《Improving Password Guessing via Representation Learning》论文阅读记录
摘要
- 介绍了一种用于密码猜测的深度生成模型表示学习方法
- 展示了一种抽象的密码表示形式,能提供通用的属性
- 提出
- 条件密码猜测的一般框架,可以生成带有任意偏差的密码
- 期望最大化启发的框架,动态调整估计的密码分布,以匹配被攻击的密码数据集的分布
介绍
- 现代的密码猜测攻击建立在这样的观察基础上:人类选择的密码并不是均匀分布在密码空间中,而是自然倾向于选择容易记住的密码
- 攻击者可以估计真实密码在密码空间的密集区域【58】
- 【42,27,56】在不同的假设下,试图直接估计一组密码背后的概率分布,以生成合适的猜测
- 表示学习从大量的非结构化数据中学习有用的和解释性的表示【18】
- 对 GAN【30】实例和 WAEs【51】实例的潜在空间中对密码的表示进行建模,由于其平滑性【18】,这种表示形式在高维密码空间中强制了语义组织,使得生成器的潜在空间中,与语义相关的密码的表示更为接近,潜在空间中的几何关系直接转换为数据空间中的语义关系
- 本文表征了两个主要属性:密码强局部性和密码弱局部性,分别对应条件密码猜测和动态密码猜测
- 贡献:
- 第一个证明,在密码猜测领域中使用完全无监督学习的表示学习具有可行性
- 提出一种概率性的,完全不受监督的基于模板的密码生成方式CPG
- 提出DPG:从与被攻击密码集的交互反馈,动态地调整猜测策略,攻击者可以利用在攻击中成功猜出的密码不断调整攻击模型
背景
深度生成模型
深度生成模型是潜变量模型。网络被隐含地引导去学习一组潜在变量
训练过程中,对学习到的潜在变量进行先验分布,这种先验,在本文中称为先验潜伏分布或$\dot{p}(z)$**——一种易于抽样、无信息和因子分解的先验,往往是标准正态分布或0-1均匀分布**【29】
生成网络是潜在空间$Z$和数据空间$X$之间确定性的映射函数:$p(X)=p(X|z;\theta)\dot{p}(z)$
本文引入了一般的潜在空间概率密度函数$p(z)$,而且生成器的平滑度迫使在学习的潜在空间中形成几何组织,类似特征嵌入
GAN 通过对抗性训练绕过了定义一个明确的似然函数,能够估计一个尖锐分布【29】
AE 没有用对抗性进行训练,而是使用最大似然方法,一旦训练好,解码器就可以充当数据生成器。但训练期间必须强制潜在空间和先验潜在分布一致
生成模型在密码猜测的应用
- 上一部分证明了深层生成模型具有其固有的新颖、有价值的特性,在表示学习的角度下抽象底层模型,这些特性可以用来设计独特的猜测技术,这是任何现有方法都做不到的
GAN
PassGAN【35】将 GAN 生成器训练为 an implicit estimator of password distributions
- 在残差网络的架构上【34】利用了具有梯度代价的 WGAN【33】
- 假定了一个具有标准正态分布的潜在空间
- PassGAN 与其他方法相比,如果要获得相同数量的匹配密码,最多需要十倍的猜测次数
- 模型无法将固定的概率分配给产生的猜测,因此无法根据密码使用人数对其排序
- 存在训练不稳定性(因此生成器和判别器不能执行足够数量的迭代次数,下面为原因)
- 离散数据对生成器难以重现,因为 softmax 层会导致低质量的梯度(
low-quality gradient) - 生成器无法完全模拟离散特性,因此判别器更容易区分真假,这样就没有给生成器留下提高的空间(特别是训练的最后阶段)
- 离散数据对生成器难以重现,因为 softmax 层会导致低质量的梯度(
- 每一个字符串表示为一个二进制矩阵,通过独热码串联而成
对策:
- 对训练集的字符串表示,增加了随机平滑机制——在每个字符的独热码上加入小幅度的加性噪声
- 噪声幅度的上限作为超参数,设置为0.01
- 加入噪声后对每个字符分布重新归一化(这里我没想明白归一化的含义?是一个独热码[1,0,0,0]+[0.005,0.005,0.005,0.005]之后,内部归一化吗,而且噪声服从什么分布?)
- 保持梯度惩罚框架 WGAN【33】 不变
- 用更深的 residual bottleneck blocks【34】替代了 residual blocks,但数量保持一致
- 生成器中**使用 batch normalization **对增加层数极为重要
- 以上对策提高了训练迭代次数,而不会出现崩溃【21】
根据密码最大长度(10、16、22)不同,训练三个生成器
AE
- 第二种生成密码猜测模型基于 WAE【51】
- WAE 规范化了潜在空间,使其与选定的潜在分布保持一致
- WAE 与 GAN 部分特点相似,但 WAE 提供了准确的逆映射(编码),使得在一些情况下比 GAN 要好
- 将模型训练为 CAE【47】
- 每次接收输入密码的噪声版本(以一定概率$p=\frac{\varepsilon}{|x|}$去除密码中的任意字符,其中分母为密码长度,分子为设置为5的超参数)
- 输入处理后的密码,再现完整的密码——必须从上下文估计丢失的字符
- 使用 GAN 生成器架构,但层数更深
- 使用和 GAN 相同的先验潜在分布($N(0,1)$,128维)
条件密码猜测(CPG)和密码的强局域性
介绍密码的局部性概念以及可能的应用
密码强局部性和本地化抽样
在训练过程中加入注意力机制/感应偏置(
inductive bias)在本文中,密码潜在表示的相似性取决于一些关键因素,例如密码结构、常见子字符串的出现以及字符类别(具体因素在论文的附录中)
这里用三个密码——“jimmy91”, “abc123abc”, and “123456”——举了一个例子(个人认为这里的图是后期手动生成的,以说明潜在的分布具有意义),每个密码的周围密码存在一定的相似性
将这种共享同一细粒度特征的密码聚集起来,这样的特征体现了密码的强局部性
由于这样的密码被限制在密码空间的特定区域,因此可以通过在此区域采样来诱导网络生成时的样本倾向,即产生 bias——需要考虑如何表达这种 bias /定位这一空间
提取原型密码 x 的潜在表示 z(之后称为枢轴,在上图就是深红色的密码) 周围的潜在点,以生成与原型 x 相关的密码
通过之前的 AE 网络从 x 推断潜在表示 z(作者认为,这个过程可以推广,也可以使用其他的深度生成模型如【25,36,40】)
获得 z 之后可以将生成器的采样限制在 z 的周围,以生成相似的密码
为了与先前的潜在分布保持一致,并避免采样分布不匹配,选择高斯分布$N(z,\sigma I)$
认为潜在点和 z 的语义关系强度,和二者的空间距离成正比,因此高斯分布的标准差提供了语义相关强度限制手段。下面这个是不同标准差下,潜在点采样结果

基于密码模板倒置的局部空间密码生成
上面用编码器、密码在密码空间的位置属性生成相关类别的密码,但还可以进一步通过“模板”定义这些类别,从而更精准定位密码空间位置
编码器通过在字母表中引入占位符,强制定义特定的密码,例如 Jimmy** 表示字符串 Jimmy 长度为8(加结束符)、前缀为 Jimmy 的密码,且占位符的独热向量为空
在生成过程的过程中,占位符被高概率的字符替换
CPG
适用场景:
- 攻击者需要生成任意数量的具有特定结构/公共子串的猜测
- 攻击者可以恢复不完整的密码
- 合法用户用于恢复遗忘了部分字符的密码
过去的方法(如FLA)无法“条件生成密码”
- 不能为丢失字符指定概率
- 丢失了前向性,即忽略了占位符出现在密码开头的可能性
- 如果占位符过多,过去的方法也不适用(但它们能处理特殊情况的模板,如前缀完全已知,而且占位符数目不多)
- 过去的方法,为了生成任意的模板,往往根据截至频率来枚举密码
- 需要大空间存储,枚举次数极多
- 难以生成低概率的猜测——如果选择的 bias 使该类密码的分布概率较低,那么这类密码在枚举过程中不容易出现
- 基于枚举的方法不能生成密码猜测攻击需要的有效猜测量
相反的,基于表示学习的方法和其位置属性,能够实现条件密码生成
局部性原则使得相似的密码分布在潜在空间的有限区域
模板反转能定位这些区域
可以有条件地为每个有意义的 bias 产生猜测
算法如下
选择一个模板$t$
用编码网络$E$得到潜在分布$z$
以$z$为中心抽取潜在点,尺度为$\sigma$
过滤与 $t$相同的猜测结果

评估
我认为这里的评估,是为了证明本文的方法在某些场景下的生成效果,会远好于已有的方法,而没有考虑具体的密码破解能力(覆盖率),也就是说CPG的方法只能作为密码破解的一个子方案;其意义在于表明强关联性是具有意义的
创建带 bias 的测试集
一个带偏差的$t_i$是一个模板,一个字符串$t_i$由字符表中的字符(210个)和占位符组成
每个模板都是从密码验证集$X_v$随机抽取,这里用 LinkedIn,密码长度最大为16,有$6 \times 10^7$个不重复密码——是训练集 Rockyou 的5倍
- 对从验证集抽取的一条密码,每个字符都有一定概率(概率为0.5)被替换为占位符(个人认为服从二项分布)
- 只选择包含至少 4 个可观察字符和至少 5 个占位符的模板,以限制暴力破解的可能性
获得足够大的模板集合后,创建一组有偏差的测试集
查找与各个模板匹配的所有密码
基于匹配的密码数目,将模板分为四类(每一类都至少有30个不同的模板,具体模板在论文附录)
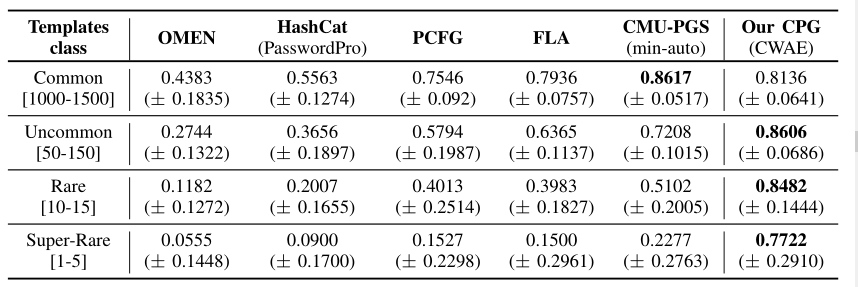
测试结果
- 使用 CWAE(此场景下,AE 要好于 GAN)根据训练集密码最大长度训练三个模型(10,16,22),三者的结果基本一致
no consistently different results have been obtained with models trained on password lengths 10 and 22
- 使用 CWAE(此场景下,AE 要好于 GAN)根据训练集密码最大长度训练三个模型(10,16,22),三者的结果基本一致
设置高斯分布标准差为0.8,为每个模板生成$10^7$个密码,计算相应模板下实际密码的覆盖率
对比模型(每个对比方法经过训练后生成$10^{10}$个密码)
疑问:这里 CWAE 是需要用rockyou获得对应模板密码后,再根据这些模板密码训练,然后在linkedin上不同模板下的密码集测试的吗?还是 CWAE 只需要保证输入和输出相同就行(我感觉应该是后者)?对比模型则是用rockyou统一训练后,生成这么多密码,再分别查看模板的覆盖率吗?
OMEN:相同的训练数据集 Rockyou(0.8-0.2)
- FLA:使用【42】中最大的模型,即3个LSTM组成,一个LSTM有1000个cell
- PCFG:相同的训练数据集 Rockyou(0.8-0.2)
- HashCat:数据来源相同,但按照频率排序,密码唯一,使用 PasswordsPro【6】作为规则集
- CMU-PGS:密码根据最小自动配置【53】猜测的,其中组合了多种工具,通过 web 界面查询猜测次数并只考虑次数少于$10^{10}$的密码,
Recommended tools setup and “1class1” have been used
结果如下
动态密码猜测(DPG)和密码弱局部性
密码弱局部性
密码的表示可以通过嵌入性质实现相似密码的映射——强局部性;密码的一般特征,如平均密码长度、字符分布可以作为弱局部性
这里论文举了一个例子,将 MySpace、Hotmail、phpbb 由生成器学习的潜在空间表示出来,与整个密码空间做了一个对比(没想明白这个图是怎么画出来的,文章说通过降维获得,但怎么做到降维成2D的?)

DPG
我觉得,这个算法的重点在于:1.需要生成器生成密码 2.根据猜测结果对生成器再次微调
以往的概率密码猜测工具都显式/隐式地捕捉训练集密码背后的概率分布,它隐含了训练集的分布满足一般性的假设
训练集和测试集分布上的差异是一个广泛的问题,称为
covariate shift reduction【49】但如果破解了第一个密码,则可以开始观察、模拟测试集的分布
- 过去的方法,如 FLA,其分布受网络参数决定$p(x)=p(x;\theta)$,因此如果通过破解结果反向作用网络参数,需要考虑破解结果的代表性问题——几百个破解结果和百万级的训练数据之间的权重——微调网络的成本很高
- 但生成模型模拟的分布,是潜在分布 z 的联合概率分布$P(x)=P(x,z)=P(x|z;\theta)P(z)$,后者可以进行调整——后者独立于生成器
- 在均匀分布的情况下(例如myspace),可以缩小密集区域周围的空间,避免探索整个潜在空间
- 对于远离生成器模型分布的密码集(训练集和测试集的分布差异较大时),可以将重点放在潜在空间的区域上
- 当改变 z 的分布来为某一猜测到的密码 x 分配更多概率密度时,其实也增加了密码空间中其相邻密码的概率——由于弱局部性属性,这些密码具有相似的特征
以下为具体算法:
$O$为目标密码集,$Z$为生成器生成的密码
$p_{latent}$代表采样潜伏点的分布(我觉得是指生成器输入的采样分布,但初始化时的分布时什么?标准正态分布吗?)
$makeLatentDistribution$函数从猜中的口令集合得出新的潜在分布(是更新生成器吗,还是更新DPG输入的分布?我觉得是后者)
- 每个新猜到的密码都会引入一个以$z_j$为中心的新高斯分布,超参数$\sigma$为每个新高斯的标准差,表明希望从观察到的密码集中采样距离,越大则可以探索更广的距离
- 新高斯函数为$N(z_j,\sigma)$
- 如果 $x_i$ 的概率已知,则可以对相应 $z_i$ 的高斯函数加权。否则认为高斯分布均匀
$G(z)$表示根据$z$生成一个候选密码
$\alpha$为启动超参数,表明猜测到预定数目的密码后,开始使用条件潜伏分布

GAN 在 DPG 的表现上好于 CWAE
和 PassGAN 对比,DPG 在三个数据集上(和下面三个不同)都比 PassGAN 好,覆盖率分别为25+、35+、30+
与其他方法的对比——如果没有明显的协变量转换,动态攻击不能直接与最先进的解决方案的性能相匹配,但能够猜测到测试集中特殊的密码

相关工作
- 基于字典的攻击是最早的猜测技术
- 基于规则的密码扩展【44】——JTR【7】,Hashcat【3】
- 基于概率:
- 马尔可夫模型【45】
- 提出 OMEN【27】作为前者的扩展,其中引入改进的枚举猜测算法
- PCFG【56】,从密码推断语法,以生成猜测密码
- 基于神经网络
- 【22】首次引入网络
- 【42】提出用递归神经网络估计密码分布(FLA),此方法放宽了潜在的n元马尔可夫假设,通过树遍历算法在密码空间中枚举
- 根据已知的其他网站泄露密码,“调整”密码以猜测其他账户密码
- 【46】方法的基础为密码相似性——用户经常使用一对密码,则这对密码是相似的
- 【46】的攻击技术基于概率神经模型,为攻击产生微调的密码变体
- 构建一个嵌入空间
embedding space以估计所选密码之间的相似性,并构建密码强度计,用于查看用户创建密码时是否微调密码。
结论
- 证明局部性原则和深度生成模型的结合具有实践和理论的可能性
- 提出 CPG 和 DPG
- 前者支持条件生成任意偏置密码——从经验上证明了其优势
- 后者证明,从猜测到的密码中获得的新知识可以进一步推广,以模拟目标密码分布,能生成被攻击的密码集特有的密码(这一点其他猜测方法做不到)
参考文献
[1] “Chinese Video Service Giant Y ouku Hacked; 100M Accounts Sold on Dark Web”. https://tinyurl.com/yb78uxnh.
[2] “Cracking Passwords 101”. https://tinyurl.com/y268xahe.
[3] “hashcat”. https://tinyurl.com/y636jsz9.
[4] “Hotmail Password Leak”. https://tinyurl.com/yyr2je4m.
[5] “Improving Password Guessing via Representation Learning”. https://github.com/pasquini-dario/PLR.
[6] “InsidePro-PasswordsPro Rules”. https://tinyurl.com/vd9jzaz.
[7] “John the Ripper”. https://tinyurl.com/j91l.
[8] “Leak Youku”. https://tinyurl.com/y9f2xez6.
[9] “LinkedIn Password Leak”. https://tinyurl.com/yxf7f5gv.
[10] “MySpace Password Leak”. https://tinyurl.com/y433aaah.
[11] “phpbb Password Leak”. https://tinyurl.com/yxonf7um.
[12] “RockYou Password Leak”. https://tinyurl.com/af858jc.
[13] “The Carnegie Mellon University Password Research Group’s Password Guessability Service”. https://tinyurl.com/y9362h6z.
[14] “Zomato hacked: Security breach results in 17 million user data stolen”. https://tinyurl.com/y8xec7sr.
[15] “Zomato Password Leak”. https://tinyurl.com/ya3sthdp.
[16] Kamran Ali, Alex X Liu, Wei Wang, and Muhammad Shahzad. Keystroke Recognition Using WiFi Signals. In ACM MobiCom, pages 90–102, 2015.
[17] Davide Balzarotti, Marco Cova, and Giovanni Vigna. Clearshot: Eaves-dropping on Keyboard Input from Video. In IEEE S&P, pages 170–183, 2008.
[18] Y oshua Bengio, Aaron Courville, and Pascal Vincent. Representation Learning: A Review and New Perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8):1798–1828, 2013.
[19] Hossein Bidgoli. Handbook of Information Security, Information Warfare, Social, Legal, and International Issues and Security Foundations, volume 2. John Wiley & Sons, 2006.
[20] Samuel R. Bowman, Luke Vilnis, Oriol Vinyals, Andrew Dai, Rafal Jozefowicz, and Samy Bengio. Generating sentences from a continuous space. In Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning, pages 10–21, Berlin, Germany, August 2016. Association for Computational Linguistics.
[21] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv preprint arXiv:1809.11096, 2018.
[22] Angelo Ciaramella, Paolo D’Arco, Alfredo De Santis, Clemente Galdi, and Roberto Tagliaferri. Neural Network Techniques for Proactive Password Checking. IEEE Transactions on Dependable and Secure Computing, 3(4):327–339, 2006.
[23] Anupam Das, Joseph Bonneau, Matthew Caesar, Nikita Borisov, and XiaoFeng Wang. The Tangled Web of Password Reuse. In NDSS Symposium, pages 1–15, 2014.
[24] Peter J Diggle and Richard J Gratton. Monte Carlo Methods of Inference for Implicit Statistical Models. Journal of the Royal Statistical Society: Series B (Methodological), 46(2):193–212, 1984.
[25] Jeff Donahue, Philipp Krähenbühl, and Trevor Darrell. Adversarial Feature Learning. arXiv preprint arXiv:1605.09782, 2016.
[26] Vincent Dumoulin, Ishmael Belghazi, Ben Poole, Olivier Mastropietro, Alex Lamb, Martin Arjovsky, and Aaron Courville. Adversarially Learned Inference. arXiv preprint arXiv:1606.00704, 2016.
[27] Markus Dürmuth, Fabian Angelstorf, Claude Castelluccia, Daniele Perito, and Abdelberi Chaabane. OMEN: Faster Password Guessing using an Ordered Markov Enumerator. In ESSoS, pages 119–132, 2015.
[28] Maximilian Golla and Markus Dürmuth. On the Accuracy of Password Strength Meters. In ACM CCS, pages 1567–1582, 2018.
[29] Ian Goodfellow. NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv preprint arXiv:1701.00160, 2016.
[30] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Y oshua Bengio. Generative Adversarial Nets. In NIPS, pages 2672–2680, 2014.
[31] Palash Goyal and Emilio Ferrara. Graph Embedding Techniques, Applications, and Performance: A Survey. Elsevier Knowledge-Based Systems, 151:78–94, 2018.
[32] Alex Graves. Generating Sequences with Recurrent Neural Networks. arXiv preprint arXiv:1308.0850, 2013.
[33] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. Improved Training of Wasserstein GANs. In NIPS, pages 5767–5777, 2017.
[34] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In CVPR, pages 770–778, 2016.
[35] Briland Hitaj, Paolo Gasti, Giuseppe Ateniese, and Fernando Perez-Cruz. PassGAN: A Deep Learning Approach for Password Guessing. In ACNS, pages 217–237, 2019.
[36] Diederik P Kingma and Max Welling. Auto-encoding V ariational Bayes. arXiv preprint arXiv:1312.6114, 2013.
[37] Yang Li and Tao Yang. Word Embedding for Understanding Natural Language: A Survey. In Springer Guide to Big Data Applications, pages 83–104. 2018.
[38] Junyu Luo, Y ong Xu, Chenwei Tang, and Jiancheng Lv. Learning Inverse Mapping by Autoencoder based Generative Adversarial Nets. In International Conference on Neural Information Processing, pages 207–216. Springer, 2017.
[39] Laurens van der Maaten and Geoffrey Hinton. Visualizing Data using t-SNE. Journal of Machine Learning Research, 9:2579–2605, 2008.
[40] Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, Ian Goodfellow, and Brendan Frey. Adversarial Auto-Encoders. arXiv preprint arXiv:1511.05644, 2015.
[41] Philip Marquardt, Arunabh V erma, Henry Carter, and Patrick Traynor. (sp)iPhone: Decoding Vibrations From Nearby Keyboards Using Mobile Phone Accelerometers. In ACM CCS, pages 551–562, 2011.
[42] William Melicher, Blase Ur, Sean M Segreti, Saranga Komanduri, Lujo Bauer, Nicolas Christin, and Lorrie Faith Cranor. Fast, Lean, and Accurate: Modeling Password Guessability using Neural Networks. In USENIX Security Symposium, pages 175–191, 2016. GitHub Repo: https://tinyurl.com/y9o7jdd8.
[43] Shakir Mohamed and Balaji Lakshminarayanan. Learning in Implicit Generative Models. arXiv preprint arXiv:1610.03483, 2016.
[44] Robert Morris and Ken Thompson. Password Security: A Case History. Communications of the ACM, 22(11):594–597, 1979.
[45] Arvind Narayanan and Vitaly Shmatikov. Fast Dictionary Attacks on Passwords using Time-space Tradeoff. In ACM CCS, pages 364–372, 2005.
[46] Bijeeta Pal, Tal Daniel, Rahul Chatterjee, and Thomas Ristenpart. Beyond Credential Stuffing: Password Similarity Models using Neural Networks. In IEEE S&P, pages 1–18, 2019.
[47] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context Encoders: Feature Learning by Inpainting. In IEEE CVPR, pages 2536–2544, 2016.
[48] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv preprint arXiv:1511.06434, 2015.
[49] Masashi Sugiyama, Matthias Krauledat, and Klaus-Robert M˜Aˇ zller. Covariate Shift Adaptation by Importance Weighted Cross V alidation. Journal of Machine Learning Research, 8(May):985–1005, 2007.
[50] Ilya Sutskever, James Martens, and Geoffrey E Hinton. Generating Text with Recurrent Neural Networks. In ICML, pages 1017–1024, 2011.
[51] Ilya Tolstikhin, Olivier Bousquet, Sylvain Gelly, and Bernhard Schoelkopf. Wasserstein Auto-Encoders. arXiv preprint arXiv:1711.01558, 2017.
[52] Blase Ur, Fumiko Noma, Jonathan Bees, Sean M Segreti, Richard Shay, Lujo Bauer, Nicolas Christin, and Lorrie Faith Cranor. I Added ‘!’at the End to Make It Secure: Observing Password Creation in the Lab. In SOUPS, pages 123–140, 2015.
[53] Blase Ur, Sean M Segreti, Lujo Bauer, Nicolas Christin, Lorrie Faith Cranor, Saranga Komanduri, Darya Kurilova, Michelle L Mazurek, William Melicher, and Richard Shay. Measuring Real-world Accuracies and Biases in Modeling Password Guessability. In USENIX Security Symposium, pages 463–481, 2015.
[54] Martin Vuagnoux and Sylvain Pasini. Compromising Electromagnetic Emanations of Wired and Wireless Keyboards. In USENIX Security Symposium, pages 1–16, 2009.
[55] Ding Wang, Zijian Zhang, Ping Wang, Jeff Yan, and Xinyi Huang. Targeted Online Password Guessing: An Underestimated Threat. In ACM CCS, pages 1242–1254, 2016.
[56] Matt Weir, Sudhir Aggarwal, Breno De Medeiros, and Bill Glodek. Password Cracking using Probabilistic Context-free Grammars. In IEEE S&P, pages 391–405, 2009.
[57] Tom White. Sampling Generative Networks. arXiv preprint arXiv:1609.04468, 2016.
[58] Roman V Yampolskiy. Analyzing User Password Selection Behavior for Reduction of Password Space. In ICCST, pages 109–115, 2006.

