《ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS》(ALBERT ICLR 2020)
摘要
- 提出两种参数缩减技术,来降低内存消耗,提高BERT的训练速度
- 使用一种专注于句子间连贯性建模的自监督损失,它有助于下游的多句输入任务
- 模型在benchmark GLUE、RACE和SQuAD上为SOTA
介绍
- 提出A LITE BERT(ALBERT),使用两个参数缩减技术
- 分解embedding参数计算过程:将大的嵌入矩阵分解为两个小的矩阵,以此将隐藏层的size与词汇表嵌入的size分开,使得在不用提高embedding size的情况下提高hidden size
- cross-layer parameter sharing:防止参数随着网络深度增加过度增长
- 18x fewer parameters,1.7x faster than BERT-large
- 预训练任务中,NSP被SOP取代(sentence-order prediction)——解决了NSP损失的无效性问题
相关工作
cross-layer parameter sharing
- 研究表明,具有跨层参数共享的网络(Universal Transformer,UT)在语言建模和主谓一致方面的性能优于标准的Transformer
- 研究人员后来将参数共享的transformer与标准的transformer相结合,进一步增加标准transformer的参数数量
SOP
- 语篇的连贯与衔接通常是训练目标
- Skipthought (2015)、和FastSent(2016)使用一个句子的编码来预测相邻句子中的单词,来学习句子嵌入
- 其他目标包括预测未来的句子,而不仅仅是相邻的句子(2017)和预测明确的话语marker(2017、2019)
- 本文SOP损失定义在文本片段而不是句子上定义的
ALBERT
模型结构
骨干网络类似BERT,使用transformer的encoder和GELU非线性化
记字典embedding size为E、层数为L、hidden size为H,设置feed forward/filter size为4H,attention head为H/64
分解的embedding参数化:
- BERT、XLNet、RoBERTa都要求E=H,此时的embedding矩阵规模就是V*E,其中的参数只在训练时稀疏地更新
- 从建模角度,wordpiece embedding用于学习上下文无关的表征,hidden layer用于学习上下文相关的表征,因此可以将WordPiece embedding size E从hidden layer size H分离,即使得H>>E
- 本文将独热向量先投影到一个低维度embedding空间,再投影到隐藏空间,而非将独热向量直接投影到size为H的隐藏空间中,此时嵌入参数从V*H变成V*E+E*H
- 对所有的wordpiece使用相同的E——和whole word嵌入相比,wordpiece在文档中分布更加均匀,并且whole word嵌入具有不同的嵌入大小,这对于不同的词语来说是很重要的
Cross-layer parameter sharing
共享参数的方法有很多种,例如仅跨层共享feed forward net参数,或仅共享注意力参数
ALBERT默认跨层共享所有参数
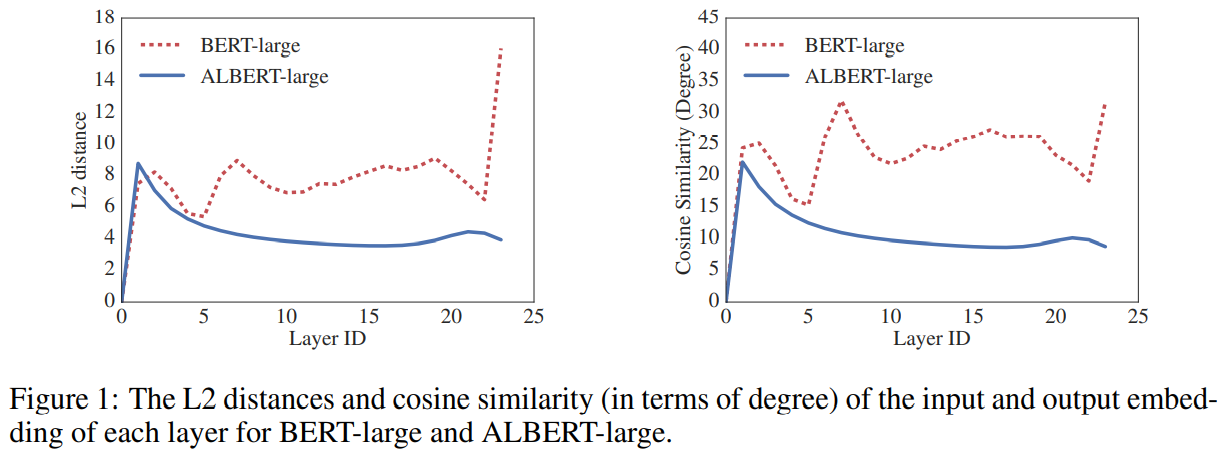
ALBERT从一层到另一层的过渡比BERT的平滑得多,权重共享对网络参数的稳定有一定的作用;尽管与BERT相比,两个指标都有所下降,但24层之后也不会收敛到0——解空间和DQE网络有很大不同
SOP:
- 后续研究表明NSP不可靠——本文认为,NSP效果差的主要原因是,与MLM相比,其任务难度较低
- NSP将主题预测和连贯预测结合到一个任务中,而主题预测比连贯性预测更容易学习,并且和MLM学习到的内容有更多重叠
- SOP避免了主题预测,专注于对句子连贯性的建模。SOP以来自同一文档的两个连续段为正例,以二者的顺序颠倒为反例,迫使该模型学习更细粒度的话语层面的连贯性
模型set up

实验结果
实验set up
输入格式为[CLS]x[SEP]y[SEP]
限制最大输入长度为512,10%为随机生成小于512的输入序列
使用sentencepiece做tokenize(同XLNet)
使用n-gram masking做MLM,n最大为3,n的概率为:
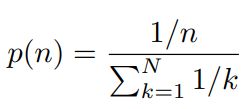
batchsize 4096
使用LAMB优化器,学习率0.00176
评估benchmark
略
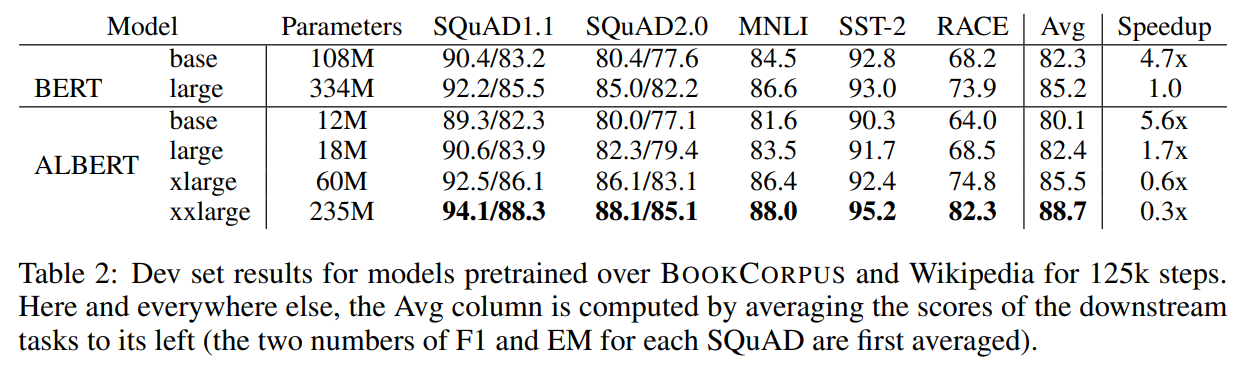
BERT与ALBERT的整体对比

消融实验
略

