HDFS 概述、CURD、NameNode与DataNode
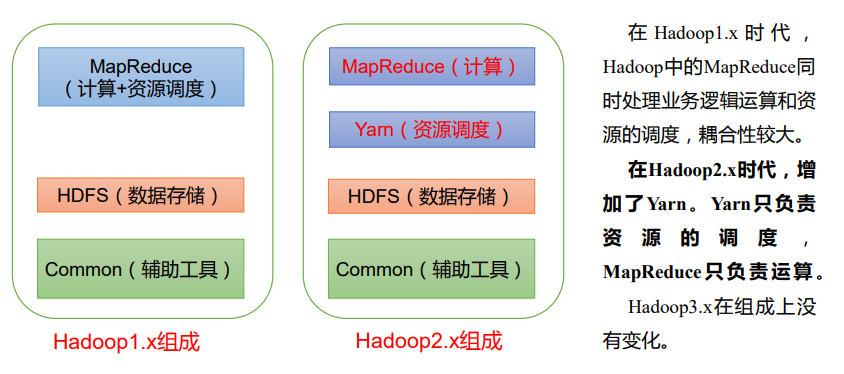
- Hadoop四高:
- 高可靠性:维护多个数据副本
- 高扩展性:集群间分配任务数据
- 高效性:集群并行工作,加快任务处理速度
- 高容错性:自动将失败的任务重新分配
- 1.x、2.x、3.x的Hadoop组成
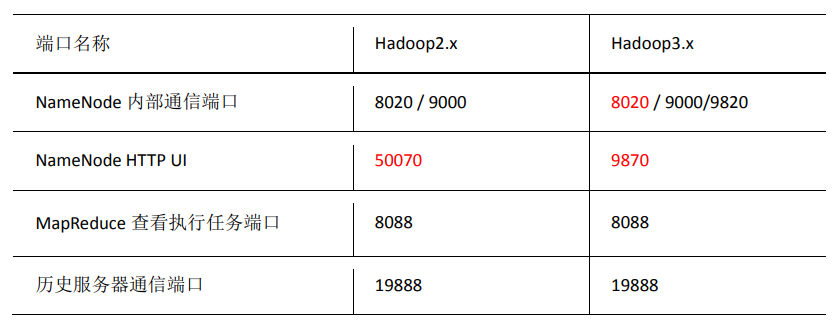
端口号:
HDFS
HDFS(Hadoop Distributed File System)是Hadoop使用离线的数据存储文件系统,容错,可扩展,适合一次写入,多次读出的场景——文件经过创建、写入和关闭后,不需要更改
优缺点:
- 高容错、适合处理大数据、构建在廉价机器上
- 不适合低延时数据访问、不适合存储大量的小文件(占用NameNode内存来存储文件目录和块信息)、不支持并发写入和文件随机修改(不允许多个线程同时写,只支持数据追加)
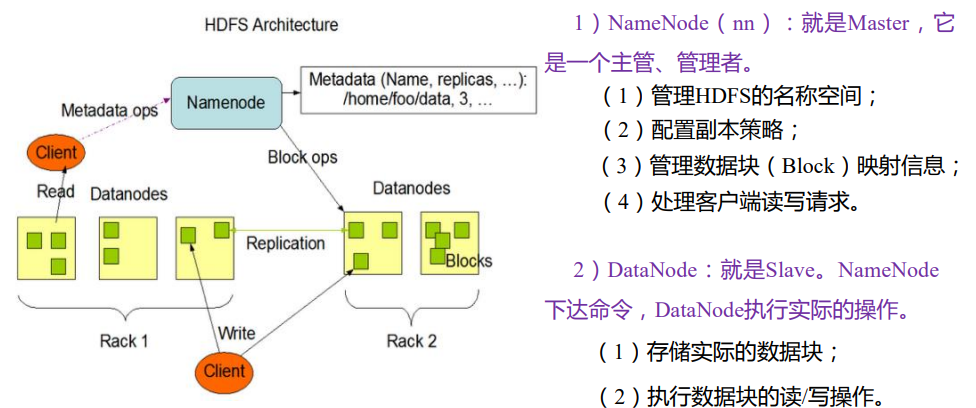
NameNode(nn):管理文件系统元数据(文件名、文件目录结构、每个文件的块列表和块所在的DataNode);DataNode:存储实际数据;客户端和NameNode交互获取文件元数据,和DataNode交互执行实际的文件I/O
Hadoop支持类似shell的命令,直接与HDFS交互
NameNode和DataNode内置web服务器,以检查集群的当前状态
一些特性:
- HDFS可以设置文件权限(类似于Linux),启动NameNode的用户被视为HDFS超级用户
- safemode:一种用于维护的管理员状态。启动过程NameNode从fsimage加载文件系统状态并编辑日志文件,等待datanode报告它们的块,在此期间NameNode保持safemode(HDFS集群的只读模式),不允许对文件系统或块进行任何修改
- fsck:一个程序,用于诊断文件系统的状况,查找丢失的文件或块
- Balancer:数据分布不均匀时,实现集群均衡
- Secondary NameNode(2nn):
- NameNode将对文件系统的修改存储为一个log,附加到文件edit中。NameNode启动时,从fsimage读取HDFS的状态,应用edit文件的log,最后将新的HDFS状态写入fsimage,以一个空的editlog开始正常运行
- Secondary NameNode定期合并fsimage和edit log,将edit文件的大小控制在一定的范围
- 参数:
dfs.namenode.checkpoint.period:连续两个检查点之间的延迟时间,默认为1小时dfs.namenode.checkpoint.txns:未建立checkpoint的事务的数量,如果达到这个数目,则强制建立检查点,默认为一百万
- Stores the latest checkpoint in a directory which is structured the same way as the primary NameNode’s directory. The check pointed image is always ready to be read by the primary NameNode if necessary
- 不是NameNode的热备,NameNode挂掉时不能马上替换NameNode提供服务
- Checkpoint node:
- NameNode使用两个文件持久化它的namespace:fsimage(namespace的最新checkpoint)、edits(自checkpoint以来对namespace的更改日志)
- Checkpoint node定期创建namespace的checkpoint——从active NameNode下载fsimage和edits,合并后将新fsimage发给active NameNode——Checkpoint node通常和NameNode所在机器不同
- Backup node:Checkpoint node的扩展,与活动的NameNode命名空间状态同步。只能有一个Backup节点注册到NameNode
HDFS中文件分块存储,可通过参数
dfs.blocksize修改,文件块的默认大小:128M(2.x和3.x),64M(1.x)- 寻址时间约为10ms
- 磁盘传输速率普遍为100MB/s
- 寻址时间为传输时间的1%,则为最佳状态——1s * 100MB/s = 100 MB
- 块太小:增加寻址时间
- 块太大:传输数据时间明显大于寻址(定位块的开始位置)时间,程序处理数据时会非常慢
- HDFS块的大小设置主要取决于磁盘传输速率
Shell操作
hadoop fs + 具体命令等同于hdfs dfs + 具体命令1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]查看某个命令的参数:
hadoop fs -help 命令常用命令:
上传
- 从本地剪切到HDFS:
hadoop fs -moveFromLocal ./A.txt /test/A.txt - 从本地拷贝到HDFS:
hadoop fs -copyFromLocal A.txt /test;hadoop fs -put A.txt /test - 追加文件A到HDFS中文件B末尾:
hadoop fs -appendToFile A.txt /test/B.txt
- 从本地剪切到HDFS:
下载
- HDFS拷贝到本地:
hadoop fs -copyToLocal /test/A.txt ./,hadoop fs -get /test/A.txt ./B.txt
- HDFS拷贝到本地:
直接操作
显示目录:
hadoop fs -ls /test显示文件内容:
hadoop fs -cat /test/A.txt修改文件权限:(-chgrp、-chmod、-chown,和linux中用法一致)
创建路径test:
hadoop fs -mkdir /test从HDFS的一个路径拷贝到 HDFS 的另一个路径:
-cpHDFS 目录中移动文件:
-mv显示一个文件的末尾 1kb 的数据:
-tail删除文件或文件夹:
-rm,递归删除则-rm -r统计文件夹的大小信息:
-du(1746为文件大小)1
2
3
4
5$hadoop fs -du -s /hadoop
1746 /hadoop
$hadoop fs -du /hadoop
873 /hadoop/hello.txt
873 /hadoop/hello2.txt设置 HDFS 中文件的副本数量:
hadoop fs -setrep 10 /jinguo/shuguo.txt——副本数只记录在NameNode的元数据中,是否真的有这么多副本,还需要考虑DataNode的数量
API操作(CRUD)
客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import java.io.IOException;
import java.net.URI;
public class SysUtil {
public static FileSystem getFileSystem() {
try {
// 设置HDFS的URL和端口号
String HDFSURL = "hdfs://localhost:9000";
// HDFS的配置信息
Configuration configuration = new Configuration();
// 设置副本数为 1
configuration.set("dfs.replication", "1");
// //获取文件系统
FileSystem fileSystem = FileSystem.get(URI.create(HDFSURL), configuration);
return fileSystem;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
}上传:
FileSystem.get(URI.create(HDFSURL), configuration).copyFromLocalFile(false, true, localPath, remotePath);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.FileInputStream;
import java.io.IOException;
public class HdfsUpload {
private static final FileSystem fileSystem = SysUtil.getFileSystem();
/**
* 判断文件是否已存在
*/
public static boolean exist(String file) {
Path remotePath = new Path(file);
try {
return fileSystem.exists(remotePath);
} catch (IOException e) {
e.printStackTrace();
return false;
}
}
/**
* 复制文件,从本地复制到HDFS中
*/
public static void uploadToHdfs(String localPathStr, String hdfsPathStr) {
Path localPath = new Path(localPathStr);
Path remotePath = new Path(hdfsPathStr);
// 第一个参数表示是否删除源文件,第二个参数表示是否覆盖
try {
fileSystem.copyFromLocalFile(false, true, localPath, remotePath);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 追加文件,从本地追加到 HDFS 的文件中
*/
public static void appendToFile(String localPathStr, String hdfsPathStr) {
Path hdfsPath = new Path(hdfsPathStr);
try (FileInputStream inputStream = new FileInputStream(localPathStr)) {
FSDataOutputStream outputStream = fileSystem.append(hdfsPath);
byte[] data = new byte[1024];
int read = -1;
while ((read = inputStream.read(data)) > 0) {
outputStream.write(data, 0, read);
}
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException {
String localPathStr = "src/hello.txt";
String remotePathStr = "/hadoop/upload.txt";
boolean override = false;
boolean isExist = exist(remotePathStr);
if (!isExist) {
// 文件不存在,上传文件
uploadToHdfs(localPathStr, remotePathStr);
} else if (override) {
// 覆盖文件
uploadToHdfs(localPathStr, remotePathStr);
} else {
// 追加
appendToFile(localPathStr, remotePathStr);
}
assert fileSystem != null;
fileSystem.close();
}
}- 参数的优先级(比如,参数”dfs.replication”):
- 客户端代码中设置的值
- 项目resources目录下配置文件(resources/hdfs-site.xml)——可以将hdfs-site.xml拷贝到resources目录下,并修改相应参数
- 服务器的自定义配置(hdfs-site.xml)
- 服务器的默认配置(hdfs-default.xml)
- 参数的优先级(比如,参数”dfs.replication”):
创建:
fileSystem.create(path)1
2
3
4
5
6
7
8
9
10
11
12
13//获取文件系统
FileSystem fileSystem = SysUtil.getFileSystem();
// 如果因为权限而无法写入,可以先修改权限 hadoop dfs -chmod 777 /hadoop
Path path = new Path("/hadoop/create.txt");
// 获取输出流
assert fileSystem != null;
FSDataOutputStream outputStream = fileSystem.create(path);
// 写入一些内容
outputStream.writeUTF("Hello HDFS!");
outputStream.close();
fileSystem.close();下载:
fileSystem.copyToLocalFile(false, remotePath, localPath, true);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.File;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class HdfsDownload {
private static final FileSystem fileSystem = SysUtil.getFileSystem();
public static void download(String remotePathStr, String prefix, String suffix) throws IOException {
String localFileStr = prefix + "." + suffix;
File localFile = new File(localFileStr);
while (localFile.exists()) { // 如果本地文件已存在,重命名(如果下面的参数改为true,则不需要这一步)
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyyMMddHHmmssS");
String tempLocalFileStr = prefix + "-" + dateFormat.format(new Date()) + "." + suffix; // 新的文件名
localFile = new File(tempLocalFileStr);
}
Path remotePath = new Path(remotePathStr);
Path localPath = new Path(localFile.getName());
// 复制到本地,第一个参数:是否删除原文件,第四个参数:是否使用 RawLocalFileSystem,校验文件
fileSystem.copyToLocalFile(false, remotePath, localPath, true);
}
public static void main(String[] args) throws IOException {
String remotePathStr = "/hadoop/upload.txt";
download(remotePathStr, "copyFile", "txt");
fileSystem.close();
}
}更名和移动:
fs.rename(new Path("/A/B/C.txt"), new Path("/A/E/F.txt"));删除:
fileSystem.delete(remotePath, recursive)1
2
3
4
5
6
7
8
9
10
11public static void delete(String remotePathStr, boolean recursive) throws IOException {
Path remotePath = new Path(remotePathStr);
FileSystem fileSystem = SysUtil.getFileSystem();
boolean result = fileSystem.delete(remotePath, recursive);
if (result) {
System.out.println("删除成功!");
} else {
System.out.println("删除失败!");
}
fileSystem.close();
}查看文件内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
//...
public static void cat(String remotePathStr) throws IOException {
final FileSystem fileSystem = SysUtil.getFileSystem();
Path remotePath = new Path(remotePathStr);
FSDataInputStream inputStream = fileSystem.open(remotePath);
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String line = null;
StringBuffer buffer = new StringBuffer();
while ((line = reader.readLine()) != null) {
buffer.append(line + "\n");
}
System.out.println(buffer.toString());
fileSystem.close();
}
//...查看文件信息(文件名、权限、长度、块信息)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.fs.BlockLocation;
import java.io.IOException;
import java.util.Arrays;
//...
public static void listFiles(String remotePathStr, boolean recursive) throws IOException {
Path remotePath = new Path(remotePathStr);
FileSystem fileSystem = SysUtil.getFileSystem();
RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(remotePath, recursive);
while (iterator.hasNext()) {
LocatedFileStatus fileStatus = iterator.next();
System.out.println("===" + fileStatus.getPath() + "====");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// 获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
fileSystem.close();
}
//...
HDFS读写流程
写入:
- 客户端通过Distributed FileSystem(
org.apache.hadoop.fs.FileSystem)向NameNode请求上传文件,NameNode检查父目录、目标文件是否存在,以及客户端权限 - NameNode返回可以上传
- 客户端询问第一个Block上传的DataNode
- NameNode返回多个DataNode(dn1,dn2,dn3)
- 客户端请求dn1,dn1收到请求继续调用dn2,dn2调用dn3,建立通信管道
- dn1、dn2、dn3逐级应答客户端
- 客户端向dn1上传第一个Block(从磁盘读取后放入本地的一个缓冲队列), 以Packet为单位(packet以chunk为单位,一个chunk 512字节+4字节校验),dn1 收到一个Packet后,一边向磁盘写一边传给dn2,dn2传给dn3;dn1每收到一个packet就应答一次,客户端将应答放入应答队列
- 客户端通过Distributed FileSystem(
NameNode选择最近距离的DataNode节点接收数据:
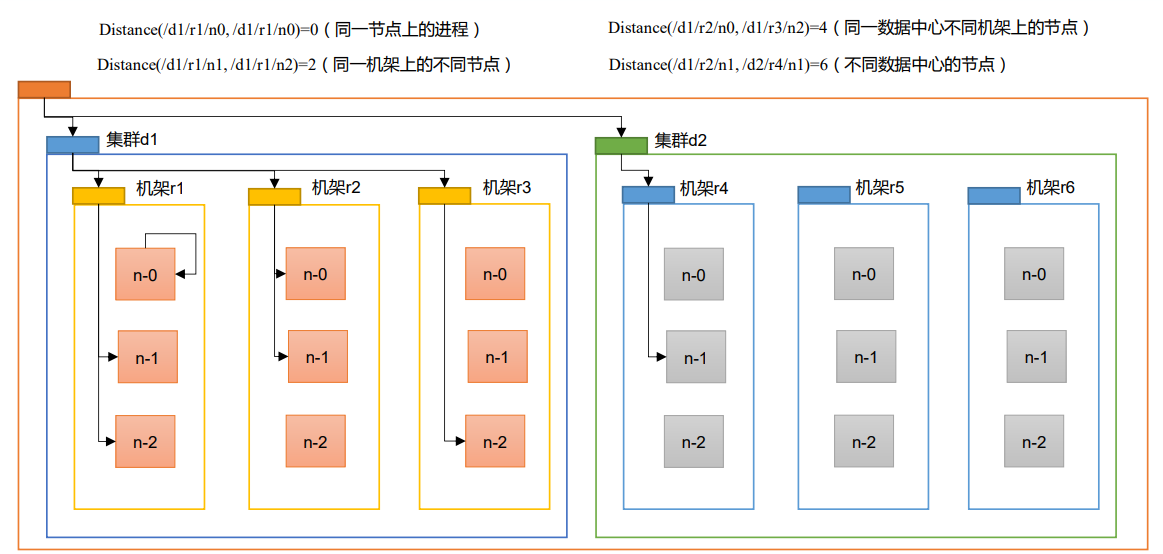
节点距离:两个节点到达最近的共同祖先的距离总和
上面的结构中,一个机架包含三台服务器,一个机架对应一个交换机,一个集群就是一个机房
副本节点选择:(机架感知)
正常情况下,如果有三个副本,HDFS会设置副本为:本地节点、其他机架的一个节点、其他机架的一个节点(和第二个副本的机架相同)
本地:向哪个服务器提交,这个服务器就是本地节点
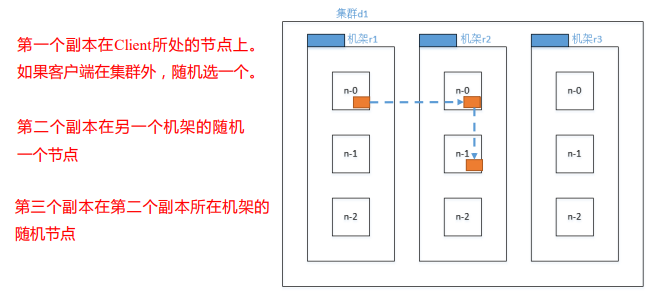
源码:(idea中ctrl n查找类
BlockPlacementPolicyDefault的chooseTargetInOrder)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51protected Node chooseTargetInOrder(int numOfReplicas,
Node writer,
final Set<Node> excludedNodes,
final long blocksize,
final int maxNodesPerRack,
final List<DatanodeStorageInfo> results,
final boolean avoidStaleNodes,
final boolean newBlock,
EnumMap<StorageType, Integer> storageTypes)
throws NotEnoughReplicasException {
final int numOfResults = results.size();
if (numOfResults == 0) { // 第一个副本,localstorage
DatanodeStorageInfo storageInfo = chooseLocalStorage(writer,
excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes,
storageTypes, true);
writer = (storageInfo != null) ? storageInfo.getDatanodeDescriptor()
: null;
if (--numOfReplicas == 0) {
return writer;
}
}
final DatanodeDescriptor dn0 = results.get(0).getDatanodeDescriptor();
if (numOfResults <= 1) { // 第二个副本,和dn0相比是远程的
chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
if (--numOfReplicas == 0) {
return writer;
}
}
if (numOfResults <= 2) { // 第三个副本
final DatanodeDescriptor dn1 = results.get(1).getDatanodeDescriptor();
if (clusterMap.isOnSameRack(dn0, dn1)) { // dn0和dn1如果在同一个机架
chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
} else if (newBlock) { // 和dn1在同一个机架
chooseLocalRack(dn1, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
} else {
chooseLocalRack(writer, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
}
if (--numOfReplicas == 0) {
return writer;
}
}
chooseRandom(numOfReplicas, NodeBase.ROOT, excludedNodes, blocksize,
maxNodesPerRack, results, avoidStaleNodes, storageTypes);
return writer;
}
读数据:
- 客户端向NameNode请求下载文件
- NameNode查找元数据,找到文件块所在的DataNode地址,返回目标文件的元数据
- 客户端创建FSDataInputSteam对象,挑选一台DataNode(就近原则,负载均衡问题)服务器,请求读取数据
- DataNode传输数据给客户端(从磁盘读取数据输入流,以Packet为单位做校验)——客户端串行读,先读出第一个block,再读第二个block,即使两个block不在同一个DataNode
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件
NN和2NN
NameNode的元数据在内存中,磁盘中有备份元数据FsImage。为了避免内存中元数据与FsImage同时更新带来的性能下降,使用Edits文件(只进行追加操作,效率高)——元数据有更新或者添加元数据时,修改内存中的元数据并追加日志到Edits。一旦NameNode断电,可以合并FsImage和Edits,得到最新的元数据
长时间添加日志到Edits中,会导致该文件过于庞大,元数据恢复时间长,因此定期合并FsImage和Edits——由Secondary Namenode负责
SecondaryNameNode每隔一小时执行一次;一分钟检查一次日志的操作次数,操作次数达到100w时,SecondaryNameNode执行一次(hdfs-default.xml)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60s</value>
<description> 1 分钟检查一次操作次数</description>
</property>工作机制:
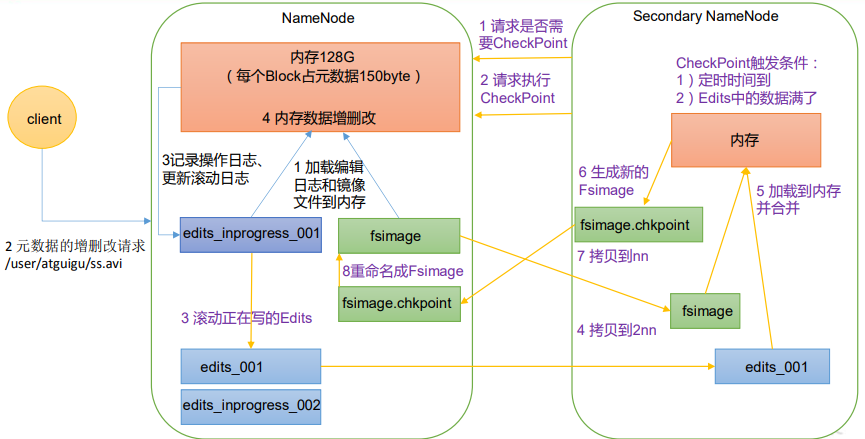
- NameNode启动
- 第一次启动NameNode并格式化后,创建Fsimage和Edits文件,如果不是第一次,则加载Edits和Fsimage到内存合并
- 客户端对元数据进行增删改
- NameNode记录操作日志,更新滚动日志
- NameNode在内存中对元数据进行修改
- Secondary NameNode工作
- Secondary NameNode询问NameNode 是否需要CheckPoint
- Secondary NameNode请求执行CheckPoint
- NameNode滚动正在写的 Edits 日志(此时,如果有新的客户端操作,则NameNode将其记录到edits_inprogress_002,这个不被2NN拷贝和持久化)
- 滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
- Secondary NameNode加载编辑日志和镜像文件到内存,并合并
- 生成新的镜像文件fsimage.chkpoint
- 拷贝fsimage.chkpoint到NameNode
- NameNode将fsimage.chkpoint重新命名成fsimage
- NameNode启动
Fsimage和Edits解析
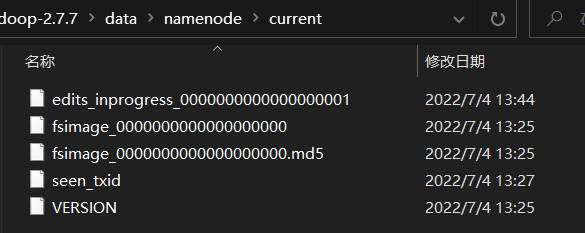
目录:
- fsimage:持久化的检查点
- edits:更新操作记录
- seen_txid:保存的是一个数字(最后一个edits_inprogress_的数字,比如上图就是1)
- VERSION:保存命名空间ID,以及集群ID(NameNode和DataNode的集群ID需要一致)
Fsimage查看:oiv,
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径1
2$hdfs oiv -p XML -i
fsimage_0000000000000000000 -o ./fsimage.xmlEdits查看:oev,
hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>1</TXID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_MKDIR</OPCODE>
<DATA>
<TXID>2</TXID>
<LENGTH>0</LENGTH>
<INODEID>16386</INODEID>
<PATH>/test</PATH>
<TIMESTAMP>1656912470698</TIMESTAMP>
<PERMISSION_STATUS>
<USERNAME>ASUS</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>493</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_MKDIR</OPCODE>
<DATA>
<TXID>3</TXID>
<LENGTH>0</LENGTH>
<INODEID>16387</INODEID>
<PATH>/hadoop</PATH>
<TIMESTAMP>1656912492184</TIMESTAMP>
<PERMISSION_STATUS>
<USERNAME>ASUS</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>493</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
</EDITS>
DN
- 工作机制
- 数据块在DataNode上以文件形式存储在磁盘,包括两个文件:数据本身、元数据(数据块的长度,校验和,时间戳)
- DataNode启动后向NameNode注册,注册后周期(6 小时)地向NameNode上报所有的块信息——这里有两个参数,汇报当前解读信息的间隔
dfs.blockreport.intervalMsec、扫描块信息列表的时间间隔dfs.datanode.directoryscan.interval,都在hdfs-default.xml - DN与NN保持心跳,3秒一次,心跳返回结果中可以有NameNode对该DN的命令(复制数据到另一台机器、删除某个数据块等),超过10分钟没有收到心跳,则认为该DN不可用
- 数据完整性保证:
- DataNode读取一个Block时计算CheckSum,如果与Block创建时的值不一样,说明Block损坏,需要Client读取备份DN的Block
- 校验算法:crc(32)、md5(128位)、sha(160位)
- 心跳超时参数:HDFS默认的超时时长为10分钟+30秒,计算公式为:
TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval,默认dfs.namenode.heartbeat.recheck-interval为5min,默认dfs.heartbeat.interval为3s- 参数在hdfs-site.xml
- 参数
heartbeat.recheck.interval的单位为ms - 参数
dfs.heartbeat.interval的单位为s

