《Hands-on Machine Learning》第二部分阅读笔记(3)数据接口与 CNN
TF 加载和预处理数据
Data API
from_tensor_slices(X)创建一个元素都是 X 的切片(沿第一维)的 tf.data.Dataset1
2X = tf.range(10) # any data tensor
dataset = tf.data.Dataset.from_tensor_slices(X)
链接转换
一旦有了数据集,就可以通过调用转换方法对它做各种转换
dataset = dataset.repeat(3).batch(7)1
2
3
4
5tf.Tensor([0 1 2 3 4 5 6], shape=(7,), dtype=int32)
tf.Tensor([7 8 9 0 1 2 3], shape=(7,), dtype=int32)
tf.Tensor([4 5 6 7 8 9 0], shape=(7,), dtype=int32)
tf.Tensor([1 2 3 4 5 6 7], shape=(7,), dtype=int32)
tf.Tensor([8 9], shape=(2,), dtype=int32)- 为了让所有 batch 都具有完全相同的大小,需要丢弃最后一个 batch,设置参数
drop_remainder=True
- 为了让所有 batch 都具有完全相同的大小,需要丢弃最后一个 batch,设置参数
通过
map()将任何转换应用到 item1
dataset = dataset.map(lambda x: x * 2)
通过
apply()将任何转换应用到数据集1
2dataset = dataset.apply(tf.data.experimental.unbatch())
# 新数据集中的每一项都将是单个整数张量,而不是一批7个整数通过
filter()过滤1
dataset = dataset.filter(lambda x: x < 10)
仅查看数据集中的几个项目:
dataset.take(3)
打乱数据
当训练集中的实例独立同分布,梯度下降法效果最好——需要 shuffle data
1
2dataset = tf.data.Dataset.range(10).repeat(3) # 0 to 9, three times
dataset = dataset.shuffle(buffer_size=5, seed=42).batch(7)- 设置随机数种子
将源数据分成多个文件,然后在训练过程中以随机顺序读取
可以随机选择多个文件,并同时读取,交错它们的行
1
2
3
4
5
6filepath_dataset = tf.data.Dataset.list_files(train_filepaths, seed=42)
n_readers = 5
dataset = filepath_dataset.interleave(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1),
cycle_length=n_readers)train_filepaths是一个列表,里面为源文件的路径list_files()返回一个打乱文件路径的数据集interleave()一次读取 5 个文件——提取 5 个文件路径,对于每个路径,调用传入的函数;在这 5 个数据集之间循环,每次读取一行,直到所有数据集都用完为止skip()跳过第一行- 将
num_parallel_calls参数设置为想要的线程数,实现并行
预处理数据
举例:
1
2
3
4
5
6
7
8X_mean, X_std = [...] # mean and scale of each feature in the training set
n_inputs = 8
def preprocess(line):
defs = [0.] * n_inputs + [tf.constant([], dtype=tf.float32)]
fields = tf.io.decode_csv(line, record_defaults=defs)
x = tf.stack(fields[:-1])
y = tf.stack(fields[-1:])
return (x - X_mean) / X_std, y- 假设预先计算了训练集中每个特征的均值和标准差
- 取一个CSV行,使用
tf.io.decode_csv()解析,其中第二个参数为文件中每列默认值数组 decode_csv()返回一个标量张量列表,需要调用tf.stack()把标量张量堆叠成一个一维张量- 缩放输入特征
合并以上过程
- 创建并返回一个数据集,该数据集从多个 CSV 文件中加载数据,shuffle、预处理并 batch
1 | def csv_reader_dataset(filepaths, repeat=None, n_readers=5, |
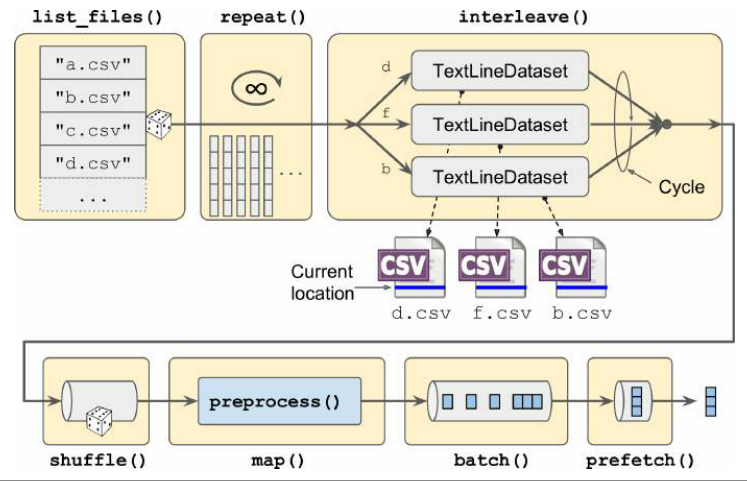
预取数据
prefetch:当训练算法处理一批数据时,数据集已经在并行处理下一批数据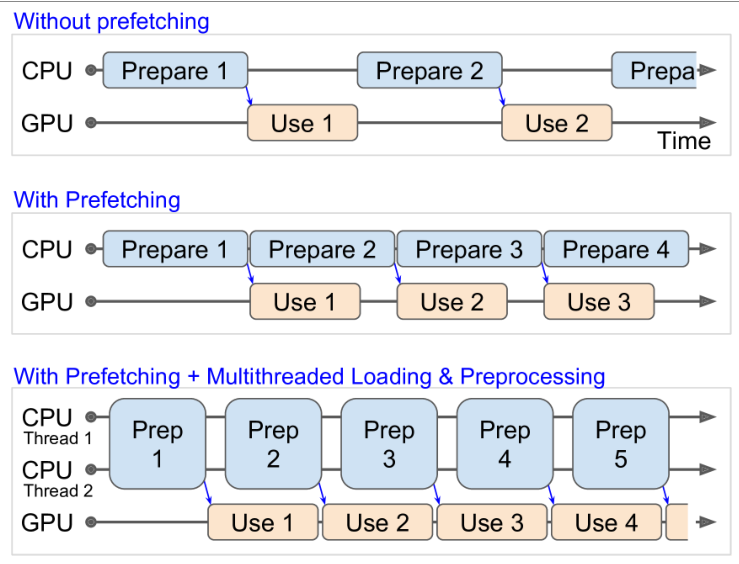
TFRecord 格式
TFRecord 格式是 TensorFlow 存储大量数据并高效读取数据的首选格式
1
2
3
4
5
6
7
8
9# 写
with tf.io.TFRecordWriter("my_data.tfrecord") as f:
f.write(b"This is the first record")
f.write(b"And this is the second record")
# 读取
filepaths = ["my_data.tfrecord"]
dataset = tf.data.TFRecordDataset(filepaths)
for item in dataset:
print(item)
压缩
设置参数即可
1
2
3options = tf.io.TFRecordOptions(compression_type="GZIP")
with tf.io.TFRecordWriter("my_compressed.tfrecord", options) as f:
...读取时也要说明压缩类型
1
2dataset = tf.data.TFRecordDataset(["my_compressed.tfrecord"],
compression_type="GZIP")
协议缓冲区
记录文件通常包含序列化的协议缓冲区——可移植、可扩展且高效的二进制格式
1
2
3
4
5
6syntax = "proto3";
message Person {
string name = 1;
int32 id = 2;
repeated string email = 3;
}- 使用 protobuf 格式版本3
- 对象 person 有一个字符串的名称,一个类型 int32 的 id,以及零个或多个电子邮件字段
- 数字1、2和3是字段标识符
1 | from person_pb2 import Person # import the generated access class |
TensorFlow 的协议缓冲区
略
加载和解析示例
略
Handling Lists of Lists Using the SequenceExample Protobuf
略
Features API
处理数据的特征
1
2housing_median_age = tf.feature_column.numeric_column(
"housing_median_age", normalizer_fn=lambda x: (x - age_mean) / age_std)- 参数
normalizer_fn用于指定一个正则化函数,前一个参数是对应数据的一个特征名
- 参数
对数据分块
1
2
3median_income = tf.feature_column.numeric_column("median_income")
bucketized_income = tf.feature_column.bucketized_column(
median_income, boundaries=[1.5, 3., 4.5, 6.])
分类特征
如果一个特征已经表示为一个类别标识,则使用
categorical_column_with_identity(),否则1
2
3ocean_prox_vocab = ['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN']
ocean_proximity = tf.feature_column.categorical_column_with_vocabulary_list(
"ocean_proximity", ocean_prox_vocab)从文件加载:
categorical_column_with_vocabulary_file()以上两个函数将每个类别映射到它在词汇表中的索引
对于具有大量词汇的分类列,可以使用
categorical_column_with_hash_bucket()编码1
2city_hash = tf.feature_column.categorical_column_with_hash_bucket(
"city", hash_bucket_size=1000)
交叉分类特征
可能两个(或更多)分类特征在联合使用时更有意义
1
2
3
4bucketized_age = tf.feature_column.bucketized_column(
housing_median_age, boundaries=[-1., -0.5, 0., 0.5, 1.]) # age was scaled
age_and_ocean_proximity = tf.feature_column.crossed_column(
[bucketized_age, ocean_proximity], hash_bucket_size=100)将纬度和经度交叉到一个分类要素中
1
2
3
4
5
6
7
8latitude = tf.feature_column.numeric_column("latitude")
longitude = tf.feature_column.numeric_column("longitude")
bucketized_latitude = tf.feature_column.bucketized_column(
latitude, boundaries=list(np.linspace(32., 42., 20 - 1)))
bucketized_longitude = tf.feature_column.bucketized_column(
longitude, boundaries=list(np.linspace(-125., -114., 20 - 1)))
location = tf.feature_column.crossed_column(
[bucketized_latitude, bucketized_longitude], hash_bucket_size=1000)
独热编码分类特征
必须先对特征进行编码,然后才能将其输入神经网络
1
ocean_proximity_one_hot = tf.feature_column.indicator_column(ocean_proximity)
一个独热向量有字典长度的大小
Embedding 编码分类特征
Embedding:
1
2ocean_proximity_embed = tf.feature_column.embedding_column(ocean_proximity,
dimension=2)每个类别编码为二维张量,得到一个 5*2 的矩阵
嵌入结果是可学习的
使用特征列进行分析
1 | columns = [bucketized_age, ....., median_house_value] # all features + target |
make_parse_example_spec()生成特性描述使用这些特性描述来解析序列化的示例,并将目标列与输入特性分开
1
2
3
4def parse_examples(serialized_examples):
examples = tf.io.parse_example(serialized_examples, feature_descriptions)
targets = examples.pop("median_house_value") # separate the targets
return examples, targets创建一个 TFRecordDataset,读取成批的序列化示例
1
2
3batch_size = 32
dataset = tf.data.TFRecordDataset(["my_data_with_features.tfrecords"])
dataset = dataset.repeat().shuffle(10000).batch(batch_size).map(parse_examples)
在模型中使用特征列
特征列也可以直接在模型中使用,将所有输入特征转换成神经网络可以处理的单一密集向量
1
2
3
4
5
6
7
8columns_without_target = columns[:-1]
model = keras.models.Sequential([
keras.layers.DenseFeatures(feature_columns=columns_without_target),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer="sgd", metrics=["accuracy"])
steps_per_epoch = len(X_train) // batch_size
history = model.fit(dataset, steps_per_epoch=steps_per_epoch, epochs=5)DenseFeatures 层将负责将每个输入要素转换为密集表示
CNN
视觉皮层的结构
- 视觉皮层中的许多神经元有一个小的局部感受野,这意味着它们只对位于视野有限区域的视觉刺激作出反应
- 一些神经元只对水平线的图像做出反应,而其他神经元只对不同方向的线做出反应
- 高级神经元基于相邻低级神经元的输出——每个神经元只与前一层的几个神经元相连
卷积层
Filter(卷积核)
- 神经元的权重可以用感受野大小的小图像来表示;神经元将忽略其感受野中除中央垂直线以外的所有东西;第二个卷积核是一个黑色正方形,中间有一条水平白线。再一次,使用这些权重的神经元会忽略它们感受野里除了中央水平线以外的一切
- 训练期间,卷积层将自动学习对其任务最有用的过滤器
- 上面的层将学习将它们组合成更复杂的模式
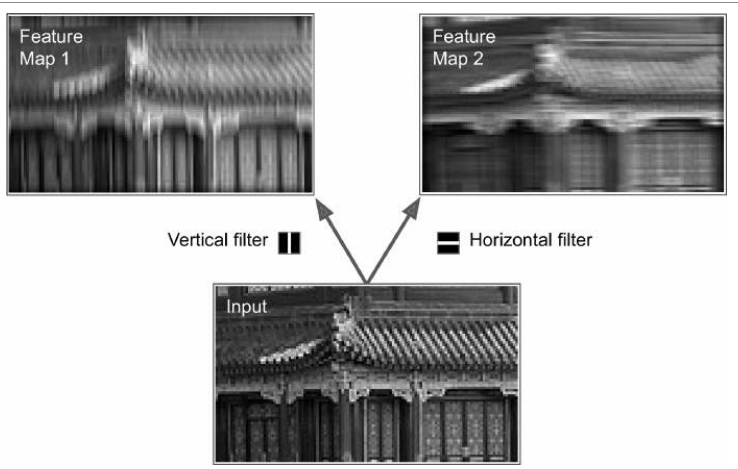
堆叠多个特征图
一个卷积层有多个滤波器,每个滤波器输出一个特征图
在每个特征图中每个像素有一个神经元,并且给定特征图中的所有神经元共享相同的参数——权重和 bias
卷积层同时对其输入应用多个可训练滤波器,使其能够检测输入中任何地方的多个特征
输入图像也由多个子层组成——每个颜色通道一个子层
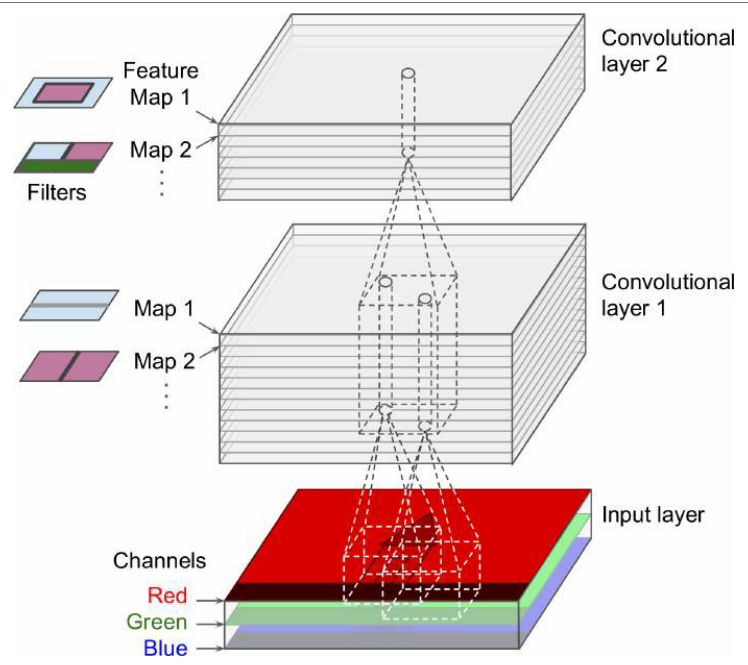
位于给定卷积层l中特征图 k 的第 I 行第 j 列的神经元,连接到所有特征图(层 l–1)中位于第$i × s_h$至I×sh+FH–1行和第$j × s_w$至$j×S_W+f_w–1$列的前一层神经元的输出
计算神经元的输出:
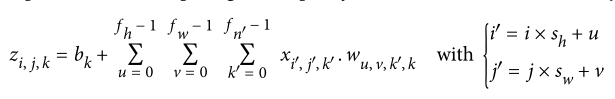
TensorFlow 的实现
图像表示为 [height, width, channels]([mini-batch size, height, width, channels])
权重被表示为形状的 4D 张量$[f_h,f_w,f_{n’},f_n]$,卷积层的偏置项简单地表示为形状的 1D 张量$[f_n]$。
1
2
3
4
5
6
7
8
9
10
11
12
13from sklearn.datasets import load_sample_image
# Load sample images
china = load_sample_image("china.jpg") / 255
flower = load_sample_image("flower.jpg") / 255
images = np.array([china, flower])
batch_size, height, width, channels = images.shape
# Create 2 filters
filters = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
filters[:, 3, :, 0] = 1 # vertical line
filters[3, :, :, 1] = 1 # horizontal line
outputs = tf.nn.conv2d(images, filters, strides=1, padding="SAME")
plt.imshow(outputs[0, :, :, 1], cmap="gray") # plot 1st image's 2nd feature map
plt.show()加载了两个示例图像
像素强度(对于每个颜色通道)表示为一个从 0 到 255 的字节——缩放
创建两个$7 × 7$的过滤器
使用
tf.nn.conv2d(),使用零填充padding="SAME"和步幅 2images 是输入 batch,4D 张量
filters 过滤器,4D 张量
strides 步幅,默认为 1,1D 张量四个元素,两个中心元素是垂直和水平步幅,第一个和第四个元素为 1,指定批处理步距(跳过一些实例)和通道步距(跳过前一层的一些特征图或通道)
padding 填充,卷积层在必要时使用零填充,或者不填充,前者使得输出神经元的数量等于输入神经元的数量除以步幅,向上舍入
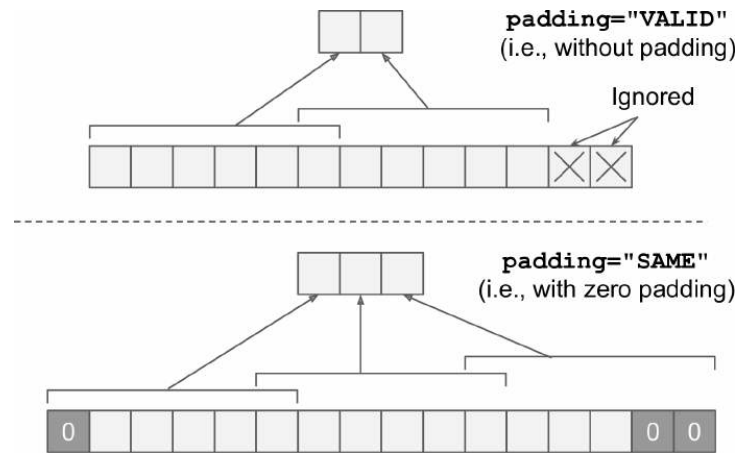
等价于
1
2conv = keras.layers.Conv2D(filters=32, kernel_size=3, strides=1,
padding="SAME", activation="relu")
内存需求
- 卷积层需要大量的内存——在训练期间,在正向传递期间计算的所有内容都需要为反向传递保留
- 预测过程中,一层占用的内存可以在计算完下一层后立即释放,因此只需要两个连续层所需的内存
池化层
池化层中的每个神经元都连接到前一层中有限数量的神经元的输出
池化神经元没有权重;它只是使用一个聚合函数(如最大值或平均值)来聚合输入——只有每个感受野的最大输入(平均)值才能到达下一层,而其他输入被丢弃(下面这个图没有设置 padding)
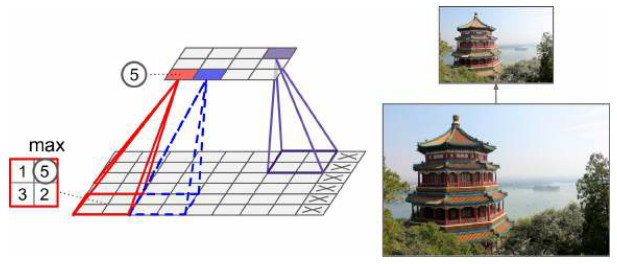
最大池层对小的转换引入了一定程度的不变性——平移不变性、少量的旋转不变性和轻微的比例不变性——这种不变性(即使它是有限的)在预测不应该依赖于这些细节的情况下是有用的
最大池化破坏性很大,有时任务需要输入的微小变化导致输出相应产生微小变化
TensorFlow 的实现
1 | max_pool = keras.layers.MaxPool2D(pool_size=2) |
最大池化比平均池化的效果往往更好
最大池化和平均池化可以沿着深度维度而不是空间维度执行,并且深度方向的最大池化层将确保输出是相同的
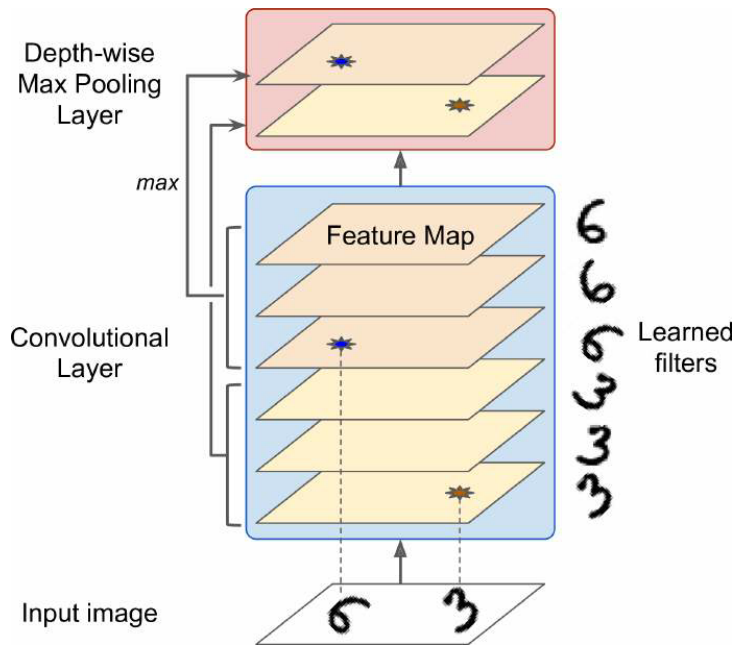
Keras 不包括深度方向的 max pool 层;
tf.nn.max_pool()可以设置内核大小和步长为 4 元组,前三个值应该是 1——表示内核大小和沿着批次、高度和宽度尺寸的步幅应该是 1——最后一个值应该是想要的沿着深度维度的任何内核大小和步长,但必须是输入深度的除数,例如,如果前一层输出20 个特征图,就不能设置为 31
2
3
4
5
6
7
8output = tf.nn.max_pool(images,
ksize=(1, 1, 1, 3),
strides=(1, 1, 1, 3),
padding="VALID")
# 作为一个层包含在Keras中,则只需用 lambda 层封装
depth_pool = keras.layers.Lambda(
lambda X: tf.nn.max_pool(X, ksize=(1, 1, 1, 3), strides=(1, 1, 1, 3),
padding="VALID"))全局平均池层(global average pooling layer):计算每个完整特征图的平均值,即使用一个与输入具有相同空间维度的池化内核,适合作为输出层
1
2
3global_avg_pool = keras.layers.GlobalAvgPool2D()
# 等价于
global_avg_pool = keras.layers.Lambda(lambda X: tf.reduce_mean(X, axis=[1, 2]))
CNN 结构
典型的 CNN 架构堆叠几个卷积层,然后是另一个池化层,并随着网络越来越深,图越来越小,但特征图越来越多;最后跟着一个 MLP,以及最后输出预测的层
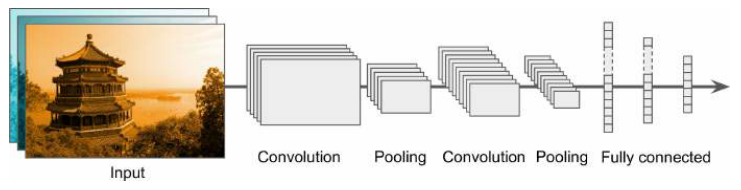
简单的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19from functools import partial
DefaultConv2D = partial(keras.layers.Conv2D,
kernel_size=3, activation='relu', padding="SAME")
model = keras.models.Sequential([
DefaultConv2D(filters=64, kernel_size=7, input_shape=[28, 28, 1]),
keras.layers.MaxPooling2D(pool_size=2),
DefaultConv2D(filters=128),
DefaultConv2D(filters=128),
keras.layers.MaxPooling2D(pool_size=2),
DefaultConv2D(filters=256),
DefaultConv2D(filters=256),
keras.layers.MaxPooling2D(pool_size=2),
keras.layers.Flatten(),
keras.layers.Dense(units=128, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(units=64, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(units=10, activation='softmax'),
])
LeNet-5
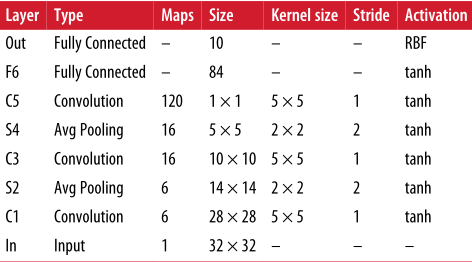
- 池化层:每个神经元计算其输入的平均值,然后将结果乘以一个可学习系数并加上一个可学习的偏差项,最后应用激活函数(每个图一个系数)
- C3 大多数神经元只与三四个 S2 中的神经元相连
AlexNet
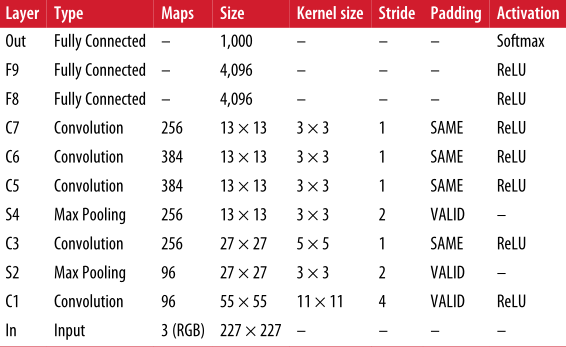
两种正则化
- F9 和 F8 应用 50% 的 Dropout
- 将训练图像移动各种偏移量、水平翻转并改变光照条件来执行数据增强
C1 层和 C3 层的 ReLU 之后立即使用竞争归一化步骤——最强激活的神经元抑制位于相邻特征图中相同位置的其他神经元

GoogleNet
- 使用 inception module
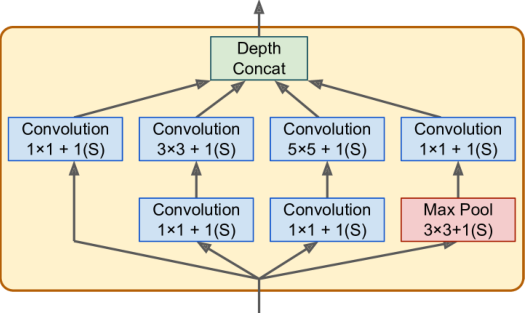
- $3 × 3 + 1(S)$:卷积核为$3 × 3$,步幅为1,padding 为 same
- 输入信号被复制并送到四个不同的层,所有卷积层都使用 ReLU 激活函数
- 第二组卷积层使用不同的内核大小,以不同的比例捕获模式,输出都具有与输入相同的高度和宽度,因此可以在最终的深度连接层(
tf.concat()且axis=3)中沿着深度维度连接所有输出 - 具体结构:
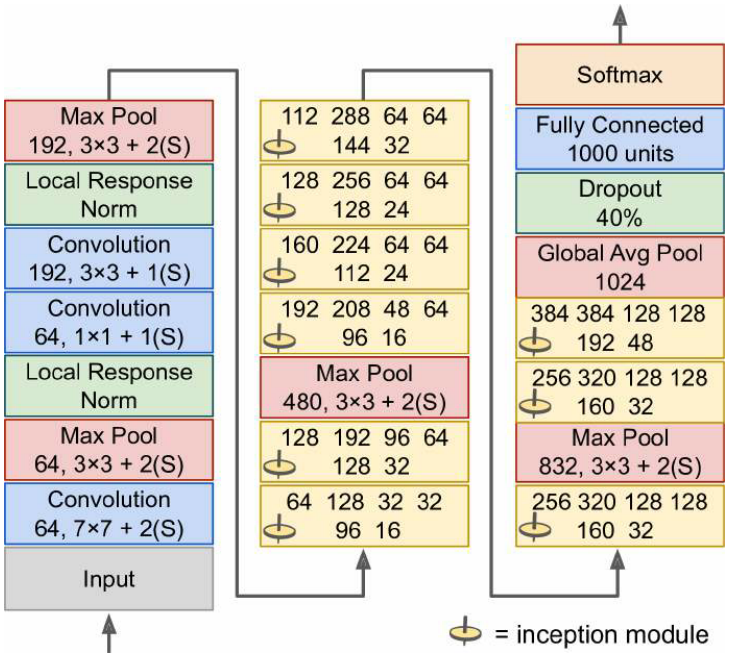
- 包括九个 inception module,6 个数字代表模块中每个卷积层输出的特征图的数量
- 所有卷积层都使用 ReLU 激活函数
- 前两层将图像的高度和宽度除以 4,减少计算量
- 第一层使用大的卷积核,因此大部分信息仍然被保留
- 后面的 1*1 卷积层充当瓶颈层
- 池化层加快计算
- inception module 的堆叠,与几个最大池层交错,以减少维度并加快网络速度
- 全局平均汇集图层只是输出每个特征图的平均值
VGGNet
- 2 或 3 个卷积层,一个池化层,然后是 2 或 3 个卷积层,一个池化层
- 最终的密集网络,有2个隐藏层和输出层
- 只用$ 3 × 3 $的过滤器
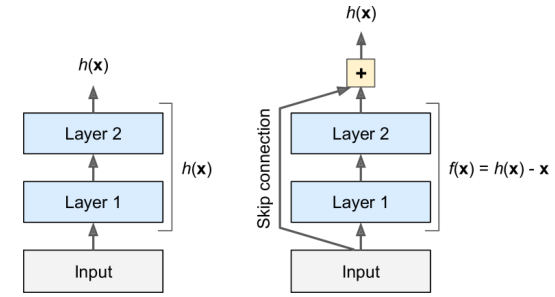
ResNet
- 添加了一个跳过连接——强制模型$f(x)= h(x)–x$而不是$h(x)$
- 首先对恒等式函数建模。如果目标函数相当接近于恒等式函数,将大大加快训练速度
- 如果添加了许多跳过连接,即使几个层还没有开始学习,网络也可以开始学习信息
- 深度残差网络可以看作是残差单元的堆叠,每个残差单元都是一个具有跳跃连接的小神经网络
- 中间只是一个非常深的简单残差单元的堆叠,每个残差单元由两个卷积层组成
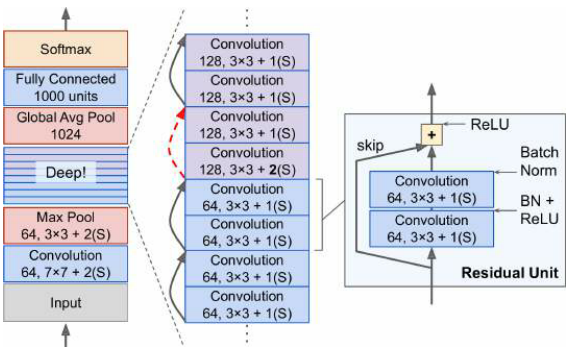
为保证输出特征图的形状和深度匹配,需要增加一个卷积层
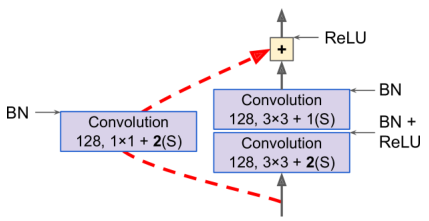
Xception
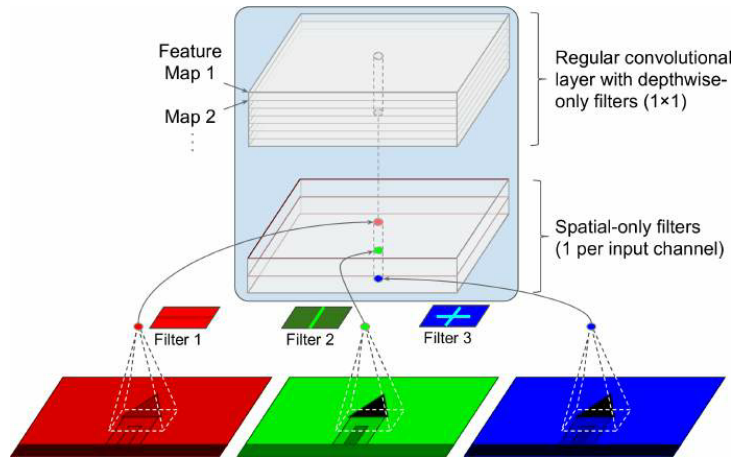
深度可分离卷积
常规卷积层使用的滤波器,试图同时捕捉空间模式(如椭圆形)和跨通道模式(如嘴+鼻子+眼睛=脸),可分离卷积层则认为空间模式和跨通道模式可以分别建模——由两部分组成:第一部分对每个输入特征图应用单个空间滤波器,第二部分专门寻找跨信道模式(只是一个带有$1 × 1$卷积核的卷积层)
应该避免在通道太少的层的后面使用可分离的卷积层
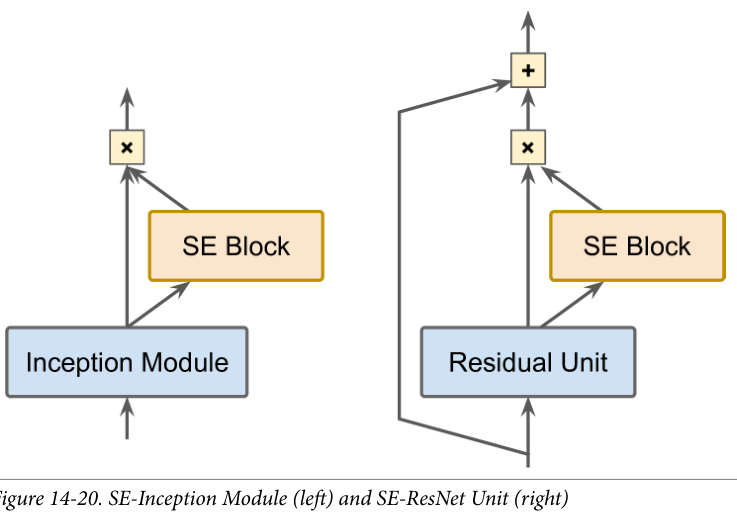
SENet
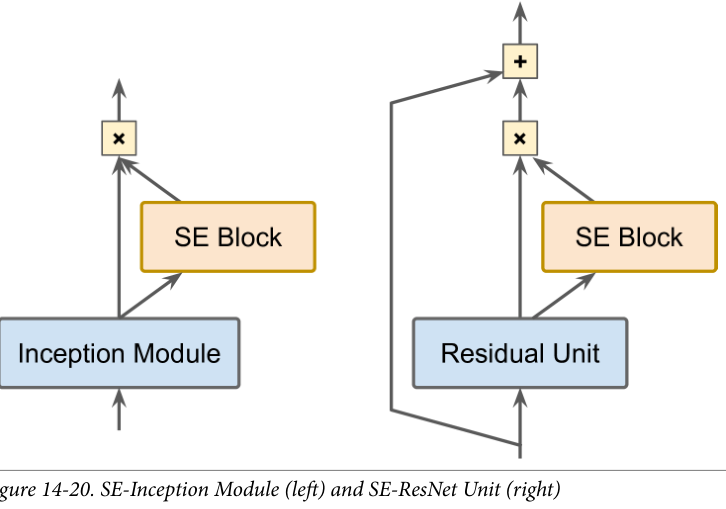
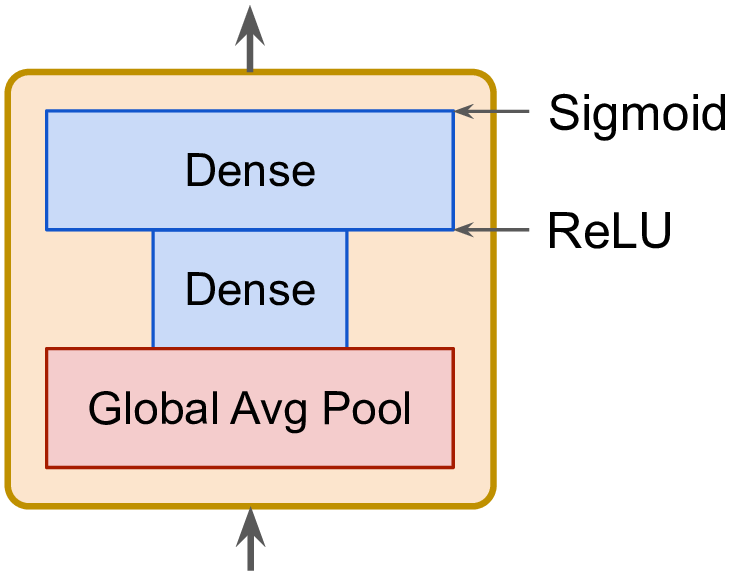
SE 块分析它所连接单元的输出,关注深度维度而不关注任何空间模式,并使用这些信息来重新校准特征图
SE 块可能知道嘴、鼻子和眼睛通常一起出现在照片中,因此如果看到嘴和鼻子,也应该看到眼睛。因此,如果 SE 块在嘴和鼻子特征图中看到强激活,但在眼睛特征图中只看到轻度激活,那么它将增强眼睛特征图
SE 块仅由 3 层组成:一个全局平均池层、一个使用 ReLU 激活函数的隐藏密集层和一个使用 sigmoid 激活函数的密集输出层
Keras 实现 ResNet-34 CNN
创建残差块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25DefaultConv2D = partial(keras.layers.Conv2D, kernel_size=3, strides=1,
padding="SAME", use_bias=False)
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation="relu", **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [
DefaultConv2D(filters, strides=strides),
keras.layers.BatchNormalization(),
self.activation,
DefaultConv2D(filters),
keras.layers.BatchNormalization()]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
DefaultConv2D(filters, kernel_size=1, strides=strides),
keras.layers.BatchNormalization()]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z + skip_Z)使用顺序模型构建 ResNet-34
1
2
3
4
5
6
7
8
9
10
11
12
13
14model = keras.models.Sequential()
model.add(DefaultConv2D(64, kernel_size=7, strides=2,
input_shape=[224, 224, 3]))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation("relu"))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding="SAME"))
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
strides = 1 if filters == prev_filters else 2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation="softmax"))将残差层添加到模型中的循环
使用 Keras 中预训练网络
获得预训练的网络:ResNet-50 模型,并下载在 ImageNet 数据集上的权重
1
model = keras.applications.resnet50.ResNet50(weights="imagenet")
需要确保之后的输入图像具有正确的大小:224*224,可通过
tf.image.resize()调整1
images_resized = tf.image.resize(images, [224, 224])
每个模型都提供一个
prepare_input()函数对图像进行预处理1
2inputs = keras.applications.resnet50.preprocess_input(images_resized * 255)
Y_proba = model.predict(inputs)显示前 K 个预测,包括类名和每个预测类的估计概率:
1
2
3
4
5
6top_K = keras.applications.resnet50.decode_predictions(Y_proba, top=3)
for image_index in range(len(images)):
print("Image #{}".format(image_index))
for class_id, name, y_proba in top_K[image_index]:
print(" {} - {:12s} {:.2f}%".format(class_id, name, y_proba * 100))
print()
迁移学习的预训练模型
重用一个预训练模型的较低层
准备自己的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import tensorflow_datasets as tfds
dataset, info = tfds.load("tf_flowers", as_supervised=True, with_info=True)
dataset_size = info.splits["train"].num_examples # 3670
class_names = info.features["label"].names # ["dandelion", "daisy", ...]
n_classes = info.features["label"].num_classes # 5
test_split, valid_split, train_split = tfds.Split.TRAIN.subsplit([10, 15, 75])
test_set = tfds.load("tf_flowers", split=test_split, as_supervised=True)
valid_set = tfds.load("tf_flowers", split=valid_split, as_supervised=True)
train_set = tfds.load("tf_flowers", split=train_split, as_supervised=True)
def preprocess(image, label):
resized_image = tf.image.resize(image, [224, 224])
final_image = keras.applications.xception.preprocess_input(resized_image)
return final_image, label
batch_size = 32
train_set = train_set.shuffle(1000).repeat()
train_set = train_set.map(preprocess).batch(batch_size).prefetch(1)
valid_set = valid_set.map(preprocess).batch(batch_size).prefetch(1)
test_set = test_set.map(preprocess).batch(batch_size).prefetch(1)加载预训练模型,添加自己的层,并训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17base_model = keras.applications.xception.Xception(weights="imagenet",
include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
output = keras.layers.Dense(n_classes, activation="softmax")(avg)
model = keras.models.Model(inputs=base_model.input, outputs=output)
for layer in base_model.layers:
layer.trainable = False
optimizer = keras.optimizers.SGD(lr=0.2, momentum=0.9, decay=0.01)
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(train_set,
steps_per_epoch=int(0.75 * dataset_size / batch_size),
validation_data=valid_set,
validation_steps=int(0.15 * dataset_size / batch_size),
epochs=5)微调
1
2
3
4
5for layer in base_model.layers:
layer.trainable = True
optimizer = keras.optimizers.SGD(lr=0.01, momentum=0.9, decay=0.001)
model.compile(...)
history = model.fit(...)
分类与定位
定位图片中的对象可以表示为回归任务,常见的方法是预测对象中心的水平和垂直坐标,以及它的高度和宽度
模型加载与编译
1
2
3
4
5
6
7
8
9
10base_model = keras.applications.xception.Xception(weights="imagenet",
include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
class_output = keras.layers.Dense(n_classes, activation="softmax")(avg)
loc_output = keras.layers.Dense(4)(avg)
model = keras.models.Model(inputs=base_model.input,
outputs=[class_output, loc_output])
model.compile(loss=["sparse_categorical_crossentropy", "mse"],
loss_weights=[0.8, 0.2], # depends on what you care most about
optimizer=optimizer, metrics=["accuracy"])对数据集的目标添加边界框,即获取标签,之后得到元组 (图像,(类标签,边界框))
指标不应该是 mse,此任务的最常见的指标是联合交集(IoU):预测边界框和目标边界框之间的重叠区域除以它们的联合区域

目标检测
Fully Convolutional Networks (FCNs)
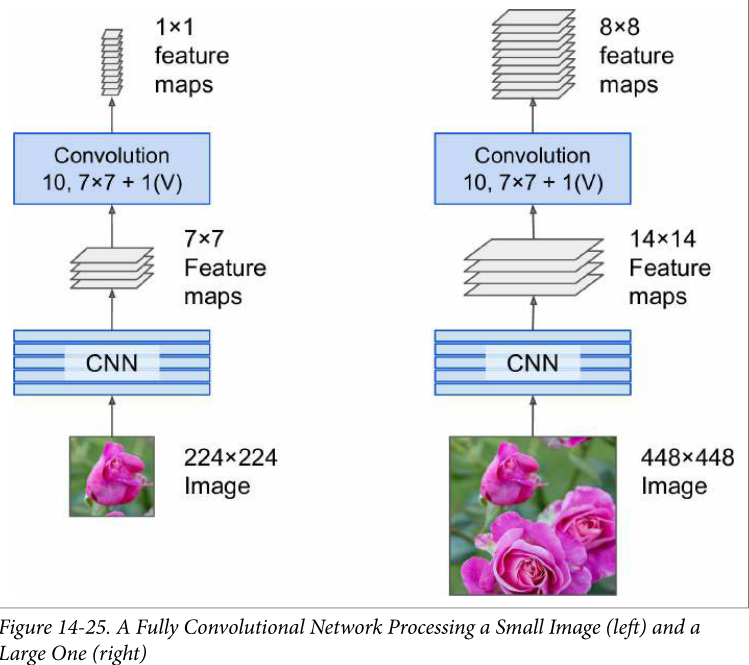
- 用于语义分割(根据对象所属的类别对图像中的每个像素进行分类的任务)
- 用卷积层代替 CNN 顶部的密集层
- 密集层需要特定的输入大小,而卷积层可以处理任何大小的图像,所以 FCN 只包含卷积层,可以在任何大小的图像上训练和执行
You Only Look Once (YOLO)
- github 上有几个使用 TF 构建的 YOLO 实现
- 略
语义分割
- 每个像素根据其所属对象的类别(例如,道路、汽车、行人、建筑物等)进行分类

将预训练的 CNN 变为 FCN
CNN 对整个输入图像应用总共 32 的步幅,最后一层输出比输入图像小 32 倍的特征图
FCN 增加了一个上采样层,将分辨率提高 32 倍——转置卷积层
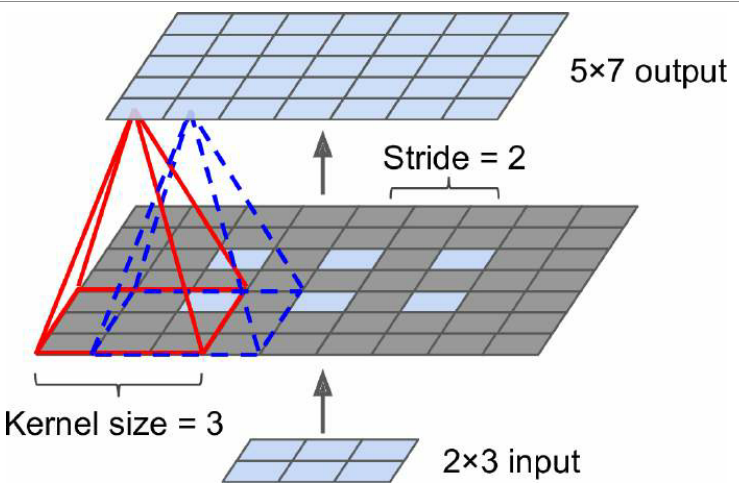
还增加了较低层的跳过连接,恢复了早期池化层中丢失的一些空间分辨率
许多 github 库提供了语义分割的 TF 实现

