch(noise, y2)
train_gan(gan, dataset, batch_size, codings_size)
训练的难点
- 生成器和判别器不断试图超越对方,是一个零和博弈——训练的进行,可能会达成纳什均衡的状态:每个选手都不改变策略,并认为对方也不会改变策略
- 最大的困难是模式坍塌:生成器的输出逐渐变得不丰富,生成器会忘掉如何生成其它类的图片,而判别器唯一能看到的就是单一类别图片,所以判别器也会忘掉如何判断其它类的图片
- 参数可能不断摇摆:训练可能一开始正常,但因为不稳定性,会突然发散
- GAN 会对超参数特别敏感
深度卷积 GAN
DCGAN
- 判别器中用卷积步长,生成器中用转置卷积,不用池化层
- 成器和判别器都使用批归一化,除了生成器的输出层和判别器的输入层
- 去除深层架构中的全连接隐藏层
- 生成器的输出层使用 tanh 激活,其它层使用 ReLU 激活
- 判别器的所有层使用 leaky ReLU 激活
举例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24codings_size = 100
generator = keras.models.Sequential([
keras.layers.Dense(7 * 7 * 128, input_shape=[codings_size]),
keras.layers.Reshape([7, 7, 128]),
keras.layers.BatchNormalization(),
keras.layers.Conv2DTranspose(64, kernel_size=5, strides=2, padding="same",
activation="selu"),
keras.layers.BatchNormalization(),
keras.layers.Conv2DTranspose(1, kernel_size=5, strides=2, padding="same",
activation="tanh")
])
discriminator = keras.models.Sequential([
keras.layers.Conv2D(64, kernel_size=5, strides=2, padding="same",
activation=keras.layers.LeakyReLU(0.2),
input_shape=[28, 28, 1]),
keras.layers.Dropout(0.4),
keras.layers.Conv2D(128, kernel_size=5, strides=2, padding="same",
activation=keras.layers.LeakyReLU(0.2)),
keras.layers.Dropout(0.4),
keras.layers.Flatten(),
keras.layers.Dense(1, activation="sigmoid")
])
gan = keras.models.Sequential([generator, discriminator])使用 DCGAN 生成非常大的图片时,通常是局部逼真,但整体不协调
渐进式放大
- Tero Karras 等人在 2018 年发表了一篇论文,建议在训练时,先从生成小图片开始,然后逐步给生成器和判别器添加卷积层,生成越来越大的图片
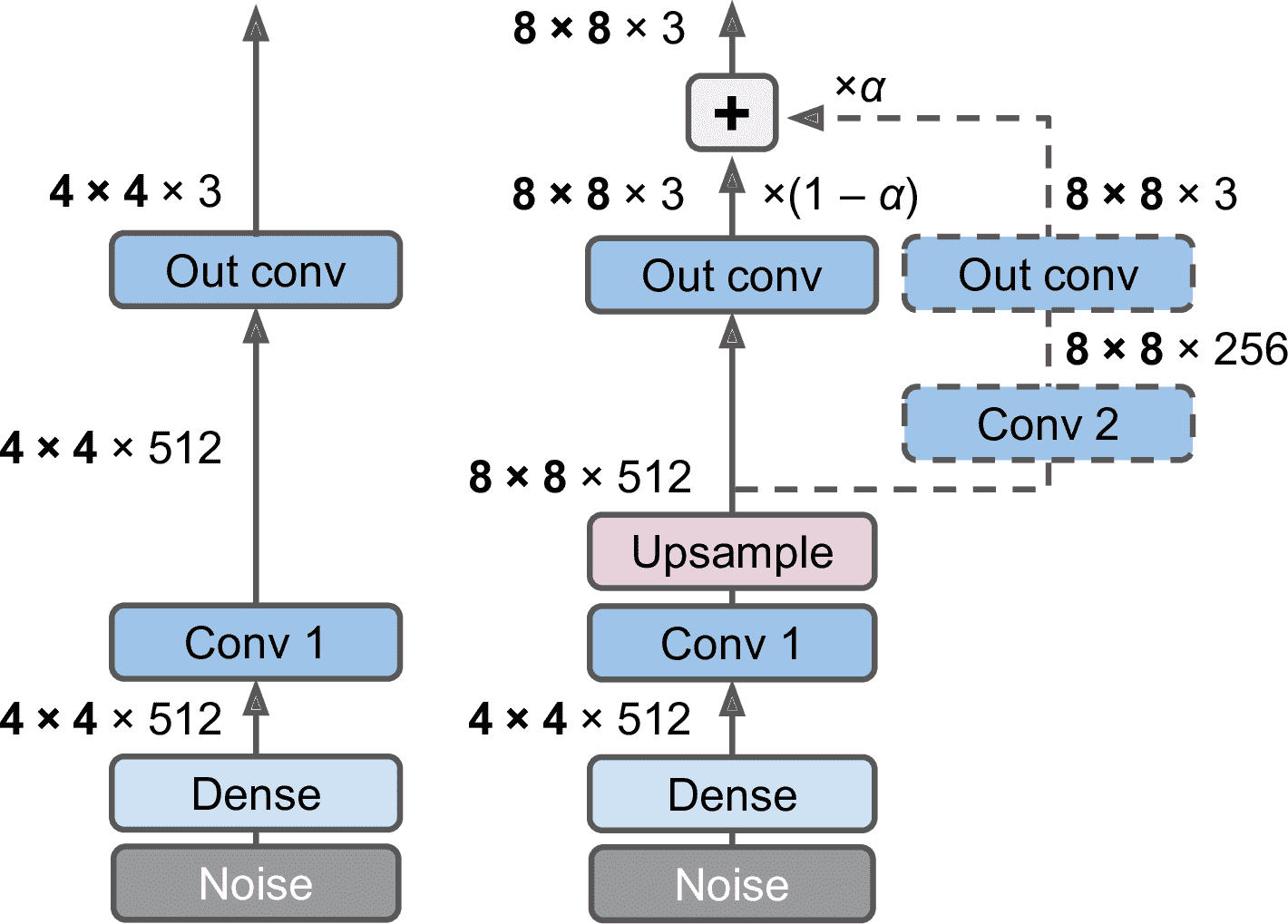
- 加上一个上采样层,传给一个新的卷积层(使用
same填充,步长为 1,输出为8 × 8) - 新输出的权重是
α,原始输出的权重是1-α,α逐渐从 0 变为 1
- 加上一个上采样层,传给一个新的卷积层(使用
- 其他建议:
- 小批次标准差层
- 添加在判别器的靠近末端的位置
- 输入的每个位置,计算批次所有通道所有实例的标准差
- 标准差对所有点做平均,得到一个单值
- 每个实例添加一个额外的特征映射,填入计算得到的单值
S = tf.math.reduce_std(inputs, axis=[0, -1]),v = tf.reduce_mean(S),tf.concat([inputs, tf.fill([batch_size, height, width, 1], v)], axis=-1)
- 相等的学习率
- 使用一个简单的高斯分布(平均值为 0,标准差为 1)初始化权重,而不使用 He 初始化
- 用相同的速度学习
- 像素级归一化层
- 生成器的每个卷积层之后添加
- 归一化每个激活函数,基于相同图片相同位置的所有激活
inputs / tf.sqrt(tf.reduce_mean(tf.square(X), axis=-1, keepdims=True) + 1e-8)
- 小批次标准差层
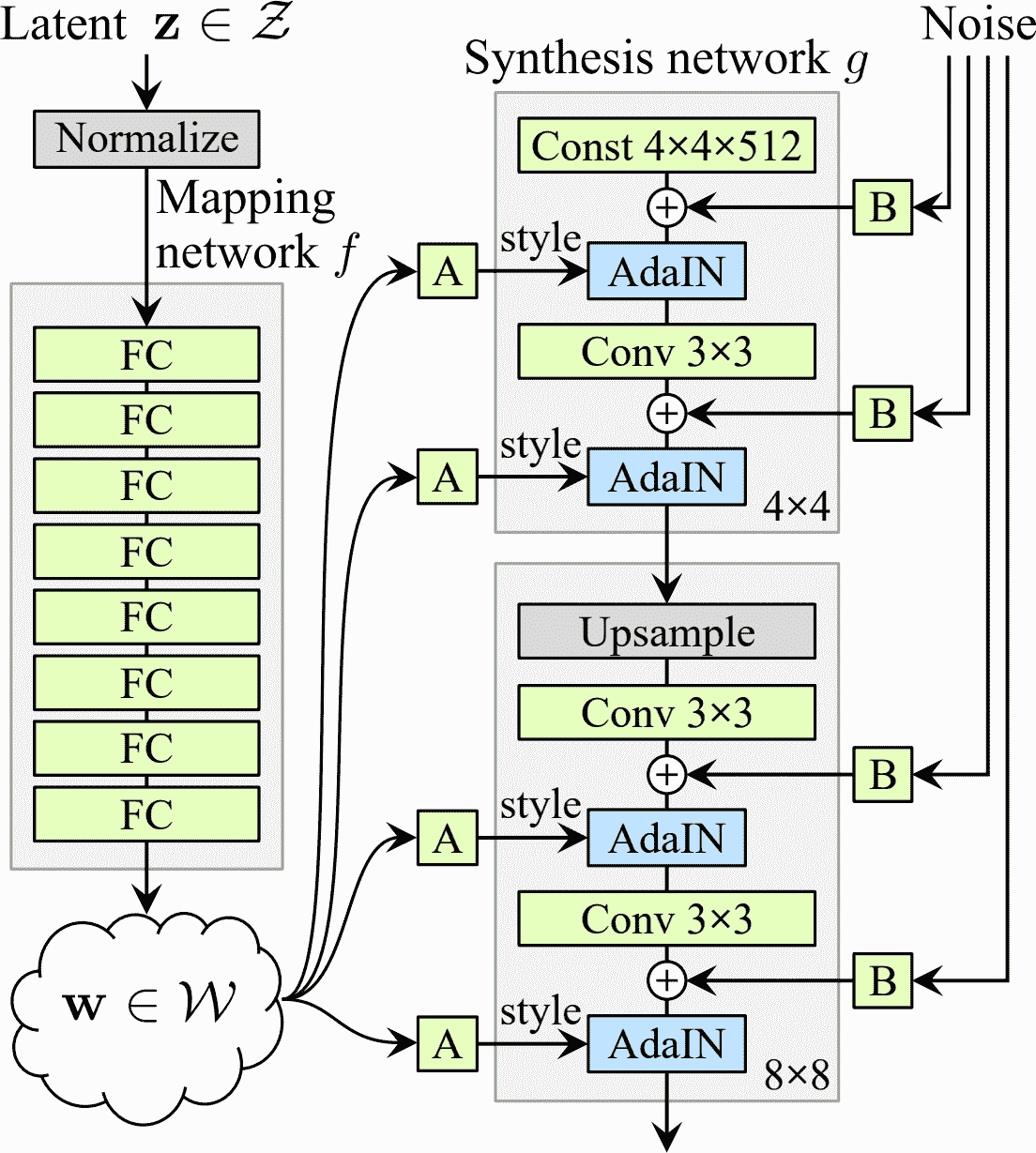
Style GAN
- 2018 年的一篇论文中提出
- 只修改生成器:生成器中使用风格迁移,使生成的图片和训练图片在每个层次,都有相同的局部结构
- 映射网络
- 八层的 MLP,将潜在表征
z(即,编码)映射为向量w,传给仿射变换(没有激活函数的 Dense 层)输出许多向量 - 映射网络将编码变为许多风格向量
- 八层的 MLP,将潜在表征
- 合成网络
- 负责生成图片
- 有一个固定的学好的输入(输入在训练之后不变,但在训练中被反向传播更新)
- 输入和所有卷积层的输出(在激活函数之前)都添加了噪音
- 每个噪音层连接一个适应实例归一化(AdaIN)层——独立标准化每个特征映射
- 使用风格向量确定每个特征映射的缩放和偏移
- 映射网络