《MapReduce: Simplified Data Processing on Large Clusters》(OSDI,2004)
摘要
- 用户写一个map函数,处理key-value对以生成一组中间key-value对的,写一个reduce函数以合并与同一个中间key相关联的所有中间value
- 运行时系统负责划分输入数据、跨一组机器调度程序的执行、处理机器故障以及管理所需的机器间通信的细节
介绍
- 大部分计算涉及到对输入中的每个逻辑“记录”应用一个map计算,以计算一组中间key-value对,然后对共享相同键的所有值应用一个reduce运算,以便适当地组合中间数据数据
- 提供简单而强大的接口,支持大规模计算的自动并行化和分布式
编程模型
- 输入key-value对,输出key’-value对,此过程通过Map函数和Reduce函数实现
- Map函数输入为key-value对,并输出中间key-value对。框架将收集所有key为I的value,发送给Reduce函数
- Reduce函数接收一个中间key(key为I)和一个value集合,并进行下一步处理
实例

- map发出每个单词和其出现次数,reduce统计某个单词的出现总次数
- map和reduce函数具有相关联的类型
其他应用
- distributed grep
- count of url access frequency
- reverse web link graph——原始输入为(source, target),reduce输出为(target, list(source))
- Term-Vector per Host——term vector将一个文档或一组文档中出现的最重要的单词整合为列表,列表元素为(word, frequency),map函数会输出(hostname, term vector),reduce函数统计这些并得到最终的(hostname, term vector)
- Inverted Index:map函数解析文档,并输出(word, document id)序列,reduce函数接收给定单词的所有pair,并对相应的document id排序,得到(word, list(document id))
- Distributed Sort
实现
描述了一个针对Google计算环境的实现
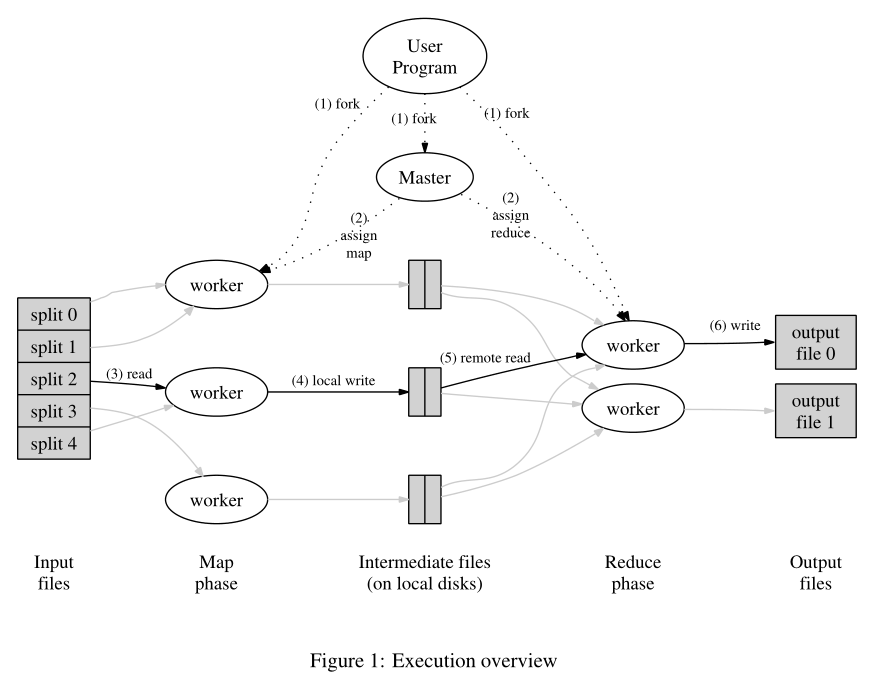
执行概述
- 自动划分输入数据为M份,分布在多个机器上
- Reduce的调用使用分区函数,将中间key的空间划分为多个piece
- 用户调用mapreduce函数时
- 将输入文件分割为多个片段
- master节点选择空闲的worker,分配map或者reduce任务
- 分配了map的worker读取相应的分割片段,解析出key-value并传递给用户定义的处理函数,生成的中间key-value在内存中缓存
- 缓存的内容周期性写入本地磁盘,写入的路径被返回给master节点
- master将路径通知给reduce worker,reduce worker使用RPC从map worker读取数据,读取完所有的中间数据后,根据中间key对数据排序,此时相同的key被组合起来。如果中间数据过多,则会使用一个external sort
- reduce worker遍历中间数据,对于唯一的中间key,它将key和相应的value列表传给用户定义的reduce函数,函数输出会放到reduce worker的最终输出文件中
- 当所有map和reduce task完成,唤醒用户程序,用户程序中对MapReduce的调用会返回数据给用户程序
- 通常,用户会将输出内容作为新的输入,传递给另一个MapReduce
Master Data Structure
- 对每个map task和reduce task,存储其状态和worker的id,对每个完成的map task,存储其产生的中间文件位置和大小
Fault Tolerance
- worker failure
- master会定期ping worker
- 一定时间内没有收到来自worker响应,则master将其标记为failure,相应线程完成和进行的任何map task都被重置回它们的初始状态
- 已完成的map task出现故障时会重新执行,因为输出存储在故障机器的本地磁盘上,不可访问
- 完成的reduce task不需要重新执行,它们的输出存储在全局文件系统中
- MapReduce对大规模worker故障具有弹性
- master failure
- 如果主设备出现故障,当前的实现会中止MapReduce计算
本地网络带宽
- 利用输入数据存储在构成集群的机器的本地磁盘上,来节省网络带宽
- GFS将每个文件分成64MB的块,在不同的计算机上存储每个块的多个副本
- MapReduce主服务器会记录输入文件的位置,并尝试在包含相应输入数据副本的计算机上安排map task,若分配失败,则会尝试将map task安排在相应task的输入数据副本附近
- 此时运行MapReduce任务时,大多数输入数据在本地读取的,不消耗网络带宽
任务粒度
- 将map阶段分为M个pieces,reduce阶段分为R个pieces
- 一般M和R要远大于worker的数目
- 但master节点必须做出O(M+R)个调度策略,并内存中保存O(M*R)个状态
Backup Tasks
导致MapReduce操作总时间延长的一个常见原因是“掉队者”(straggler)——花费异常长的时间来完成最后几个map或Reduce任务
解决机制:当MapReduce操作接近完成时,主服务器会计划剩余的 in-progress task的备份执行,只要主执行或备份执行完成,相关任务就会被标记为已完成
When a MapReduce operation is close to completion, the master schedules backup executions of the remaining in-progress tasks.
改良
略
性能
略

