《ZooKeeper: Wait-free coordination for Internet-scale systems》(ZooKeeper,2010)
这篇论文在读的时候因为没有合适的例子,理解起来很费劲。。。
摘要
- ZooKeeper是一种用于协调分布式应用程序进程的服务
- 提供一个简单而高性能的内核,用于在客户端构建更复杂的协调原语。在一个可复制的集中式服务中,集成了组消息传递(group messageing)、共享寄存器和分布式锁服务
- ZooKeeper公开的接口在共享寄存器方面具有无等待特性,使用类似于分布式文件系统缓存失效的事件驱动机制,提供简单而强大的协调服务
- ZooKeeper接口支持高性能的服务实现:
- 无等待的特性
- 为每个客户端提供FIFO的执行请求保证,将所有改变ZooKeeper状态的请求线性化
- ZooKeeper可以每秒处理数以十万计的事务,因此客户端应用程序可以广泛使用ZooKeeper
介绍
- 大规模分布式应用需要不同形式的协调,配置(Configuration)是最基本的协调形式之一,它是系统进程的操作参数列表,更复杂的系统需要具有动态配置参数
- 组成员关系和领导选举在分布式系统中很常见:进程需要知道哪些其他进程是存活的以及负责内容
- 锁是一个协调原语,实现对关键资源的互斥访问
- ZooKeeper放弃在服务端实现特定的原语,而是暴露API,开发人员能够实现自己的原语——为此实现了一个协调内核(coordination kernel),新原语的实现不需要改变服务核心,使得多种形式的协调能够适应应用的需求
- ZooKeeper放弃阻塞原语的实现(比如锁),因为阻塞原语(Blocking primitives)会带来很多问题,如客户端变慢或故障
- Zookeeper实现了一个 API,可以操作像文件系统那样分层组织的简单的无等待数据对象。
- ZooKeeper实现了一个通用对象。
- 服务由一组使用复制来实现高可用性和高性能的服务器组成,能够使用简单的管道结构来实现ZooKeeper,以处理数百或数千个请求的同时仍保证低延迟。这样的管道自然支持按FIFO顺序从单个客户端执行操作,而保证FIFO客户端的顺序使客户端可以异步提交操作, 使用异步操作,客户端一次可以执行多个未完成的操作。
- 为了保证更新操作满足线性化的要求,实现一个基于leader的原子广播协议,称为Zab(ZooKeeper Atomic Broadcast))
- ZooKeeper中,服务器本地化处理读操作,不使用Zab对读操作进行完全排序
- ZooKeeper使用一种监视机制,使客户端可以缓存数据,而无需直接管理客户端缓存。 使用此机制,客户端可以监视给定数据对象的更新,并在更新时接收通知。
- 本文的主要贡献:
- 协调内核(Coordination kernel):提出了一种无等待的协调服务,该服务具有宽松的一致性保证,可用于分布式系统。论文描述了协调内核的设计与实现,并且已在许多关键应用程序中使用它实现各种协调技术
- 协调方法(Coordination recipes):展示了ZooKeeper如何用于构建更高级别的协调原语,甚至包括阻塞和强一致性原语
- 协调经验(Experience with Coordination):分享了一些使用ZooKeeper并评估其性能的方式
ZooKeeper服务
- client使用ZooKeeper client library,通过clientAPI向ZooKeeper提交请求。 client library还管理client与ZooKeeper服务器之间的网络连接
- 术语:
- client表示ZooKeeper服务的用户
- server表示提供ZooKeeper服务的进程
- znode表示ZooKeeper数据中的内存数据节点,它被组织在称为数据树的分层命名空间中。
- update和write表示修改数据树状态的任何操作
- client在连接到ZooKeeper时会建立一个会话,并获得一个会话句柄,通过句柄(handle)发出请求
Service Overview
ZooKeeper给client提供根据分层命名空间组织的一组数据节点(znode)的抽象:
znode是client通过ZooKeeper API操作的数据对象
分层命名空间是组织数据对象的一种理想方式
引用给定的znode时,使用标准的UNIX符号表示文件系统路径。 例如,/A/B/C表示到znode C的路径
所有znode都存储数据,除临时znode之外的所有znode都可以有子节点
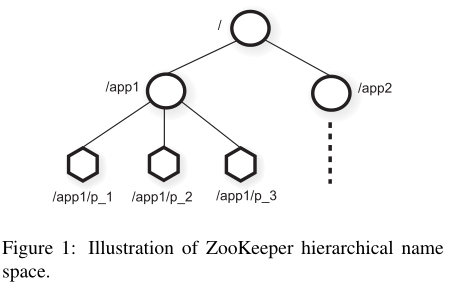
客户端可以创建两种类型的znode:
- 普通(Regular):客户端能显式地创建和删除普通的znode;
- 临时(Ephemeral):客户端创建临时znode后,要么显式地删除,要么系统在会话终止时自动删除(包括人为或者意外导致故障
- 创建一个新的znode时,客户端可以设置一个顺序标志(sequential flag),此时该节点后面附加一个单调递增的计数器值,如果n是新的znode, p是父znode,n的序列值永远不会小于在p下创建的任何其他顺序znode的名称中的值
ZooKeeper实现了监视器(Watches),客户端不需要轮询便能接收更改通知
- 客户端发出设置监视标志的读取操作时,服务器会承诺在返回的信息发生变化时通知客户端
- 监视器在一次会话内是一次性触发的,一旦触发或会话关闭,监视器就会被移除
- 监视器只会通知更改的发生,而不会提供更改的内容
数据模型(Data model):ZooKeeper的数据模型本质上是一个文件系统,有一个只能读写完整的数据的简化API。znode不是为了通用的数据存储而设计的,它通常对应于用于协调目的的元数据
- 上图有两个子树,一个用于应用程序1 (/app1) ,另一个用于应用程序2(/app2)
- 应用程序1的子树实现一个简单的group membership protocol:每个客户端进程$$p_i$$在/app1下创建一个znode pi,只要该进程正在运行就一直存活
ZooKeeper允许客户端存储一些可用于分布式计算中的元数据或配置的信息
会话(Sessions):客户端连接到ZooKeeper会启动一个会话(有一个超时时间,超过该时间内ZooKeeper没有收到会话的任何消息,则认为客户端故障)。在一个会话中,客户端观察一系列反映其操作执行情况的状态变化。会话使客户端在ZooKeeper集合中,透明地从一个服务器移动到另一个服务器
Client API
ZooKeeper API的相关子集如下
create(path, data, flags):用路径名path创建一个znode,在其中存储data [],并返回新znode的名称。客户端通过flags选择znode类型:regular、ephemeral、sequential flagdelete(path, version):如果版本号一致则删除znodeexists(path, watch):如果路径名为path的znode存在,则返回true,否则返回false。watch flag使客户端在znode上设置监视器getData(path, watch):返回与znode关联的数据和元数据(meta-data),watch flag使客户端在znode上设置监视器,但如果znode不存在,则不会设置监视器setData(path, data, version):如果version是znode的当前版本,则把data写入路径为path的znodegetChildren(path, watch):返回znode子集名称的集合sync(path):操作开始时,等待所有挂起的更新传播到客户端连接到的服务器。path被忽略Waits for all updates pending at the start of the operation to propagate to the server that the client is connected to.
所有方法都有一个同步和一个异步版本,可以通过API使用
- 同步API:应用程序需要执行单个ZooKeeper操作,没有要执行的并发任务
- 异步API:使应用程序同时执行多个未完成的ZooKeeper操作和其他任务。ZooKeeper客户端保证为每个操作依次调用相应的回调
ZooKeeper不使用句柄访问znodes,而是在每个请求中包含正在操作的znode的完整路径
每个更新方法都有一个版本号参数,从而实现条件更新,如果znode的实际版本号与版本号参数不匹配,则更新失败,抛出版本错误。但如果版本号为-1,则不执行版本检查
Zookeeper guarantees
ZooKeeper有两个基本的顺序保证:
- Linearizable writes:所有更新ZooKeeper状态的请求都是可线性化的,并且遵循优先级顺序
- FIFO client order:客户端的所有请求均按客户端的发送顺序执行
此处线性化的定义是A-linearizability(异步线性化),允许一个客户端有多个未完成的操作,并保证FIFO顺序
一个例子:
- 一个系统选举主节点管理其他节点,主节点随后需要更新一些配置,然后通知其他节点,要求:
- 主节点在修改配置过程,不希望其他节点访问正在被修改的配置
- 主节点在更新完成前崩溃,不希望其他节点访问这些破碎的配置
- 分布式锁不足以满足第二个需求
- 可以设置一个
readyznode解决:主节点在配置前删除,完成后重新建立。当其他节点看到ready不存在时就不读取配置 - 新问题:如果其他节点看到
ready后读取配置,主节点随即删除、修改配置,此时其他节点将得到过时的配置——采用观测机制(通知的排序)来解决,ready删除后会及时通知其他节点,即客户端在该更改完成后会被通知(在看到系统新状态之前)
- 一个系统选举主节点管理其他节点,主节点随后需要更新一些配置,然后通知其他节点,要求:
ZooKeeper两个活动性和持久性保证:
- 如果大部分服务器都活跃,那么服务就是可用的
- 如果ZooKeeper响应了一个修改请求,只要大部分的节点都可以最终恢复,那么修改就可以在无数次故障中保持持久。
Examples of primitives
很多原语是在客户端使用ZooKeeper clientAPI实现的
ZooKeeper的顺序保证允许对系统状态进行有效的推理,而watches(监视器)则允许高效的等待
原语 Configuration Management(配置管理):
- 在分布式应用程序中实现动态配置
- 存储在znode $z_c$中,进程以$z_c $的完整路径名启动,并通过将watch标志设置为true来读取$z_c$并获取其配置。如果$z_c$中的配置被更新,进程将收到通知并读取新的配置,并再次将watch标志设置为true
- 如果监视$$z_c$$的进程收到$$z_c$$变更的通知,并且发出对$$z_c $$的读取之前还有三次变更,该进程不会再收到这个三个(变更的)通知事件,但这不会影响进程的行为,因为这三个事件只会通知进程它已经知道的事情:拥有的$z_c$的信息过时了
原语 Group Membership:
- 利用临时节点来实现组成员关系管理——利用可以看到创建临时节点的会话的状态
- 首先指定一个znode $z_g $表示一个组。该组的进程成员启动时,将在$$z_g $$下创建临时子节点znode。如果每个进程都有唯一的名称或标识符,名称用作子进程znode的名称,否则创建带有顺序标志的znode,以获得唯一的名称分配——通过组znode的子znode获取组成员状态
- 进程可以将进程信息放入子znode的数据中,例如进程使用的地址和端口。
- 如果该进程失效或结束,在$$z_g$$下表示该进程的znode将自动删除
- 如果进程希望监视组成员关系的变化,则可以将watch标志设置为true,并在收到变更通知时刷新组信息
原语 Simple Locks:
- 最简单的锁实现使用“锁文件”,该锁由znode表示,为了获取锁,客户端尝试创建带有临时标志的指定znode。如果创建成功,客户端将持有锁。否则,客户端仅可以读取znode,并设置watch标志,以便在当前leader死亡时收到通知。客户端在锁失效或显式删除znode时释放锁
- 受到羊群效应的影响:如果很多客户端在等待获取锁,当锁被释放时会一起争夺锁
- 只实现了独占锁
原语 Simple Locks without Herd Effect(解决羊群效应)
一个锁znode $l$ :将请求锁的所有客户端排列起来,每个客户端按照请求到达的顺序获得锁。因此,clients希望获得锁的客户可以执行以下操作
1
2
3
4
5
6
7
8
9
10Lock
1 n = create(l + “/lock-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest z node in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for watch event
6 goto 2
Unlock
1 delete(n)- SEQUENTIAL标志让所有客户端按照顺序尝试获取锁
- 第3行如果发现客户端的znode的序列号是最低的,则客户端持有锁
- 通过只监视客户端znode之前的znode,只在锁被释放或锁请求被放弃时唤醒一个进程
- 创建时使用EPHEMERAL标志,崩溃的进程将自动清除所有锁请求或释放它们可能拥有的任何锁
- 该锁方案优点
- 删除一个znode只会导致一个客户端唤醒,因为每个znode都被另一个客户端监视
- 没有轮询或超时
- 通过浏览ZooKeeper数据,可以看到锁争用的数量、中断锁和调试锁问题
原语 Read/Write Locks:
读锁和写锁过程分开。解锁过程与全局锁的情况相同
1
2
3
4
5
6
7
8
9
10
11
12
13
14Write Lock
1 n = create(l + “/write-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 2
Read Lock
1 n = create(l + “/read-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if no write znodes lower than n in C, exit
4 p = write znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 3写锁和普通锁类似,和其他的锁互斥,读锁可以共享,和写锁互斥
原语 Double Barrier
- 双重屏障使客户端能够同步计算的开始和结束
- 客户端开始计算之前添加znode到Barrier对应的znode下,结束计算后删除znode
- 客户端需要等待栅栏znode的子znode数量到达一定阈值后才能开始计算
- 客户端可以在数量到达阈值后创建一个特殊的
ready的znode - 客户端退出的时需要等待子znode全部被删除,或者通过删除
ready删除
ZooKeeper Applications
解析服务(The Fetching Servic):
- 在雅虎的爬虫系统解析服务中,主节点需要告知解析节点系统配置,解析节点需要报告自己的状态——好处在于,可以恢复主服务器的故障,在出现故障时仍然可用,并将客户端与服务器解耦,允许它们仅通过从ZooKeeper读取状态就可以将请求指向好的服务器
- 解析服务使用ZooKeeper管理配置和领导选举
- 系统读写操作中,读取操作占大头
**Katta**:
- Katta是使用ZooKeeper进行协调的分布式索引器,是一个非yahoo!应用程序
- Katta使用分片划分索引工作。主服务器将分片分配给从服务器并跟踪进度。从服务器可能会故障,主服务器必须随着从服务器是否故障重新分配负载。主服务器也可能出现故障,其他服务器必须准备好在出现故障时接管
- Katta使用ZooKeeper跟踪从服务器和主服务器(组成员关系)的状态,处理主服务器故障转移(leader选举),并跟踪和传播分配给从服务器的分片(配置管理)
雅虎消息中介(YMB):
雅虎消息中介负责无数话题下的消息的发布和接收,话题分布在多个服务器上,每个服务器采用主从备份
系统的znode结构如下所示,类似于
shutdown、migration_prohibited是系统的配置信息,nodes保存了属于组成员的服务器信息,而topics保存了负责具体话题对应的主服务器和从服务器,在主节点崩溃后需要领导选举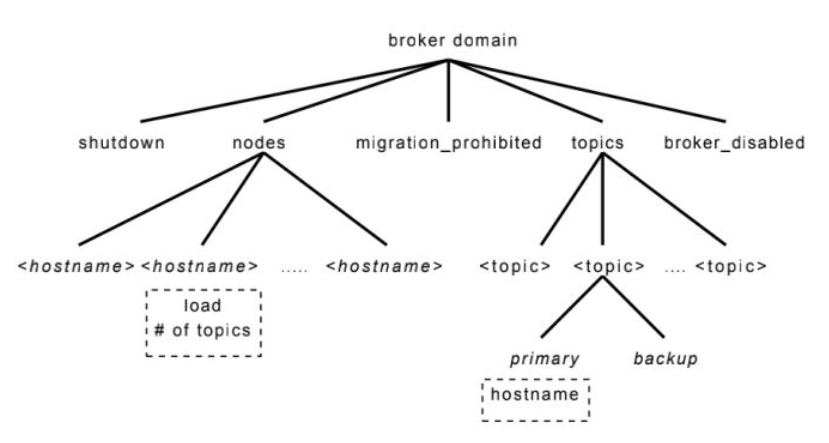
ZooKeeper Implementation
ZooKeeper通过在集群的每个服务器上复制ZooKeeper数据提供高可用性
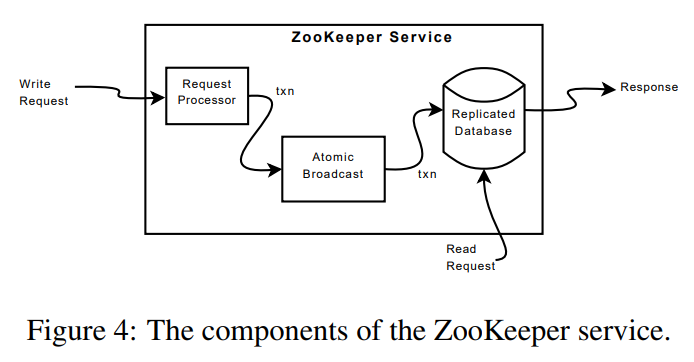
Fig4显示了ZooKeeper服务的高层组件
- 接收到请求后,服务器为执行请求做准备(请求处理器)
- 若请求需要在服务器(写请求)之间协调,则使用一致性协议(原子广播的一种实现)
- 服务器将更改提交给ZooKeeper数据库,将其完全复制到全体服务器中
- 对于读取请求,服务器只需读取本地数据库的状态,并生成对请求的响应
复制的数据库是包含整个数据树的内存数据库
- 树中的每个znode默认最多存储1MB的数据,该最大值是可以在特定情况下更改的可配置参数
- 为了提高可恢复性,将记录更新到磁盘,在将log应用到内存中的数据库之前强制写入磁盘
- 每个ZooKeeper服务器都向客户端提供服务,客户端只需要连接到一个服务器来提交请求,写请求被转发到称为leader的单个服务器(其他ZooKeeper服务器称为followers),接收来自leader的包含状态改变的proposals(提案)信息,改变状态达成一致
请求处理器
- 消息传递层是原子的
- 与客户端发送的请求不同,事务是幂等的
- leader接收到一个写请求时,计算应用写请求时系统的状态,并将其转换为捕获这个新状态的事务
- 根据请求内容,计算新的状态、版本号、更新时间戳,生成一个包含新数据、新版本号和更新的时间戳的
setDataTXN。如果出现错误,如版本号不匹配或要更新的znode不存在,则生成errorTXN
原子广播
- leader执行请求,通过原子广播协议Zab将状态更改广播到ZooKeeper,接收客户端请求的服务器在提交相应状态更改时响应给客户端
- Zab默认使用简单的quorums原则决定一个提案,因此Zab和ZooKeeper只有在大多数服务器都正确的情况下才能工作
- 为了实现高吞吐量,ZooKeeper尝试保持请求处理管道满载
- Zab提供比常规原子广播更强的顺序保证:保证一个leader广播的变更按照发送的顺序传递,leader节点广播之前需要确保已经收到了前一个leader的广播
多副本数据库
当服务器故障后,使用周期性的快照和快照之后的日志恢复
称ZooKeeper快照为模糊快照,因为获取快照时不锁定ZooKeeper状态(对树进行深度优先扫描,原子地读取每个znode的数据和元数据,并写入磁盘)
由于状态更改是幂等的,因此只要按顺序应用状态更改,可以应用修改两次(再次应用已经应用的修改没有影响)
例如,假设在一个ZooKeeper数据树中,两个节点/foo和/goo的值分别为f1和g1
当模糊快照开始时,它们的版本都是1
状态更改流到达时,其形式为(transactionType, path, value, new-version):
1
2
3(SetDataTXN, /foo, f2, 2)
(SetDataTXN, /goo, g2, 2)
(SetDataTXN, /foo, f3, 3)处理这些状态更改后,/foo和/goo的版本3和版本2的值分别为f3和g2
模糊快照可能已经记录了/foo和/goo在版本3和1中分别拥有f3和g1的值
如果服务器崩溃并使用此快照恢复,并且Zab重新提交状态更改,则结果状态仍然对应于崩溃前的服务状态
客户端-服务器交互
- 当服务器执行一个写入操作后,会通知观测的客户端并清除观测,每个服务器只负责通知自己连接的客户端
- 每个读取请求对应着一个
zxid(服务器上看到的最后一个写入事务的ID) - 可能读取之前的一些写入没有同步到客户端连接的服务器,ZooKeeper提供了
sync操作,保证sync之后的读取操作都能够获得发生在sync之前的写入结果 - 客户端会从服务器获取最新
zxid,zxid另外一个作用是保证客户端在切换服务器后,新服务器看到视图不能比客户端之前看到的视图落后,即服务器zxid不能早于客户端的zxid - 如果检测客户端故障,会话有超时时间,客户端在没有活动期间也要发送心跳避免超时(心跳消息也包括客户端所连接的服务器所看到的最后一个zxid)

