《SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient》论文阅读笔记
摘要
作为一种训练生成模型的新方法,生成式对抗网络(GAN)利用判别模型指导生成式模型的训练,在生成连续值的数据方面取得了相当大的成功
当目标是生成离散 token 序列时,它有一定局限性:
- 一个原因在于生成式模型的离散输出使得从判别模型到生成式模型的梯度更新很难实现
- 判别模型只能评估完整的序列,因此对于部分生成的序列,平衡其当前分数和未来分数(整个完整序列)是非常重要的
本文提出了一个序列生成框架 SeqGAN 来解决这些问题
将生成器建模为强化学习(RL)中的随机策略,SeqGAN 通过执行策略梯度更新绕过了生成器差异化问题
RL 奖励信号来自按完整序列判断的 GAN 鉴别器,使用蒙特卡罗搜索传回中间状态-动作步骤
pass back to the intermediate state-action steps using Monte Carlo search
对合成数据和现实世界任务的广泛实验表明,在强基线上有显著改进
介绍
生成模拟真实数据的序列合成数据是无监督学习中的一个重要问题
具有长短期记忆单元(LSTM)的递归神经网络(RNNs)(Hochriter和Schmidhuber 1997)显示了从自然语言生成到手写生成的优异性能(Wen等人,2015;Graves 2013)
训练 RNN 最常见的方法是在给定先前观察到的标记下,最大化训练序列中每个真实标记的对数预测似然性——但如(Bengio等人,2015)中所述,最大似然方法在推理阶段受到所谓的暴露偏差
exposure bias的影响:模型迭代地生成序列,并根据其先前预测的序列——该序列可能没有出现在训练数据——来预测下一个令牌。训练和推理之间的差异随着序列累积产生,并随着长度的增加而更明显- (Bengio等人,2015)提出计划抽样
scheduled sampling - (Husz ar 2015)表明,
scheduled sampling不能从根本上解决问题 - 另一种可能的方案是在整个生成序列上而不是在每个转换上建立损失函数,但特定任务如 chatbot 和 poem generation 的损失可能不能直接用于对生成的序列进行准确评分
- (Bengio等人,2015)提出计划抽样
(Goodfellow, 2014)提出 GAN,但将 GAN 应用于生成序列有两个问题
- GAN 主要生成实值的连续数据,在直接生成离散标记序列(如文本)方面存在困难(Husz ar 2015):在 GAN 中,生成器首先从随机采样开始,然后进行确定性转换。从 D 反向传播到 G 的损失梯度被用来引导 G 更新参数以使生成更真实。如果生成的数据是基于离散标记的,则来自鉴别网的“微小变化”指导意义不大,因为在有限的字典空间中,这种微小变化可能没有相应的标记(Goodfellow 2016)
- GAN 只能给出已经生成的整个序列的得分/损失;对于一个部分生成的序列来说,平衡整个序列的现在和将来的分数是非常重要的
本文为了解决上面的两个问题,沿用(Bachman and Precup 2015; Bahdanau et al. 2016)的方法,并将序列生成过程视为一个序列决策过程
生成模型被视为强化学习
状态是到目前为止生成的 tokens,操作是下一个要生成的 token
需要特定任务的序列分数,如机器翻译中的 BLEU 给出奖励
使用鉴别器评估序列,反馈评估结果指导生成器的学习
将生成模型视为随机参数化策略,以解决梯度回传的问题
regard the generative model as a stochastic parametrized policy
使用蒙特卡罗搜索来近似 state-action 值,通过策略梯度直接训练策略(生成模型),以避免传统算法中离散数据的区分问题
在合成数据的测试中,SeqGAN 的性能明显优于最大似然法
maximum likelihood、计划抽样scheduled sampling和 PG-BLEU;在三个现实任务诗歌生成、语音语言生成和音乐生成,SeqGAN 在包括人类专家判断在内的各种指标上显著优于 baseline
相关工作
- 深度生成模型最近引起了极大的关注,对大型未标记数据的学习能力使得它们有更多的潜力和活力(Salakhutdinov,2009;Bengio等人,2013年)
- (Hinton, Osindero, and Teh 2006)首次提出使用对比散度算法来训练深度信念网(DBN)
- (Bengio等人,2013)提出了去噪自动编码器(DAE),以监督学习的方式学习数据分布
- DBN 和 DAE 为每个数据实例学习低维表示(编码),从解码网络中生成
- 结合深度学习和统计推理的变分自动编码器 VAE 旨在表示潜在隐藏空间中的数据实例(Kingma和Welling 2014),同时利用(深度)神经网络进行非线性映射。
- 以上生成模型都最大化训练数据似然性,但(Goodfellow等人,2014)认为,这种方法难以逼近棘手的概率计算。(Goodfellow等人,2014)提出了一种生成模型的替代训练方法 GAN,其训练过程是生成模型和判别模型之间的极小极大博弈,绕过了最大似然学习的困难,并在自然图像生成方面取得了显著的成功(Denton等人,2015)
- 但 GAN 在序列离散数据生成上没有什么进展,因为生成网络被设计成能够适应连续输出,而不适合离散数据生成
- 递归神经网络用于产生标记序列,如机器翻译(Sutskever、Vinyals、Le 2014;Bahdanau、Cho、Bengio 2014)
- 训练 RNN 最常见的方法是最大化训练数据中每个标记的可能性,而(Bengio等人,2015)指出训练和生成之间的差异使得最大似然估计不是最优,并提出了预定采样策略(SS)
- (Husz ar 2015)理论上认为 SS 的目标函数不合适,并从理论上解释了 GAN 倾向于生成更为自然的样本的原因
- (Bachman and Precup 2015)认为序列数据生成可以被表述为一个序列决策过程,使用强化学习,序列生成器建模为挑选下一个 token 的策略,如果有奖励函数,则可以使用策略梯度优化生成器。
- 对于一些生成任务,奖励信号仅对整个序列有意义,这些情况下可以使用 state-action 评估方法,如蒙特卡罗(树)搜索(Browne et al. 2012)
SeqGAN
SeqGAN via Policy Gradient
序列生成问题的表述:给定真实世界结构化序列的数据集,训练 G 以生成一个序列 $Y_{1:T}$
基于强化学习的阐述:在时间步 $t$ 中,状态 $s$ 对应当前的令牌序列 $(y_1,…,y_{t-1})$,动作 $a$ 是下一个选取的令牌 $y_t$。因此策略模型中当下一个动作确定了,状态转移也确定了
此外还训练一个判别器,用于对 G 的改进给出指导,表示序列来自真实序列的可能性;D 通过提供正例和负例进行训练
G 通过对接收到的来自 D 的 expected end reward 应用策略梯度与蒙特卡洛搜索,进行更新;这个 reward 来自欺骗判别模型的可能性
The generative model G is updated by employing a policy gradient and MC search on the basis of the expected end reward received from the discriminative model D.
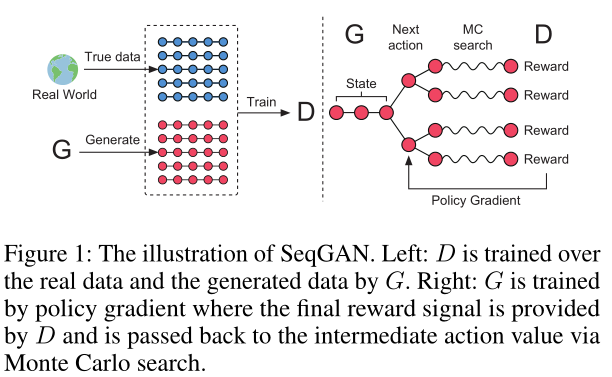

- 用最大似然估计 MLE 在训练集上对 $G_{\theta}$ 预训练,之后生成器、判别器交替训练
- 为了保持平衡,为每个 d 步生成的反例数量与正例数量相同。为了减少估计的可变性,使用不同的负样本集与正样本集相结合
- 具体的推导过程略
序列生成模型
使用递归神经网络作为生成模型
softmax 输出层将隐藏状态映射到输出令牌分布
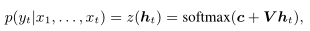
为了处理时间序列反向传播的常见消失和爆炸梯度问题(Goodfellow, Bengio, and Courville 2016),使用 LSTM 神经元
序列判别模型
深度判别模型如深度神经网络、卷积神经网络和递归卷积神经网络,在复杂序列分类任务中表现出较高的性能
本文中,选择 CNN 作为鉴别器,因为CNN最近在文本(令牌序列)分类方面显示出了很好的效果(Zhang and LeCun 2015)
序列首先被表示为 k 维 embed 的结果
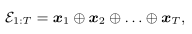
之后输入一个卷积核,以得到新的特征图
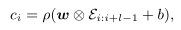
使用 sigmoid 激活的全连接层来输出输入序列是真实的概率。优化目标是最小化真实标签和预测概率之间的交叉熵
合成数据实验
使用随机初始化的 LSTM 作为真实模型,即 Oracle,来生成真实的数据分布 $p(x_t|x_1,…,x_{t-1})$ 进行下面的合成数据实验
评估指标
oracle 提供了训练数据集,并且能够评估生成模型的确切性能,这在真实数据中是不可能的
- MLE 试图最小化真实数据分布 p和模型近似 q $-E_{x∼p}logq(x))$ 之间的交叉熵。但评估生成模型最准确的方法是从中提取一些样本,并让人类观察者根据先验知识进行审查。假设人类观察者已经知道自然分布的精确模型。为了通过图灵测试,实际上需要最小化的平均负对数似然$E_{x∼q}logp_{human}(x)$ (Husz ar 2015)
将 Oracle 视为现实世界问题的人类观察者,因此评估指标是
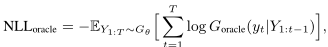
$G_{\theta}$ 生成100,000个序列样本,通过 $G_{oracle}$ 和平均分数计算每个样本的 $NLL_{oracle}$
训练设置
- 按正态分布 $N(0,1)$ 初始化 Oracle 的 LSTM 参数,生成 10000 个长度为 20 的序列作为训练集
- 使用 Dropout 与 L2 正则化
- 每个内核数目在 100 到 $200^4$ 之间
- 对比四个其他模型
- 随机令牌生成
- MLE 训练的 LSTM $G_{\theta}$
scheduled sampling- PG-BLEU
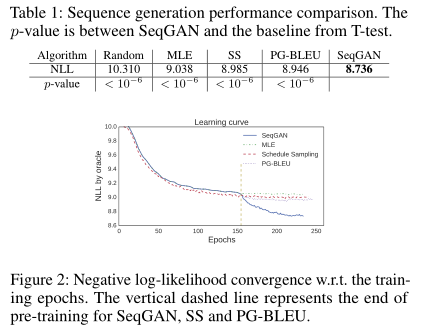
结果
SeqGAN 的表现明显优于其他 baseline
对 $NLL_{oracle}$ 进行显著性 T 检验(
significance T-test)学习曲线体现了 SeqGAN 的优势,在 150 个 epoch 后,SeqGAN 仍然可以继续优化
讨论
- SeqGAN 的稳定性取决于训练方法
- 算法中的 $g$ 步、$d$ 步、$k$ 参数影响极大
- 在分析生成对抗网络的收敛性时,一个重要的假设是允许鉴别器在给定的条件下达到最优。只有鉴别器能够一致地区分真实数据和非自然数据,来自它的监督信号才能有意义,整个对抗训练过程才能稳定有效(Goodfellow and others 2014)
现实场景
文本生成
SeqGAN 生成中文诗歌和奥巴马的政治演讲
使用 16394 首绝句,没有加入任何关于中国诗歌中特殊结构规则的先验知识,如音韵
使用一个语料库,内有 11092 段演讲
使用 BLEU 评分(Papineni等,2002)作为评估标准来衡量生成的文本和人工创建的文本之间的相似度
对于诗歌评价,将 n-gram 设置为 2;对演讲,将 n-gram 分别设置为 3 和 4
混合 20 首真正的诗歌和 20 首分别由 SeqGAN 和 MLE 生成的诗歌,邀请 70 位中国诗歌专家来判断这 60 首诗中的每一首是由人类还是机器创作

音乐生成
- Nottingham 数据集作为训练集
- 使用 88 个数字来表示 88 个音高,对应于钢琴上的 88 个键
- 对每 0.4s 的音高采样,将 midi 文件转换为长度为 32 的从 1 到 88 的数字序列
- 为了测试离散钢琴键模式这一方法是否合适,使用 BLEU 进行评估
- 使用均方误差评估连续音调数据模式是否合适
结论
- 提出了一种序列生成方法 SeqGAN,通过策略梯度有效地训练生成对抗性网络生成结构化序列
- 这是第一个扩展 GAN 以生成离散符号序列的工作
- 在实验中,使用了 Oracle 评估机制来明确说明 SeqGAN 在合成数据上相对于 baseline 的优越性
- 对于诗歌、语音语言和音乐生成这三个真实世界的场景,SeqGan 在生成创造性序列方面表现出了出色的表现
- 还进行了一组实验来研究训练 SeqGAN 的稳健性和稳定性
- 在未来的工作中,计划建立蒙特卡罗树搜索和值网络(Silver, 2016)以改善大规模数据的行动决策
参考文献
Bachman, P ., and Precup, D. 2015. Data generation as sequential decision making. In NIPS, 3249–3257.
Bahdanau, D.; Brakel, P .; Xu, K.; et al. 2016. An actor-critic algorithm for sequence prediction. arXiv:1607.07086.
Bahdanau, D.; Cho, K.; and Bengio, Y . 2014. Neural machine translation by jointly learning to align and translate. arXiv:1409.0473.
Bengio, Y .; Yao, L.; Alain, G.; and Vincent, P . 2013. Generalized denoising auto-encoders as generative models. In NIPS, 899–907.
Bengio, S.; Vinyals, O.; Jaitly, N.; and Shazeer, N. 2015. Scheduled sampling for sequence prediction with recurrent neural networks. In NIPS, 1171–1179.
Browne, C. B.; Powley, E.; Whitehouse, D.; Lucas, S. M.; et al. A survey of monte carlo tree search methods. IEEE TCIAIG 4(1):1–43.
Cho, K.; V an Merri¨ enboer, B.; Gulcehre, C.; et al. 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation. EMNLP.
Denton, E. L.; Chintala, S.; Fergus, R.; et al. 2015. Deep generative image models using a laplacian pyramid of adversarial networks. In NIPS, 1486–1494.
Glynn, P . W. 1990. Likelihood ratio gradient estimation for stochastic systems. Communications of the ACM 33(10):75–84.
Goodfellow, I., et al. 2014. Generative adversarial nets. In NIPS, 2672–2680.
Goodfellow, I.; Bengio, Y .; and Courville, A. 2016. Deep learning. 2015. http://deeplearning.net/tutorial/rnnrbm.html
Goodfellow, I. 2016. Generative adversarial networks for text. http://goo.gl/Wg9DR7.
Graves, A. 2013. Generating sequences with recurrent neural networks. arXiv:1308.0850.
He, J.; Zhou, M.; and Jiang, L. 2012. Generating chinese classical poems with statistical machine translation models. In AAAI.
Hingston, P . 2009. A turing test for computer game bots. IEEE TCIAIG 1(3):169–186.
Hinton, G. E.; Osindero, S.; and Teh, Y .-W. 2006. A fast learning algorithm for deep belief nets. Neural computation 18(7):1527–1554.
Hochreiter, S., and Schmidhuber, J. 1997. Long short-term memory. Neural computation 9(8):1735–1780.
Husz´ ar, F. 2015. How (not) to train your generative model: Scheduled sampling, likelihood, adversary? arXiv:1511.05101.
Kim, Y . 2014. Convolutional neural networks for sentence classification. arXiv:1408.5882.
Kingma, D. P ., and Welling, M. 2014. Auto-encoding variational bayes. ICLR.
Lai, S.; Xu, L.; Liu, K.; and Zhao, J. 2015. Recurrent convolutional neural networks for text classification. In AAAI, 2267–2273.
Manaris, B.; Roos, P .; Machado, P .; et al. 2007. A corpus-based hybrid approach to music analysis and composition. In NCAI, volume 22, 839.
Papineni, K.; Roukos, S.; Ward, T.; and Zhu, W.-J. 2002. Bleu: a method for automatic evaluation of machine translation. In ACL, 311–318.
Quinlan, J. R. 1996. Bagging, boosting, and c4. 5. In AAAI/IAAI, V ol. 1, 725–730.
Salakhutdinov, R. 2009. Learning deep generative models. Ph.D. Dissertation, University of Toronto.
Silver, D.; Huang, A.; Maddison, C. J.; Guez, A.; Sifre, L.; et al. Mastering the game of go with deep neural networks and tree search. Nature 529(7587):484–489.
Srivastava, N.; Hinton, G. E.; Krizhevsky, A.; Sutskever, I.; and Salakhutdinov, R. 2014. Dropout: a simple way to prevent neural networks from overfitting. JMLR 15(1):1929–1958.
Srivastava, R. K.; Greff, K.; and Schmidhuber, J. 2015. Highway networks. arXiv:1505.00387.
Sutskever, I.; Vinyals, O.; and Le, Q. V . 2014. Sequence to sequence learning with neural networks. In NIPS, 3104–3112.
Sutton, R. S.; McAllester, D. A.; Singh, S. P .; Mansour, Y .; et al. Policy gradient methods for reinforcement learning with function approximation. In NIPS, 1057–1063.
V esel` y, K.; Ghoshal, A.; Burget, L.; and Povey, D. 2013. Sequence discriminative training of deep neural networks. In INTERSPEECH, 2345–2349.
Wen, T.-H.; Gasic, M.; Mrksic, N.; Su, P .-H.; V andyke, D.; and Young, S. 2015. Semantically conditioned LSTM-based natural language generation for spoken dialogue systems. arXiv:1508.01745.
Williams, R. J. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning 8(3-4):229–256.
Yi, X.; Li, R.; and Sun, M. 2016. Generating chinese classical poems with RNN encoder-decoder. arXiv:1604.01537.
Zhang, X., and Lapata, M. 2014. Chinese poetry generation with recurrent neural networks. In EMNLP, 670–680.
Zhang, X., and LeCun, Y . 2015. Text understanding from scratch. arXiv:1502.01710.

