MIT-6.824 Lab2A 总结与备忘
思路整理
重点参考论文的Fig2
Lab2A需要实现Raft的领导选举功能:
状态转换过程如下:
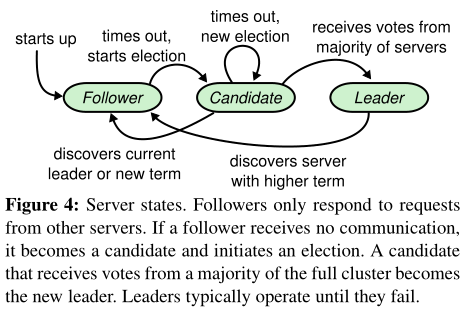
当服务器启动时,初始化为follower。只要能够收到来自leader或者candidate的有效RPC,服务器会一直保持follower的状态
leader会向所有follower周期性发送心跳来保证leader地位。如果一个follower一个周期内没有收到心跳,则选举超时(election timeout)
为了开始选举,follower自增它的当前任期并转换状态为candidate,给自己投票并且给其他服务器发送RequestVote RPC。一个candidate会一直处于该状态,直到下列三种情形之一发生:
- 赢得了选举:candidate在任期内收到大多数服务器的投票,会赢得选举,然后立刻向其他服务器发送心跳来建立领导地位,阻止新的选举
- 另一台服务器赢得了选举:新leader的任期(应当包含在RPC中)大于等于当前candidate的任期,则candidate转为follower
- 一段时间后没有任何一台服务器赢得了选举:每一个candidate都超时,自增任期号并发起另一轮RequestVote RPC,开始新的选举——选举超时时间是在一个固定时间间隔里随机产生的
广播时间(broadcastTime) << 选举超时时间(electionTimeout) << 平均故障间隔时间(MTBF),代码中超时时间为
const RaftElectionTimeout = 1000 * time.Millisecond,因此可以设置心跳时间间隔为50ms
综上:
每个服务器(代码中的
type RPC)有:mu:锁me:idvoted_for:给某个raft投票cur_term:当前的任期号state:当前的状态get_vote_num:获得投票的数目log:Entry列表timeout:最后一次收到心跳或其他Entry的时间其他变量见fig2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
voted_for int // candidate id(rf.me)that received vote in current term
cur_term int // 当前的term
timeout time.Time // 接收心跳的时间上线,超过该时间则follower成为candidate
state string // 状态: follower candidate leader
get_vote_num int // 该实例得到的票数
log []Entry
commit_index int // index of highest log entry known to be committed
last_applied int // index of highest log entry applied to state machine
next_index []int
match_index []int
applyCh chan ApplyMsg
// SnapShot Point use
last_snapshot_point_index int
last_snapshot_point_term int
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
}
为了判别RPC是否合法,RPC的Args和Reply包含:
- Args:
Term:申请选举的任期Candidate_index:candidate的id-
Last_log_term:term of candidate’s last log entry Last_log_index:index of candidate’s last log entry
- Reply:
Term:收到RPC的服务器的任期Vote_for_you:是否投票给args对应的candidate
- Args:
关键代码
根据raft的功能设置两个goroutine:选举、发送Entry(后续可能还有其他功能)
选举goroutine:
每sleep一段时间(该时间对每个实例都是一个长于心跳周期的随机时间),就检查sleep之间记录的时间是否超过了
timeout。如果leader发生故障,记录的时间一定会在timeout之后。如果leader没有故障,则在该goroutine sleep的时候,会更新timeout,该时间戳会在记录时间之后当发现记录时间在
timeout之后,并且实例不是leader,则转换为candidate,并开始选举1
2
3
4
5
6
7
8
9
10
11
12
13
14func (rf *Raft) candidate_election_ticker() {
for !rf.killed() {
now := time.Now()
time.Sleep(time.Duration(getRand(int64(rf.me))) * time.Millisecond) // 随机选举超时时间,错开时间以防止选票分割
// 这里随机的时间长于心跳,因此如果leader出问题,那么下面的if判断一定为true
// 而如果leader没有出问题,那么rf.timeout会在另一个goroutine里被更新,下面if判断一定为false
rf.mu.Lock()
if now.After(rf.timeout) && rf.state != "leader" {
// 当前时间在rf心跳期限之后,并且rf不是leader
rf.change_state(TO_CANDIDATE, true)
}
rf.mu.Unlock()
}
}为了方便,将状态转换实现为一个函数,并且——需要明确什么时候才更新timeout变量(收到新的entry,以及开始新的选举)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15func (rf *Raft) change_state(change_to int, reset_timestamp bool) {
if change_to == TO_CANDIDATE {
rf.state = "candidate"
rf.cur_term += 1
rf.get_vote_num = 1 // 投自己一票
rf.voted_for = rf.me
rf.candidate_election()
rf.timeout = time.Now()
}
// if change_to == TO_FOLLOWER {}
// if change_to == TO_LEADER {}
}candidate_election()实现选举功能,包含两个步骤:发送RPC和处理RPC的结果。candidate并行地向集群里的其他成员发送RequestVote RPC——即在一个for循环里,创建goroutine
处理返回结果时,要分类讨论:
- 如果发送request前后,candidate的状态会不会发生变化
- 如果reply的term更大,怎么办
- 如果投票给自己了,怎么办
一个函数内加了锁,那么函数结束前需要解锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45func (rf *Raft) candidate_election() {
for index := range rf.peers {
if index == rf.me {
continue
}
// 并行发送request vote和处理request reply
go func(server_id int) {
rf.mu.Lock()
vote_args := RequestVoteArgs{
Term: rf.cur_term,
Candidate_index: rf.me,
Last_log_term: rf.get_last_term(),
Last_log_index: rf.get_last_index(),
}
vote_reply := RequestVoteReply{}
rf.mu.Unlock()
ok := rf.sendRequestVote(server_id, &vote_args, &vote_reply)
rf.mu.Lock()
defer rf.mu.Unlock()
if ok {
if rf.state != "candidate" || vote_args.Term != rf.cur_term {
// 发送request前后,rf的term发生改变
return
}
if vote_reply.Term > rf.cur_term {
// rule1不满足
rf.cur_term = vote_reply.Term
rf.change_state(TO_FOLLOWER, false) // 没有收到appendentry rpc时,不要重置时间
return
}
if vote_reply.Term == rf.cur_term && vote_reply.Vote_for_you {
// 记录投票
rf.get_vote_num += 1
if rf.get_vote_num >= len(rf.peers)/2+1 {
rf.change_state(TO_LEADER, true)
}
return
}
}
}(index)
}
}
发送了RPC后,被询问的raft要在
RequestVote ()里,根据args和自己的情况,判断是否给当前的candidate投票。需要考虑:是否满足rule1
如果raft的term偏小,则转换为follower——此时即使raft是candidate,由于自己的term小于args的term,也要变成follower
如果raft的term相同,并且是follower,则当前的candidate是否保存了最新的log——这是
is_updated()要判断的内容1
2
3
4
5
6
7// 检查当前raft存储的log是否新于输入的index和term
func (rf *Raft) is_updated(index, term int) bool {
cur_log_index_saved := rf.get_last_index()
cur_term_saved := rf.get_last_term()
return cur_term_saved > term ||
cur_term_saved == term && cur_log_index_saved > index
}如果raft的term相同,那么raft此时是不是candidate——即是否已经投票过了。注意,这里即使投票了也先不转为follower,必须收到心跳才成为follower!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// rf为接收申请的服务器
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.cur_term > args.Term {
// candidate的term偏小(fig2 rule1)
reply.Vote_for_you = false
reply.Term = rf.cur_term
} else {
// candidate的term不小于rf的term时,考虑两种情况(fig2 rule2)
if rf.cur_term < args.Term {
// rf的term偏小,rf转为follower
rf.cur_term = args.Term
rf.change_state(TO_FOLLOWER, false)
}
if (rf.voted_for == -1 || rf.voted_for == args.Candidate_index) &&
!rf.is_updated(args.Last_log_index, args.Last_log_term) &&
rf.cur_term == args.Term {
rf.voted_for = args.Candidate_index
rf.cur_term = args.Term
rf.timeout = time.Now() // 重置时间
reply.Vote_for_you = true
reply.Term = rf.cur_term
} else {
// 可能已经给其他人投票了(或者自己就是candidate)
reply.Vote_for_you = false
reply.Term = rf.cur_term
}
}
}经过以上过程,完成选举(此时尚未发送心跳给其他对象)
发送Entry的goroutine:
心跳是内容为空的log entry,因此二者可以合并
同样地,每sleep一段时间(该时间为心跳周期,可以认为,leader每过一个心跳周期发送一个log,如果有信息更新,则同时实现heartbeat和日志复制,否则只有heartbeat),就检查raft实例是不是leader,如果是leader则开始发送log entry
1
2
3
4
5
6
7
8
9
10
11
12func (rf *Raft) leader_append_entries_ticker() {
for !rf.killed() {
time.Sleep(heat_beat_time)
rf.mu.Lock()
if rf.state == "leader" {
rf.mu.Unlock()
rf.leader_append_entries()
} else {
rf.mu.Unlock()
}
}
}leader_append_entries()在2A里只用实现心跳的发送,此时appendentries RPC相应args和reply结构体如下(并不完整,但足以完成heartbeat)1
2
3
4
5
6
7
8
9
10type AppendEntryArgs struct {
Term int // 当前leader任期
Leader_id int // 当前leader id
}
type AppendEntryReply struct {
Term int // current term
Success bool // True if follower contained entry which matched the prev_log_index and term
}leader_append_entries()同样并行地构造args和reply,发送并分析返回结果(”分析结果“2a暂未实现)。由于2a只实现选举,因此args里的内容只需要填充一部分即可1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52func (rf *Raft) leader_append_entries() {
for index := range rf.peers {
go func(follower_id int) {
if follower_id == rf.me { // 不向自己发送消息
return
}
rf.mu.Lock()
if rf.state != "leader" {
rf.mu.Unlock()
return
}
entry_args := AppendEntryArgs{}
if rf.get_last_index() >= rf.next_index[follower_id] {
// 发送append entry RPC
// TODO: 一般的entry
} else {
// 发送心跳
// prevLogIndex, prevLogTerm := rf.getPrevLogInfo(server)
entry_args = AppendEntryArgs{
rf.cur_term,
rf.me,
0, // prevLogIndex,
0, // prevLogTerm,
[]Entry{},
rf.commit_index,
}
}
entry_reply := AppendEntryReply{}
rf.mu.Unlock()
ok := rf.sendAppendEntries(follower_id, &entry_args, &entry_reply)
rf.mu.Lock()
defer rf.mu.Unlock()
if ok {
if rf.state != "leader" {
// 可能不再是leader
return
} else {
if rf.cur_term < entry_reply.Term {
rf.cur_term = entry_reply.Term
rf.change_state(TO_FOLLOWER, true)
} else {
return
}
}
}
}(index)
}
}
发送了RPC后,被询问的raft要在
RequestVote ()里,根据args和自己的情况,判断是否更新心跳,以及复制日志(复制日志在2a里暂未实现)。需要考虑:- args的term是否大于raft的term
- 更新状态和心跳时间戳——这也意味着选举完成,收到心跳的raft都更新状态为follower并更新时间戳
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23func (rf *Raft) AppendEntries(args *AppendEntryArgs, reply *AppendEntryReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.cur_term > args.Term {
// 不满足rule1
reply.Term = rf.cur_term
reply.Success = false
return
}
rf.cur_term = args.Term
reply.Term = rf.cur_term
reply.Success = true
// 收到心跳,更新状态和时间戳
if rf.state != "follower" {
rf.change_state(TO_FOLLOWER, true)
} else {
rf.timeout = time.Now()
}
return
}
在实现的过程中,一定一定要留意加锁和解锁是否一一对应

