《PassGAN:A Deep Learning Approach for Password Guessing》论文阅读记录
摘要
- 最先进的密码猜测工具(HashCat和John the Ripper)可以执行简单的字典攻击,并使用密码生成规则(连接字符串、leet)扩展密码字典
- 进一步扩展生成规则以模拟真实密码较为困难——用基于理论的机器学习算法 PassGAN 代替人工生成的密码规则
- PassGAN 使用生成性对抗网络(GAN)从实际的密码泄漏中自动学习真实密码的分布,并生成高质量的密码猜测
- 在两个大型密码数据集上评估PassGAN,效果优于基于规则的和最先进的机器学习密码猜测工具
- 将 PassGAN 的输出与 HashCat 的输出相结合,能够比单独使用 HashCat 多匹配 51%-73% 密码——PassGAN 可以自动提取一定数目的密码属性
介绍
密码猜测工具在识别弱密码上具有价值(尤其是密码以哈希形式存储)
- 根据每个密码的散列快速测试大量极有可能(或者说,高度相似)的密码
- 没有用尽所有可能的字符组合,而是使用字典中的单词和泄漏的密码作为候选
最先进的密码猜测工具采用启发式算法,包括复合单词(iloveyou123456)、混合字母大小写(例如,iLoVeyOu)和leet speak(例如,il0v3you)以及这些规则的组合。
启发式算法:一个基于直观或经验构造的算法,在可接受的花费(指计算时间和空间)下给出待解决组合优化问题每一个实例的一个可行解。该算法常能发现很不错的解,但没办法证明它不会得到较坏的解
转换规则再结合马尔可夫模型
启发式方法基于用户如何选择密码的直观经验,而不来自大型密码数据集的原则性分析——可扩展性有限
我们的方法
- 基于深度学习的方法代替基于规则的,以及基于马尔可夫模型等简单数据驱动技术的密码猜测
- 训练一个神经网络,更好地确定密码的特征和结构,生成遵循相同分布的新样本
- 马尔可夫模型:隐式假设所有相关密码特征都可以用n-grams定义;基于规则:只能猜测与规则匹配的密码
- 假设:
- 神经网络有足够的表达能力
- 不需要任何先验知识
- 通过 PassGAN 验证
- 一个深层生成网络(G)试图模拟样本的潜在分布,一个判别深层神经网络(D)试图区分原始训练样本(即“真实样本”)和G生成的样本(即“假样本”)
- 使用泄漏的密码列表(真实示例)来训练D
GANs 通过训练一个深层神经网络来执行隐式生成建模,该结构由一个简单的随机分布(例如,高斯分布或均匀分布)提供,并通过生成遵循可用数据分布的样本来完成
隐式地建立了$x=F^{-1}(s)$模型,其中$F(x)$是数据的累积密度函数,$s$是均匀分布的随机变量
2.2. 贡献
- 经过适当训练的GAN能够产生高质量的密码猜测
- 在RockYou数据集的一部分上进行训练,并在两个不同的数据集上进行测试:
- RockYou数据集的另一部分(最终匹配43.6%)
- LinkedIn泄露的密码数据集(最终匹配24.2%)
- 若测试数据集删除训练集中存在的密码示例,以测试 PassGAN 创建未知密码的能力,则最终匹配 34.6%、 34.2%
- PassGAN 生成的绝大多数密码与测试集不匹配,但“看起来”像是人类生成的密码——可能与未考虑的真实账户密码匹配
- 在RockYou数据集的一部分上进行训练,并在两个不同的数据集上进行测试:
- 证明 PassGAN 效果不弱于最先进的密码生成规则
- 使用 PassGAN,匹配的次数会随着生成的密码数量而稳步增加
- PassGAN的输出不限于密码空间的一小部分
- 这以生成更多密码为代价,但在实际应用上并不是问题
- 存储成本在稳步下降
- 密码猜测工具可以组合使用
- PassGAN 在基于神经网络的密码猜测算法方面,不弱于最先进的技术(FLA)
- 证明 PassGAN 可以有效地补充密码生成规则
- PassGAN 匹配的密码不由密码规则生成
- 与 HashCat 结合,与单独使用 HashCat 相比,可额外猜出 51%到73% 的唯一密码。
背景和相关工作
- 深度学习:特征可以有效地从数据中学习,而手工编码的特征往往表现不好
生成性神经网络
- 由两个神经网络组成:生成型神经网络$G$和判别型神经网络$D$
- 给出输入数据集 $L = {x_1,x_2,…x_n}$ ,$G$的目标是根据潜在分布$Pr(x)$中产生“假样本”,$D$的目标是通过学习数据集$L$,区分假样本和真实样本。当不能区分样本真假时,认为训练完成
- 对于一个噪声分布$z$:
$$min_{\theta_G}max_{\theta_D}\sum_{i=1}^nlogf(x_i;\theta_D)+\sum_{j=1}^nlog(1-f(g(z_j;\theta_G);\theta_D))$$
密码猜测
JTP、HashCat、马尔可夫模型
与其他神经网络的比较:
FLA:RNN,每一个新的字符(包括一个特殊的密码结尾字符)都是根据其概率来选择的
As such, given a trained FLA model, one can feed a set of passwords to the model and retrieve as output a file containing 6 fields organized as follows:
(1) password
(2) the probability of that password
(3) the estimated output guess number
(4) the std deviation of the randomized trial for this password
(5) the number of measurements for this password
(6) the estimated confidence interval for the guess number (in units of number of guesses).FLA 和 PassGAN 的输出概率之间的差异,来自FLA中密码生成过程的马尔可夫结构——任何未在 n-gram 范围内捕获的密码特征都可能不会被 FLA 编码。例如,如果将10个字符密码的有意义子集构造为两个单词的连接(例如MusicMusic),则n≤5的任何 Markov 过程都将无法正确捕获此行为
GaN结构与超参数
使用Gullajani等人的
Wasserstein-GANs(IWGAN)的改进训练来实例化PassGAN依赖于
ADAM优化器来最小化训练误差,即减少模型输出与其训练数据之间的不匹配训练误差大说明对训练集特性学习得不够,训练误差太小说明过度学习了训练集特性,容易发生过拟合
超参数:
Batch size批处理大小:在优化器的每个步骤中通过 GAN 传播的来自训练集的密码数Number of iterations迭代次数:GAN 调用其前向步骤和后向传播步骤的次数。在每个迭代中,GAN 运行一次生成器和一次或多次判别器。Number of discriminator iterations per generator iteration每个生成器迭代的判别器迭代次数:生成器在每个 GAN 迭代中执行的迭代次数。Model dimensionality模型维度:每个卷积层的维度(权重)数量Gradient penalty coefficient (λ)梯度惩罚系数:与其输入相关的判别器梯度范数的惩罚。使 GAN 的训练更加稳定Output sequence length输出序列长度:生成器生成的字符串的最大长度Size of the input noise vector (seed)输入噪声向量(seed)的大小:为生成样本,多少随机比特作为$G$的输入Maximum number of examples样本的最大数量:代表训练项目的最大加载数目(即密码)Adam优化器的超参数:Learning rate学习率:调整模型权重的速度- `Coefficient $\beta_1$ 系数$\beta_1$:渐变的运行平均值的衰减率
- Coefficient $\beta_2$ 系数$\beta_2$:梯度平方的运行平均衰减率
超参数设置:
- Batch size 为64
- number of iterations 为 199000,number of discriminator iterations per generative iteration 设置为 10(
IWGAN的默认值) - 两个神经网络每一层有128维,有5层
- 梯度惩罚为 10
- 生成序列长度为 10 字符
- 噪声矢量为128个浮点数
- 系数$\beta_1$和$\beta_2$分别为0.5和0.9
- 学习速率为10-4
评估
- 量化 PassGAN 猜测密码的能力,与 FLA、3-gram Markov模型、JTR(SpiderLab mangling rules)、HashCat (Best64 和 gen2 rules)进行比较
- 从概率密度和密码分布的角度分析 PassGAN 的输出
实验
- GAN 训练与测试
- 训练集和测试集同上所述
- 选择长度不大于10字符的密码
- 由于 LinkedIn 为密码哈希值,因此 LinkedIn 测试数据集只包含JTR和HashCat 等工具能够恢复的明文密码
- 训练中过拟合的影响:
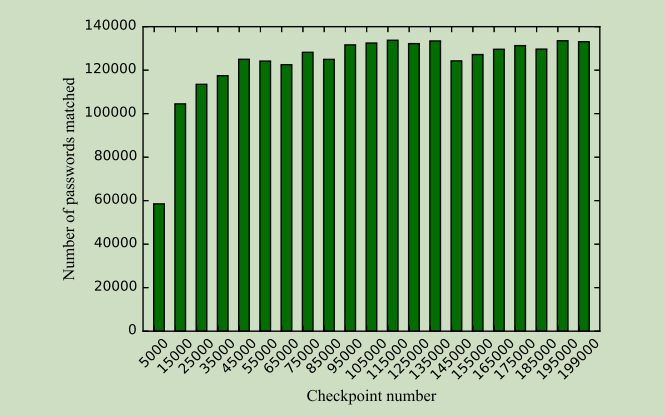
- 为评估训练过程中是否产生过拟合,在训练过程设置了 CheckPoint
- 在每个 CheckPoint 上,生成108个密码以测试是否过拟合
- 下图显示 PassGAN 在各种检查点上生成的与RockYou测试集匹配的唯一密码数。X轴表示PassGAN训练过程的迭代次数(检查点)
评估 PassGAN 生成的密码
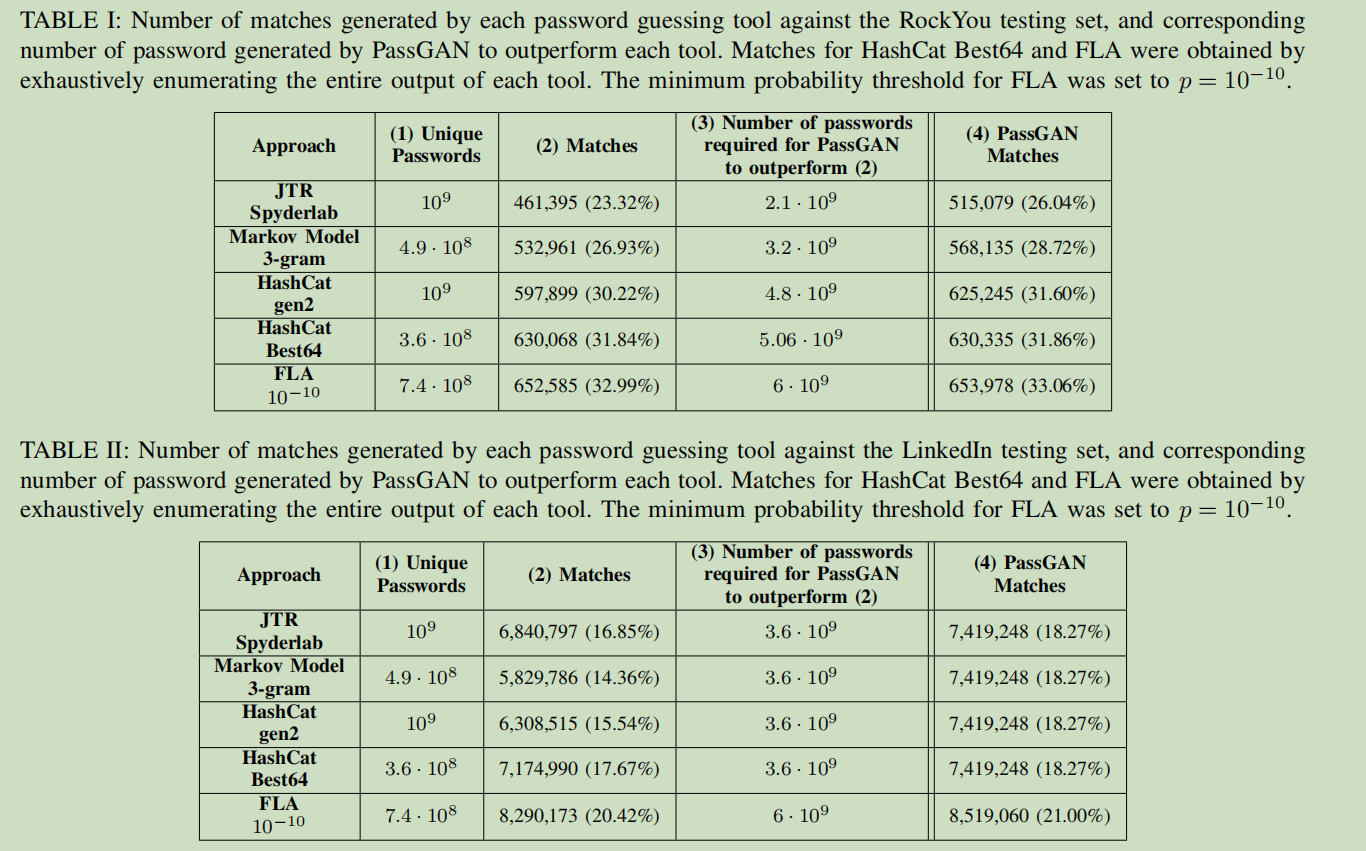
- PassGAN 生成 5*1010个密码
- 其余模型计算密码方式:
- HashCat 与 JTR:
- 使用训练集中按频率降序排列的密码实例化二者的规则
- 对其输出均匀采样109个样本,样本中密码长度不超过10个字符
- FLA:
- 模型包含两个隐藏层和一个大小为512的密集层(dense layer)
- 取出输出空间的一个概率阈值$p$为10-10的子集(密码概率至少为$p$),并降序排列
- Markov 模型:
- 使用标准配置运行 3-gram Markov模型
- HashCat 与 JTR:
- 对以上每一种工具,PassGAN 至少能获得相同数目的匹配密码——生成密码数目要多一个数量级。若训练集和测试集不同,PassGAN的效果更好
- 将多个密码猜测工具联合使用:
- 将基于规则的工具和基于机器学习的工具联合起来评估
- 假设:基于规则的工具更快,但基于机器学习的工具能在猜测次数更多的前提下匹配到额外的密码
- 方法:删去 HashCat Best64 匹配到的密码,重新测试,Rockyou测试集和LinkedIn测试集结果如下:
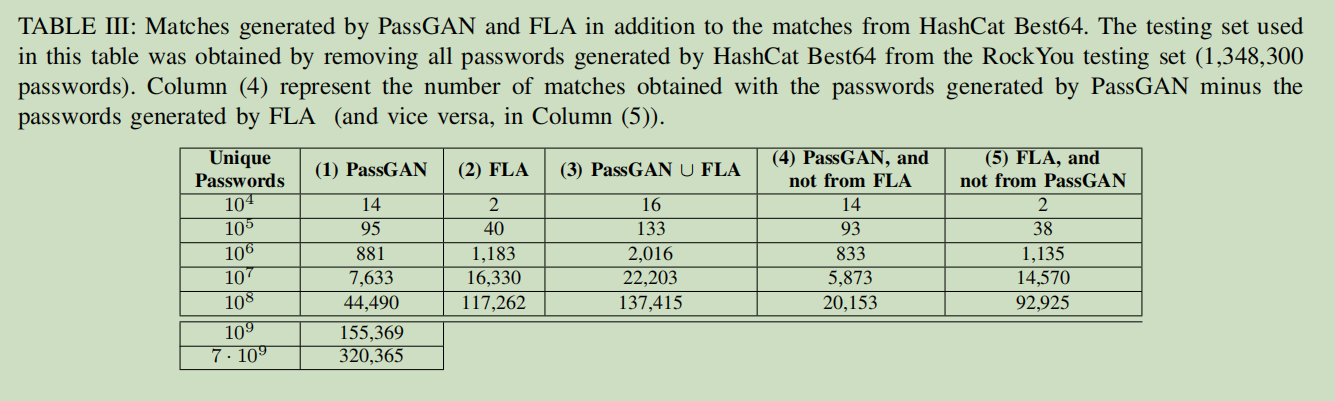

- PassGAN 和 FLA 均可产生不少于基于规则工具的匹配密码,且密码并不相同
- PassGAN 和 FLA 的更多差别:
- 下图显示了在Rockyou测试集上,PassGAN 在前 7·1010 次猜测中匹配的密码,有多少是FLA需要更多次数才能猜到(即,FLA认为这些密码的概率比较小)
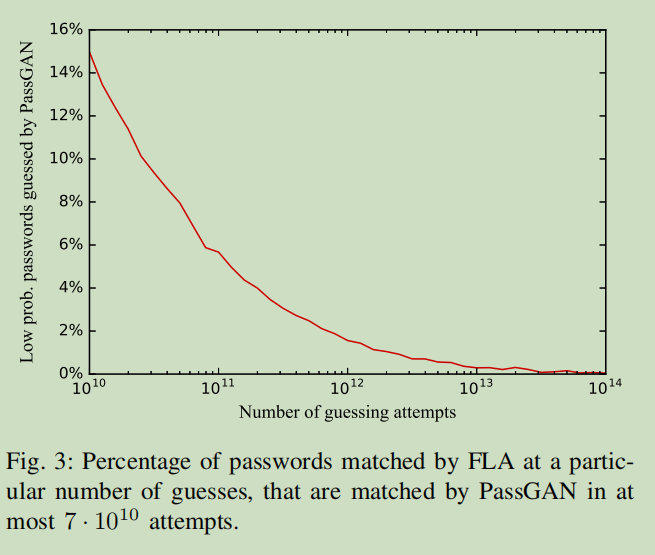
- 由图像的趋势可知,一般来说,这两个工具在为密码分配概率上是一致的
- 下图显示了在Rockyou测试集上,PassGAN 在前 7·1010 次猜测中匹配的密码,有多少是FLA需要更多次数才能猜到(即,FLA认为这些密码的概率比较小)
评估 PassGAN的输出特性
- PassGAN 概率密度估计
- 匹配密码的能力取决于正确估计密码频率的能力
- 生成 1010 个密码,并计算了其中每个密码的频率,并与训练集中的相应频率比较
- 50个最频繁的密码,40%属于训练集最频繁的100个密码
- PassGAN 没有为不太可能的密码精确地建模密码概率——任何导致更好的密度估计的改进,都可能提高模型猜测能力
- 输出空间的大小
- 增加 PassGAN 生成的密码数时,生成唯一密码(新密码)的速率只略微降低
- PassGAN 生成的未匹配密码,很多是人工生成密码的合理候选
讨论
- 字符级 GAN 很适合密码猜测
- 当前的基于规则的密码猜测很有效,但作用有限
- 最好的猜测策略是将这些工具组合起来
- GANs 可以很好地推广到密码数据集,而不限于训练集
- 最新的GANs密度估计仅对其生成的空间子集是正确的。随着密码频率的降低,PassGAN 密度估计的质量下降——更大的训练数据集,再加上更复杂的神经网络结构,可以显著提高密度估计,从而提高 PassGAN 性能
总结
- PassGAN 旨在从泄漏密码中学习密码分布信息,不依赖任何附加信息
- PassGAN 能够在没有用户干预的情况下生成密码,不需要对密码的先验知识,也不需要对密码泄漏数据库进行手动分析
- 测试 PassGAN 是否能猜到没有被训练过的密码,以及 PassGAN 输出的分布如何接近真正的密码泄漏的分布
- PassGAN 始终能够生成与其他密码猜测工具相同数量的匹配
- PassGAN 目前需要输出比其他工具更多的密码才能获得相同数量的匹配——就提出的技术而言,这一成本可以忽略不计
- 相信通过在更大的数据集上训练 PassGAN(即部署更复杂的神经网络和进行更全面的训练),底层 GAN 将执行更精确的密度估计,从而减少实现特定匹配次数所需的输出密码数

