牛客网、leetcode面经整理
Redis
概述
为什么用redis:高性能、高并发
为什么快:
基于内存
基于 Reactor 模式设计一套事件处理模型,包括单线程事件循环和IO多路复用
内置多种优化过后的数据结构实现
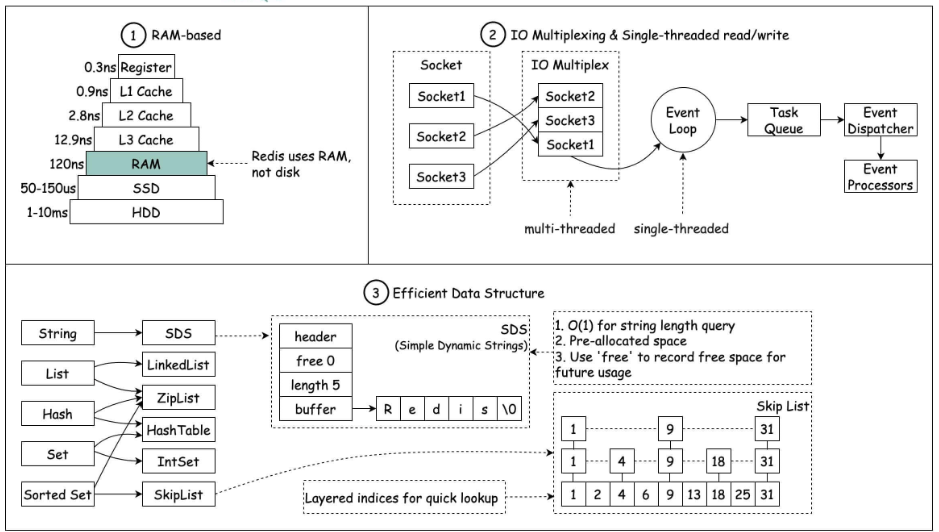
和Memcached的异同:
- 基于内存,有过期策略
- Redis除了基本的k-v外,支持更丰富的数据类型;支持数据的持久化,能够灾难恢复;内存使用完之后,可以将不用的数据放到磁盘;支持集群模式;单线程的多路 IO 复用模型,而Memcached是多线程非阻塞IO复用网络模型;Redis 支持发布订阅模型、事务等;Redis对过期数据删除使用了惰性删除与定期删除
redis 的负载因子是 1(负载因子:存储元素的个数/数组的长度)
其他应用:
分布式锁:基于Redis的扩展Redisson分布式锁详解open in new window
限流:通过 Redis + Lua 脚本的方式实现限流。相关阅读:《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》open in new window
消息队列:自带的 list 可以作为一个简单的队列使用。5.0增加的 Stream 类型的数据结构也适合做消息队列,类似于 Kafka:Redis 消息队列的三种方案(List、Streams、Pub/Sub)
- 支持发布-订阅模式
- 按照消费者组进行消费
- 支持消息持久化(RDB、AOF)以及 ACK 机制
业务场景:
- String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
- List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
- Hash 类型:缓存对象、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
- BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
- GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据
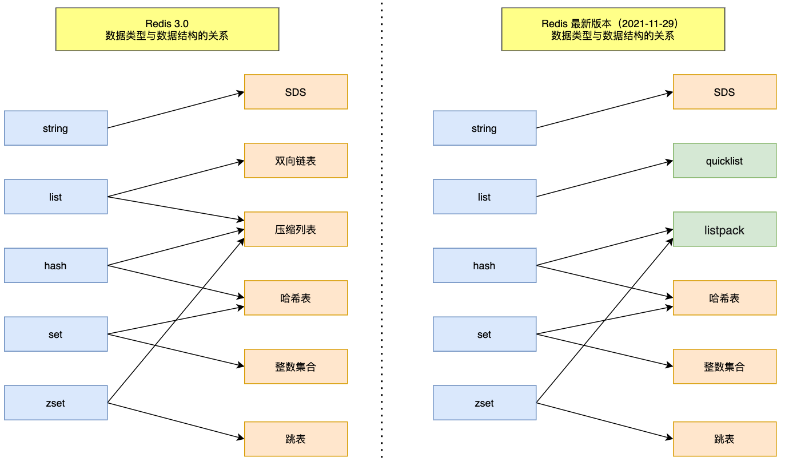
数据结构
5 种基础数据结构 :String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)
3 种特殊数据结构 :HyperLogLogs(基数统计)、Bitmap(位存储)、Geospatial (地理位置)
Redis结构
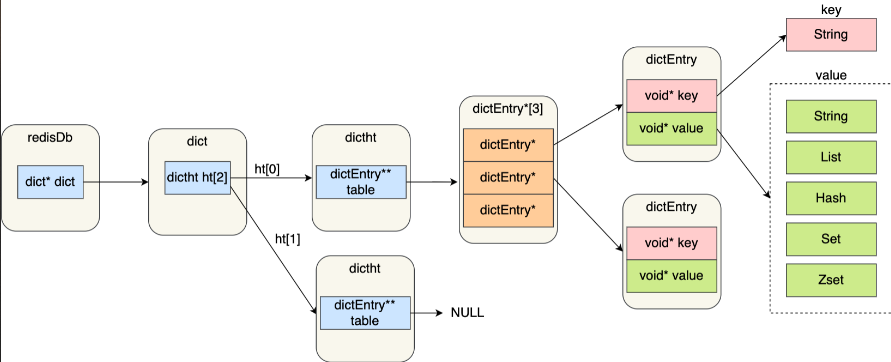
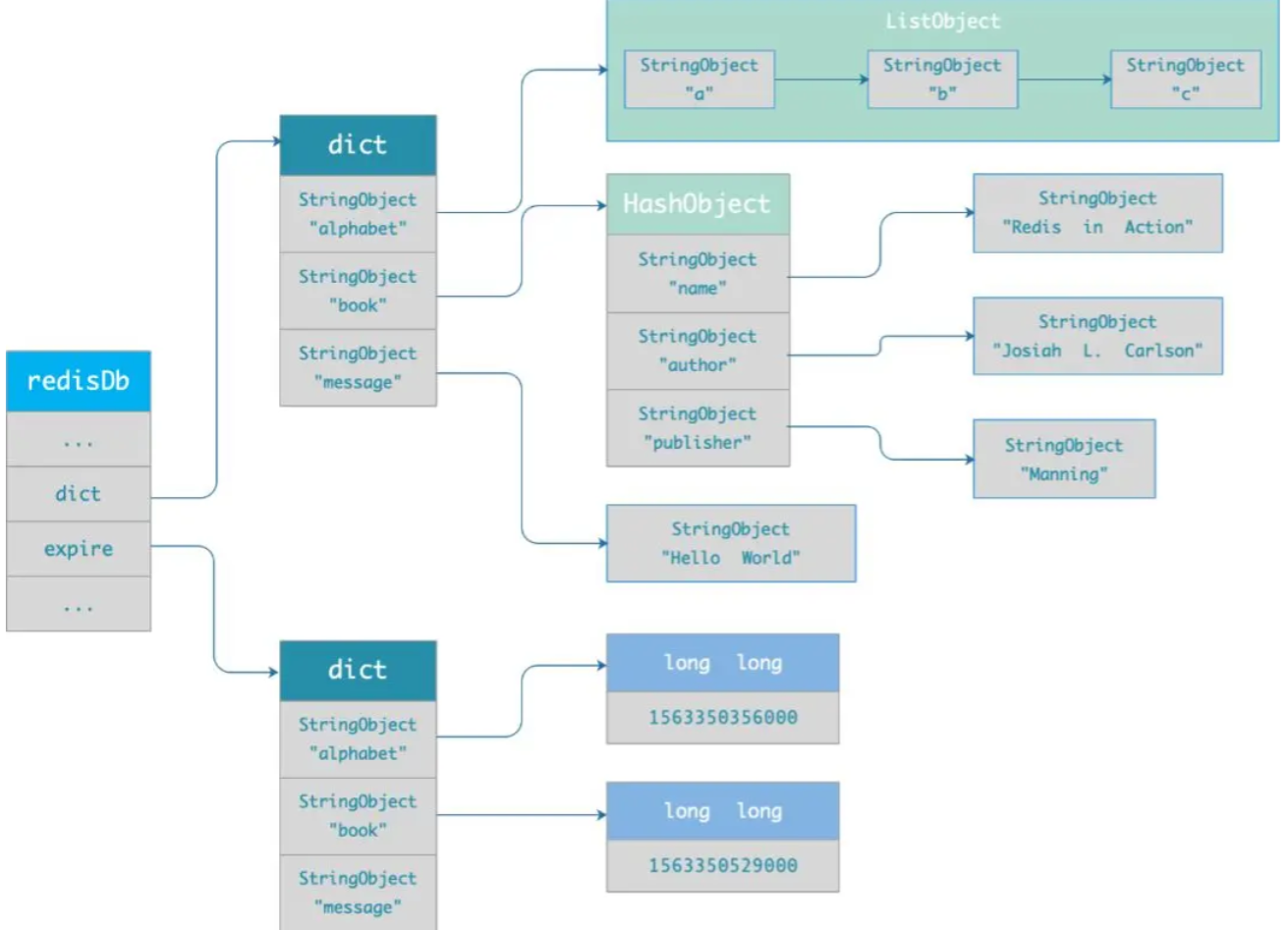
redisDb:Redis 数据库的结构,结构体存放指向 dict 结构的指针
dict 结构:存放 2 个哈希表——见扩容和缩容
ditctht 结构:哈希表的结构,存放哈希表数组,数组中的每个元素是指向一个哈希表节点结构(dictEntry)的指针
dictEntry 结构:哈希表节点的结构,存放 void *key 和 void *value 指针,key 和 value 都指向 Redis 对象
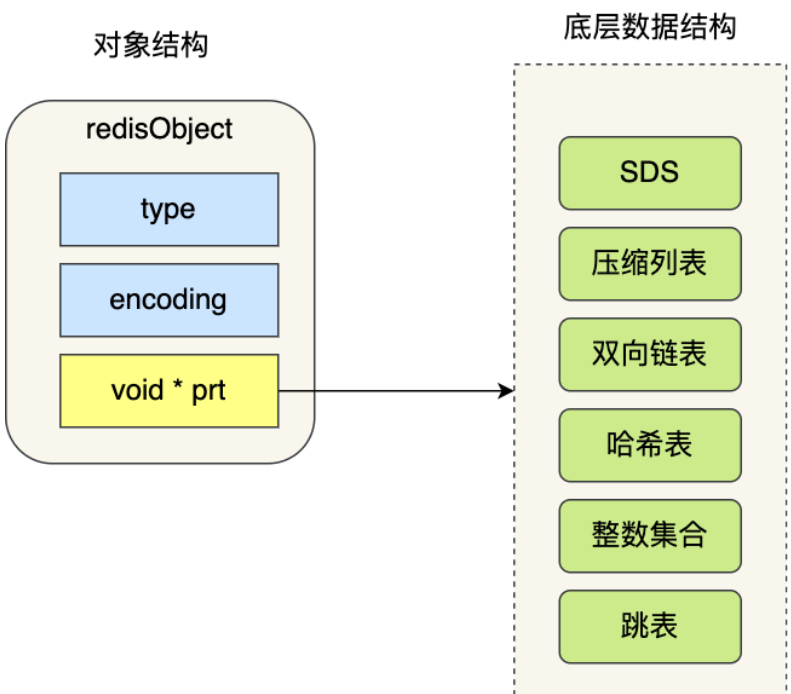
对象都由 redisObject 结构表示
- type:标识该对象的类型
- encoding:标识该对象的底层数据结构
- ptr:指向底层数据结构的指针
String
String底层原理:SDS(Simple Dynamic String)
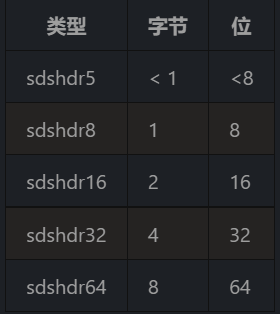
Redis根据初始化的长度决定使用哪种类型的SDS
数据结构:

对比C中的字符串:
- 避免缓冲区溢出:SDS 被修改时,先根据 len 属性检查空间大小是否满足要求
- 获取字符串长度方便:无需遍历字符串,读取len属性即可
- 二进制安全:C中字符串以空字符
\0结尾,无法正确保存图片、视频等二进制文件。SDS用len属性判断字符串是否结束,能够存储此类文件
编码:
- 保存整数值,且可以用
long类型表示,则会将将字符串对象的编码设置为int - 保存一个字符串,用一个SDS保存:
- 字符申的长度小于等于 32 字节(redis 2.+版本),设置对象编码为
embstr - 字符串的长度大于 32 字节(redis 2.+版本),设置对象编码为
raw
- 字符申的长度小于等于 32 字节(redis 2.+版本),设置对象编码为
- 阈值跟版本有关
- 保存整数值,且可以用
应用:
- 存储对象:
- 直接缓存对象的json
- 用mset存储,分离为
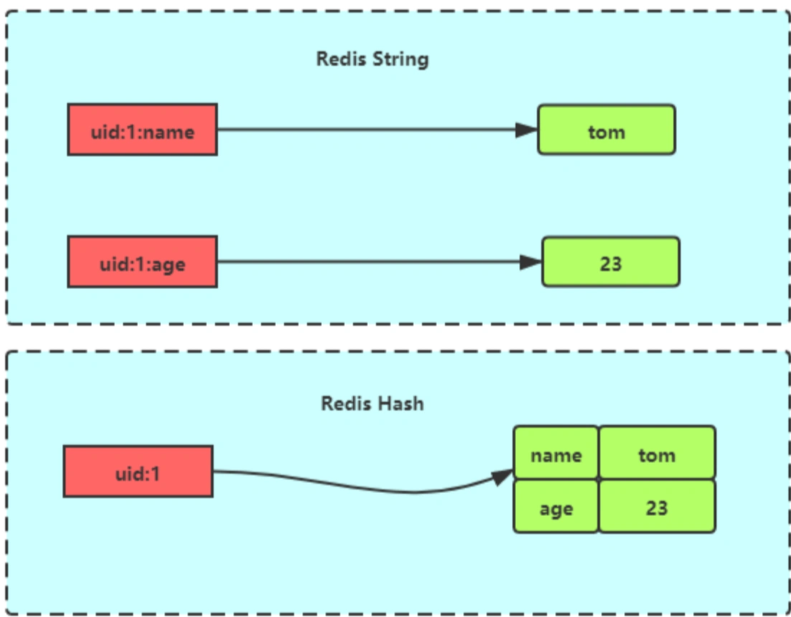
user:id:属性,例如user:1:name li user:1:age 24
- 分布式锁:见后文
- 存储对象:
List
List 底层结构:压缩列表或双向链表(取决于列表的元素个数),支持反向查找和遍历
压缩列表:见Zset
双向链表:list结构体、listNode结构体,dup(节点复制函数)、free(节点释放函数)、match(节点值比较函数)
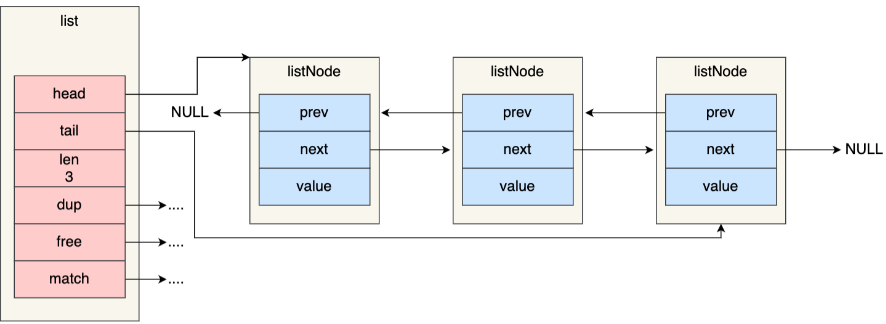
Redis3.2后,由 quicklist 实现
一个 quicklist 是一个链表,链表中的每个元素是一个压缩列表——控制每个链表节点中的压缩列表的元素个数,规避连锁更新
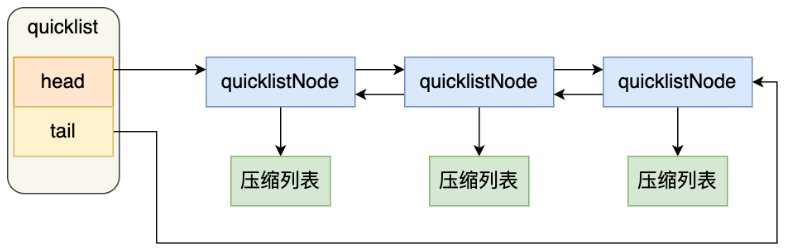
添加一个元素的时候,检查插入位置的压缩列表是否能容纳该元素,能容纳则直接保存,不能容纳时才新建一个新的 quicklistNode
应用:
- 消息队列:见后文
Hash
底层结构:
- ziplist:当保存的键和值字符串长度都小于64字节、键值对数量小于512,采用ziplist编码,将所有的key及value都当成一个元素,顺序存入到ziplist中
- hashtable:类似于 JDK1.8 前的
HashMap,内部实现也差不多(数组 + 链表),field为String类型
Redis7之后,由listpack实现。没有压缩列表中记录前一个节点长度的字段,向 listpack 加入一个新元素不会影响其他节点的长度字段
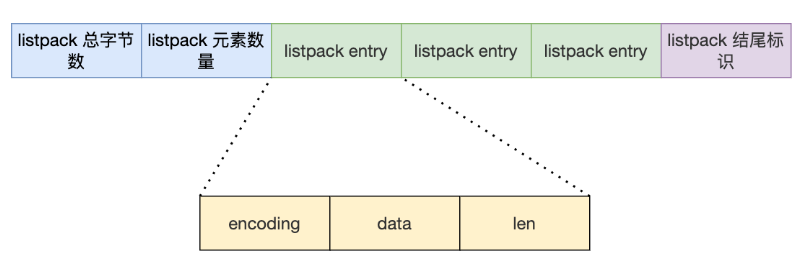
应用:
存储对象:一般对象用 String + Json 存储,对象中频繁变化的属性可以用 Hash 存储
购物车:用户id为key,商品id为field,商品数量为value(清空购物车直接删除对应的 key )
Set
- 底层结构:最多可以存储
2^32-1个元素- 整数集合:理解为数组,要求满足:元素个数不少于默认值 512,元素用整型表示。查询时采用二分查找
- 保存元素的容器是一个数组
- 当将一个新元素(int32_t)加入到整数集合()里,需要先按新元素类型扩展数组的空间大小,再将新元素加入到整数集合,并需要维持底层数组的有序性
- 不支持降级操作
- hashtable:类似 JDK 中的
HashSet,value为null
- 整数集合:理解为数组,要求满足:元素个数不少于默认值 512,元素用整型表示。查询时采用二分查找
- 应用:
- 点赞:保证一个用户只点赞一次
- 共同关注:通过交集运算获得(交集运算复杂度高,建议由从库完成,或者只交付原始数据给客户端)
- 抽奖(重复和不重复):
SPOP key count(随机移除并获取集合中一个或多个元素,适合不允许重复中奖的场景);SRANDMEMBER key count(随机获取集合中指定数量的元素,适合允许重复中奖的场景)
Zset
底层结构:
类似于Java的
Map<String, Map<String, Double>>和TreeSet,分值可以重复ziplist:
 ****
****元素数量小于默认值128个、所有元素的长度小于默认值64字节
表头:
- zlbytes:压缩列表占用对内存字节数
- zltail:尾节点偏移量
- zllen:包含的节点数
节点:三个字段
- prevlen:前一个节点的长度,以实现从后向前遍历
- encoding:当前节点实际数据的「类型和长度」
- data:当前节点的实际数据
当新插入的元素较大,可能导致后续元素的 prevlen 占用空间都发生变化,引起「连锁更新」
每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存value,第二个节点为score
Redis7之后,由listpack实现
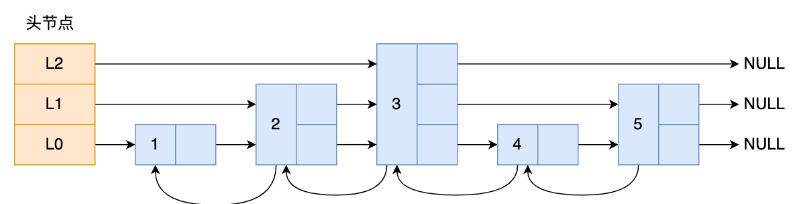
哈希表+跳跃表:哈希表只用于以常数复杂度获取元素权重
1
2
3
4
5
6
7
8
9
10typedef struct zset {
// 字典,键为value,值为score
// 用于支持 O(1) 复杂度的按成员取分值操作
dict *dict;
// 跳跃表,按分值排序成员
// 用于支持平均复杂度为 O(log N) 的按分值定位成员操作
// 以及范围操作
zskiplist *zsl;
} zset;dict关联value和score,保证value唯一,通过value找相应score
跳跃表:给value排序,并根据score的范围获取元素列表(robj指针指向具体元素,这个指针和dict中的key指针指向同一个元素)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 表头节点和表尾节点
unsigned long length; // 表中节点的数量
int level; // 表中层数最大的节点的层数
} zskiplist;
typedef struct zskiplistNode {
robj *obj; // 成员对象
double score; // 分值
struct zskiplistNode *backward; // 后退指针
struct zskiplistLevel { // 层
struct zskiplistNode *forward; // 前进指针
unsigned int span; // 跨度
} level[];
} zskiplistNode;
跳表创建节点时,生成范围为[0-1]的随机数,如果小于 0.25 层数就加 1 层,继续生成下一个随机数,直到随机数的结果大于 0.25,最终确定该节点的层数
为什么不用平衡树?
- 经常需要执行 ZRANGE 或 ZREVRANGE 命令,作为链表遍历跳表——在做范围查找的时候,跳表比平衡树操作要简单
- 平衡树的插入和删除操作可能引发子树的调整,跳表的插入和删除只需要修改相邻节点的指针
应用:
- 排行榜:相关命令包括
ZRANGE(从小到大排序)、ZREVRANGE(从大到小排序)、ZREVRANK(指定元素排名) - 电话排序、姓名排序
- 排行榜:相关命令包括
BitMap
- 一个 bit 数组
- 应用:
- 签到统计
- 判断用户登录状态:用一个bitmap存储所有用户,用户id为offset
- 连续签到的用户:七天连续签到,则对应7个bitmap的offset上均为1
HyperLogLogs
- 底层结构:略,不精确的去重计数(输入元素很多时,计算基数所需的内存空间固定)
- 应用:百万级以上的网页 UV 的场景,将访问指定页面的每个用户 ID 添加到
HyperLogLog中,然后统计该页面的UV
Geo
- 直接使用 Sorted Set 集合类型
- GeoHash 编码方法实现经纬度到 Sorted Set 中元素权重分数的转换——关键机制是「对二维地图做区间划分」和「对区间进行编码」。一组经纬度落在某个区间后,用区间的编码值来表示,并把编码值作为 Sorted Set 元素的权重分数,根据“按权重进行有序范围查找”的特性实现“搜索附近”
- 应用:搜索附近的人
Stream
- 支持消息队列
- 应用:消息队列
线程模型
Redis对读写是单线程模型。4.0后引入多线程执行大键值对的异步删除操作,6.0后引入多线程处理网络请求
Pipeline模式:客户端可以一次性发送多个命令,无需等待服务端返回,将多次I/O往返的时间缩短为一次。集群无法使用pipeline
单线程模型:
- 基于 Reactor 模式的事件处理模型,即Redis 中的文件事件处理器(file event handler)
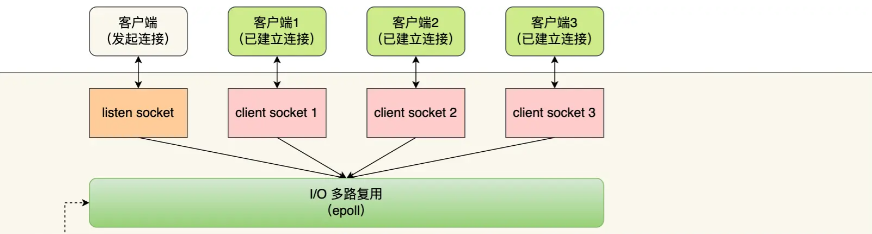
- 使用 I/O 多路复用程序同时监听多个套接字,根据套接字目前执行的任务为套接字关联不同的事件处理器
- 被监听的套接字准备执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,会产生对应的文件事件,此时文件事件处理器调用套接字关联的事件处理器来处理它们
- redis初始化时:
- 调用 epoll_create() 创建一个 epoll 对象
- 调用 socket() 创建一个服务端 socket
- 调用 bind() 绑定端口,调用 bind() 绑定端口
- 调用 epoll_ctl() 将 listen socket 加入 epoll,注册连接事件处理函数
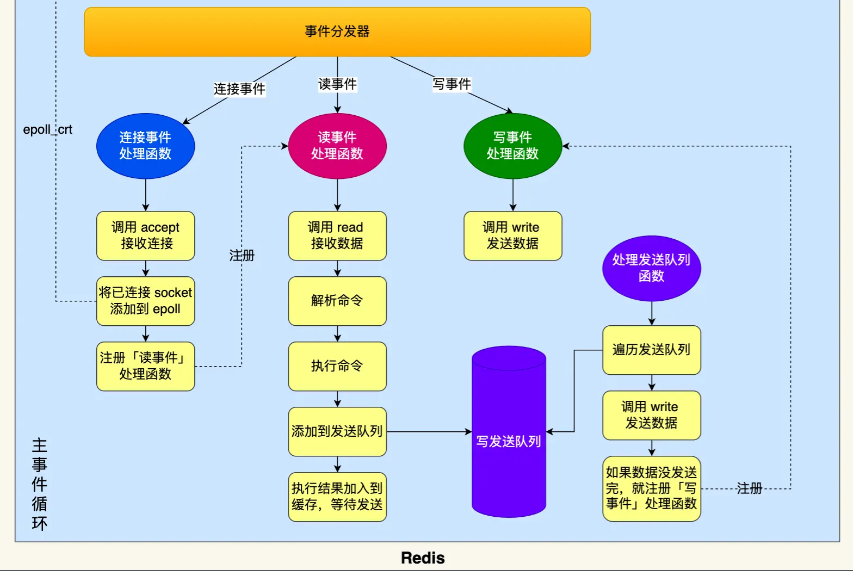
- 事件循环函数:
- 先调用处理发送队列函数,如果发送队列里有发送任务,通过 write 函数将发送缓存区的数据发给客户端。否则,注册写事件处理函数,等待 epoll_wait 发现可写后再处理
- 调用 epoll_wait 函数等待事件到来
- 连接事件:调用连接事件处理函数——调用 accpet 获取已连接的 socket -> 调用 epoll_ctl 将已连接的 socket 加入 epoll -> 注册读事件处理函数
- 读事件:调用读事件处理函数——调用 read 获取客户端发送的数据 -> 解析命令 -> 处理命令 -> 将客户端对象添加到发送队列 -> 将执行结果写到发送缓存区等待发送
- 写事件:调用写事件处理函数——如果发送队列里有发送任务,通过 write 函数将发送缓存区的数据发给客户端。否则,注册写事件处理函数,等待 epoll_wait 发现可写后再处理
- 以单线程方式运行但使用 I/O 多路复用监听多个套接字,实现高性能的网络通信模型,并且能够与服务器中其他以单线程方式运行的模块对接,保持redis单线程设计的简单性
文件事件处理器(file event handler)包含 4 个部分:
- 多个socket(客户端连接)
- IO 多路复用程序(支持多个客户端连接的关键)
- 文件事件分派器(将 socket 关联到相应的事件处理器)
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器、主从连接处理器等)
之前不使用多线程:
- 单线程的编程和维护简单
- 性能瓶颈不在 CPU ,主要在内存和网络(单个线程处理网络读写的速度跟不上底层网络硬件的速度)
- 多线程会存在死锁、线程上下文切换等问题,可能影响性能
引入多线程:提高网络IO读写性能,改善瓶颈;多线程只在网络数据读写这类耗时操作上使用,执行命令仍然是单线程顺序执行。开启需要设置IO线程数 > 1,需要修改 redis 配置文件
redis.conf的io-threads,开启后默认只使用多线程IO writes,即发送数据给客户端。开启多线程读需要再改一个配置字段——官网描述开启多线程读并不能有太大的性能提升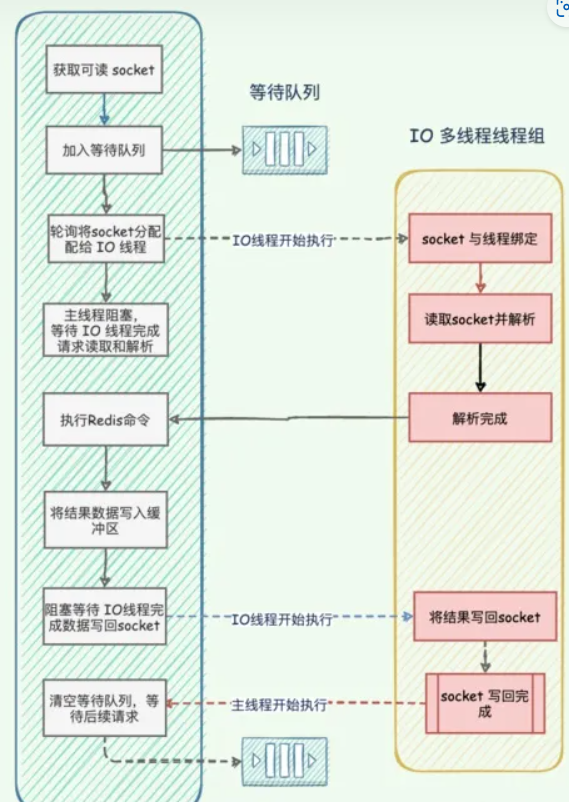
内存管理与内存淘汰
给缓存数据设置过期时间,防止OOM,或者需要某个数据只在某一时间段内存在
除了字符串类型有设置过期时间的命令
setex外,其他类型用expire key x设置过期时间 。persist命令能移除一个键的过期时间原理:
通过过期字典(一个hash表)保存数据过期时间——查询一个键,先看是否在过期字典,以及是否过期
key指向redis的某个key,value是一个long long类型的整数,保存相应key的过期时间(毫秒精度的 UNIX 时间戳)
1
2
3
4
5
6
7typedef struct redisDb {
...
dict *dict; //数据库键空间,保存着数据库中所有键值对
dict *expires // 过期字典,保存着键的过期时间
...
} redisDb;
删除策略
- 惰性删除:只在取出 key 时进行过期检查。对 CPU 友好,但对内存不友好——可能太多过期 key 没有被删除
- 定期删除: 每隔一段时间抽取一批 key 检查并删除过期的key。底层通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响
- redis二者都用,即访问或者修改 key 之前都会检查是否过期,每轮抽查时随机选 20 个 key 判断是否过期(如果过期的占比超过0.25且检查过程没有超过25ms,则再选20个key判断,)
进一步,如果内存满了:内存淘汰机制:(MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?redis内存满了怎么办?)
- volatile-lru(least recently used):从已设置过期时间的数据集(server.db[i].expires)中淘汰最近最少使用的数据
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中淘汰将要过期的数据
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中淘汰任意数据
- allkeys-lru(least recently used):内存不足时,键空间中移除最近最少使用的 key(这个是最常用的)
- allkeys-random:从数据集(server.db[i].dict)中淘汰任意数据
- no-eviction:禁止驱逐数据。内存不足时新写入操作报错
4.0后增加:
- volatile-lfu(least frequently used):从已设置过期时间的数据集(server.db[i].expires)中淘汰最不经常使用的数据
- allkeys-lfu(least frequently used):内存不足时,键空间中淘汰最不经常使用的 key
LRU不会准确的删除所有键中最近最少使用的键,而是随机抽取5个键删除最少使用(具体数目由参数决定)——不用在每次数据访问时都移动链表项,也不用维护一个大的链表
持久化
用于数据恢复。快照(snapshotting,RDB),只追加文件(append-only file,AOF)
RDB:Redis 默认,全量快照
- 内存的数据在某个时间点上的副本
- xxmin后,xxx个key发生变化时拍摄快照
save: 主线程执行,会阻塞主线程;bgsave: 子线程执行,不会阻塞主线程,默认选项(写时复制COW,子进程和父进程共享同一片内存数据)- 主线程执行读操作和 bgsave 子进程互不影响
- 主线程执行写操作,被修改的数据复制一份副本,bgsave 子进程把该副本数据写入 RDB 文件
AOF:实时性更好,主流方案
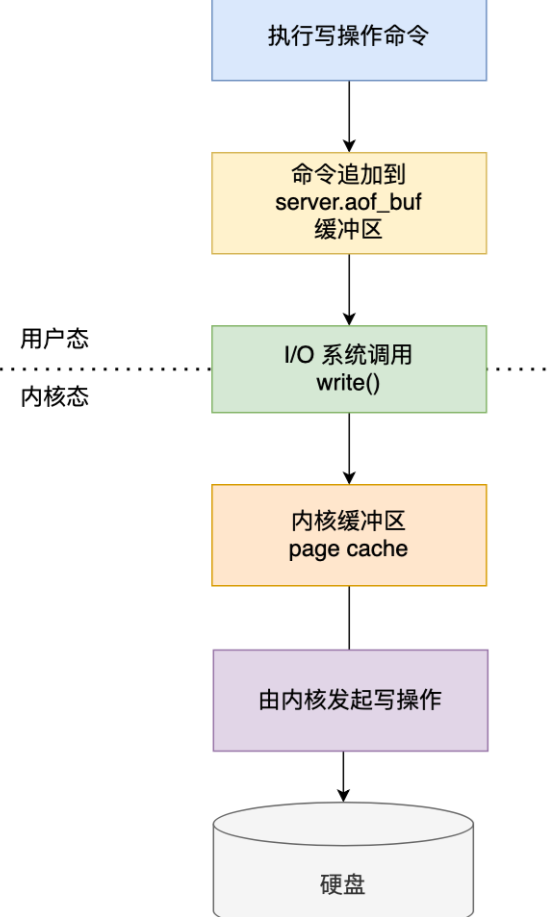
每执行一条更改 Redis 数据的命令,就将该命令写入到内存缓存
server.aof_buf,根据appendfsync配置决定何时同步到硬盘的 AOF 文件。三种策略只是控制fsync()函数的调用时机——Always 策略每次写入 AOF 文件数据后就执行 fsync() ,Everysec 策略会创建一个异步任务执行 fsync() ,No 策略永不执行 fsync()1
2
3appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
appendfsync everysec #每秒钟同步一次,显式地将多个写命令同步到硬盘
appendfsync no #让操作系统决定何时进行同步执行完命令之后再记录日志——避免额外的语法检查开销,不会阻塞当前的命令执行。风险:数据可能丢失
AOF重写:
自动重写 AOF 产生一个新的 AOF 文件,体积更小
在重写时,读取当前数据库中的所有键值对,然后将每一个键值对用一条命令记录到新的 AOF 文件,程序无须对现有 AOF 文件进行任何读入、分析或者写入操作
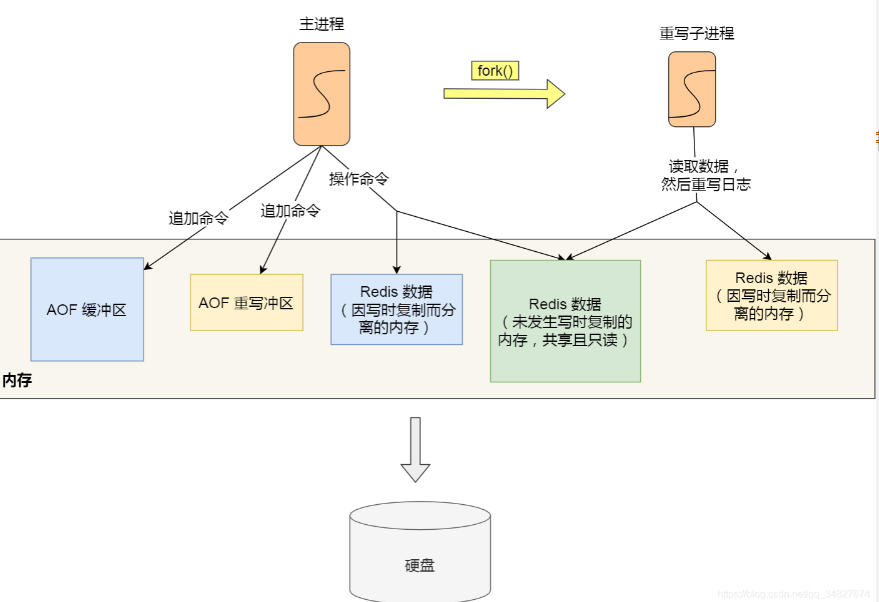
重写 AOF 过程由后台子进程 bgrewriteaof 完成
- 子进程进行 AOF 重写期间,主进程可以继续处理命令请求
- 子进程带有主进程的数据副本(
fork系统调用生成子进程时,主进程的页表会复制给子进程),如果使用线程,多线程间会共享内存,修改共享内存数据需要加锁来保证数据的安全,性能下降
为了解决重写期间主进程的写入和重写日志的数据不一致问题,服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令,之后追加到新的AOF文件末尾
重写期间,主进程将:
- 执行客户端发来的命令;
- 将执行后的写命令追加到 「AOF 缓冲区」
- 将执行后的写命令追加到 「AOF 重写缓冲区」
当子进程完成 AOF 重写工作后,向主进程发送一条信号,主进程收到该信号后会调用一个信号处理函数,将 AOF 重写缓冲区中的所有内容追加到新的 AOF 的文件中,使得新旧两个 AOF 文件所保存的数据库状态一致,并重命名新 AOF 文件名,覆盖现有的 AOF 文件
RDB优势:文件很小,直接解析即可还原数据
AOF优势:安全性好,能够实时或者秒级持久化数据;RDB 文件是以特定的二进制格式保存,存在兼容问题;AOF 的格式易于理解和解析
4.0后可以混合持久化,AOF 重写时直接把 RDB 的内容写到 AOF 文件开头
COW:
- 执行bgsave或重写AOF由子进程负责,子进程复制父进程的页表,二者虚拟内存不同但物理内存一致。父进程或者子进程向这个内存发起写操作时,CPU 触发写保护中断,操作系统在「写保护中断处理函数」里进行物理内存的复制,重新设置其内存映射关系
- 两个阶段中父进程阻塞:
- 创建子进程中,要复制父进程的页表等数据结构
- 写时复制会拷贝物理内存,拷贝越多阻塞时间越长
过期的数据:
RDB:
- 生成阶段:从内存状态持久化成 RDB(文件)的时候,会对 key 进行过期检查,过期的键「不会」被保存到新的 RDB 文件中
- 加载阶段:
- 主服务器在载入 RDB 文件时,过期键「不会」被载入
- 从服务器在载入 RDB 文件时,不论键是否过期都会被载入到数据库中——主从服务器在之后数据同步时,从服务器的数据会被清空
AOF:
- AOF 文件写入阶段:如果某个过期键还没被删除,AOF 文件会保留此过期键。当此过期键被删除,Redis 向 AOF 文件追加一条 DEL 命令来显式地删除该键值
- AOF 重写阶段:已过期的键不会被保存到重写后的 AOF 文件中
事务
- 通过
MULTI,EXEC,DISCARD和WATCH等命令实现事务:开始事务(MULTI);命令入队;执行事务(EXEC) - 通过
DISCARD取消事务,通过WATCH监听指定的key,如果该key被其他客户端或会话修改,整个事务不会执行,而若被监视的 Key 的修改操作发生同一session且在事务内部。则执行成功 - Redis 事务在运行错误的情况下,除了出错的命令外,其他命令都能正常执行。并且不支持回滚(roll back),因此不是原子的
- 事务中的每条命令都会与 Redis 服务器进行网络交互,因此浪费资源
- 缺陷弥补:利用 Lua 脚本来批量执行多条 Redis 命令。脚本被提交到服务器一次性完成,且脚本执行过程中不会有其他脚本或 Redis 命令同时执行。虽然脚本运行时出错,后面命令不会执行,但不会回滚,因此也不是原子的
性能优化
- bigkey:一个 key 对应的 value 所占用的内存比较大,例如超过10kb,复合类型的value包含的元素超过5000个
- 通过 Redis 自带的
--bigkeys参数来查找:redis-cli -p 6379 --bigkeys,但只能找出每种数据结构 top 1 bigkey - 分析 RDB 文件
- 通过 Redis 自带的
- key集中过期:此时客户端必须等待定期清理过期 key 任务线程执行完成,使得请求不能被及时处理
- 给 key 设置随机过期时间
- 开启 lazy-free(惰性删除/延迟释放):Redis 异步延迟释放 key 使用的内存。该操作交给单独的子线程处理,避免阻塞主线程
扩容与缩容
源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2]; // 存储所有的数据,是一个散列表
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;哈希冲突:通过链表方式进行连接
扩容:翻倍扩容
- 如果正在 fork (在 rdb、aof 复写以及 rdb-aof 混用情况下),会阻止扩容;但是若负载因子 > 5,马上扩容——写时复制原理,只有在不得不复制数据内容时才去复制数据内容
- rehash的key存储的index要么在oldIndex,要么在oldIndex+oldSize
rehashindex就是已经index< rehashindex的下标对应的链表已经迁移过了,迁移到 ht[1] 上,index > rehashindex 还没迁移,index = rehashindex正在迁移
缩容:负载因子 < 0.1(如果阈值是1,会造成频繁的扩缩容)
- 假如此时数组存储元素个数为 9,则缩容为16
渐进式rehash:
- redis是一个数据库,里面存储的数据非常多,不能一次性 rehash 到ht[1]
- 步骤:
- 为ht[1]分配空间,字典同时持有ht[0]和ht[1]两个哈希表
- rehashindex设置为0,表示rehash工作正式开始
- rehash期间,每次对字典执行增删改查操作,程序执行指定的操作外,还顺带将ht[0]哈希表在rehashindex索引上的所有键值对rehash到ht[1]。rehash工作完成后,rehashindex的值+1
- 随着字典操作的不断执行,在某一时间段上ht[0]的所有键值对都会被rehash到ht[1],将rehashindex的值设置为-1,表示rehash操作结束
- 都迁移到了 ht[1] 后 (ht[0] 变为空表),释放 ht[0] ,ht[1] 设置为 ht[0] ,ht[1] 新建⼀个空哈希表, 为下⼀次 rehash 做准备
- 分而治之的方式,将rehash的操作分摊在每一个的访问中,避免集中式rehash而带来的庞大计算量
生产问题
缓存穿透
大量请求的 key 是不合理的,不存在于缓存中,也不存在于数据库 ,导致这些请求直接到了数据库造成压力
方案:
- 参数校验,对不合法的参数请求直接抛出异常信息
- 缓存无效的key:此类数据写一个到redis并设置过期时间(一般比较短)。可以解决请求的 key 变化不频繁的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public Object getObjectInclNullById(Integer id) {
// 从缓存中获取数据
Object cacheValue = cache.get(id);
// 缓存为空
if (cacheValue == null) {
// 从数据库中获取
Object storageValue = storage.get(key);
// 缓存空对象
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
// 必须设置过期时间,否则有被攻击的风险
cache.expire(key, 60 * 5);
}
return storageValue;
}
return cacheValue;
}- 所有可能存在的请求的值都存放在布隆过滤器中,先判断用户的请求的值是否存在于布隆过滤器
- 布隆过滤器:判断一个给定数据是否存在于海量数据中
- 加入过滤器:计算元素的哈希,根据hash值设置bit数组相应下标值为1
- 判断:计算哈希,看相应位置是否为1
- 布隆过滤器:判断一个给定数据是否存在于海量数据中
缓存击穿
缓存中某个热点数据过期,导致瞬时大量的请求直接访问数据库
方案:
- 热点数据永不过期或者过期时间较长
- 热点数据过期前,提前通知后台线程更新缓存以及重新设置过期时间
- 数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上
缓存雪崩
缓存在同一时间大面积的失效,导致大量的请求都直接落到数据库,对数据库造成巨大压力
可能原因:redis服务不可用,或者大量缓存失效(不只是某个热点数据不在缓存中)
方案:
- 采用 Redis 集群或者 redis 服务限流
- 随机设置缓存时间
缓存预热
- 系统上线时,缓存内还没有数据,如果直接提供给用户使用,每个请求都会穿过缓存去访问底层数据库
- 方案:
- 定时刷新缓存
- 需要看当天的具体访问情况,试试统计出频率较高的热数据
缓存和数据库数据一致性
当数据发生更新时,不仅要操作数据库,还要一并操作缓存——更新数据库+更新缓存会带来顺序上的问题
- 先更新数据库,后更新缓存——缓存更新成功,但数据库更新失败,那么当缓存过期,数据又是旧值
- 先更新缓存,后更新数据库——数据库更新成功,但缓存更新失败,那么只有当缓存过期才能得到新值
- 缓存中的值并不是与数据库中的值一一对应,可能有计算过程
- 并发更新时,即使都成功,数据库和缓存中的值可能是不同的
更新数据库+删除缓存:
并发问题:
- 先删除缓存,后更新数据库:当存在读+写并发时,仍然存在不一致(A写的时候删除了缓存,B读的时候读取数据库旧值,A更新数据库后B向缓存写入旧值)
- 解决:可以延迟双删——先淘汰缓存,再写数据库(这两步和原来一样),过1秒再次淘汰缓存
- 第二次可以用另一个线程异步删除,从而写请求就不用沉睡一段时间后再返回,从而提高吞吐量
- 重试机制解决删除缓存失败的问题
- 先更新数据库,后删除缓存:缓存刚好失效(不失效的话A不会向缓存写入旧值),A读取数据库旧值,B更新数据库并删除缓存,A向缓存写入旧值——但这要求缓存失效、读写并发、更新数据库+删除缓存的速度快于读数据库+写缓存,而写数据库更慢,因此保证数据一致
- 先删除缓存,后更新数据库:当存在读+写并发时,仍然存在不一致(A写的时候删除了缓存,B读的时候读取数据库旧值,A更新数据库后B向缓存写入旧值)
通过异步重试(MQ),保证第二步发生失败后,能够重连实现一致(旁路缓存模式)
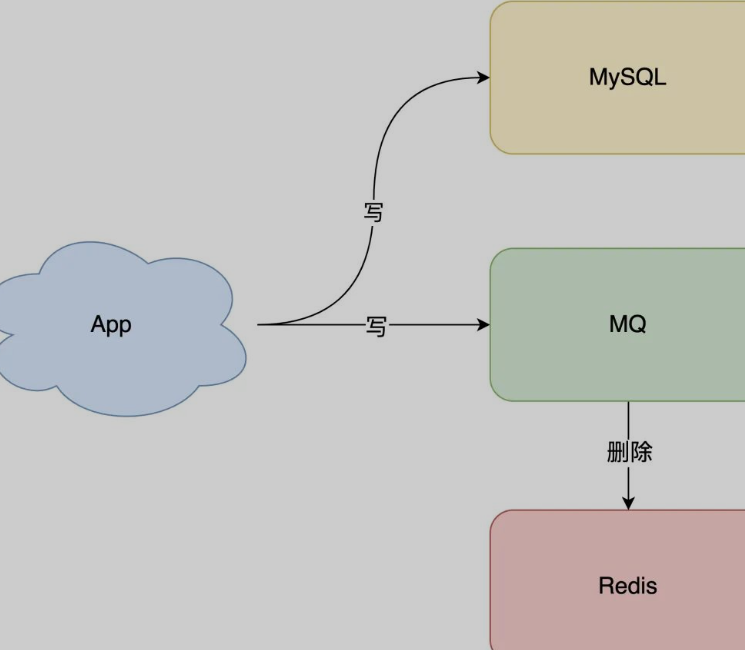
订阅数据库变更日志(bin log),再操作缓存。此时只需修改数据库,无需操作缓存(拿到具体操作的数据,然后再根据这条数据去删除对应的缓存)

Cache Aside Pattern(旁路缓存模式):更新 DB,直接删除 cache
- 如果更新数据库成功,而删除缓存这一步失败的情况的话,可以每隔一段时间重试。如果多次重试仍旧失败,则将更新失败的key放入队列。redis可用后再根据该队列删除缓存中的key
- 延迟失效:写请求开始前给缓存设置1s过期时间
Read/Write Through Pattern(读写穿透):把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务将此数据读取和写入 db(redis没有提供这个功能)
- 写:先查 cache,cache 未命中则直接更新 db。命中则先更新 cache,cache 服务自己更新 db
- 读:从 cache 中读取数据,命中则直接返回 。未命中则从 db 加载,写入 cache 后返回
Write Back Pattern(异步缓存写入):更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。适合数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量
缓存降级
- 当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,即使是有损部分其他服务,仍然需要保证主服务可用
分布式锁的实现
有些场景中为了保证数据一致,要保证某一方法/共享资源同一时刻只能被一个线程访问(高并发下争夺共享资源)
要满足:
- 互斥 :任意一个时刻锁只能被一个客户端获取锁
- 高可用 :锁服务是高可用的。即使客户端释放锁的代码出现问题,锁还是会被释放
- 可重入:一个客户端获取锁之后,还可以再次获取锁
SETNX命令实现互斥地获取锁——如果key不存在,才设置key的值,否则啥也不做;DEL命令删除对应的锁(通过lua脚本保证解锁的原子性,需要先比较锁对应地value值是否相等,防止误删)为避免锁无法被释放,需要给锁设置过期时间(加锁和设置过期时间要为一个原子操作)
1
SET lockKey uniqueValue EX 3 NX
- lockKey :加锁的锁名;
- uniqueValue :能够唯一标示锁的随机字符串;(释放锁时先检查这个标识,看这个锁是否是当前进程的锁)
- NX :只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功;
- EX :过期时间设置(秒为单位)。PX以毫秒为单位
锁的续期:Redisson提供了一个监控和续期锁的 Watch Dog,如果操作共享资源的线程还未执行完成,调用 Lua 脚本实现续期(原子性)——只有未指定锁超时时间,才会使用 Watch Dog 自动续期
集群下分布式锁的可靠性:Redlock算法
- 对于Redis的主从结构中出现的主服务器宕机情况(单点故障),客户端A已经获取到锁,但是主服务器还没来得及将键复制到从服务器,并且从服务器晋升为了主服务器,这时客户端B也可以获取锁,锁互斥效果失效
- 客户端向 Redis 集群中多个独立的 Redis 依次请求加锁,如果和半数以上的实例完成加锁操作,那么客户端获得分布式锁,否则加锁失败
- 第一步,客户端获取当前时间(t1)
- 第二步,客户端按顺序向 N 个 Redis 节点执行加锁操作
- 第三步,一旦客户端从超过半数(大于等于 N/2+1)的 Redis 节点上成功获取到了锁,再次获取当前时间(t2),计算加锁过程的总耗时(t2-t1)。如果 t2-t1 < 锁的过期时间,认为客户端加锁成功,否则认为加锁失败
- 加锁失败,客户端向所有 Redis 节点发起释放锁的操作
- 和zk的区别:zk不需要设置过期时间,它通过watcher机制和临时节点来使得锁自动释放;redlock的性能高于zk,但需要假设多个节点机器时钟都是一致的;redlock中的实例,指的是主服务器,因此需要至少三台主服务器
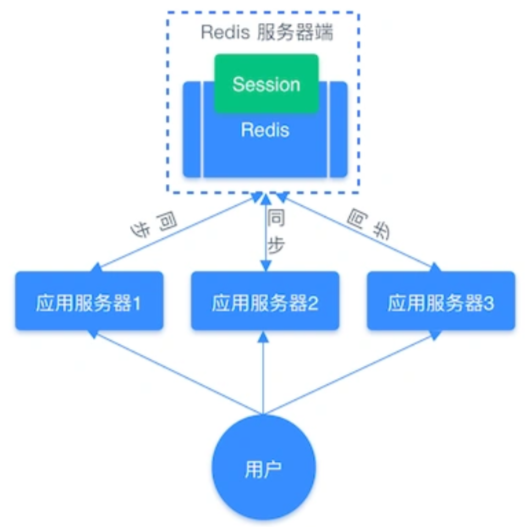
共享Session
无论请求发送到哪个服务器,都去同一个 Redis 获取Session信息
redis再借助集群实现可用
消息队列的实现
利用 高效可靠 的 消息传递机制 进行与平台无关的 数据交流,基于数据通信实现分布式系统的集成
特点:
- 生产者、消费者、消息处理中心
- 异步处理:生产者将消息发送到消息队列,无须等待响应。消费者订阅或监听该通道,取出消息。互不干扰,不需要同时在线
- 可靠性:消息不丢失、不重复消费、顺序性保证
List实现消息队列:(点对点的消息模型)
- 列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边)
- 需要延后处理的任务结构体序列化成字符串塞进 Redis 列表,另一个线程从这个列表中轮询数据进行处理——保证消息有序
LPUSH、RPUSH、RPOP、LPOP、BLPOP、BRPOP(阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,不需要消费者循环调用POP)- 在消费数据时,同一个消息不会同时被多个
consumer消费掉——Redis单线程
- ack机制(读取消息的可靠性):
- 消费者向队列报告消息已收到或已处理(上面的命令,如果消费者崩溃,则消息无法还原)
- 通过
RPOPLPUSH、BRPOPLPUSH(阻塞),从一个 list 中获取消息,并把这条消息复制到另一个 list 里(可以当做备份)。在业务流程安全结束后,再删除队列元素
- 重复消息处理:自行为每个消息生成一个全局唯一的id
- 缺陷:不支持多个消费者消费同一条消息
订阅与发布:(消息多播),没有ack机制,没有持久化——没有基于任何数据类型实现,发布/订阅机制的相关操作不会写入到 RDB 和 AOF 中,当 Redis 宕机重启,发布/订阅机制的数据也会全部丢失
通过
PUBLISH、SUBSCRIBE等命令实现了订阅与发布模式发布到频道:频道可以理解为一个 Redis 的 key
subscribe frame1
2
3
* ```
publish frame a此时订阅的客户端会收到三个参数的消息:消息种类、频道名称、实际的消息
发布到模式:模式可以理解为一个类似正则匹配的 key,一次性订阅多个频道
psubscribe frame.*1
2
3
* ```
publish frame.x a
streams实现消息队列:消息能够被持久化,任何客户端访问任何时刻的数据
- 是个仅追加内容的消息链表,消息链表有唯一的名称(key),把所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容
- 消息保序:XADD/XREAD
- 当没有数据时,阻塞住:调用 XRAED 时设定 BLOCK 配置项,实现类似于 BRPOP 的阻塞读取操作
- 消息唯一:在使用 XADD 命令时,自动生成全局唯一 ID
- 消息可靠性:使用 PENDING List 自动保存消息,消费者在重启后,用 XPENDING 查看已读取但尚未确认处理完成的消息
缺陷:
- Redis 本身可能会丢数据,例如AOF时宕机
- 面对消息挤压,内存资源紧张
延迟队列
- 把当前要做的事情,往后推迟一段时间再做。例如,取消订单
- 使用有序集合(ZSet),Score 属性存储延迟执行的时间
- 使用 zadd score1 value1 命令往内存中生产消息。用 zrangebysocre 查询符合条件的所有待处理的任务, 通过循环执行队列任务即可
限流
计数器:内通过原子类计数器
AtomicInteger、Semaphore信号量来做简单的限流lua脚本(原子操作):检查一个key对应的value是否小于limit,如果小于则value+1,设置过期时间为一秒后,如果大于则拒绝
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20-- 获取调用脚本时传入的第一个key值(用作限流的 key)
local key = KEYS[1]
-- 获取调用脚本时传入的第一个参数值(限流大小)
local limit = tonumber(ARGV[1])
-- 获取当前流量大小
local curentLimit = tonumber(redis.call('get', key) or "0")
-- 是否超出限流
if curentLimit + 1 > limit then
-- 返回(拒绝)
return 0
else
-- 没有超出 value + 1
redis.call("INCRBY", key, 1)
-- 设置过期时间为1秒钟以后
redis.call("EXPIRE", key, 2)
-- 返回(放行)
return 1
end
动态缓存热点数据
- 通过数据最新访问时间来做排名,过滤掉不常访问的数据,只留下经常访问的数据
- Top 1000 的商品:先存一个排序队列,定期过滤队列中排名最后的 200 个商品,数据库随机读取出 200 个商品加入队列
去重
- 基于set去重(如果元素个数很大,消耗内存太多)
- 基于bitmap去重(要求元素能否简单映射为位偏移)
- 基于Hyperloglog去重(实现超大数据量精确的近似唯一计数——HyperLogLog Counting)
- 基于布隆过滤器去重(利用类似位图或者位集合数据结构来存储数据,需要插件)
Redis集群
- 单机模式
- 主从模式:master 节点挂掉后,需要手动指定新的 master,可用性不高
- 哨兵模式:master 节点挂掉后,哨兵进程主动选举新的 master,可用性高,每个节点存储的数据相同
- Redis cluster:所有主节点的容量总和是Redis cluster可缓存的数据容量
主从复制
支持多个数据库之间的数据同步。主数据库可以进行读写操作,从数据库一般是只读
不是强一致,主服务器在本地执行完命令就会向客户端返回结果
服务器B执行
replicaof <服务器 A 的 IP 地址> <服务器 A 的 Redis 端口号>,成为A的从服务器过程:
启动一个从节点时,它会发送一个 PSYNC 命令给主节点(主服务器的runid和自己的复制进度)
如果是从节点初次连接到主节点,会触发一次全量复制。主节点启动一个后台线程,生成一份 RDB 快照文件,client 新收到的写命令缓存在内存
主节点将 RDB 文件发送给从节点
从节点先将 RDB 文件写入本地磁盘,再从本地磁盘加载到内存
主节点将缓存的写命令发送到从节点,从节点同步
从节点跟主节点之间网络出现故障,会自动重连,主节点仅将缺失的数据同步给从节点
后续双方维护一个TCP长连接,保持状态一致

全量复制如上。当二者断开一段时间重新连接时,进行增量复制:
- 快照一致,并将offset后面的内容的修改命令发给slave(此时psync中的offset不是-1)
- 主节点维护一个环形缓冲区,以及缓冲区的同步进度(主节点有 master_repl_offset 记录「写」到的位置,从节点有 slave_repl_offset 记录「读」到的位置)
- 当从节点重新连上主节点,从节点通过 psync 将复制偏移量 slave_repl_offset 发送给主节点,主节点根据 master_repl_offset 和 slave_repl_offset 之间的差距,来决定对从节点执行哪种同步操作——从节点要读取的数据还在缓冲区,则增量复制,否则全量复制
过期的数据:从库不会进行过期扫描,即使从库中的 key 过期,客户端也可以得到 key 对应的值;主节点通过淘汰算法淘汰了一个key,则发送一条del命令给从节点
Redis 主节点每次收到写命令之后,先写到内部的缓冲区,然后异步发送给从节点
Redis如何判断节点是否工作:
- 主节点默认每 10 秒对从节点发送 ping 命令,判断从节点的存活性和连接状态
- 从节点每 1 秒发送 replconf ack{offset} 命令,上报自身的复制偏移量
数据丢失:
- 同步时丢失:主节点先写入,然后返回响应给客户端,再将写请求同步给从节点。如果此时断电,则主节点的数据丢失
- 有一个参数 min-slaves-max-lag,表示一旦所有的从节点数据复制和同步的延迟都超过 min-slaves-max-lag,主节点会拒绝接收任何请求
- 该参数为10s,则能将 master 和 slave 数据差控制在10s内
- 脑裂:
- 当主节点发现「从节点下线的数量太多」,或者「网络延迟太大」的时候,那么主节点会禁止写操作,直接把错误返回给客户端
- 同步时丢失:主节点先写入,然后返回响应给客户端,再将写请求同步给从节点。如果此时断电,则主节点的数据丢失
哨兵:主从节点故障转移
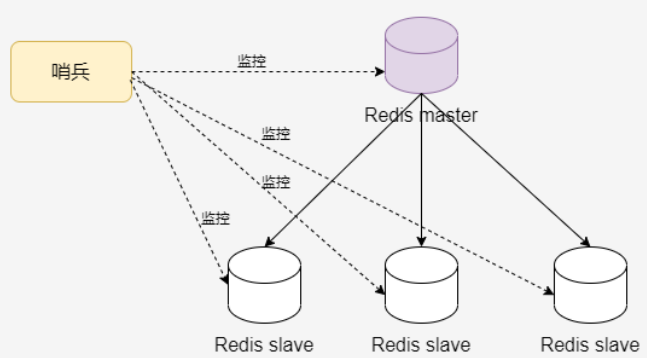
- 自动切换主从节点。客户端先连接哨兵,哨兵告知主节点的地址,客户端再进行操作
- 原理:
- 监控:每个 Sentinel 每秒钟向所知道的Master、Slave、其他 Sentinel 实例发送PING命令,如果某个实例最后一次有效回复的时间超过指定值, 实例被 Sentinel 标记为主观下线——需要哨兵集群,防止哨兵出问题
- 如果一个 Master 被标记为主观下线,该sentinal询问其他sentinel对主节点的判断。 当有超过
quorum个 Sentinel (大于等于配置文件指定值)在指定的时间范围内确认 Master 主观下线,Master 会被标记为客观下线。若 Master 重新向 Sentinel 的 PING 命令返回有效回复,主观下线状态被移除 - 选举:哨兵节点会选举哨兵 leader,负责故障转移——哪个哨兵节点判断主节点为「客观下线」,哪个就是候选者
- 每个哨兵节点只有一票
- 要拿到半数以上的赞成票,且票数大于等于quorum
- 通知:哨兵 leader 会推选出某个表现良好的从节点成为新的主节点,然后通知其他从节点更新主节点信息
- 选举哨兵leader:
- 用Raft协议实现Sentinel间选举Leader的算法
- 一个Sentinel节点确认redis集群的主节点客观下线后,让其他Sentinel节点将自己选举为Leader
- 得票超过quorum且超过Sentinel节点数一半时,成为leader
- 如果此过程选举出了多个领导者,那么重新进行选举
- 选举新的master:按照如下顺序选择新的master
- 较低的slave_priority(在配置文件中指定,默认配置为100)
- 较大的replication offset(每个slave在与master同步后offset自动增加,offset表明主从复制偏移量)
- 较小的runid(每个redis实例启动后会有一个随机的runid)
- 看哪个slave节点处理之前master发送的command多
- 故障转移过程:
- sentinel leader从slave中选举出合适的从节点进行故障转移
- 选取的slave执行slave of no one
- 更新应用程序端的链接到新的主节点(通过 Redis 的发布者/订阅者机制来实现。每个哨兵节点提供发布者/订阅者机制,客户端可以从哨兵订阅消息)
- 对其他从节点变更master为新的节点(向从服务器发送SLAVEOF命令)
- 修复原来的master并将其设置为新master的slave
- 执行一次全量复制
- 哨兵节点之间通过 Redis 的发布者/订阅者机制来相互发现。主节点有一个名为
__sentinel__:hello的频道,哨兵 A 把自己的 IP 和端口发布到__sentinel__:hello频道,哨兵 B 和 C 订阅该频道后可以从这个频道直接获取 A 的 IP 和端口号
切片集群
所有主节点的容量总和就是Redis cluster可缓存的数据容量
无中心架构,支持动态扩容; 节点间数据共享,可动态调整数据分布; 高可用性,能够实现自动故障转移,用投票机制完成 Slave 到 Master 的角色转换(集群中所有master参与投票,半数以上master与一个master节点通信超时)
cluster实现Redis的分布式存储,节点最小配置6个节点以上(3主3从),主节点提供读写操作,从节点作为备用节点只作为故障转移
Redis cluster采用哈希槽处理数据和节点的映射关系,所有的键根据哈希函数映射到0~16383个整数槽,每个节点维护一部分槽以及槽所映射的键值数据
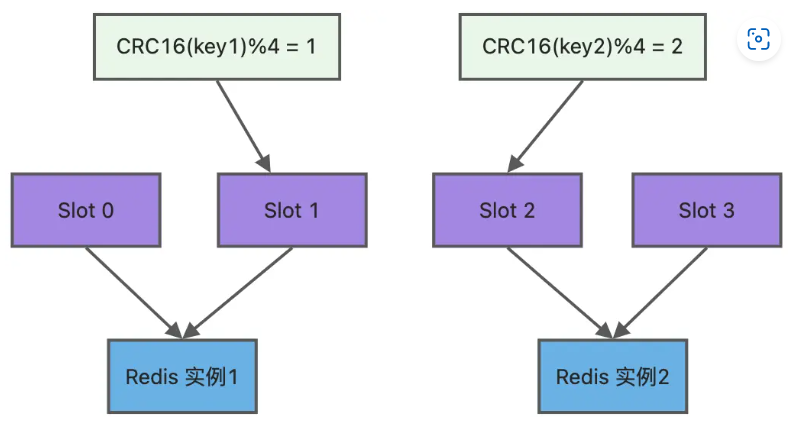
哈希槽如何映射到 Redis 实例上?
- 对键值对的 key 使用 crc16 算法计算一个16bit结果
- 结果对 16384 取余(& 16383),得到 key 对应的哈希槽,根据该槽信息定位对应的实例
节点之间如何通信?
- 建立TCP连接,使用gossip协议——master节点彼此不断通信交换信息,一段时间后集群所有的节点都会有完整的(集群)信息
16384:
CRC16算法产生的hash值有16bit,有2的16次方65536个值- 节点通信时,消息头中会带有一个bitmap,每一个位代表一个槽,如果该位为1,表示这个槽属于这个节点,如果槽位时65536,则消息头为8k。浪费带宽
- redis的集群主节点数量基本不可能超过1000个
- 16374/8/1024刚好为2,即此时消息头为2kb
缺点:
- 不支持批量操作(pipeline)
- 数据通过异步复制,不保证数据的强一致性
- 事务操作支持有限,只支持多 key 在同一节点上的事务操作
- key 作为数据分区的最小粒度,不能将一个很大的键值对象如 hash 、 list 等映射到不同的节点
脑裂问题:
- 问题发生:
- 主节点和从节点、哨兵失联,客户端向主节点发送写请求
- 哨兵选择新的leader后连上旧leader,旧leader成为从节点后和新leader同步,原先的写入数据丢失
- 解决方案:当主节点发现从节点下线或者通信超时的总数量小于阈值时,禁止主节点写数据,直接把错误返回给客户端
- 问题发生:
一致性哈希
redis使用哈希槽不用一致性哈希,为什么?
- Hash slot 可以做到数据分配更均匀——有 N 个节点,每个节点准确地承担 1/N 的容量
- Hash slot 更便捷的新增/删除节点——新增 R4 节点,只需要从 R1、R2、R3 挪一部分 slot 到 R4 上,删除 R1 节点,只需将 R1 中 slot 移到 R2 和 R3 节点上, 节点之间的槽移动不会停止服务
- 一致性哈希的节点分布基于圆环,无法很好的手动控制数据分布,比如有些节点的硬件差,希望少存一点数据,这种很难操作(还得通过虚拟节点映射,总之较繁琐);哈希槽位空间可以用户手动自定义分配的,类似于 windows 盘分区的概念,手动控制大小
一致性哈希:
用于负载均衡,将客户请求分配到多个节点上
如果用一般的哈希算法,则当节点扩容,必须迁移改变了映射关系的数据,否则会出现查询不到数据的问题
原理:
- 一致性哈希对 $2^{32}$ 取模,把取模运算的结果组织成一个圆环(哈希环),对存储节点进行哈希计算,数据进行存储或访问时,对数据进行哈希映射——一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上
- 映射的结果值往顺时针的方向的找到第一个节点,就是存储该数据的节点
- 一致哈希算法中,增加或者移除一个节点仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据不受影响
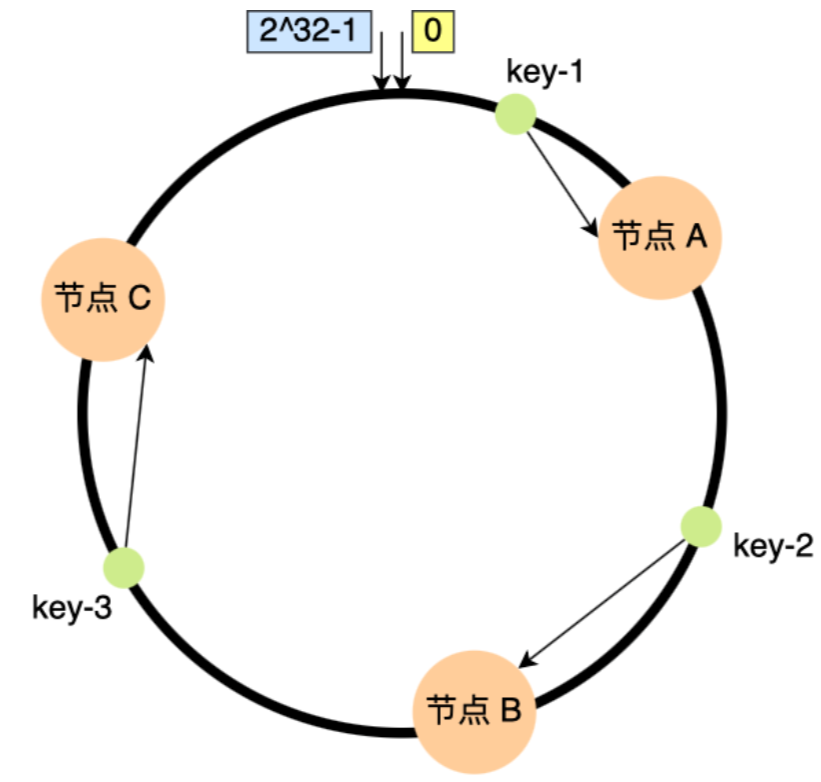
缺陷:不保证节点能够在哈希环上分布均匀,会有大量的请求集中在一个节点上。如果节点A移除,B的数据量、访问量会急速增加,一旦超过B的处理上限,B崩溃,进而导致“雪崩”
解决:不将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点——「两层」映射关系
例如,A、B、C都映射为三个虚拟节点,交叉分布
Zookeeper
概览
- CAP:对于一个分布式系统,当设计读写操作时只能同时满足两个(一般都是cp和ap,Eureka为ap):
- 一致性(Consistency) : 所有节点访问同一份最新的数据副本
- 可用性(Availability): 非故障的节点在合理的时间内返回合理的响应(不是错误或者超时的响应)
- 分区容错性(Partition Tolerance) : 分布式系统出现网络分区的时候,仍然能够对外提供服务
- 三选二:(三种特性都是范围类型)
- 满足C,所有的机器上的数据都是一样:每当一个新数据新增到其中一个服务器上,这个数据要同步到其它服务器,这样才可以保证C
- 满足A:用户随时都在访问,都能在可控的时间内返回正确的数据
- 满足P:非常可靠,必须是机器越多越可靠,为啥?我有1亿台服务器,挂了几万台,完全没影响
- 满足C和A,那么P能不能满足呢?
- 满足C需要所有的服务器的数据要一样,也就是说要实现数据的同步,同步也要时间,并且机器越多,同步的时间肯定越慢,这里问题就来了,我们同时也满足了A,也就是说,我要同步时间短才行。这样的话,机器就不能太多了,也就是说P是满足不了的
- 满足C和P,那么A能不能满足呢?
- 满足P需要很多服务器,假设有1000台服务器,同时满足了C,也就是说要保证每台机器的数据都一样,那么同步的时间可就很大,在这种情况下,我们肯定是不能保证用户随时访问每台服务器获取到的数据都是最新的,想要获取最新的,可以,你就等吧,等全部同步完了,你就可以获取到了,但是我们的A要求短时间就可以拿到想要的数据啊,这不就是矛盾了,所以说这里A是满足不了了
- 满足A和P,那么C能不能满足呢?
- 满足P的话,需要多台服务器,而满足C的话,只有一台服务器才可以满足,这和P矛盾。
- 一个开源的分布式协调服务(CP,任何时刻对 ZooKeeper 的读请求都能得到一致性的结果,不保证每次请求的可用性,比如可能在选举或者半数以上的机器不可用),将数据保存在内存
- 特点:
- 顺序一致性: 同一客户端发起的事务请求会按照顺序被应用到 ZooKeeper
- 原子性: 要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用
- 单一系统映像 : 客户端连到任意一个zk服务器,看到的服务端数据模型一致
- 可靠性: 一旦更改请求被应用,更改的结果会被持久化,直到被下一次更改覆盖
Zookeeper数据模型
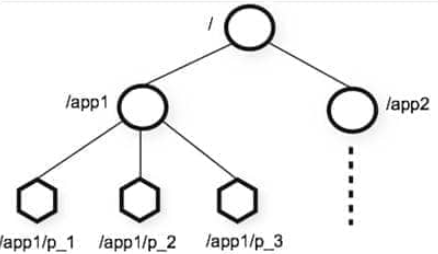
层次化的多叉树形结构,每个节点都可以存储数据(数字、字符串、二级制序列),根节点以“/”来代表。数据节点为 znode(最大为1M),每个 znode 都有一个唯一的路径标识
znode
- 类型:
- 持久(PERSISTENT)节点 :一旦创建就一直存在,直到将其删除
- 临时(EPHEMERAL)节点 :生命周期与客户端会话(session) 绑定,会话消失则节点消失 。只能做叶子节点 ,不能创建子节点
- 持久顺序(PERSISTENT_SEQUENTIAL)节点 :持久节点,且子节点名具有顺序性。如
/node1/app01、/node1/app02 - 临时顺序(EPHEMERAL_SEQUENTIAL)节点 :临时节点,节点名为自增的数字
- 数据结构:stat :状态信息 + data : 节点存放的数据的具体内容
- stat:myid、节点创建时的事务id、节点被修改时最新事务 ID(mZxid)、节点创建时间(time )、子节点个数(numChildren)、当前 znode 节点的版本号(dataVersion)、当前 znode 子节点的版本(cversion)、当前 znode 的 ACL 的版本(aclVersion)
- 每更新一次节点内容值增加 1、当前节点的子节点每次变化时值增加 1、节点 ACL 信息变更次数
ACL:AccessControlLists
- 类似unix的权限控制:
- CREATE:能创建子节点
- READ:能获取节点数据和列出子节点
- WRITE:能设置/更新节点数据
- DELETE:能删除子节点
- ADMIN:能设置节点 ACL 的权限
- 身份认证方式:
- world:默认,所有用户可无条件访问
- auth:不使用任何 id,代表任何已认证的用户
- digest:用户名:密码认证
- ip:对指定 ip 做限制
Watcher:事件监听器
- 用户在指定节点上注册,一些特定事件触发时,ZooKeeper 服务端将事件通知到感兴趣的客户端
- 一次性
Session:会话
- ZooKeeper 服务器与客户端的一个 TCP 长连接
- 客户端通过heartbeat与服务器保持会话,并向zk服务器发送请求接受响应,以及接收来自服务器的 Watcher 事件通知
sessionTimeout属性:会话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在sessionTimeout规定的时间内能够重新连接上集群中任意一台服务器,之前创建的会话仍然有效-
sessionID属性:为客户端创建会话前,服务端为每个客户端分配一个id,务必保证全局唯一
集群
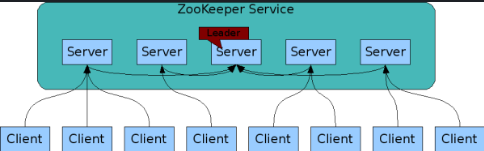
Server 代表 ZK 服务的服务器。在内存维护当前的服务器状态,服务器之间保持通信。集群间通过 ZAB 协议(ZooKeeper Atomic Broadcast)保持数据一致性
不使用Master/Slave 模式(主备模式):Master 服务器提供写服务,Slave 服务器异步复制 Master 最新的数据提供读服务
Leader、Follower 和 Observer
集群的机器通过 Leader 选举选定 Leader,为客户端提供写和读服务
Follower 和 Observer(3.3新增) 提供读。写请求会转发给leader。Observer 机器不参与 Leader 的选举过程,不参与写操作的“过半写成功”策略,因此 Observer 在不影响写性能的情况下提升集群的读性能
选票数据结构:
- logicClock 每个服务器会维护一个自增的整数,表示这是该服务器发起的第多少轮投票
- state 当前服务器状态
- self_id 当前服务器的myid
- self_zxid 当前服务器上的最大zxid
- vote_id 被推举的服务器的myid
- vote_zxid 被推举的服务器的最大zxid
Leader发生网络中断、重启等异常时,进入 Leader 选举
- Leader election(选举阶段):只要有一个节点得到超半数节点的票数,可以当选准 leader(初始化时,id小的服务器给id大的服务器投票;重新投票,则选择事务id大的)
- Discovery(发现阶段):followers 跟准 leader 进行通信,同步 followers 最近接收的事务id
- Synchronization(同步阶段):利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 成为真正的 leader
- Broadcast(广播阶段):集群对外提供事务服务,leader 可以进行消息广播。如果有新的节点加入,对新节点进行同步
服务器状态:
- LOOKING :寻找 Leader
- LEADING :Leader 状态,该节点为 Leader
- FOLLOWING :Follower 状态,节点为 Follower
- OBSERVING :Observer 状态,节点为 Observer,不参与 Leader 选举
奇数台服务器:2n+1台和2n+2台的容灾能力相同,都是允许n台机器宕机,减少成本
过半机制防止脑裂:不可能产生 2 个 leader
Zab协议(ZooKeeper Atomic Broadcast 原子广播)
Paxos 算法是一种通用的分布式一致性算法
实现分布式数据一致性。实现一种主备模式的系统架构保持集群中各个副本的数据一致性
崩溃恢复模式:服务启动,或者重新选择leader时的模式。当有了新 Leader,并且有过半机器完成状态(数据)同步后,退出恢复模式
- 初始化选举过程:(假设三台机器)
- 启动
server1,投票给自己 ,发出的投票为 (1,0),它票数不够不能作为Leader,整个集群处于Looking状态 -
server2启动,投票给自己(2,0),广播投票信息,server1在收到server2的投票信息后比较ZXID,如果相同则比较myid,myid大的优先作为Leader server1将自己的投票信息更改为(2,0)再广播出去,server2收到后发现和自己的一样无需更改,并且投票过半,则确定server2为Leader,server1设置为Follower,服务器从Looking变为正常状态-
server3启动发现集群没有处于Looking状态时,直接以Follower的身份加入集群
- 启动
- 重新选举leader:
-
server2挂了,两个Follower将状态 从Following变为Looking,每个server首先给自己投票,server1给自己投票(1,99)并广播,server3给自己投票(3,95)并广播 server1和server3收到彼此的投票,比较自己的投票和收到的投票(zxid大的优先,如果相同那么就myid大的优先)server3收到server1投票结果后更改投票为(1,99)并广播-
server1自己设为Leader,server3变为Follower
-
- 各个服务器都维护自己的选票箱,保存其他服务器的投票结果。因此如果一个leader选出来后,无需像raft通过心跳通知
- 需要确保已经被Leader提交的提案最终能够被所有的Follower提交,跳过已经被丢弃的提案
-
Leader (server2)发送commit请求,发送给server3,发给server1的时候突然挂了,此时根据上述过程,server3的ZXID肯定比server1的大,之后server3通过再同步,使得被所有follower提交 Leader (server2)发送commit请求前挂了,选举出新leader后又上线,此时新leader没有该记录,原先提案要被废弃
-
- 初始化选举过程:(假设三台机器)
消息广播模式:新服务器加入到集群时,新服务器进入数据恢复模式,然后参与到消息广播中
写:
- 客户端向Leader发起写请求
- Leader将写请求以Proposal的形式发给所有Follower并等待ACK
- Follower收到Leader的Proposal后返回ACK(Leader不需要得到Observer的ACK)
- Leader得到过半数的ACK(Leader对自己默认有一个ACK)后向所有的Follower和Observer发送Commit
- Leader将处理结果返回给客户端
- 如果为follower,则将写请求转发给Leader处理,最后follower返回客户端处理结果
顺序性:
ZAB让Follower和Observer保证顺序性 ,后者处理请求的顺序要和leader发送的一致- leader为每个其他的
zkServer准备一个队列 ,FIFO发送消息,和TCP协议一起保证消息的发送顺序性和接受顺序性,此时即使follower挂了,重启后也能顺序收到请求 - 事务ID
ZXID: 64位long型,高32位表示epoch年代,低32位表示事务id。一个Leader挂了,新的Leader上位时,年代(epoch)更改。每个proposal在Leader中生成后需要先通过其ZXID来进行排序
- leader为每个其他的
应用
客户端集群选取其集群的master
- zk能够在高并发的情况下保证节点创建的全局唯一性(创建节点,即写请求,由leader控制,而同一路径下的节点名称不能重复)
- 让多个客户端创建一个指定的临时节点 ,创建成功的就是
master,其他不是master的节点监听节点的状态(可以是该临时节点的父节点) - 如果这个
master挂了,该会话断开,该临时节点删除,父节点的stat改变,watcher机制会触发回调函数,使得客户端集群重新选举
分布式锁
分布式锁的实现方式:
Redis、数据库(在唯一索引对应字段,insert一行,insert成功则获取锁) 、zookeeperzk在高并发的情况下保证节点创建的全局唯一性,可以实现互斥锁
同样利用临时节点的创建来实现——多个客户端同时创建一个临时节点,创建成功说明获取到了锁 。没有获取到锁的客户端创建一个
watcher监听节点状态共享锁:
- 使用有序临时节点
- 读请求(要获取共享锁),要求没有比自己更小的节点,或比自己小的节点都是读请求,则可以获取到读锁
- 若比自己小的节点中有写请求 ,则当前客户端无法获取到读锁
独占锁:没有比自己更小的节点 ,则表示当前客户端可以直接获取到写锁,对数据进行修改。若有比自己更小的节点,当前客户端无法获取到锁
让等待的节点只监听他们前面的节点(读请求监听比自己小的最后一个写请求节点,写请求只监听比自己小的最后一个节点),避免羊群效应
Raft、Paxos、Zab
Raft和Zab的相似之处:单M架构、两者都要先写入leader、都为CP
Raft和Zab的区别:
项目 ZAB RAFT 节点状态 looking:选举状态,无主、leading、 following、 observing:不参与选举 leader、 follower、 candidate:不认leader的node 选举机制 默认FastLeaderElection: 节点启动直接投自己,然后开始给其他节点发请求,在每个朝代(epoch,raft里是term)中,节点先收到其他提案(proposal),然后本地battle(zxid, myid) 大小后再发出选票给所有node,一个朝代中每个节点可以发多次投票,一个节点收到半数以上选票则当选leader 每个candidate具备随机时钟(election timeout),到时间了先投自己,然后发消息给其他所有node,收到消息的candidate变为follower并回复,当半数原则满足后leader确立,leader再通告所有节点你们的leader出现了,停下手里的针线活吧。但每个朝代一个节点只能投票一次,而且candidate只响应大于自己term的请求,否则保持选举状态。 选举机制优劣 不存在分区、有利于选出有最新数据的node| battle次数过多造成选举时间长、首次启动会有myid节点大概率成为leader 选举速度快| 可能因为随机时钟差不多造成每个node的票数都没过半,发生投票分区,那只能进入下一个周期再选举 选主依据 1. epoch选举朝代、 2.ZXID:64BIT正整数,高32为epoch,低32为顺序自增的事务ID、 3. 机器myid 1. term朝代每一轮选举都增加、 2. 日志条目 3. election timeout 定时心跳 双方检测。 leader向所有follower发送定期心跳,心跳返回不过半则导致leader退位。follower没有收到来自leader的心跳会导致进入looking状态 单方检测。 follower定时没有接到心跳则变为candidate状态,自增term并准备选举 新节点加入 新节点启动先给所有node发消息,然后自己内部做选主依据信息battle 直接接到leader的append entry消息,就知道谁是leader了 写消息流程 两阶段:client请求followerA、followerA发请求给leader,leader对众follower发送proposal,过半后返回后再发commit,当followerA commit后返回客户端。 非两阶段:client请求follower,follower把消息转到leader后,leader写日志并向其他节点发AppendEntries,大多数返回后leader就向客户端返回。(之后的commit隐含在心跳和后续AppendRpc中) 消息一致性(线性顺序) zab利用client、leader、follower的多端努力,以自增的zxid为依据,保证写入强一致性(线性一致性)。若收到非顺序的zxid则禁止写入或节点退出。 相同的 term 和 index的节点之前内容肯定一样。选举时candidate携带最新 (term, index),如果对家小于自己则拒绝投票,所以选出来的leader肯定是大多节点里最新的。外加,提交也要过半成功。两者组合实现了一致性 消息顺序性 follower必须按顺序接收zxid和提交,否则退出进入恢复。 leader每次都发当前的消息和上一条消息,如果follower找不到上一条消息就不复制,再要求leader发上一条消息,直到定位到缺失消息。 残留消息一致性(follower有较新的未提交消息) 新leader上台后,leader尝试commit未提交的消息,没commit的proposal都会被丢弃 STRONG LEADER,非持有uncommitted log的新leader,会强制follower复制自己的日志解决一致性。 脏读 存在但几率低,leader 发proposal过半后再发commit,接收follower commit后才返回客户端 存在,leader 发消息过半ack后就返回client请求了,可能follower没有commit就没了、或者leader没发现自己丧失领导权等 持久性 WAL实现,zk将其优化为每个64MB的预占文件。snapshot压缩数据日志 类似zab,也是WAL + snapshot committed log raft的leader在commit了一条日志后,立刻挂了,其他节点如何处理这条日志?不存在commit log数组或uncommit log数组,都在log数组中,新leader一定是有这个log的,因为新leader在收到appendrpc的follower中选出,新leader会重新commit(节点存有变量commit_index)并应用到本地的状态机中
raft防止脑裂:
- 过半选举
- raft选举时参考最后一个log的term和index,而非candidate的term,保证leader的log一定是最新的(脑裂时一方会不停增大自己的term)
设计模式
七大原则
- 单一职责原则(Single Responsibility Principle)——一个类只负责一项职
- 开放-关闭原则(Open-Closed Principle)——软件实体 (类、模块、函数等等) 应该是可以被扩展的,但是不可被修改
- 里氏替换原则(Liskov Substitution Principle)——使用继承时候,类 B 继承类 A 时,除添加新的方法完成新增功能,尽量不要修改父类方法预期的行为
- 依赖倒转原则(Dependence Inversion Principle)——高层模块不应该依赖低层模块(面向接口编程)
- 接口隔离原则(Interface Segregation Principle)——客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上
- 迪米特法则,又称为最少知道原则(Law Of Demeter)——一个对象应该对其它对象保持最少的了解。通俗来说就是,只与直接的朋友通信
- 组合/聚合复用原则(Composite/Aggregate Reuse Principle)——在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分; 新的对象通过向这些对象的委派达到复用已有功能的目的
单例模式
一个类仅有一个实例,并提供一个访问它的全局访问点
几种实现方法,常用的是什么?
饿汉式:浪费内存,线程安全(基于 classloader 机制避免了多线程的同步问题),不管你用的用不上,一开始就建立这个单例对象
1
2
3
4
5
6
7public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}懒汉式:单线程下有效,多线程下不安全(真正用到的时候才去建这个单例对象)
1
2
3
4
5
6
7
8
9
10
11public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}懒汉式且线程安全(加锁,影响效率)
1
2
3
4
5
6
7
8
9
10public class Singleton {
private static Singleton instance;
private Singleton (){}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class SingleObject {
//创建 SingleObject 的一个对象
private static SingleObject instance = new SingleObject();
//让构造函数为 private,这样该类就不会被实例化
private SingleObject(){}
//获取唯一可用的对象
public static SingleObject getInstance(){
return instance;
}
public void showMessage(){
System.out.println("Hello World!");
}
}
工厂模式
- 在创建对象时不会对客户端暴露创建逻辑,通过使用一个共同的接口来指向新创建的对象
- 明确地计划不同条件下创建不同实例时使用,让子类自己决定实例化哪一个工厂类
一般的工厂模式
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39public interface Shape {
void draw();
}
// 工厂
public class ShapeFactory {
//使用 getShape 方法获取形状类型的对象
public Shape getShape(String shapeType){
if(shapeType == null){
return null;
}
if(shapeType.equalsIgnoreCase("CIRCLE")){
return new Circle();
} else if(shapeType.equalsIgnoreCase("RECTANGLE")){
return new Rectangle();
} else if(shapeType.equalsIgnoreCase("SQUARE")){
return new Square();
}
return null;
}
}
// 要创建的类
public class Rectangle implements Shape {
public void draw() {
System.out.println("Inside Rectangle::draw() method.");
}
}
public class Square implements Shape {
public void draw() {
System.out.println("Inside Square::draw() method.");
}
}
抽象工厂
提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类
系统的产品有多于一个的产品族,而系统只消费其中某一族的产品
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88public interface Shape {
void draw();
}
public class Square implements Shape {
public void draw() {
System.out.println("Inside Square::draw() method.");
}
}
public class Square implements Shape {
public void draw() {
System.out.println("Inside Square::draw() method.");
}
}
public interface Color {
void fill();
}
public class Green implements Color {
public void fill() {
System.out.println("Inside Green::fill() method.");
}
}
public class Red implements Color {
public void fill() {
System.out.println("Inside Red::fill() method.");
}
}
// 工厂
public abstract class AbstractFactory {
public abstract Color getColor(String color);
public abstract Shape getShape(String shape);
}
public class ShapeFactory extends AbstractFactory {
public Shape getShape(String shapeType){
if(shapeType == null){
return null;
}
if(shapeType.equalsIgnoreCase("CIRCLE")){
return new Circle();
} else if(shapeType.equalsIgnoreCase("RECTANGLE")){
return new Rectangle();
}
return null;
}
}
public class ColorFactory extends AbstractFactory {
public Color getColor(String color) {
if(color == null){
return null;
}
if(color.equalsIgnoreCase("RED")){
return new Red();
} else if(color.equalsIgnoreCase("GREEN")){
return new Green();
}
return null;
}
}
// 工厂创造器/生成器类,通过传递形状或颜色信息来获取工厂
public class FactoryProducer {
public static AbstractFactory getFactory(String choice){
if(choice.equalsIgnoreCase("SHAPE")){
return new ShapeFactory();
} else if(choice.equalsIgnoreCase("COLOR")){
return new ColorFactory();
}
return null;
}
}
装饰器模式
向一个现有的对象添加新的功能,同时又不改变其结构——作为现有的类的一个包装
就增加功能来说,装饰器模式相比生成子类更为灵活(是继承的一个替代模式,可以动态扩展一个实现类的功能)
代码:
准备:
1
2
3
4
5
6
7
8
9
10public interface Shape {
void draw();
}
public class Rectangle implements Shape {
public void draw() {
System.out.println("Shape: Rectangle");
}
}创建实现了 Shape 接口的抽象装饰类和实体装饰类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public abstract class ShapeDecorator implements Shape {
protected Shape decoratedShape;
public ShapeDecorator(Shape decoratedShape){
this.decoratedShape = decoratedShape;
}
public void draw(){
decoratedShape.draw();
}
}
public class RedShapeDecorator extends ShapeDecorator {
public RedShapeDecorator(Shape decoratedShape) {
super(decoratedShape);
}
public void draw() {
decoratedShape.draw();
setRedBorder(decoratedShape);
}
// 增加的装饰功能
private void setRedBorder(Shape decoratedShape){
System.out.println("Border Color: Red");
}
}
模板方法模式
一个抽象类公开定义了执行它的方法的方式/模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// 模板方法被设置为 final
public abstract class Game {
abstract void initialize();
abstract void startPlay();
abstract void endPlay();
//模板
public final void play(){
//初始化游戏
initialize();
//开始游戏
startPlay();
//结束游戏
endPlay();
}
}
public class Cricket extends Game {
void endPlay() {
System.out.println("Cricket Game Finished!");
}
void initialize() {
System.out.println("Cricket Game Initialized! Start playing.");
}
void startPlay() {
System.out.println("Cricket Game Started. Enjoy the game!");
}
}
代理模式
一个类代表另一个类的功能,为其他对象提供一种代理以控制对这个对象的访问
通常,如果想在访问一个类时做一些控制,可以增加一个中间层
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public interface Image {
void display();
}
public class RealImage implements Image {
private String fileName;
public RealImage(String fileName){
this.fileName = fileName;
loadFromDisk(fileName);
}
public void display() {
System.out.println("Displaying " + fileName);
}
private void loadFromDisk(String fileName){
System.out.println("Loading " + fileName);
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 当被请求时,使用 ProxyImage 来获取 RealImage 类的对象
public class ProxyImage implements Image{
private RealImage realImage;
private String fileName;
public ProxyImage(String fileName){
this.fileName = fileName;
}
public void display() {
if(realImage == null){
realImage = new RealImage(fileName);
}
realImage.display();
}
}
场景题
- 40亿条数据去重(长度相同):
- 布隆过滤器
- 基于第一个字符分桶,建立树结构
- 网页上打开个二维码,手机扫描登录这个过程如何实现?
- 线上服务 CPU 占用过高怎么排查(JVM调优)
- A 和 B 进行 TCP 传输,B 的网线被拔了,A会怎么做
- 设计一个分布式文件系统
- 当数据量非常多,读不进来内存,如何排序
- 秒杀,如何设计一个 redis+mysql 的结构,让其能承载很高的 qps 而不被打
- 设计本地缓存+redis 缓存的多级缓存
- 如何保证 redis 和 mysql 的一致性
- 如果 redis 挂了咋办?如果mysql挂了咋办
- 存一个 key-value 数据类型,查询的时候使用模糊查询,应该怎么设计数据结构?(前缀树)
- redis 中当数据量逐渐变大时,底层是怎么优化数据结构的?(sds、rehash、跳表)
- Dockerfile 关键字有哪些,说几个重要的以及含义
- 有一亿个随机数,只有 1k 的内存可以用,找中位数
- 微博上某个大 V 突然发个什么结婚啊离婚的声明,经常挂掉,是吧?你有什么好的措施来 预防这个问题呢?
- 高峰期,想保证买家尽可能在半小时收到外卖,你有什么优化思路
- 怎么保证 Redis 的高可用性
- 查询上万条数据中某个字段在某个范围内的记录,怎么优化,假如查出来有上千条上万条,怎么处理
- Redis 中的数据能做到绝对可靠不丢失嘛?能。如何做到?还是要丢失性能换取可靠,让 AOF 时 刻刷盘并同步
- 如何实现群聊功能
- 我牛客是如何实现视频连线面试的
算法题
- 找 N 叉树最长的连续节点
- 实现一个哈希表
- 反转链表该怎么实现
- 讲讲排序算法,他们的稳定性
- z 字形打印二叉树
- 链表增删改查
- 假设有一万个数,如何找出出现次数等于 10 的数(数字大小:1~20 万)
- 数组中出现次数超过一半的元素
- 二分查找
- 手写快排,并给出最坏情况
- 无序数组的前 K 小的数字
- 高精度大数乘法,大数乘大数 https://leetcode-cn.com/problems/multiply-strings/
- 最小覆盖子串
- 字符串分隔 s=abcd,dict={ab, c, d, cd},s 只能切割为 dict 中存在的子串,返回所有合法的分割方法
- 子树中最大路径和
- 实现一个循环队列, 基于数组实现, 实现其中的入队,出队方法, size =5
- 合并两条升序链表
- 最长公共子序列
- 数组逆序对
- 连续整数之和为 1000,有多少组
- 三层的二叉树多少种?
- 合并 K 个有序链表
- 电梯的调度算法
- 链表中删除重复元素
- 约瑟夫问题
- 给定一个无序数组,求出需要排序的最短子数组的长度 arr={1,5,3,4,2,6,7}返回 4,因为只有[5,3,4,2]需要排序
- 一个未排序数组里面有有一个数只出现一次,其余的都出现三次,怎么找到这个数
Spring
Spring ioc,bean生命周期
Springboot的优势
spring 事务传播机制
.springMVC 各层作用,和数据库交互用哪个,怎么使用,dao 层全称是什
spring 的特性,以及使用场景
git 发生冲突时候怎么处理
为什么要二级缓存——多级缓存的实现

