《An Efficient Algorithm for Anomaly Detection in Wireless Sensor Networks》 阅读笔记
摘要
在过去的几年里,WSN 得到了极大的关注
WSN 设备由于其高密度使用而暴露于攻击中,而与正常行为严重偏离的传感器读数是不准确和不可靠的。这些异常数据被认为是异常数据
异常值的识别不当会导致数据不准确和高能耗
为了检测离群点并提高精度,提出了一种两阶段算法
- 聚类技术描述了训练阶段传感器数据的分组(微聚类,合并)
- 基于密度的离群点检测技术,来检测异常点
实验结果表明,该方法准确率为 99.56%,虚警率低
介绍
- 近年来,WSN 在开发不同的应用方面发挥了重要作用,并因其复杂和多方面的先决条件而吸引了分析人员的注意
- WSN 由间隔很远的传感器组成,这些传感器的电池功率有限,可以检查和记录不同的自然条件,如压力、湿度、强度等
- 由于某些恶意攻击、降低的电池消耗和错误,数据的测量可以不同于其原始模式——异常值。异常值是与数据的其余部分有很大差异的数据实例
WSN 中的问题
- WSN 面临的主要挑战是通过降低能耗和提高数据准确性来延长网络寿命
- 能量:能量在信息分类、信息处理和信息传输中被消耗。节点进行稳定的活动需要节点组件消耗大量的能量。能量规划、硬件的执行是 WSN 分析师面临的最关键的研究挑战【6】
- 安全:错误信息的发生几率很大。每个传感器节点和基站都应该有能力确认接收到的数据确实是由可信的发送者发送的
- 部署:传感器网络的大量部署导致网络堵塞,这是由于少数传感器节点发出大量的干扰信号。静态部署根据优化策略选择最佳位置,而动态部署为了优化而任意丢弃节点【9】
当前系统局限性
- 由于资源和计算的限制,为现有的传感器网络提供安全性是一项令人担忧的工作
- 现有网络部署在更远的距离,增加物理攻击的风险,并可能暴露其漏洞
- 另一个限制为障碍物对信号的阻挡——信号的最终强度取决于位置
- 更换耗尽能量的传感器是很困难的,这导致整个网络的吞吐量降低
无线网络集群
- 为了提高网络运行的效率,采用分簇技术,缩小大型平面传感器网络的规模
- 传感器节点被安排在称为集群的特定组中,每一个簇都包括 m 个被称为簇成员的节点(CM)和一个被称为簇头的特殊节点(CH)【11】
- 加入和合并包含在单个集合中的信息,最佳方法称为基于集群的数据聚合
WSN 数据聚合
- 收集和聚合有意义信息的过程称为数据聚合
- WSN 中数据聚合是节约受限资源的一种方式。WSN 限制了计算能力、电池功率,这导致应用程序设计的复杂性,并经常在与网络协议紧密耦合的应用程序中出现问题【12】
- 数据聚合的工作原理:
- 选择节点并将其划分为簇
- 簇可以满足预期的参数条件,包括 RSSI、TTL、MRIC、数据传输、电池利用率等,这些参数决定簇中节点数目
- 为每个簇的所有节点选择一个簇头 CH,负责组织簇内的节点,从簇的节点收集数据,将数据移动到相邻的 CH,以进行更多的数据交换和更新
- 通过数据立方体方法【13】累积信息,将聚集的信息移动到基站以供附加使用
WSN 异常检测
- 离群值或异常值是一种明显偏离其余数据的对象
- 离群值是在考虑约束总体时不具有共同行为的感知结果
- 与给定标准或普通数据集类型严重偏离的一点信息被视为异常值
- 异常值分为全局异常值、环境异常值和集体异常值
- 给定的数据集中,如果一个对象与数据集的其他部分偏离很大,则为全局异常值
- 某些情况下,全局异常值也称为点异常值,是异常值中最不复杂的类型
- 在特定的环境或条件下,个别信息出现的可能性很小,被称为环境异常值
- 集体异常值定义为与整个数据集显著偏离的对象或数据实例,而不是单个数据对象
相关工作
用于检测异常值的最早算法之一是统计方法【14】
- 假设信息遵循参数分布
- 统计模型可以用一个属性来处理大多数异常值【15】,而在其他一些情况下,可以用多个属性来处理多达 k<4 的数据能力
用于处理大数据应用的节能且安全的路由协议【19】
- 有助于根据应用程序的重要性对其进行优先排序,有助于满足大数据场景中的所有要求,如网络延迟、路由开销和延迟
- 安全路由协议是一个完整的过程,分为三个步骤,即路径识别、通知传输和路径维护
【1】提出蚁群聚类算法——基于密度的快速聚类——对动态数据流进行聚类
- 形成由低密度区域分隔的高密度区域
- 粗略的聚类是在一次通过一个窗口的过程中形成的,并且使用一个旋转的窗口模型来读取流
- 它结合了求和与聚类,只需要四个参数
- 具有单个点的聚类被认为是异常值
【7】定义了基于聚类的方法是最流行的方法,不需要信息传播的先验知识
- 任何一个聚类偏离度很大或者比其他聚类小,并且如果任何数据实例不属于任何一个聚类,那么它们就被识别为异常值
- 来自数据集的信息首先被分成簇。在每个簇中,数据点被批准为自由度【16】(In each cluster the data point is
approved as a degree of the membership)
【20】研究 WSN,使用压缩感知和信任感知提供更好的安全性并减少消息开销
- 协议可以分为基于分层或基于平面的路由
- 主要目的是增加路径的可信度,减少消息数和跳数以及传送距离
【17、18】提出一种通用的方法。随着深度学习网络的发展,许多分析人员希望利用它们来分离信息中隐藏的特征
异常检测解决方案可分为两类
- 监督异常检测
- 无监督异常检测
方法
- 两个阶段:加载、合并数据形成簇,之后孤立点检测
- 首先识别每一个簇,每个簇包含 L 个数据点形成$\vec{W_i}$,使用线性和(LS)、平方和(SS)计算簇的半径 r 和中心 o,LS 和 SS 均为 d 维向量,维度是一个节点中的特征数
- $LS = \sum_{i=1}^L{\vec{W_i}}$
- $SS=\sum_{i=1}^L{\vec{W_i}^2}$
- $r = \sqrt{\frac{SS}{L}-(\frac{LS}{L}})^2$
- $o=\frac{LS}{L}$
- 一个点$l$可以加入一个簇$\mu$,当将点加入簇后$radius(\mu)<\epsilon$
- 两个簇可以合并为一个簇$\mu=(L_i+L_j,LS_i+LS_j,SS_i+SS_j)$,当合并后$radius(\mu)<\epsilon$
识别簇
加载数据,预处理以去除遗漏属性值
分组
经过分组,第一个簇被建立,每个节点都是一个 CH
$Suitability(d_j,M_i)=\frac{\sum_{k=0}^ndist(d_j,m_{ik})}{n}$,其中 n 为$M_i$中的 n 个采样
检查每个簇,节点被包含在最合适的一个,参数$\epsilon$取决于簇的最大半径
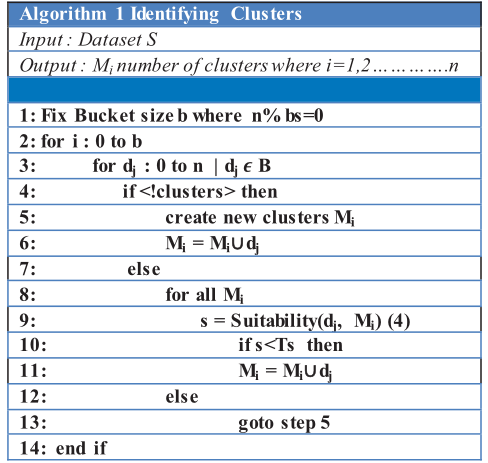
合并
簇中每个数据点被视为微簇,半径为 0
每个微簇一开始与其他微簇合并在同一个簇下,但需要和其他微簇对比,如果合并后的半径小于$\epsilon$,说明合并后更好

最终聚类与异常点检测


- 随机选择一个微簇,同其他 n 个同一簇下的微簇对比
- 计算密度:$Reach(o_{ui},o_{uj})\le w$,其中$o_{ui}、o_{uj}$为微簇的中心,若满足此关系,则密度可获得(density obtainable)
- 计算选择概率$ProbPick=1-(obtainable/n)$
- 若此概率小于阈值,则微簇将和相邻簇合并
实验和结论
数据集
- IBRL 数据集
- 包含从位于英特尔伯克利研究实验室的 54 个传感器中收集的数据,数据以时间戳的方式被收集,其中每 31s 收集一次信息
- 主要含有四个属性:湿度,温度,光线和电压
评估方式
- 混淆矩阵评估
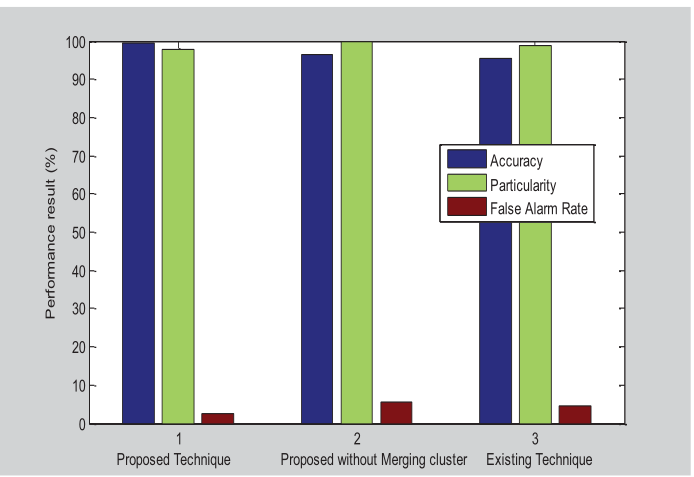
结果
总结
- 本文提出了一种自然启发算法,用于找到异常值
- 首先,形成初始集群,并且每个群集都被拆分以形成不同的微簇,以便在找到异常值时获得更高的准确性
- 群集中的每个数据点被认为是微簇,通过计算不同微簇之间的适用性来执行合并操
- 异常值检测算法基于PICK-N-DROP方法,有助于解体较小的聚类并将其内容融为最合适的集群
- 实验结果表明,具有 99.56% 的精度和较少的误报率

