《Hand Me Your PIN! Inferring ATM PINs of Users Typing with a Covered Hand》(2022 USENIX)
摘要
- 攻击场景:ATM机取款时拍摄视频
- 本文提出了一种新的攻击方法,重建受害者的PIN(用户输入PIN时,用另一只手覆盖打字手)
- 攻击使用深度学习架构,从打字手的位置和动作推断个人识别码
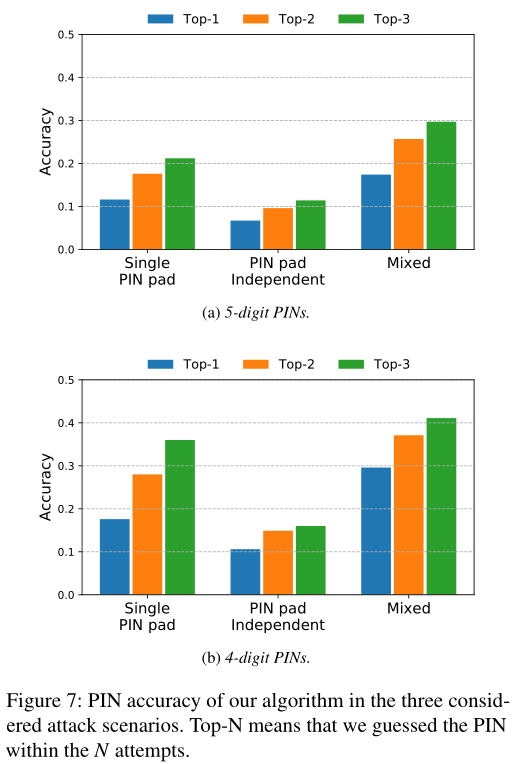
- 运行一个包含58个用户的详细实验,可以在三次尝试中猜出30%的5位数PINs
- 对78名用户进行了一项调查,在相同的设置下,平均准确率仅为7.92%
- 本文最后评估了一种屏蔽对策,该对策被证明是相当低效的
介绍
虽然自动取款机和PoS设备被广泛使用,但许多人并不认为除了通常提到的安全风险和防御措施之外还有其他安全风险和防御措施
- 在打字时隐藏个人识别码
- 确保没有人观看屏幕
为了减轻肩部冲浪攻击(
shoulder surfing attacks),ISO 9564-1标准指出:PIN数字不得显示在屏幕上、反馈声音的持续时间和类型对于每个按键必须相同本文使用深度学习方法进行攻击——攻击者可以访问与受害者使用的个人识别码相同或相似的个人识别码,为此构建一个分析模型,预测在目标设备上输入了什么数字
贡献:
- 提出一种新的攻击来从视频中推断PIN。
- 攻击可以在三次尝试内重建30%的5位数PIN和41%的4位数PIN
- 收集了5800个5位数PIN的视频(58个志愿者将PIN输入模拟ATM)
- 进行了一项研究,评估人类从视频中推断覆盖PIN的准确性——本文攻击性能优于人类,在三次尝试中,重建5位数PIN的性能提高了四倍
- 对覆盖PIN输入板时的攻击性能进行了分析(覆盖25%、50%、75%和100%),表明即使覆盖PIN输入板,攻击也是可能成功的
攻击模型
- ATM配有PIN输入板,按下按键时会发出反馈声音——PIN输入板的反馈声音都是相同的
- 本文的攻击可以视为card-skimmer攻击的替代方法,但一般的card-skimmer攻击依赖直接记录输入数字的假密码板,本文的攻击是从视频中推断密码
攻击者
- 攻击者旨在窃取受害者的PIN
- 攻击者可以在ATM附近放置一个隐藏的摄像头——假设摄像机隐藏在ATM附近,同时有PIN板的直接视野
- 当受害者在键盘上键入时,攻击者可以检索时间戳,并通过收听视频记录的音频来获得键入帧
- 攻击者可以利用两种声音线索:
- 按键时键盘发出的反馈声音
- 键盘上物理按钮被按下的声音
- 如果出于任何原因,攻击者无法从录制的音频中检索时间戳,则可以将摄像机放置在自动柜员机的键盘和屏幕上进行录制——攻击者通过查看屏幕上出现的PIN屏蔽符号来提取按键的时间,常见的屏蔽符号通常是点和星号
受害者
- 受害者采取了基本的对策来对抗盗卡攻击,例如在输入PIN时遮住手
攻击方法
攻击阶段
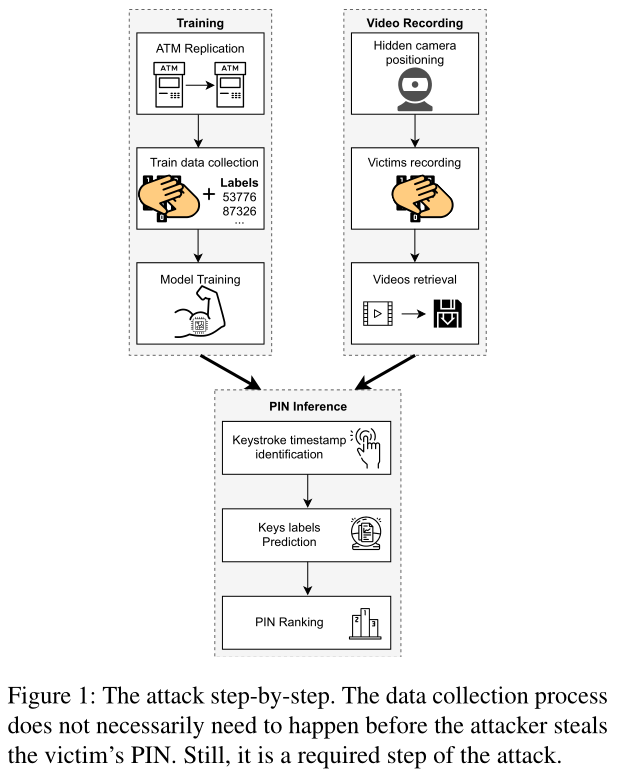
- 训练
- 攻击者选择一个ATM作为攻击目标,建立目标ATM的副本(使用类似于目标ATM上的键盘,或者使用略有不同的PIN输入板)
- 攻击者使用ATM副本构建训练集,模拟受害者输入PIN时的行为
- 在不失一般性的情况下,攻击者可以使用一个记录所按下的按键和相应时间戳的带USB的PIN板,以分割视频并打标签——得到每个按键事件的帧序列和数字标签
- 视频获取
- 攻击者在目标ATM附近隐藏一个摄像头来记录PIN
- 相机可以放在多个地方
- PIN推断
- 攻击者从录制的视频中检索时间戳(按键事件)——利用按键的反馈声音或屏幕上出现的屏蔽符号
- 利用时间戳,执行与第一个阶段相同的过程来生成攻击集——攻击集包含每个受害者的按键帧序列,不包含相关标签的信息
- 攻击者在攻击集里检测对应于PIN输入的帧序列,并将视频分割为N个子序列,其中N是PIN的位数
- 对每个子序列,应用在第一阶段训练的模型。模型的每个类对应于输入子序列的概率
- 利用对子序列的预测结果,按概率的降序建立一个PIN排名(PIN的概率对应各位数字预测概率乘积)
攻击设置
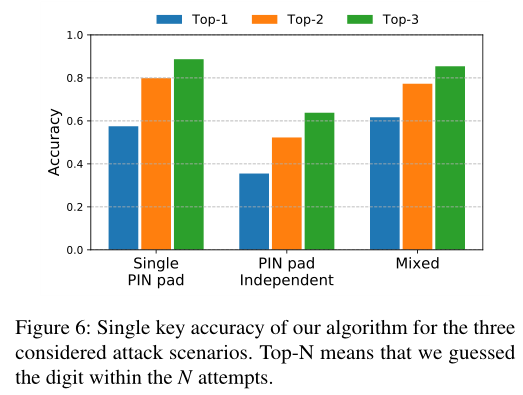
- 考虑三种现实的攻击场景
- 单个PIN输入板:
- 攻击者知道目标PIN输入板的模型,并获得它的副本来进行训练
- 攻击者可以很容易获得关于要攻击的ATM的信息,购买具有相同布局的键盘
- PIN输入板独立:
- 最有挑战的场景
- 攻击者不知道或无法检索目标PIN板的型号
- 在与目标PIN板具有相似特征(形状、按键之间的距离、按键布局、按键灵敏度)的PIN板上训练
- 混合场景
- 攻击者知道目标PIN板
- 训练在两个PIN板上进行的:目标PIN板的副本和至少一个具有相似特性的PIN板
- 如果攻击者对键盘模型不确定、攻击者假设键盘会因环境条件而表现不同、攻击者旨在用相同的机器学习模型攻击多种类型的ATM、攻击者未能获得单个键盘的大数量训练数据,需要考虑在训练集中使用多个PIN板
相机位置
- 本文允许相机位于任何位置
- 本文认为位于ATM顶部的位置对攻击者来说更好
- 本文还考虑了机箱正面的设置,因为可视性更好,并且受害者很难拿注意到摄像头
- 相机的三个主要位置:左上角、中间、右上角
- 若摄像头位于右上角,输入PIN为右手,观察输入的数字会更容易
- 本文集中讨论机箱正面、顶部中心的摄像头位置
实验设置
实验设备

DA VO LIN ModelD-8201 F:100mm*100mm
Model D-8203 B:92mm*88mm
相机最大分辨率为1080p,采集速率为30 fps。本文以720p的分辨率和30 fps的采集速率录制视频

数据收集
- 在实验过程中,参与者站在测试ATM前,并在输入PIN时遮住打字手
- 每个参与者输入100个随机生成的5位数PIN
- 总共记录了5800个随机的5位数PIN
- 通过USB接口采集了环境音频(利用网络摄像头麦克风)和PIN板的键盘记录——对于输入的每个数字,都会收集向下键和向上键事件,将视频记录与关键事件的时间戳同步
视频预处理
- 对采集的视频进行预处理
- 将视频帧转换为灰度
- 归一化输入,所有像素值位于[0,1]
- 将PIN输入板居中,裁剪帧,去除背景无关部分
- 图像调整到250x250像素
- 对每个PIN视频进行分割,获得对应于单次按键的帧的子序列(5位PIN对应5个子序列)
- 从记录的PIN板反馈声音中提取按键的时间戳(根据[8]中的程序)。特别地,以反馈声音的特定频率为中心(D-8201型2900Hz、D-8203 B型2500Hz),使用带通滤波器对音频信号进行滤波,通过识别滤波信号的峰值,可以检测按键(下记为TK,target keyt)的时间戳
- 根据时间戳,在每个TK邻域提取一组帧。对于每个TK,最大帧数(full neighborhood)包括从TK前面的关键帧到TK后面的关键帧之间的所有帧
- TK对应于PIN的第一位:只考虑TK和下一次按键之间的帧
- TK对应于PIN的最后一位:只考虑TK与其前一次按键之间的帧
- 模型要求所有输入样本具有相同的长度,本文为每个样本保留11帧(去除异常值——即$3\sigma$——后邻域帧的平均值)
- 将TK放在帧序列的中心,TK前后各有5个帧
- 三种边界情况:
- 第一个数字:子序列头部添加5个黑色帧
- 最后一个数字:子序列尾部添加5个黑色帧
- 全邻域的帧少于11帧:在前后添加黑色帧
- pad到11帧
网络模型设置
- 使用Keras 2.3.0-tf(Tensorflow 2.2.0)、Python 3.8.6
- 使用CNN和LSTM实现模型
- CNN为序列的每一帧做空间特征提取
- LSTM利用这些特征为整个帧序列提取时间特征
- LSTM的输出通过MLP和softmax(10个unit)
- 该模型在文献中被称为LRCN[11]
- 使用遍及所有CNNs层的TimeDistributed wrapper来实现,使得相同的卷积滤波器被应用于输入序列的所有时间步长(即帧)
- 使用随机网格搜索来探索不同的超参数
- 超参数的范围:
- CNN的kernel size:[3x3,6x6,9x9]
- CNN层数:[1,…,4]
- 后面的Dropout:[0.01,0.05,0.1,0.2]
- LSTM层数:[1,2,3]
- LSTM单元数:[32,64,128,256]
- 循环单元:GRU、LSTM
- MLP:层数在在1到4范围内,单元数在[16,32,64,128]
- MLP架构:所有层单元数相同、单元数量不断减少(漏斗架构,下一层为上一层单元数的一半)
- 结果:
- 四个卷积层(Keras中的Conv2D)+ReLU激活
- 每个卷积层后有一个池化(Keras中的MaxPooling2D)
- 三个卷积层的kernel size为3x3,第二个的kernel size为9x9;每个池化层都一个2x2的filter;卷积层的filter数量在每一层都翻倍:第一层32个、第四层256个
- 最后一个池化层后添加dropout层(0.1)
- 展平输出,保留时间维度;单层128维的LSTM+双曲正切激活
- MLP堆叠四层,每层有64个单元
- 使用分类交叉熵损失函数和SGD优化器
- batchsize为16,学习率为0.1,epoch为70
- 超参数的范围:
- 本文注意到本文使用的架构符合手跟踪问题的最新结果[17,23]
- 数据增强(训练集的20%):
- 旋转:顺时针和逆时针旋转7度
- 水平位移:做最大宽度10%的水平位移
- 垂直位移:做最大高度为10%的垂直位移
- 缩放:0.9和1.1之间的缩放
实验结果
针对第2节描述的三种攻击场景评估性能
参与者的视频在三组中只出现一次;删除参与者误输入的所有非5位序列
如何预测PIN:最佳猜测包括对每个数字的最佳猜测,如果该PIN不正确,考虑两个最佳猜测之间差异最小的数字,将该数字更改为个人识别码中的次优猜测,然后重试
场景1:只考虑了由40名参与者组成的第一个数据集合,划分比例为0.8,0.1,0.1
场景2:用第一个收集的数据集(40名参与者组成)进行训练和验证——35训练,5验证,第二个收集的数据集做测试
场景3:合并两个收集的数据集,0.8+0.1+0.1
图6显示了单键精度,图7显示PIN的精度
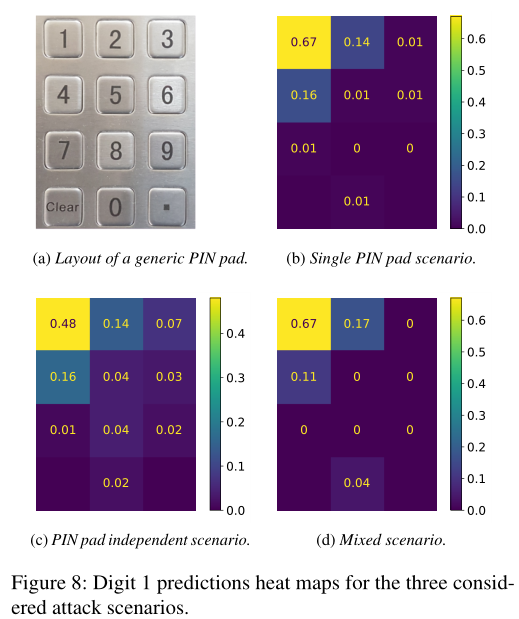
结论
- 提出了一种深度学习的密码攻击,即使用户覆盖了要输入的密码,也能达到很高的准确率
- 攻击利用了手的位置信息和输入PIN时手的移动
- 对于一个4位数的PIN,攻击准确率达到了40%以上
- 数据集太小,无法得出一般性结论
- 分析只考虑了两种类型的键盘
- 虽然尽量平衡了志愿者性别比例,但志愿者的年龄不够丰富、只分析了右撇子、所有志愿者都是白种人
- 未来可能的工作
- 允许用户选择他们的覆盖策略,探索用户覆盖PIN的方式是否会能更好保护PIN
- 丰富数据集
- 研究是否有可能直接从视频中提取时间戳(按键帧)

