《Using Personal Information for Targeted Attacks in Grammar based Probabilistic Password Cracking》(2017)
摘要
- 基于PCFG,根据训练集学习文法,以最优的概率顺序生成猜测
- 直接将目标的个人信息有效地合并到PCFG模型中,以进行有针对性的攻击
- 建立一个融合多个文法的数学模型,使用目标的个人信息派生出各种结构和词典,更快匹配到目标密码
- 一个单独的模块,可以直接与PCFG系统一起使用
介绍
- “攻击者”表示试图破解密码的人,“目标”表示受害人。攻击者获取有关目标的特定信息,如家庭成员的姓名、重要日期、地址和电话号码,可能获得目标以前在同一帐户或姐妹帐户中的某些密码。
- 本文以非常直接的方式将个人信息有效地合并到PCFG密码破解中,不需要对PCFG代码组件进行任何修改
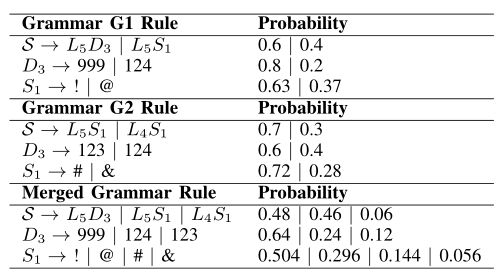
- 讨论如何在数学上组合两个或多个语法以形成另一种语法,该语法基于适当地加权每个组件语法的参数来组合组件语法的特征
方法
Merging Two or More Context-free Grammars
如果有两个训练集,从两个训练集中获得PCFG语法的方式:
合并两个训练集重新训练PCFG
直接合并两个训练集独有的PCFG语法——可以为每个训练集定义一个权重参数
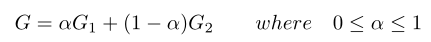
此时,对于一个语法规则R,在$G_1$中概率为$p_1$,在$G_2$中概率为$p_2$(如果R不在语法中,则概率为0),此时$p=\alpha p_1+(1-\alpha)p_2$
Integrating Personal Information into the Grammar
- 基于个人信息输入,创建一个名为PIgram的语法和一个名为PI-Dictionary的攻击字典
- 数字将被加到PI-gram的数字变量中,姓名、单词或任意字母字符串会添加到PI-DICTIONARY中——在攻击阶段,PCFG可以使用多个字典,例如,基本词典是标准的单词词典而不是从训练中学习的单词,因为训练集可能太稀疏;可以使用附加的专用词典,例如训练集中最频繁的单词组成的热门单词词典,或者用于定向攻击的单词组成的个人信息词典
- 猜测生成过程中使用PI-字典,确保PI-字典中的字符串在生成的猜测中以更高的概率使用
- 日期将被分为月、日和年,日期的大多数变化也将类似地添加到PI语法中,例如02/10/2016的日期出现时,字典中会添加02, 10, 2016, 16, 02102016, 021016, 10022016, 100216, 0210, 1002等
- 单独使用的PI语法在密码破解中不是很有用,因为该语法只有很少的基本结构和组件。在生成猜测时,会将此语法与通用语法合并
I Know Your Old Password
- 已知以前密码的情况下,为target attack构建语法——旧密码可能包含重要信息,如重要的数字、日期或家庭成员姓名
- 使用Houshmand等人[15]使用的AMP编辑距离来定义相似密码的度量,并确定可以生成此类密码的语法
- AMP使用一个距离函数在编辑距离内创建增强密码,该编辑距离是用户根据Damerau-Levenshtein编辑距离选择的密码之一[16]。Damerau-Levenshtein编辑距离给出了将一个字符串转换成另一个字符串所需的最小操作数。该距离函数的AMP版本包括基本结构的组件的插入、删除、替换和转置,以及组件内部的类似操作
- 本文进一步改进了AMP的distance函数,增加了对键盘pattern和多词pattern的操作
- 多词(multiword):修正后的AMP编辑距离有以下单位操作:
- 插入:在多字中的两个字之间插入一个$D_1$或$S_1$。例如,对于包含starwars的密码,创建star5wars或star!wars
- 成分换位:将相邻的两个字,以及多字中的第一个和最后一个字进行换位。比如mysweetbaby改成sweetmybaby,mybabysweet,babysweetmy
- 删除:从一个多词中删除一个词,从而在语法中产生一个新的基本结构和一个新的多词。例如,给定密码mysweetbaby12和基本结构M11D2,可以创建其他基本结构,如M9D2、M6D2、M7D2以及mysweet、mybaby等多词
- 多词(multiword):修正后的AMP编辑距离有以下单位操作:
- 此方法产生的语法,称为编辑距离语法(ED-grammar)——产生旧密码修改的AMP编辑距离1内的所有猜测,并认为这些猜测是等概率的
Predicting New Password by Considering Password Modifications
- 假设攻击者拥有关于用户的更多信息——关于用户密码习惯,假设攻击者知道至少两个相似的旧密码,可以收集用户对密码所做的修改的信息,以预测新密码
- 本节讨论确定两个已知密码之间的变化的算法,展示如何基于该信息预测新密码
- 为了确定两个密码之间的变化,实现一个函数,通过创建一个距离矩阵找到最小编辑距离。该函数还涉及回溯算法,回溯算法用于确定两个字符串之间的操作
- 编辑距离函数同样基于Damerau-Levenshtein算法
- 算法首先填充大小为n1×n2的(距离)矩阵D,其中n1是第一个字符串s的长度,n2是第二个字符串t的长度。D[i,j]中的值是长度为i的s的初始子串和长度为j的t的初始子串之间的距离
- 创建该矩阵时,还捕获与每个步骤相关联的操作,将其存储在另一个矩阵O中(I:插入,D:删除,t:转置)。用O建立转换算法,该算法回溯矩阵,在将一个字符串转换为另一个字符串时找到相应的转换步骤
Hierarchical transformation algorithm
- AMP编辑距离函数[15]不同于常规的Damerau-Levenshtein编辑距离
- Damerau-Levenshtein编辑距离将两个相邻字符的换位视为一个编辑距离——这不适合密码更改。例如,比较两个密码iloveyou123和123iloveyou时,Damerau-Levenshtein编辑距离算法认为距离为6,因为字符串开头有3个插入,结尾有3个删除
- 将这两个字符串视为具有不同组成部分的密码时,其实用户只做了一处更改,将多字组成部分M8替换为数字组成部分D3
- 为了对此进行建模,本文开发一种分层转换算法,该算法首先找到简单基础结构之间的编辑距离。简单基础结构是密码的基本结构(不考虑每个组成部分的长度)——love456!的简单基础结构LSD
- 给定两个旧的密码,第一层里将两个密码解析成简单基本结构,调用简单基础结构的编辑距离算法,确定基础结构的差异,使用回溯算法,确定导致简单基础结构变化的操作:回溯算法从矩阵的右下角开始,往回到矩阵的左上角,在每一步中确定进行了什么操作,以计算编辑距离。然后,沿着路径创建一个操作字符串,显示一个字符串如何转换为另一个字符串。如果在简单基础结构中进行转置,算法将检查每个组件对应的字符串,然后反转转置,以中和最初的转置,并通过应用转置来重新创建一个与另一个相似的密码
- 第二层,查找已更改密码与第二个密码之间的编辑距离,以查找这两个字符串之间的编辑距离和操作。比如,给定密码123alice!$、12alice$!,回溯函数返回nndnnnnnt(n:无变化,d:删除,t:转置)
- 分层的转换算法将会预测用户在创建新密码时将做出的新更改
Creating the Grammar
- 根据现有数据和其他研究显示的内容[12]、[13]定义了一些最常见和最重要的更改,以创建PM-grammar(密码修改语法)
- 数字部分递增/递减1:识别旧密码的数字部分中的递增或递减1,将下一个可预测的变化添加到语法中。例如,旧密码是bluemoon22和bluemoon23,数字24将被添加到语法的D2部分,基本结构L8D2在语法中的权重+1
- 插入相同的数字:识别某个数字是否被插入到密码中,以及它是否被重复添加。例如,bluemoon->bluemoon5->bluemoon55,如果旧密码是bluemoon3和bluemoon33,将333添加到语法中,并将L8D3添加到语法的基础结构中
- 字母字符串的大写:旧密码具有相同的字母序列,但大写不同,将两个大写都添加到语法中
Merging Grammars and Generating Targeted Guesses
- 综上,攻击者基于可用信息的种类创建任意或所有的语法PI、ED和PM
- 将所有的语法合并在一起,形成一个更全面的通用语法,用于在不知道个人信息的情况下破解密码
- 通过为每种语法分配适当的权重,可以平衡所生成的猜测,使得具有个人信息的猜测通常会以较高的概率值更早地生成,而更一般的猜测可能会在稍后的猜测过程中生成
- 本文的方法可以视为PCFG的一个附加的中间步骤——对大型密码集进行通用的语法训练后,根据可用的个人信息创建PIgrammar、ED-grammar和PM-grammar。将这些语法与普通语法合并,最终的语法可以像以前一样用于离线攻击
- 攻击者使用个人信息,是希望目标在密码中使用他们的个人信息。这里合并技术的优点在于,如果目标没有在他们的密码中使用个人信息,本文的系统仍将正常工作,因为可以生成一般的猜测(调整权重)
实验
- 第一个实验中,比较了使用和不使用ED语法的攻击
- 将攻击分别称为有针对性的攻击和一般的攻击,使用Houshmand等人的[6]进行训练
- 一般攻击中,在真实用户密码的大型数据集上进行训练,并使用(一般)语法来生成猜测
- 有针对性的攻击中,将旧密码输入到系统中以产生ED语法,将该ED语法与一般语法结合
- 从雅虎密码集中随机选取了30万个密码(2012年泄露),作为训练集
- [6]的训练方法需要一个训练字典来确定多词。使用EOWL[18],增加了与[6]相同的电影剧本中的常见专有名词和热门词汇。还使用dict-0294[19]作为主要的攻击字典
- 测试集使用56对新旧密码,这些密码是通过对用户如何更改密码的调查获得的
- 调查
- 调查要求参与者(大学学生)创建和更改密码
- 参与者是佛罗里达州立大学的学生,2000名随机挑选的学生参加
- 建立了一个网站,要求第一次参与者创建一个带密码的账户。关于密码的唯一策略是至少有8个字符。用户被要求在一周内每天登录一次,总共登录四次。每次登录时,用户都会被问一些调查问题
- 在第三次访问站点时,用户被要求更改密码。第四次访问通过用户使用更改后的密码登录完成了调查
- 多次登录允许用户在要求他们更改密码之前,对他们第一次创建的密码更加熟悉
- 测试
- 调查中,会问参与者是如何更改密码的,以及是否通过修改之前的密码来更改密码——从而知道哪些密码是通过修改旧密码得到,否则即使密码看起来相似,也无法知道用户的意图
- 56个密码中,有23个是根据之前的密码创建的
- 对于每个破解会话,将旧密码输入本文的系统,生成ED语法。这个语法与通用语法相结合
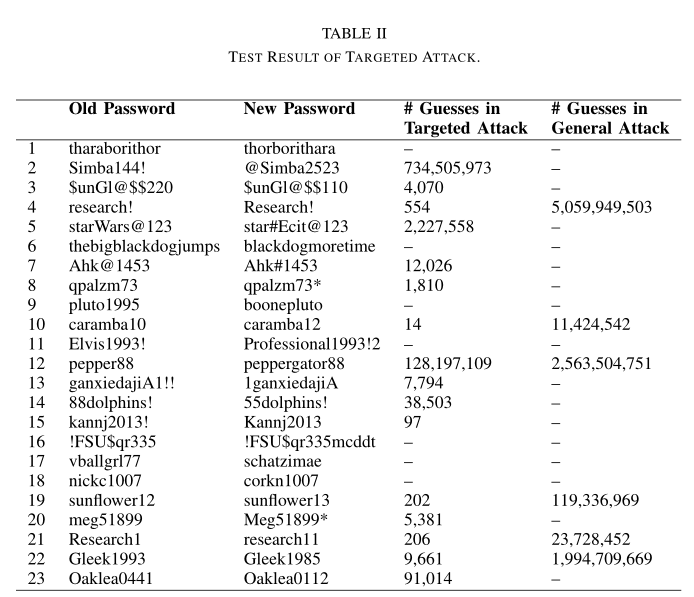
- 下表显示了输入系统的旧密码、尝试破解的新密码,以及使用目标语法和普通语法找到新密码所需的猜测次数
- 结果显示,能够猜出大部分稍微更改过的密码,无法猜出一些密码是因为字典中没有相关的字母字符串,而一般的密码破解攻击中,只有少数密码被破解,并且破解时间更长
- 通过一个私人聚会获得了一个30组以前密码的小列表,列表中除了两个密码外,所有密码都是成对的,只有两个密码由三个连续的密码组成。在它们中使用PMgrammar,能够破解该列表的78%,其中66%在不到20次猜测的情况下被破解