《Python深度学习》笔记整理:第二部分 深度学习实践——CNN与RNN
代码基于 Keras 框架
CNN
介绍
1 | model = models.Sequential() |
卷积运算
Dense 层从输入特征空间中学到的是全局模式,卷积层学到的是局部模式
- 可以学到平移不变性:在某个地方(右下角)学到某个模式之后,它可以在任何地方(左上角)识别这个模式
- 可以学到模式的空间层次结构:第一个卷积层将学习较小的局部模式(比如边缘) ,第二个卷积层将学习由第一层特征组成的更大的模式
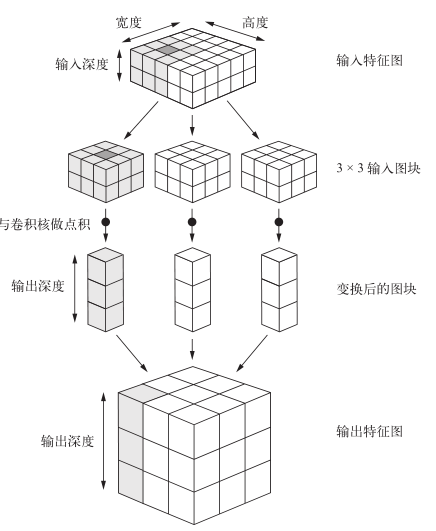
深度轴的不同通道不再像输入一样代表特定颜色,而代表过滤器;过滤器对输入数据的某一方面进行编码
第一个卷积层接收一个(28, 28, 1)的特征图,输出一个(26, 26, 32)的特征图;即计算 32 个过滤器(输出通道),每个通道都包含一个 26*26 的数值网格,它是过滤器对输入的响应图
关键参数:
- 提取的图块尺寸:这些图块的大小通常是 3*3 或 5*5
- 输出特征图的深度:卷积所计算的过滤器的数量
在输入特征图上滑动网格,提取 3D 图块与同意给权重矩阵(卷积核)做张量积,转换为(output_depth,)的一维张量。重组所有一维张量
边界效应与填充:
对 5*5 的输入特征图,用 3*3 的窗口提取特征,如果没有填充,则最终只能获得 3*3 的输出特征图(只有 9 个方格可以作为窗口的中心)
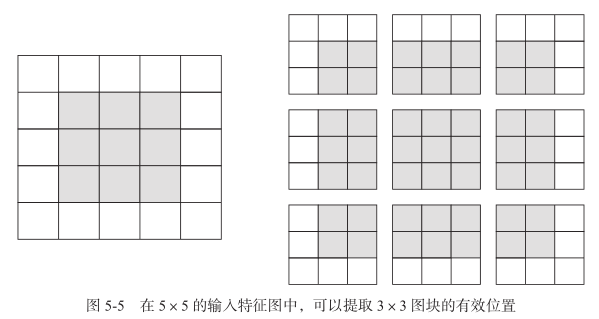
为保证输出特征图的空间维度和输入相同,需要设置填充(padding)——输入特征图的每一边添加适当数目的行和列,使得每一个方格都可作为提取窗口的中心
参数:
padding=valid/same,默认为 valid。前者不使用填充
卷积步幅
- 步幅等于相邻两个窗口中心的距离
- 步幅为 2:特征图的宽度和高度都做了 2 倍降采样
- 实践中较少使用,以最大池化运算替代步幅实现降采样
最大池化运算
- 从输入提取窗口,并输出各个通道的最大值
- 最大池化通常使用 2*2 的窗口和步幅 2,以将特征图降采样 2 倍。对应的卷积通常使用 3*3 窗口和步幅 1
- 有利于学习特征的空间层级结构,且减少元素的个数,变相得让观察窗口越来越大
- 特征中往往编码了某种模式或概念在特征图的不同位置是否存在,观察不同特征的最大值比观察平均值能够给出更多的信息
小型数据集上的应用
根据大数据集,创建一个新的小数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61import os, shutil
original_dataset_dir = '/Users/fchollet/Downloads/kaggle_original_data' # 原始数据集目录
base_dir = '/Users/fchollet/Downloads/cats_and_dogs_small' # 新数据集目录
os.mkdir(base_dir)
# 划分后的训练、验证和测试的目录
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# 具体类的训练目录
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
# 具体类的验证目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
# 具体类的测试目录
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
# 前1000张复制到训练目录
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# 后500张复制到验证目录
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# 后500张复制到测试目录
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)构建网络、编译网络:(卷积+池化)*4 + 展平 + 全连接 + sigmoid激活
预处理数据(
keras.preprocessing.image)读取图像
解码为像素网格
网格转为浮点张量
正则化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16from keras.preprocessing.image import ImageDataGenerator
# 图像乘以 1/255 缩放
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir, # 目标目录
target_size=(150, 150), # 图像的大小调整为 150*150
batch_size=20,
class_mode='binary') # 二进制标签
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
利用
fit_generator拟合;参数steps_per_epoch:生成器中抽取这么多 batch 后进入下一个轮次;参数validation_data类似方法fit,但可以是一个生成器,此时还要指定参数validation_steps参数,表明需要从验证生成器中抽取多少个 batch 用于评估1
2
3
4
5
6history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)增强数据:利用多种能够生成可信图像的随机变换,从现有训练样本中生成更多的训练数据
对
ImageDataGenerator实例读取的图像执行多次随机变换1
2
3
4
5
6
7
8datagen = ImageDataGenerator(
rotation_range=40, # 图像随机旋转的角度范围,0-180
width_shift_range=0.2, # 图像在水平或垂直方向上,相对总宽度或总高度的平移范围
height_shift_range=0.2,
shear_range=0.2, # 随机错切变换的角度
zoom_range=0.2, # 图像随机缩放的范围
horizontal_flip=True, # 随机将一半图像水平翻转
fill_mode='nearest') # 填充新创建像素的方法,新像素可能来自于旋转或宽度/高度平移输入仍然高度相关,因为输入都来自于少量的原始图像
不能增强验证数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
预训练的CNN
预训练网络(pretrained network)是一个保存好的网络,之前已在大型数据集(通常是大规模图像分类任务)上训练好,可将其应用于某个不相干的任务上
特征提取:使用预训练网络从新样本中提取出特征,输入一个新的分类器,进行训练(以模型 VGG16 为例)
即使用预训练网络的卷积部分,训练时仅更新全连接层的参数
某个卷积层提取的表示的通用性(以及可复用性)取决于该层在模型中的深度
- 更靠近底部的层提取的是局部的、高度通用的特征图
- 更靠近顶部的层提取的是更加抽象的概念(顶部即接近输出)
- 若新数据集与原始模型的数据集有很大差异,最好只使用前几层做特征提取
实例化卷积部分(卷积基)
1
2
3
4
5from keras.applications import VGG16
conv_base = VGG16(weights='imagenet', # 模型初始化的权重检查点
include_top=False, # 模型最后是否包含全连接层
input_shape=(150, 150, 3)) # 输入到网络中的图像张量形状方法一:数据集上运行卷积基,输出 Numpy 数组保存到硬盘,之后作为输入进入独立的全连接分类器——不允许数据增强
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
base_dir = '/Users/fchollet/Downloads/cats_and_dogs_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
# 卷积基提取特征
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch) # 提取特征
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count: # 在读取完所有图像后终止循环(生成器会不断循环)
break
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
# 输入为(samples, 4, 4, 512),需要展平
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4 * 512))
# 定义全连接分类器并训练
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_features, train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels))方法二:添加 Dense 层来扩展已有模型,数据端到端在整个模型上运行——可以使用数据增强;编译和训练模型之前,必须“冻结”卷积基,即将属性
trainable设置为False1
2
3
4
5
6
7
8
9
10
11
12# 卷积基上添加一个密集连接分类器
from keras import models
from keras import layers
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
conv_base.trainable = False
# 训练过程相似
模型微调:将其顶部的几层“解冻” ,并将解冻的几层和新增加的部分联合训练
微调应当在添加部分训练完后进行,即先冻结卷积基,训练全连接分类器,后解冻,联合训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# 冻结直到某一层的所有层
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1': # 名字参见summary()的第一列
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
# 微调模型
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
CNN的可视化
卷积神经网络学到的表示非常适合可视化,很大程度上因为是视觉概念的表示
可视化中间激活:理解卷积神经网络连续的层如何对输入进行变换
展示网络中各个卷积层和池化层输出的特征图
将每个通道的内容分别绘制成二维图像
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63# 加载模型
from keras.models import load_model
model = load_model('cats_and_dogs_small_2.h5')
# 单张图像预处理
img_path = '/Users/fchollet/Downloads/cats_and_dogs_small/test/cats/cat.1700.jpg'
from keras.preprocessing import image
import numpy as np
img = image.load_img(img_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor, axis=0)
img_tensor /= 255. # # img_tensor.shape为 (1, 150, 150, 3)
# 实例化模型
from keras import models
layer_outputs = [layer.output for layer in model.layers[:8]] # 提取前 8 层的输出
activation_model = models.Model(inputs=model.input, outputs=layer_outputs) # 创建一个模型,给定输入,返回这些输出
# 返回8个Numpy数组组成的列表,每一层的激活对应一个数组
activations = activation_model.predict(img_tensor)
# 可视化第一层激活的第四个通道
import matplotlib.pyplot as plt
first_layer_activation = activations[0]
plt.matshow(first_layer_activation[0, :, :, 4], cmap='viridis')
# 可视化所有通道
layer_names = []
for layer in model.layers[:8]: # 层的名称
layer_names.append(layer.name)
images_per_row = 16
for layer_name, layer_activation in zip(layer_names, activations):
n_features = layer_activation.shape[-1] # 特征图中的特征个数
# 特征图的形状为(1, size, size, n_features)
size = layer_activation.shape[1]
n_cols = n_features // images_per_row # 矩阵中将激活通道平铺
display_grid = np.zeros((size * n_cols, images_per_row * size))
for col in range(n_cols): # 每个过滤器平铺到一个大的水平网格
for row in range(images_per_row):
channel_image = layer_activation[0,
:, :,
col * images_per_row + row]
# 特征处理,使其美观
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image, 0, 255).astype('uint8')
# 显示网格
display_grid[col * size : (col + 1) * size,
row * size : (row + 1) * size] = channel_image
scale = 1. / size
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid, aspect='auto', cmap='viridis')
可视化过滤器:理解卷积神经网络中每个过滤器容易接受的视觉模式或视觉概念
显示每个过滤器所响应的视觉模式
从空白输入图像开始,将梯度下降应用于卷积神经网络输入图像的值,让某个过滤器的响应最大化。最终得到使选定过滤器具有最大响应的图像
构建损失函数,使某个过滤器最大化
1
2
3
4
5
6
7
8
9
10
11from keras.applications import VGG16
from keras import backend as K
model = VGG16(weights='imagenet',
include_top=False)
layer_name = 'block3_conv1'
filter_index = 0
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])得到损失相对于模型输入的梯度
1
2
3grads = K.gradients(loss, model.input)[0] # gradients 返回的是一个张量列表
# 标准化,确保更新的值处于相同的范围
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5) # 防止除以 0指定输入图像,得到损失和梯度
1
2
3
4iterate = K.function([model.input], [loss, grads])
import numpy as np
loss_value, grads_value = iterate([np.zeros((1, 150, 150, 3))])随机梯度下降,最大化损失
1
2
3
4
5
6input_img_data = np.random.random((1, 150, 150, 3)) * 20 + 128.
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data]) # 计算损失值和梯度值
input_img_data += grads_value * step # 沿着让损失最大化的方向调节输入图像对图像张量进行后处理
1
2
3
4
5
6
7
8
9
10
11
12def deprocess_image(x):
# 标准化
x -= x.mean()
x /= (x.std() + 1e-5)
x *= 0.1
# 裁切到区间【0,1】
x += 0.5
x = np.clip(x, 0, 1)
# x转换为RGB数组
x *= 255
x = np.clip(x, 0, 255).astype('uint8')
return x具体的生成函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def generate_pattern(layer_name, filter_index, size=150):
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
grads = K.gradients(loss, model.input)[0]
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
iterate = K.function([model.input], [loss, grads])
input_img_data = np.random.random((1, size, size, 3)) * 20 + 128.
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
img = input_img_data[0]
return deprocess_image(img)
可视化类激活的热力图:理解图像的哪个部分被识别为属于某个类别
对输入图像生成类激活的热力图,表示每个位置对该类别的重要程度
Grad-CAM
给定一张输入图像,对于一个卷积层的输出特征图,用类别相对于通道的梯度对这个特征图中的每个通道进行加权
加载网络
为模型预处理一张图像
1
2
3
4
5
6
7
8
9
10
11
12
13from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input, decode_predictions
import numpy as np
img_path = '/Users/fchollet/Downloads/creative_commons_elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img) # 形状为(224, 224, 3) 的float32格式的Numpy数组
x = np.expand_dims(x, axis=0) # 添加一个维度,转换为批量
x = preprocess_input(x) # 批量进行预处理(按通道进行颜色标准化)应用 Grad-CAM 算法(
np.argmax(preds[0])为386,即对应预测向量中,认为最符合这个类别的是第386个元素)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17african_elephant_output = model.output[:, 386]
last_conv_layer = model.get_layer('block5_conv3') # 输出特征图,是网络的最后一个卷积层
grads = K.gradients(african_elephant_output, last_conv_layer.output)[0] # 类别相对于最后一个卷积层输出特征图的梯度
pooled_grads = K.mean(grads, axis=(0, 1, 2)) # 向量,每个元素是特定特征图通道的梯度平均大小
iterate = K.function([model.input],
[pooled_grads, last_conv_layer.output[0]])
pooled_grads_value, conv_layer_output_value = iterate([x]) # 给定的样本图像,pooled_grads 和 block5_conv3 层的输出特征图
for i in range(512): # 每个通道*重要程度
conv_layer_output_value[:, :, i] *= pooled_grads_value[i]
heatmap = np.mean(conv_layer_output_value, axis=-1) # 特征图的逐通道平均值即为类激活的热力图将热力图标准化到 0-1
原始图像叠加到热力图
1
2
3
4
5
6
7
8
9
10
11
12
13import cv2
img = cv2.imread(img_path) # 加载原始图像
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0])) # 热力图的大小调整为与原始图像相同
heatmap = np.uint8(255 * heatmap) # 热力图转换为 RGB 格式
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET) # 应用于原始图像
superimposed_img = heatmap * 0.4 + img # 0.4是热力图强度因子
cv2.imwrite('/Users/fchollet/Downloads/elephant_cam.jpg', superimposed_img)
RNN
文本数据处理
- 文本向量化
- 文本分割为单词,并将每个单词转换为一个向量
- 文本分割为字符,并将每个字符转换为一个向量
- 单词或字符的 n-gram,并将每个 n-gram 转换为一个向量——形成二元、三元语法袋,即成立的是标记的集合
- 分解的单元称为标记(token),其过程为分词(tokenization)
- 独热编码
- 标记嵌入(token embedding)
- 词袋是一种不保存顺序的分词方法,往往被用于浅层的语言处理模型如 logistic 回归和随机森林
独热码
字符级独热码
1
2
3
4
5
6
7
8
9
10
11
12import string
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
characters = string.printable # 所有可打印的 ASCII 字符
token_index = dict(zip(range(1, len(characters) + 1), characters))
max_length = 50
results = np.zeros((len(samples), max_length, max(token_index.keys()) + 1)) # 结果保存在results中
for i, sample in enumerate(samples):
for j, character in enumerate(sample):
index = token_index.get(character)
results[i, j, index] = 1.Keras 内置函数实现独热编码
1
2
3
4
5
6
7
8
9
10
11
12from keras.preprocessing.text import Tokenizer
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
tokenizer = Tokenizer(num_words=1000) # 分词器,只考虑前1000个最常见的单词
tokenizer.fit_on_texts(samples) # 构建单词索引
sequences = tokenizer.texts_to_sequences(samples) # 字符串转换为整数索引组成的列表
one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary') # 得到one-hot二进制表示
word_index = tokenizer.word_index # 找回单词索引 {'the': 1, ... 'homework': 9}如果唯一标记的数目很多,则可将单词散列编码为固定长度的向量,避免维护一个显式的单词索引
1
2
3
4
5
6
7
8
9samples = ['The cat sat on the mat.', 'The dog ate my homework.']
dimensionality = 1000 # 单词保存为长度为1000的向量
max_length = 10
results = np.zeros((len(samples), max_length, dimensionality))
for i, sample in enumerate(samples):
for j, word in list(enumerate(sample.split()))[:max_length]:
index = abs(hash(word)) % dimensionality # 将单词散列为0~1000范围内的一个随机整数索引
results[i, j, index] = 1.
词嵌入
one-hot 编码得到的向量是二进制、稀疏、维度高,词嵌入是低维的浮点数向量
- 完成主任务(如文档分类或情感预测)的同时学习词嵌入
- 预计算词嵌入,将其加载到模型中
合理的做法是对每个新任务都学习一个新的嵌入空间——学习 Embedding 层的权重;Embedding 层实际上是一种字典查找,将整数索引(表示特定单词)映射为密集向量
1
2
3from keras.layers import Embedding
embedding_layer = Embedding(1000, 64, input_length=10) # 标记个数(1000),嵌入的维度(64),句子最长的长度输入是一个二维整数张量(samples, sequence_length),返回三维浮点数张量(samples, sequence_length, embedding_dimensionality)
1
2
3
4
5
6
7from keras.models import Sequential
from keras.layers import Flatten, Dense, Embedding
model = Sequential()
model.add(Embedding(10000, 8, input_length=maxlen))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))预计算的词嵌入:
类似卷积基,可以下载词嵌入数据库并在 Keras 的 Embedding 层中使用
word2vec, GloVe等
解析嵌入文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19glove_dir = '/Users/fchollet/Downloads/glove.6B'
embeddings_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'))
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
embedding_dim = 100
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
if i < max_words:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector # 嵌入索引找不到的词,其嵌入向量均为0创建模型,加载嵌入
1
2
3
4
5# 定义模型
...
# 加载嵌入层权重并冻结
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
RNN
以上神经网络单独处理每个输入,在输入与输入之间没有保存任何状态
RNN 的 Numpy 实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import numpy as np
timesteps = 100 # 输入序列的时间步数
input_features = 32 # 输入特征空间的维度
output_features = 64 # 输出特征空间的维度
inputs = np.random.random((timesteps, input_features))
state_t = np.zeros((output_features,)) # 初始状态:全零向量
# 创建随机的权重矩阵
W = np.random.random((output_features, input_features))
U = np.random.random((output_features, output_features))
b = np.random.random((output_features,))
successive_outputs = []
for input_t in inputs:
# 由输入和当前状态(前一个输出)得到当前输出
output_t = np.tanh(np.dot(W, input_t) + np.dot(U, state_t) + b)
successive_outputs.append(output_t) # 输出保存到一个列表
state_t = output_t # 更新网络的状态,用于下一个时间步
final_output_sequence = np.stack(successive_outputs, axis=0) # 输出是一个形状为(timesteps,output_features) 的二维张量Keras 中 SimpleRNN 接收输入(batch_size, timesteps, input_features),可以输出(batch_size, timesteps, output_features)或(batch_size, output_features),取决于参数
return_sequences=True堆叠需要所有中间层都返回完整的输出序列
1
2
3
4model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32))SimpleRNN 不擅长处理长序列
LSTM:添加额外的数据流,其中携带着跨越时间步的信息;适用于评论分析全局的长期性结构
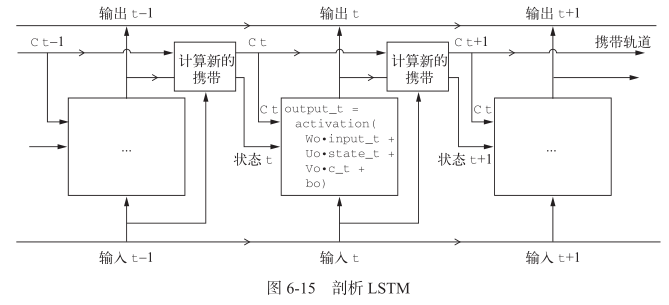
1
2
3
4
5
6output_t = activation(dot(state_t, Uo) + dot(input_t, Wo) + dot(C_t, Vo) + bo)
i_t = activation(dot(state_t, Ui) + dot(input_t, Wi) + bi)
f_t = activation(dot(state_t, Uf) + dot(input_t, Wf) + bf)
k_t = activation(dot(state_t, Uk) + dot(input_t, Wk) + bk)
c_t+1 = i_t * k_t + c_t * f_t1
2
3model = Sequential()
model.add(Embedding(max_features, 32))
model.add(LSTM(32))
堆叠循环与双向循环
dropout降低过拟合
- 每个循环层都有两个与 dropout 相关的参数:
dropout指定该层输入单元的丢弃比率,recurrent_dropout指定循环单元的丢弃比率
- 每个循环层都有两个与 dropout 相关的参数:
堆叠循环层:提高网络的表示能力
- 所有中间层都应该返回完整的输出序列(3D 张量)
- 通过指定
return_sequences=True实现
双向循环层:相同的信息以不同的方式呈现给循环网络
包含两个普通 RNN,每个 RNN 分别沿一个方向对输入序列进行处理,并结合二者的表示
如果在序列数据中最近的数据比序列开头包含更多的信息,双向循环的效果就不明显
逆序序列训练一个 RNN
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30from keras.datasets import imdb
from keras.preprocessing import sequence
from keras import layers
from keras.models import Sequential
max_features = 10000 # 单词索引规模
maxlen = 500 # 序列最长长度
(x_train, y_train), (x_test, y_test) = imdb.load_data(
num_words=max_features)
# 反转序列
x_train = [x[::-1] for x in x_train]
x_test = [x[::-1] for x in x_test]
# 填充序列
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
model = Sequential()
model.add(layers.Embedding(max_features, 128))
model.add(layers.LSTM(32))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)训练并评估一个双向 LSTM
1
2
3
4
5
6
7
8
9
10model = Sequential()
model.add(layers.Embedding(max_features, 32))
model.add(layers.Bidirectional(layers.LSTM(32))) # 第一个参数是一个循环层实例
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
一维卷积神经网络
使用一维卷积,从序列中提取局部一维序列段(即子序列);对每个序列段执行相同的输入变换,所以在句子中某个位置学到的模式稍后可以在其他位置被识别,因此一维卷积神经网络具有平移不变性
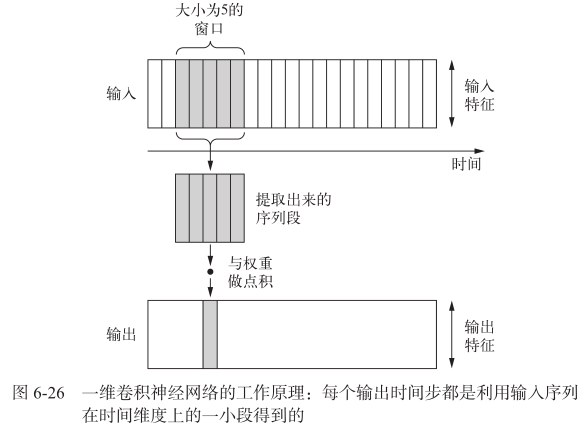
池化: 从输入中提取一维序列段,输出其最大值(最大池化)或平均值(平均池化),用于降低一维输入的长度(子采样)
接收的输入为(samples, time, features)的三维张量,返回类似形状的三维张量,卷积窗口是时间轴上的一维窗口
一维卷积神经网络可以使用更大的卷积窗口
简单的网络
1
2
3
4
5
6
7model = Sequential()
model.add(layers.Embedding(max_features, 128, input_length=max_len)) # (None, 500, 128) 每一行是一个单词
model.add(layers.Conv1D(32, 7, activation='relu')) # (None, 494, 32)
model.add(layers.MaxPooling1D(5))
model.add(layers.Conv1D(32, 7, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
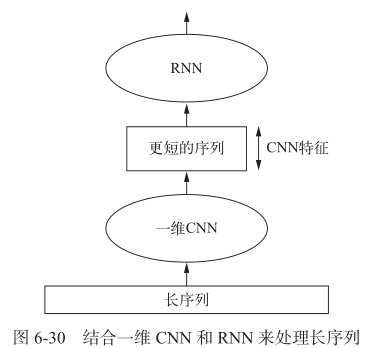
model.add(layers.Dense(1))结合卷积神经网络的速度和轻量与 RNN 的顺序敏感性,可以在 RNN 前面使用一维卷积神经网络作为预处理步骤——适用于非常长,以至于 RNN 无法处理的序列 (如包含上千个时间步的序列)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Conv1D(32, 5, activation='relu',
input_shape=(None, float_data.shape[-1]))) # 输出(None, None, 32)
model.add(layers.MaxPooling1D(3)) # 输出(None, None, 32)
model.add(layers.Conv1D(32, 5, activation='relu')) # 输出(None, None, 32)
model.add(layers.GRU(32, dropout=0.1, recurrent_dropout=0.5)) # 输出(None, 32)
model.add(layers.Dense(1)) # 输出(None, 1)
model.summary()
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=val_steps)