《Hands-on Machine Learning》第二部分阅读笔记(5)字符级RNN、单词级RNN、基于RNN的编码-解码器
RNN 实现 NLP
Character RNN 生成莎士比亚风格的文本
创建训练数据集
get_file()下载文本1
2
3
4
5shakespeare_url = "https://homl.info/shakespeare" # shortcut URL
filepath = keras.utils.get_file("shakespeare.txt", shakespeare_url)
with open(filepath) as f:
shakespeare_text = f.read()每个字符编码为一个整数——将一个
Tokenizer拟合到文本:从文本中发现所有的字符,并将所有字符映射到不同的字符 ID1
2tokenizer = keras.preprocessing.text.Tokenizer(char_level=True)
tokenizer.fit_on_texts([shakespeare_text])char_level=True:得到字符级别的编码,默认为单词级别- 默认将所有文本转换成了小写,否则设置
lower=False - 分词器可以将一整句(或句子列表)编码为字符 ID 列表,可以知道文本中有多少个独立的字符以及总字符数
切分数据集
处理时间序列时,通常按照时间切分——默认 RNN 在训练集(过去)学到的规律也适用于将来
可以在验证集上画出模型随时间的误差:如果模型在验证集的前端表现优于后段,则时间序列可能不是静态
1
2train_size = dataset_size * 90 // 100
dataset = tf.data.Dataset.from_tensor_slices(encoded[:train_size])
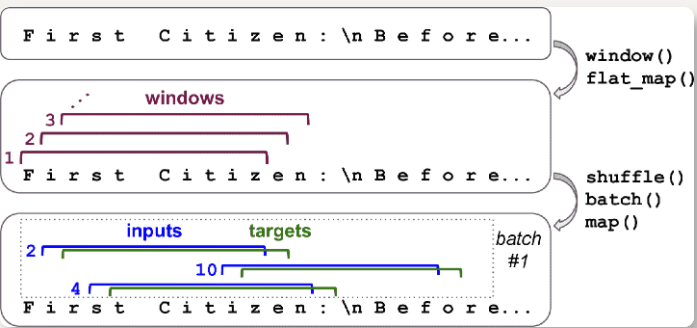
切分成多个窗口
使用数据集的
window(),将长序列转化为许多小窗口文本(此时训练集包含一个单独的长序列)1
2
3n_steps = 100
window_length = n_steps + 1 # target = input 向前移动 1 个字符
dataset = dataset.window(window_length, shift=1, drop_remainder=True)window()默认创建的窗口不重叠- 为了获得可能的最大训练集,设定
shift=1:第一个窗口包含字符 0 到 100,第二个窗口包含字符 1 到 101 drop_remainder=True:确保所有窗口是准确的 101 个字符长度,否则最后的 100 个窗口会分别包含 100 个字符、99 个字符,一直到 1 个字符
将嵌套的数据集展平(
{{1, 2}, {3, 4, 5, 6}}展平为{1, 2, 3, 4, 5, 6})1
dataset = dataset.flat_map(lambda window: window.batch(window_length))
flat_map()接收函数作为参数,处理嵌套数据集的每个数据集lambda ds: ds.batch(2)传递给flat_map(),能将{{1, 2}, {3, 4, 5, 6}}转变为{[1, 2], [3, 4], [5, 6]}
打散,分割输入和目标
1
2
3batch_size = 32
dataset = dataset.shuffle(10000).batch(batch_size)
dataset = dataset.map(lambda windows: (windows[:, :-1], windows[:, 1:]))
独热编码 + 预取
1
2
3dataset = dataset.map(
lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch))
dataset = dataset.prefetch(1)
搭建 Char-RNN 模型
1 | model = keras.models.Sequential([ |
使用模型生成文本
处理输入文本(映射为序列)
1
2
3def preprocess(texts):
X = np.array(tokenizer.texts_to_sequences(texts)) - 1
return tf.one_hot(X, max_id)预测下一个字母
1
2
3
4X_new = preprocess(["How are yo"])
Y_pred = model.predict_classes(X_new)
tokenizer.sequences_to_texts(Y_pred + 1)[0][-1] # 1st sentence, last char
'u'提高文本多样性
1
2
3
4
5
6def next_char(text, temperature=1):
X_new = preprocess([text])
y_proba = model.predict(X_new)[0, -1:, :]
rescaled_logits = tf.math.log(y_proba) / temperature
char_id = tf.random.categorical(rescaled_logits, num_samples=1) + 1
return tokenizer.sequences_to_texts(char_id.numpy())[0]- 温度接近 0,会利于高概率字符;高温度让所有字符概率相近
重复调用,生成文本
1
2
3
4def complete_text(text, n_chars=50, temperature=1):
for _ in range(n_chars):
text += next_char(text, temperature)
return text
有状态的 RNN
无状态 RNN:在每次迭代中,模型从全是 0 的隐藏状态开始训练;最后一个时间步,隐藏态被丢弃
有状态 RNN:让 RNN 保留这个状态,供下一个 batch 使用——反向传播只在短序列传播,但模型也可以学到长时规律
使用不打散、没有重叠的输入序列(训练无状态 RNN 时,使用打散和重叠的序列)
window()必须使用shift=n_steps不能使用
shuffle()方法调用
batch(32),连续的窗口会放到一个相同的批次中,后面的批次不会接着这些窗口,即每个批次中的第一个窗口(窗口 1 和 33)是不连续的——用batch(1)1
2
3
4
5
6
7
8
9dataset = tf.data.Dataset.from_tensor_slices(encoded[:train_size])
dataset = dataset.window(window_length, shift=n_steps, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_length))
dataset = dataset.batch(1)
dataset = dataset.map(lambda windows: (windows[:, :-1], windows[:, 1:]))
dataset = dataset.map(
lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch))
dataset = dataset.prefetch(1)实现 batch:可以切分成 32 段等长的文本,每个做成一个连续序列的数据集,最后使用
tf.train.Dataset.zip(datasets).map(lambda *windows: tf.stack(windows))来创建合适的连续 batch
创建模型
1
2
3
4
5
6
7
8
9model = keras.models.Sequential([
keras.layers.GRU(128, return_sequences=True, stateful=True,
dropout=0.2, recurrent_dropout=0.2,
batch_input_shape=[batch_size, None, max_id]),
keras.layers.GRU(128, return_sequences=True, stateful=True,
dropout=0.2, recurrent_dropout=0.2),
keras.layers.TimeDistributed(keras.layers.Dense(max_id,
activation="softmax"))
])每个循环层设置
stateful=True有状态 RNN 需要知道批次大小(要为批次中的输入序列保存状态),在第一层中设置
batch_input_shape,第二个维度为序列长度,不做限制每个 epoch 回到文本开头,要重设状态——设置回调
1
2
3
4
5
6class ResetStatesCallback(keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs):
self.model.reset_states()
model.compile(loss="sparse_categorical_crossentropy", optimizer="Adam")
model.fit(dataset, epochs=50, callbacks=[ResetStatesCallback()]) \
情感分析(词级别)
IMDb 数据集是 NLP 的“hello world”
1
2
3(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data()
X_train[0][:10]
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65]- 每个整数代表一个词
- 去掉标点符号,用空格隔开
- 单词转换为小写
- 用频次建立索引(小整数对应常见词)
- 0:填充标记;1:序列开始(SSS)标记;2:未知单词
解码看原文
1
2
3
4
5
6word_index = keras.datasets.imdb.get_word_index()
id_to_word = {id_ + 3: word for word, id_ in word_index.items()}
for id_, token in enumerate(("<pad>", "<sos>", "<unk>")):
id_to_word[id_] = token
...
" ".join([id_to_word[id_] for id_ in X_train[0][:10]])分词
- 前面的
Tokenizer——使用空格确定单词的边界、 - 2018 年的一篇论文中的无监督学习方法,在亚词层面分词和取消分词
- Rico Sennrich 的论文中提出,其它创建亚单词编码的方法
TF.Text库
- 前面的
预处理
加载原始文本
1
2
3
4import tensorflow_datasets as tfds
datasets, info = tfds.load("imdb_reviews", as_supervised=True, with_info=True)
train_size = info.splits["train"].num_examples预处理
1
2
3
4
5
6def preprocess(X_batch, y_batch):
X_batch = tf.strings.substr(X_batch, 0, 300)
X_batch = tf.strings.regex_replace(X_batch, b"<br\\s*/?>", b" ")
X_batch = tf.strings.regex_replace(X_batch, b"[^a-zA-Z']", b" ")
X_batch = tf.strings.split(X_batch)
return X_batch.to_tensor(default_value=b"<pad>"), y_batch- 裁剪影评,只保留前 300 个字符
- 正则表达式替换标签、非字母字符为空格
- 用空格分隔影评,得到嵌套张量
- 嵌套张量转变为紧密张量,给影评填充
"<pad>",使其长度相等
构建词典,统计单词出现次数,并裁剪词典只保留最常见的词
1
2
3
4
5
6
7
8
9from collections import Counter
vocabulary = Counter()
for X_batch, y_batch in datasets["train"].batch(32).map(preprocess):
for review in X_batch:
vocabulary.update(list(review.numpy()))
vocab_size = 10000
truncated_vocabulary = [
word for word, count in vocabulary.most_common()[:vocab_size]]将单词替换为其在词典中的索引,并创建未登录词(oov)桶
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15words = tf.constant(truncated_vocabulary)
word_ids = tf.range(len(truncated_vocabulary), dtype=tf.int64)
vocab_init = tf.lookup.KeyValueTensorInitializer(words, word_ids)
num_oov_buckets = 1000
table = tf.lookup.StaticVocabularyTable(vocab_init, num_oov_buckets)
# faaaaaantastic不在词表中,将其映射到一个oov桶,ID大于等于 10000
table.lookup(tf.constant([b"This movie was faaaaaantastic".split()]))
<tf.Tensor: [...], dtype=int64, numpy=array([[ 22, 12, 11, 10054]])>
def encode_words(X_batch, y_batch):
return table.lookup(X_batch), y_batch
train_set = datasets["train"].batch(32).map(preprocess)
train_set = train_set.map(encode_words).prefetch(1)
创建模型
1 | embed_size = 128 |
- 模型输入 2D 张量
[批次大小, 时间步],嵌入层的输出 3D 张量[批次大小, 时间步, 嵌入维度]。
mask
创建嵌入层时加上
mask_zero=True,则填充标记(其 ID 为 0)被接下来的所有层忽略,但不必要第二个
GRU层只返回最后一个时间步,mask 张量不会传递到全连接层所有接收 mask 的层必须支持 mask,即必须有等于
True的属性supports_masking实现自定义的支持遮挡的层,要给
call()添加mask参数如果第一个层不是嵌入层,使用
keras.layers.Masking层:它设置 mask 为K.any(K.not_equal(inputs, 0), axis=-1),表明最后一维都是 0 的时间步,会被后续层 mask对于
Sequential模型,将Conv1D层与循环层混合使用时不能用 mask 层,必须使用函数式 API 或子类化 API 显式计算 mask 张量1
2
3
4
5
6
7
8K = keras.backend
inputs = keras.layers.Input(shape=[None])
mask = keras.layers.Lambda(lambda inputs: K.not_equal(inputs, 0))(inputs)
z = keras.layers.Embedding(vocab_size + num_oov_buckets, embed_size)(inputs)
z = keras.layers.GRU(128, return_sequences=True)(z, mask=mask)
z = keras.layers.GRU(128)(z, mask=mask)
outputs = keras.layers.Dense(1, activation="sigmoid")(z)
model = keras.Model(inputs=[inputs], outputs=[outputs])
复用 Embedding
TensorFlow Hub 上可以找到复用的预训练模型组件(模块),包含预训练权重的模块可以自动下载(TF Hub 仓库)
1
2
3
4
5
6
7
8
9
10
11import tensorflow_hub as hub
model = keras.Sequential([
hub.KerasLayer("https://tfhub.dev/google/tf2-preview/nnlm-en-dim50/1",
dtype=tf.string, input_shape=[], output_shape=[50]),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="Adam",
metrics=["accuracy"])
# hub.KerasLayer默认是不可训练的,需要创建时设定trainable=True不是所有的 TF Hub 模块都支持 TensorFlow 2
下载文件默认缓存到系统临时目录,可以设置环境变量
TFHUB_CACHE_DIR,存储到固定目录1
os.environ["TFHUB_CACHE_DIR"] = "./my_tfhub_cache"
编码-解码器实现翻译(NMT)
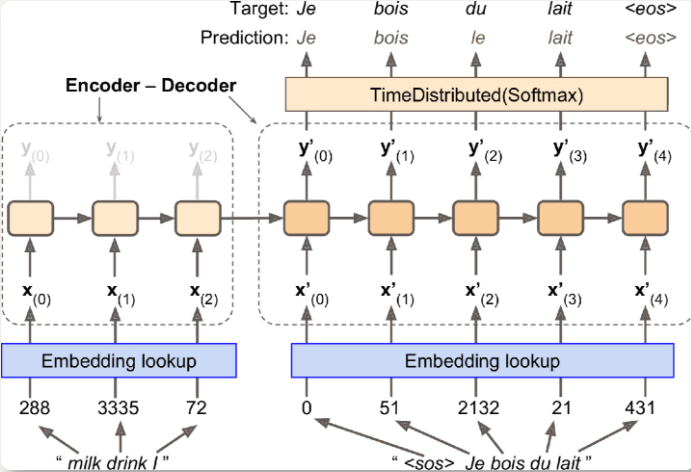
英语输入进编码器,解码器输出法语
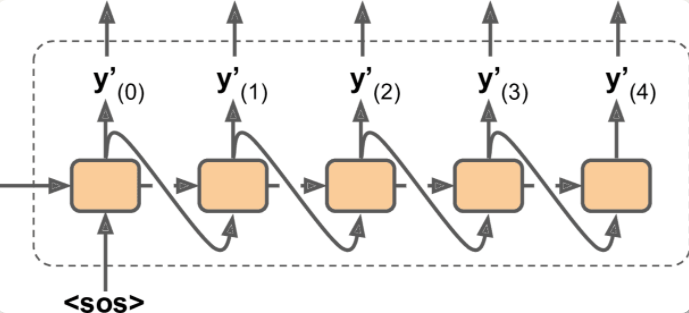
解码器将前一步的输出再作为输入
英语句子在输入给编码器之前,先做翻转,保证第一个词最后输入给编码器,也是解码器要翻译的第一个词
单词首先用 ID 表示,嵌入层返回单词嵌入
解码器输出词典中每个单词的分数,softmax 层将分数变为概率,概率最高的词作为输出
在预测时,将前一步的输出作为输入
其他问题
- 假定所有(编码器和解码器的)输入序列的长度固定——用 mask 处理,或者将句子放进长度相近的桶里,即一个桶放 1 个词到 6 个词的句子,另一个桶放 7 个词到 12 个词的句子——
tf.data.experimental.bucket_by_sequence_length() - 忽略所有在 EOS 标记后面的输出,这些输出不能影响损失
- 只查看模型对正确词和非正确词采样的对数概率输出,然后根据这些对数概率计算一个大概的损失,即训练时使用
tf.nn.sampled_softmax_loss(),预测时使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import tensorflow_addons as tfa
encoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
decoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
sequence_lengths = keras.layers.Input(shape=[], dtype=np.int32)
embeddings = keras.layers.Embedding(vocab_size, embed_size)
encoder_embeddings = embeddings(encoder_inputs)
decoder_embeddings = embeddings(decoder_inputs)
encoder = keras.layers.LSTM(512, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_embeddings)
encoder_state = [state_h, state_c]
sampler = tfa.seq2seq.sampler.TrainingSampler()
decoder_cell = keras.layers.LSTMCell(512)
output_layer = keras.layers.Dense(vocab_size)
decoder = tfa.seq2seq.basic_decoder.BasicDecoder(decoder_cell, sampler,
output_layer=output_layer)
final_outputs, final_state, final_sequence_lengths = decoder(
decoder_embeddings, initial_state=encoder_state,
sequence_length=sequence_lengths)
Y_proba = tf.nn.softmax(final_outputs.rnn_output)
model = keras.Model(inputs=[encoder_inputs, decoder_inputs, sequence_lengths],
outputs=[Y_proba])- TensorFlow Addons 涵盖了许多序列到序列的工具
- 创建
LSTM层时,设置return_state=True,以得到最终隐藏态,并传给解码器 TrainingSampler:在每一步告诉解码器,前一步的输出是什么
- 假定所有(编码器和解码器的)输入序列的长度固定——用 mask 处理,或者将句子放进长度相近的桶里,即一个桶放 1 个词到 6 个词的句子,另一个桶放 7 个词到 12 个词的句子——
双向 RNN
循环层是遵循因果关系的,不能查看未来
可以对于相同的输入运行两个循环层,一个从左往右读,一个从右往左读,将每个时间步的输出结合(通常是连起来)
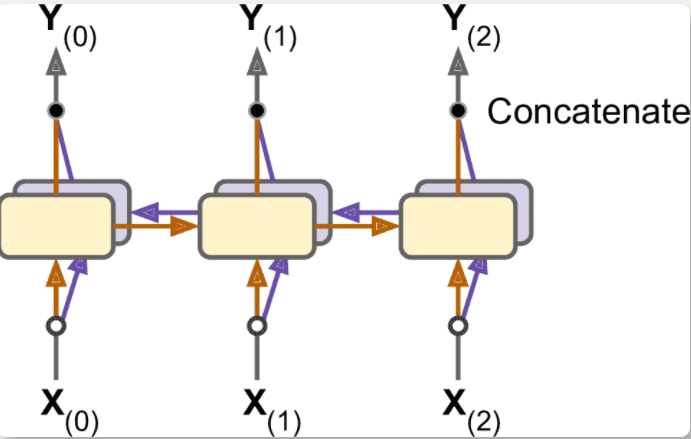
1
keras.layers.Bidirectional(keras.layers.GRU(10, return_sequences=True))
集束搜索
如果每步都是最大贪心地输出结果,只能得到次优解——要让模型返回到之前的错误并改错
跟踪
k个最大概率的句子列表,在每个解码器步骤延长一个词,然后再关注其中k个最大概率的句子;参数k被称为集束宽度举例:使用宽度为 3 的集束搜索,用模型来翻译句子
Comment vas-tu?- 输出每个可能词的估计概率,取前三个:
How(估计概率是 75%)、What(3%)、You(1%) - 创建三个模型的复制,预测每个句子的下一个词
- 计算 30000 (假设词典有 10000 个词)个含有两个词的句子的概率,连乘条件概率,只保留概率最大的 3 个
How will(27%)、How are(24%)、How do(12%) - 用三个模型预测这三个句子的接下来的词,再计算 30000 个含有三个词的句子的概率,只保留概率最大的 3 个
1
2
3
4
5
6
7
8beam_width = 10
decoder = tfa.seq2seq.beam_search_decoder.BeamSearchDecoder(
cell=decoder_cell, beam_width=beam_width, output_layer=output_layer)
decoder_initial_state = tfa.seq2seq.beam_search_decoder.tile_batch(
encoder_state, multiplier=beam_width)
outputs, _, _ = decoder(
embedding_decoder, start_tokens=start_tokens, end_token=end_token,
initial_state=decoder_initial_state)- 输出每个可能词的估计概率,取前三个:
创建
BeamSearchDecoder,包装所有解码器的克隆;给每个解码器克隆创建一个编码器的最终状态的复制

