《Stealing Passwords by Observing Hands Movement》(TIFS CCF A类)2019
摘要
- 本文提出了一种基于视频的侧信道攻击,来破译移动设备上的密码
- 使用5到10秒的短视频,从远处不引人注目地拍摄,不需要手机的键盘或屏幕可见
- 通过将用户在打字过程中手的时空移动与手机任何可见部分上的锚点联系起来,可以高精度地预测输入的密码
- Galaxy S4手机上375个密码输入过程短视频数据集的结果显示,与随机猜测相比,搜索空间呈指数级缩减——每个字符对应的实际按键,可以将搜索空间减少到平均2-3个猜测按键
介绍
分析手机打字时手部运动的潜在动态特征来预测密码
系统组件包括视频剪辑(video clip)组件,在手机和打字手的任何可见部分提供锚点
预测按键簇的准确率高达94%,每个簇代表键盘上5-6个空间上接近的键
利用分析视频帧获得的键盘状态转换概率和手指在按键之间的转移时间,可以正确识别密码中70%的字符:
手机键盘的几何形状设计固定,因此可以估计键盘的位置、长度和宽度来定位视频中的键盘,通过简单几何变换将视频中的这些尺寸与键盘的实际物理尺寸(已知)相关联
分析键入字符的思路:当键入一个字符时,手移动得更靠近键盘,键入后手就离开
The cues to deciphering the characters typed include the observations that the hand moves closer to the keyboard when pressing a key and moves away just after that.
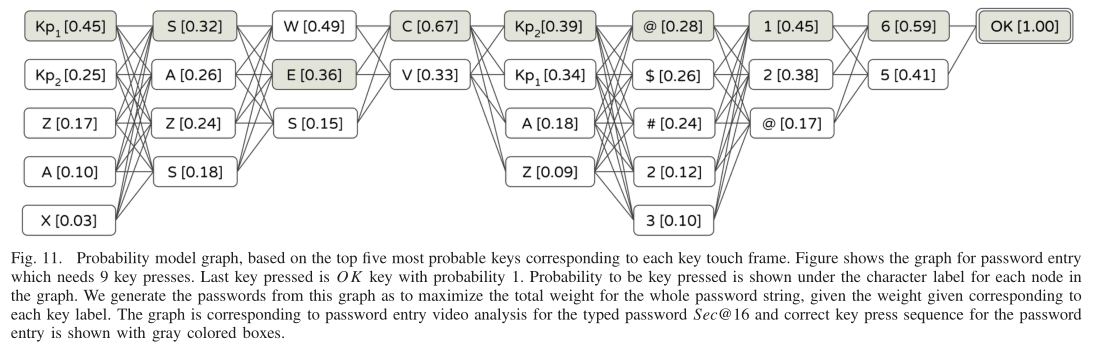
任何字符都可以表示一系列按键,例如要输入密码Sec@16,用户将按下:Shift→S→e→c→数字键→@→1→6。Shift将键盘状态从小写字母更改为大写字母,数字键将状态从字母转换为数字
本文是第一个仅根据观察到的手部动作来预测密码的工作
- 根据剪辑视频中记录的手部动作解码用户密码,以不会引起用户任何怀疑的方式执行
- 使用用户键入密码时手部动态的视频记录数据集,本文的攻击能够破解平均超过70%的密码字符
- 用户坚信,在公共场所输入密码时覆盖屏幕足以保护密码免受攻击,本文的发现与之相反,因为研究中的所有视频都没有屏幕可见的部分
相关工作
- 与本文密切相关的一项工作为[6](即2014的CCS)
- 该攻击记录用户的手部动作,适用于数字pin
- 密码或文本输入的键盘更为复杂,且按键位置接近,键盘状态会从字符变为数字和特殊字符,[6]的攻击会失败
- 差异:本文考虑了攻击中的键盘状态转换;本文通过每一帧观察到打字手的某一点的位置,来估计指尖移动;本文提出的攻击不只依赖于跟踪打字的手上的一个点,而是采取多个点来跟踪和融合跟踪的结果,来更好估计手部运动;本文构建密码语言模型,以在用户密码中出现词汇模式的情况下获得更好的预测
- Xu等人[7]的工作(见上一个博客中的相关工作)
- Ye等人的攻击[8]利用用户手机屏幕的视频记录,来攻击pattern lock。他们的攻击在前五次尝试中可以重建超过95%的图形模式
- Chen的工作[9]展示了一种自动攻击,通过用户打字时屏幕的视频记录,快速推断手机屏幕上的数字输入
- Balzarotti等人[13]的攻击需要使用用户在桌面键盘上打字的视频记录——摄像机直接指向键盘
- Maggiet等人[14]的攻击使用用户在智能手机屏幕上打字时的视频记录,摄像机需要直接指向屏幕。他们训练一个分类器,以根据字符放大显示的外观来确定视频记录流中键入的字符
- Asonov和Agrawal[18]利用从受害者收集的样本训练的神经网络,声学键盘辐射可以用来检索打字文本,准确率接近80%
- Zhuang等人[19]改进了[18],取消了训练过程
- 有一系列工作探索了手机上传感器数据带来的漏洞
攻击细节
图2显示了密码破解的每个步骤

拍摄键入密码时手部动作的视频——假设手的运动和手机背面的一部分在剪辑视频上是可见的
预处理录制视频,只保留密码输入过程。逐帧观察录制的视频,剪切在视频开始和结束时捕获的额外部分,仅保留密码输入部分。不需要非常精确,但额外帧的数量越少,后续步骤中的处理就越少
使用TLD跟踪工具[29,30]跟踪手机可见部分上的锚点和手部的锚点。攻击者手动选择手和手机的锚点,通过跟踪每一帧中手机锚点和手锚点的位置,计算手锚点相对于手机锚点的相对位置
给定手锚点、手某些可见部分的移动,估计用户手的隐藏部分的形状和大小。通过以上的估计值,估计用户的指尖移动
检测关键触摸帧。计算对应于指尖的图像的速度,找到速度为0的帧。帧来自连续帧序列,帧序列按顺序排列为:$P,Z…Z,N$,其中$P$为正速度,$Z$为速度0,$N$为负速度(image velocity)
在关键触摸帧中找到之间。假设最后一次按键内容为确认键,给出指尖的估计移动、确认键的已知位置,回溯键盘上的轨迹(类似于2014年的那个CCS)
根据先前的按键和从密码数据集计算的概率,确定键盘状态
利用来自确定的触摸位置和键盘状态信息,建立一个基于概率的密码模型,识别触摸的按键。若跟踪点的位置正确,则可以将搜索空间减少到每个触摸帧只有2-3个按键可能
Step 1-获得视频
- 用户的手部动作和手机的一部分是可见的
- 收集用户输入密码的视频,以评估本文攻击模型的性能;还使用一个大的密码集来构建基于概率的模型
- 数据集:
- UNIQPASS v15密码集用于构建Step7和Step8中的基于概率的模型
- 超过200万个唯一的ASCII密码以随机顺序存储
- 本文据此创建两个互斥的子列表(列表I和列表II),密码长度在4-15之间,分别有60万和10万个密码
- 录制了密码输入过程的视频数据集
- 训练集:10名志愿者的20个视频
- 测试集:45名志愿者的135个视频
- 三个摄像头来记录视频——HTC One手机摄像头、索尼摄像机和iPhone 6 plus摄像头——使用各种规格的摄像机来不同的攻击者,iPhone 6 plus:使用的高端手机摄像头具有相当好的分辨率和高帧率的视频录制;HTC One:基本手机摄像头;索尼摄像机:使用具有光学变焦功能和高分辨率的录像机的攻击者
- UNIQPASS v15密码集用于构建Step7和Step8中的基于概率的模型
- 密码输入过程和视频录制:
- 志愿者从列表II中随机选择一个密码,在Galaxy S4上练习输入密码直到习惯——平均需要10-15次练习
- 录制了一些用户坐着、另一些用户站着的场景;录制了实验室内输入密码、住宅内外输入密码
- 在距离参与者约4-5米的地方录制
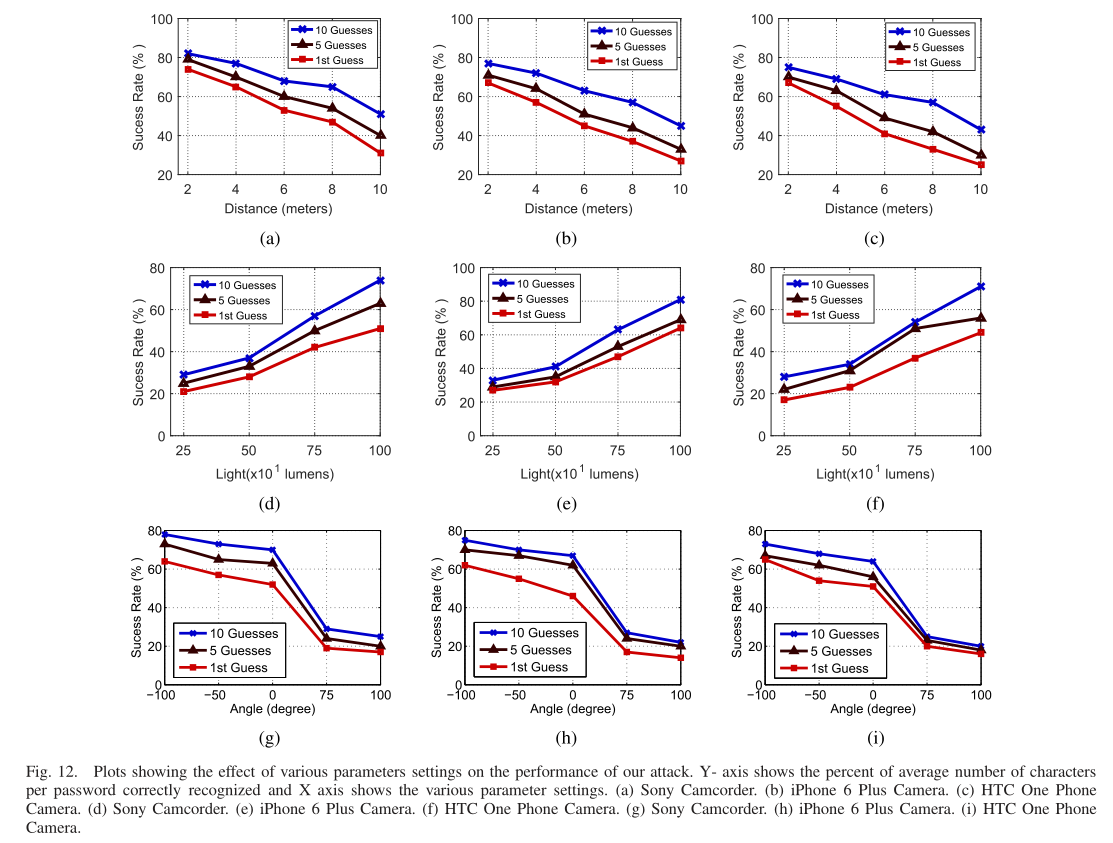
- 分析参数设置效果的视频数据集:
- 为分析参数设置对攻击模型的影响,为5个不同用户各录制42个视频,
- 15个视频:三种不同的摄像机配置,每个摄像机配置用于五个不同的录制距离——2米、4米、6米、8米、10米
- 12个视频:三种不同的摄像机配置,用于四种不同的照明条件——250、500、750、1000(单位lumens)
- 15个视频:三种不同的摄像机配置,五个不同的录制角度:-100度、-50度、0度、+50度、+100度。角度为用户视线和相机的视角方向的负向之间的角度
Step 2-视频预处理
- 给定5到10秒的密码输入视频
- 观察用户与移动电话的交互识别视频片段中密码输入的部分——假设使用电话过程中,用户首先输入密码
- 剪切和删除不需要的部分
- 剪辑后的视频片段包含密码输入过程前后200-300毫秒的记录
- 剪辑视频输入视频编辑器中提取帧
- 索尼和HTC One的视频,平均每个视频生成120帧;iPhone的平均每个视频生成1000帧
Step 3-手和手机两个锚点的跟踪
- 使用TLD跟踪视频中用户的手和手机上的锚点(具体介绍见上一篇博客,2014的CCS)
- 跟踪整个视频中可见的一个手机锚点,该点可以出现在手机任何地方
- 跟踪视频中用户手上的五个不同锚点,锚点的标准满足:
- 锚点一直可见
- 应该尽可能靠近手机或打字手指
- 跟踪手上的多个点,并合并结果,以最小化跟踪误差——对于给定的帧,如果超过10%的帧的跟踪置信度小于设定的阈值,则选择另一个点,并对该特定视频重新执行整个跟踪操作(跟踪置信度阈值设置为0.5)
- 简单地通过手机锚点的像素位置减去手锚点的像素位置,来计算手锚点在手机锚点参考系的相对运动
Step 4-估计指尖的移动
用户的手指首先向屏幕移动,停留,然后在键入后离开触摸屏——手的其余部分也遵循类似的运动行为,由此建立指尖运动和锚点运动的联系
建立一个手部运动模型,作为用户输入密码时手部运动的近似
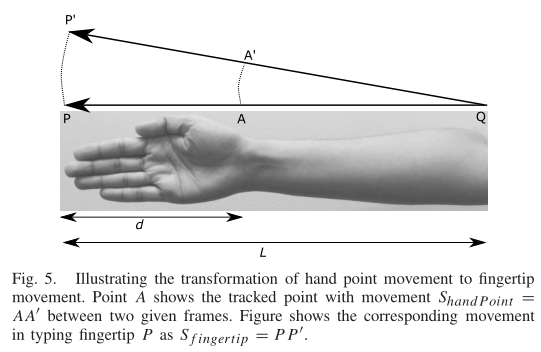
- 给定被跟踪点的移动轨迹$S_{handPoint}=AA’$
- 应用相似三角形的规则,得到$S_{fingertip}=PP’$的关系:$S_{fingertip}/S_{handPoint}=PP’/AA’=PQ/AQ=L/(L-d)$
- 其中$L$作为手的长度,可以使用视频中手的可见部分来估计(小臂长度一般为手掌长度的1.6倍)
Step 5-确定按键帧
根据上一步指尖运动的估计,可以计算对应于指尖点的图像速度(视频片段中两个连续帧之间指尖点的像素移动)
寻找连续帧的序列,这些帧按顺序具有正、零和负图像速度。零速度帧表示按键事件发生,因此将这一组帧记为$F_i$
如上文所述,选择了5个手锚点,因此会产生五组非互斥的按键帧:$F_1,F_2,F_3,F_4,F_5$——合并为$F_{candidate}$,合并过程为:
- 任何组中两个最远帧之间的距离必须小于设置的阈值$Th_{max}$
- 两个不同组中最接近的两帧之间的距离必须大于设定的阈值$Th_{min}$
在这一步中,如果被跟踪的锚点没有检测到一个按键帧(假阴性),该按键帧可以通过其他锚点检测到。如果一个帧错误(误报)检测为按键帧,它不会出现在其他锚点检测结果中
从候选按键帧集合中移除那些帧数小于设定阈值$Th_{frames}$的帧组,最终形成一个新的集合$F_{keyTouch}$,其中元素为相应集合的中位数——一组的所有帧代表一个按键事件,因此每组一帧足以创建按键帧集合
例如:

形成7个集合:
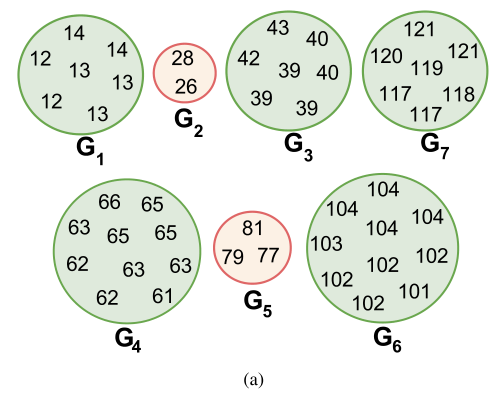
集合$G_2$和$G_5$中的帧数过少,因此排除掉
最终的按键帧为:$F_{keyTouch}={13,40,63,102,119}$
阈值的选择:
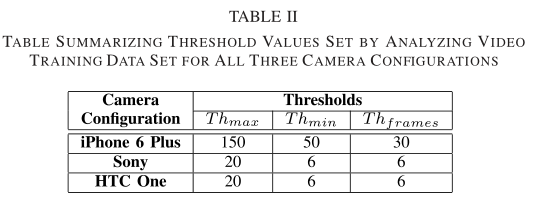
- 逐帧观察的方式,从20个视频(训练集)手动提取按键帧
- 计算两个按键帧之间的差,绘制累积分布函数,得到$Th_{max}$和$Th_{min}$
- $Th_{frames}$根据训练集做
empirical analysis得到
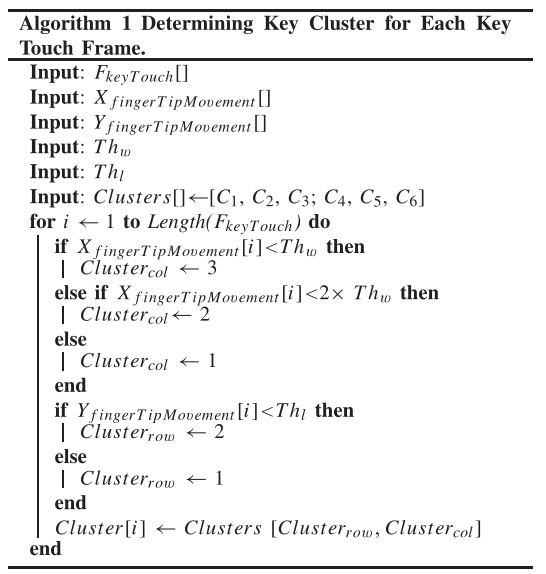
Step 6-估计触摸的位置(簇)
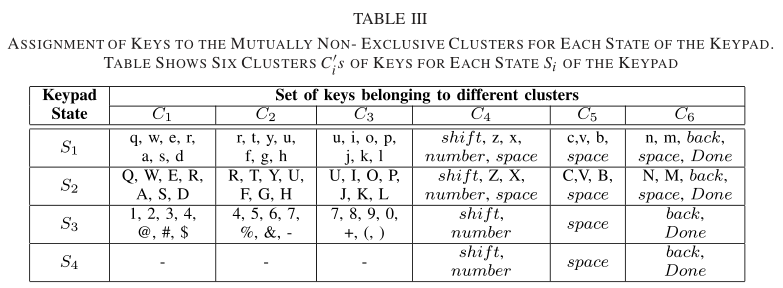

- 对于按键帧列表$F_{keyTouch}$的每一帧,将指尖位置映射到键盘上触摸的实际位置
- 将键盘屏幕划分为非互斥的按键簇,如表三所示(根据几何距离划分)——其中$S_4$只有三个簇,因为其余三个簇对应的字符不能出现在密码中
- 图8显示了键盘的四种不同状态,a代表键盘的默认状态,所有键都是小写的
- 将指尖位置映射到特定的按键簇:
- $F_{keyTouch}$:n个按键帧;$(x_1,y_1),…,(x_n,y_n)$相应的指尖相对像素位置(原本为手部锚点,通过Step 4得到指尖估计位置)
- 计算指尖在帧$f_i$到帧$f_j$的移动:$X_{fingerTipMovement_{ij}}=x_i-x_j$,y坐标类似
- 依次计算$f_i$和$f_n$的移动($f_n$为确认键对应的帧,由于确认键的物理位置已知,因此可以据此获得其他帧的映射结果,类似于上一篇博客中的映射过程)
- 计算放大率:根据视频中的手机宽度和实际手机宽度,计算放大率
- 基于放大率估计视频中键盘的尺寸。视频中键盘的宽度和长度为:$w_{keypad}=magnification\times actualWidth$、$l_{keypad}=magnification\times actualLength$,设置$Th_w$和$Th_l$为$w_{keypad}/3$和$l_{keypad}/2$——先前将键盘分割为3*2的簇
- 根据确认键的映射关系,为每个按键帧分配簇的位置(利用先前计算的帧之间的移动幅度)
- 具体过程如算法1所示
Step 7-确定键盘状态
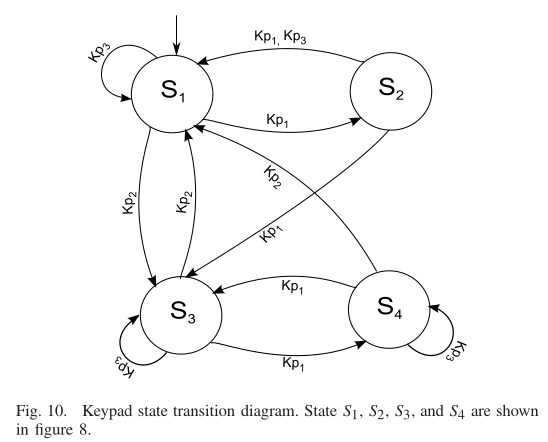
状态转移图:
键盘状态根据用户触摸的按键,从一个状态转为另一个状态
$S_1$表示小写键盘,$S_2$表示大写键盘,$S_3$表示带数字的键盘,$S_4$表示带特殊符号的键盘
定义三种按键事件:$K_{p1}$为按下Shift键,在$S_1$$S_2$、$S_3$$S_4$之间转换;$K_{p2}$为按下num键,在字母和数字之间转换;$K_{p3}$为按下其他键
图10为状态转移图
Step 8-识别触摸的按键(具体按键)
由上,每个按键帧都分配到了一个按键簇,需要计算每个按键成为用户实际触摸按键的概率
根据列表I来设计概率模型。假如有一个n字符的密码(n个按键帧):
最后一个按键为确认键,因此:
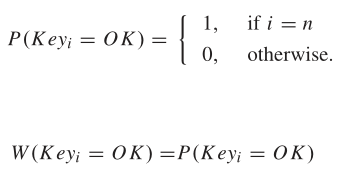
按键$A_j$为用户在第$i$个按键帧触摸的按键的概率为$p_i(A_j)$:
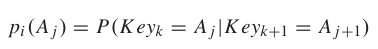
- $Key_k$为第k帧按下的键,$A_j\in C_i$
- 选择概率前5的结果作为候选按键
根据每个按键帧的前5候选按键构建一张图。图11为Sec@16的例子
性能评估
按键帧检测
- 攻击模型中的一个主要步骤是检测按键帧
- 攻击模型能在99.7%的情况下正确识别按键帧,假阳性率为1.6%,假阴性率为0.3%
按键簇预测
- 键簇预测的平均精度为97.15%
- 索尼摄像机的键簇预测平均精度为94.42%
Shift和Num键预测

字符预测精度
- 使用135个密码输入视频的测试数据集,使用iPhone 6 plus相机在10次猜测中实现了每个密码的70.9%字符预测精度;使用索尼摄像机和HTC One手机拍摄的视频,68.4%和66.0%
不同配置的影响
结论
- 通过分析视频片段中的手部动作,展示预测密码的可行性
- 在公共场所使用智能手机存在严重的安全性隐患

