transformer 模型原理介绍
基本框架
transformer 总体为一个编码组件、解码组件以及二者之间连接。
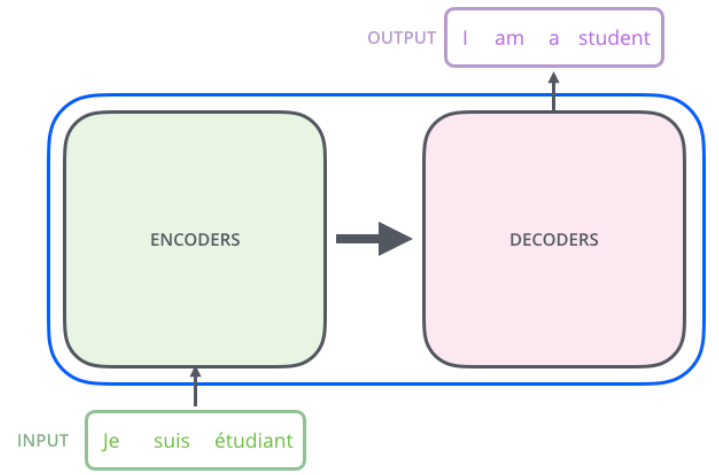
编码部分和解码部分都为编码器、解码器的堆叠,最后一层编码器的输出是各个解码器的输入之一。第一个编码器的输入为单词的嵌入向量,后面编码器输入为前一层的输出。
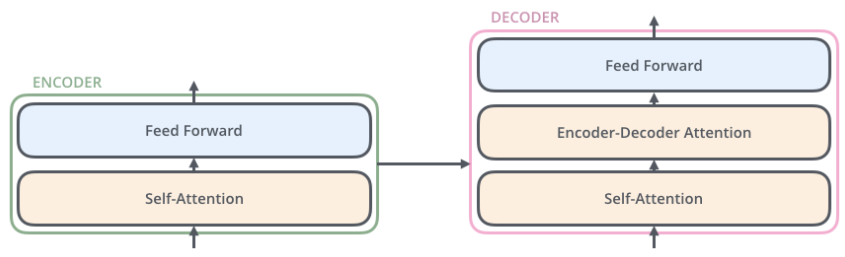
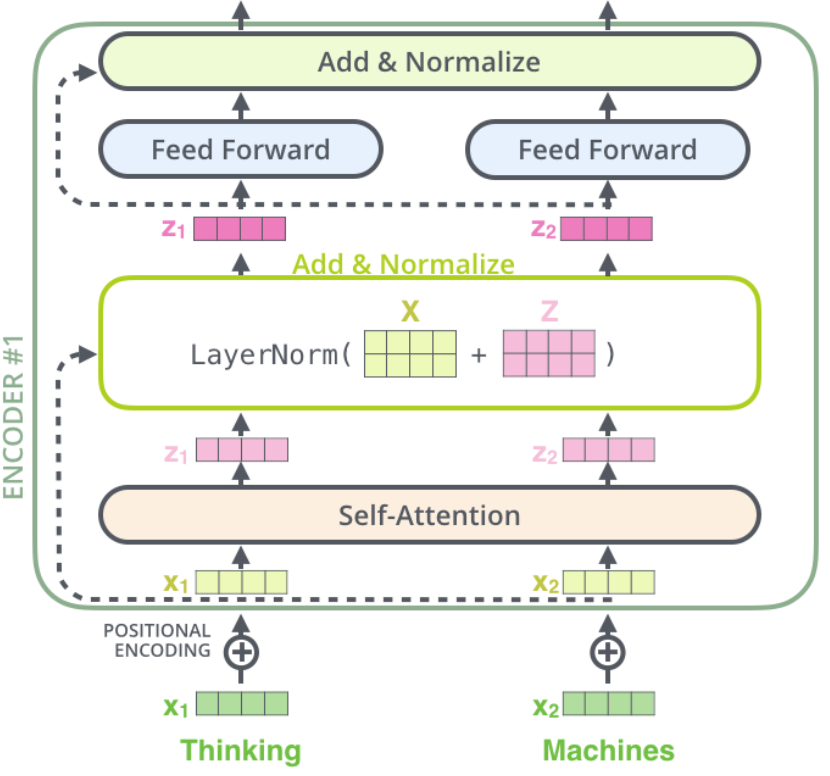
编码器均由两个子层组成:self-attention与feed forward neural network。self-attention用于帮助编码器在编码特定单词时查看输入中的其他单词。解码器也有这两个子层,中间有一个注意力层,帮助解码器查看输入句子的相关部分。
编码
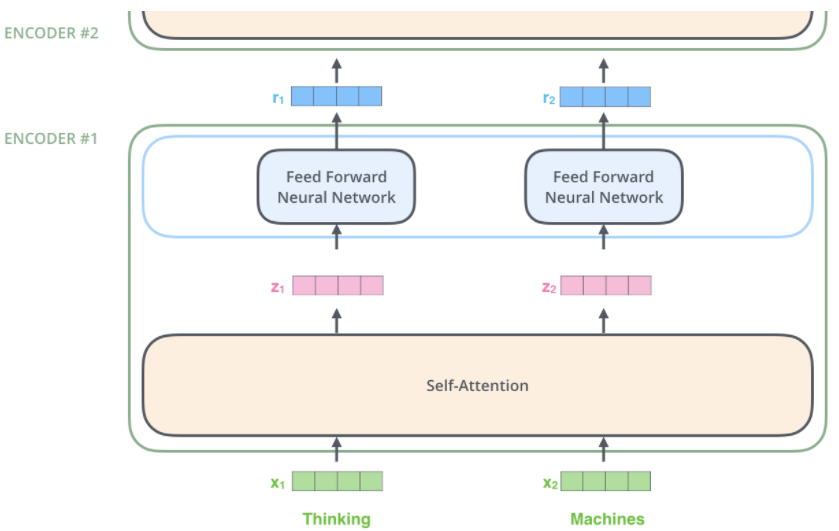
输入句子的各个单词先编码为词向量。
各个词向量均进入编码器的两个子层,self-attention层中各个词向量的路径具有一定关联,而feed forward neural network层中各个词向量参与的计算过程独立。
self-attention使得模型在处理一个词向量时,能够将其与相关的词关联起来,以更好地对该词向量编码。RNN 通过维护隐藏状态以将先前处理的词向量同当前词向量合并,transformer 则使用self-attention将对相关词的“理解”融入当前处理的词。
self-attention 步骤
第一步,为每个词向量创建三个向量:Query、Key、Value。这三个向量是通过将每个词向量乘以三个待训练的矩阵创建的(对后面的编码器,则是将上一个编码器的输出乘以三个新的待训练矩阵)。
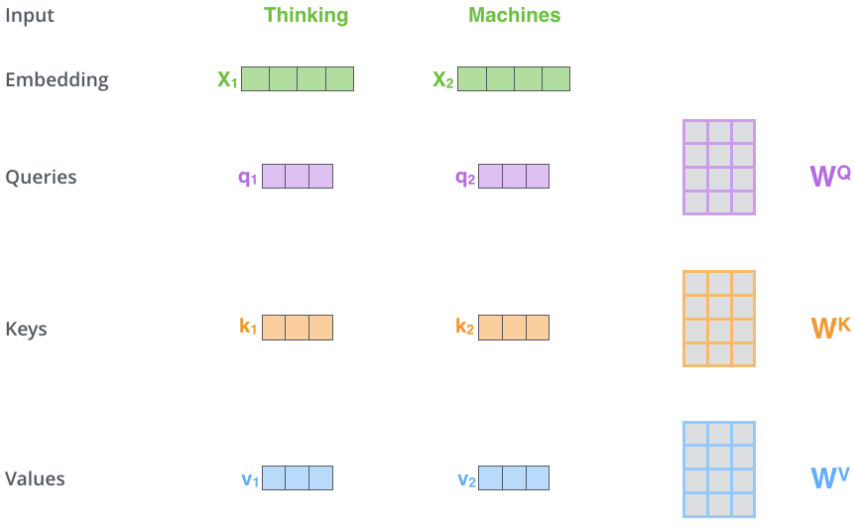
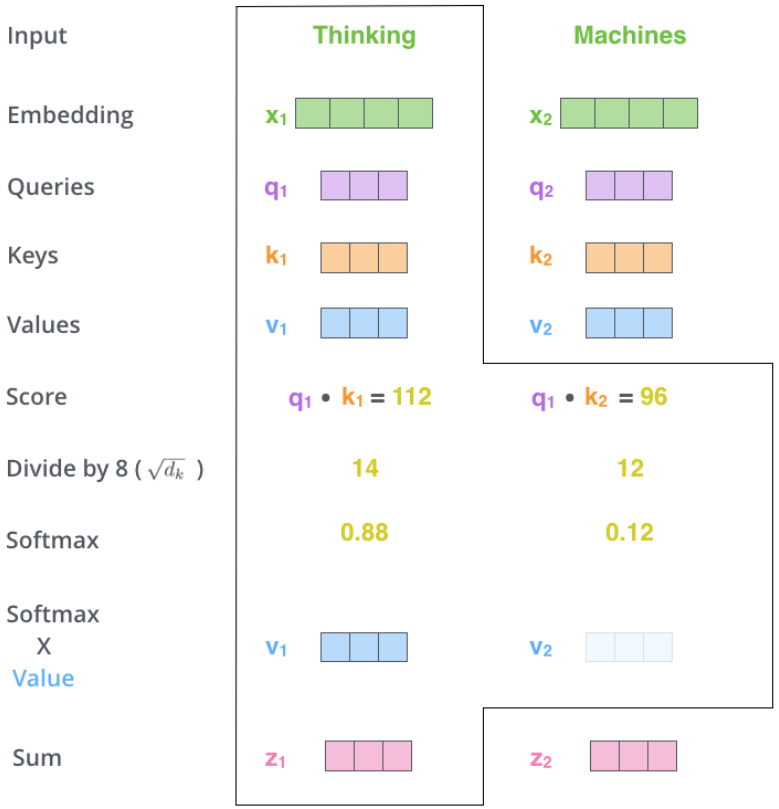
第二步,计算当前词向量与输入句子所有词向量的分数,分数会决定将多少注意力放在这些词上。分数通过将当前词向量对应的Query向量与各个单词的Key向量点积得到,第一个分数是q1与k1点积,第二个分数为q1与k2点积,以此类推。
第三步,将分数除以Query向量长度的平方根。此步骤提高了梯度的稳定性。
第四步,通过softmax将分数归一化。
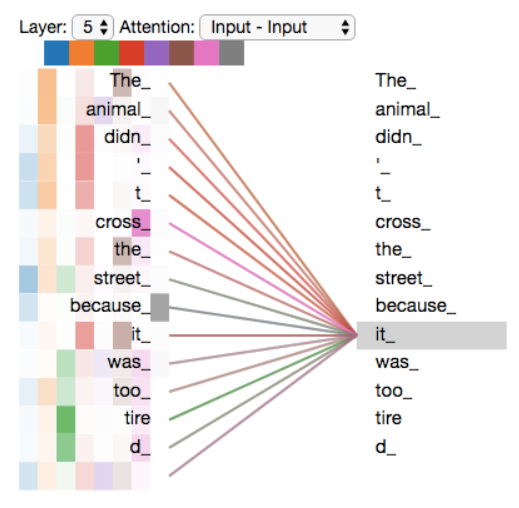
This softmax score determines how much each word will be expressed at this position. Clearly the word at this position will have the highest softmax score, but sometimes it’s useful to attend to another word that is relevant to the current word.
第五步,归一化的得分与各个单词的Value向量相乘,此做法的直觉是保持想要关注的单词的值不变,而且消除不相关的单词,即对各个单词的Value向量加权。
第六步,对所有加权后的Value向量求和,即为当前词向量在self-attention下的输出。
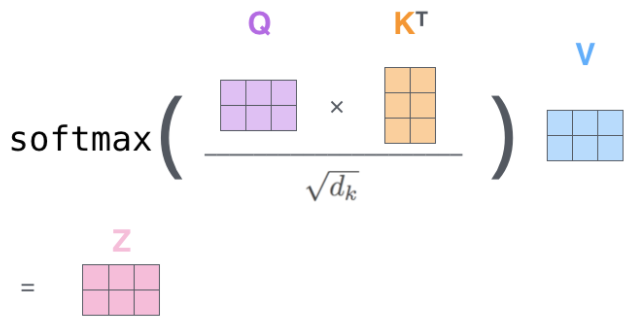
上述过程的矩阵形式为:
多头注意力
进一步优化self-attention:使用multi-headed attention。提高了模型关注不同位置的能力,为注意力层提供了多个表示子空间(representation subspaces)——可以有多组Query、Key、Value权重矩阵,每一组都是随机初始化,因此训练完成后每一组都可以将输入投射到不同的子空间,具体可以类比 CNN 中的多个卷积核。
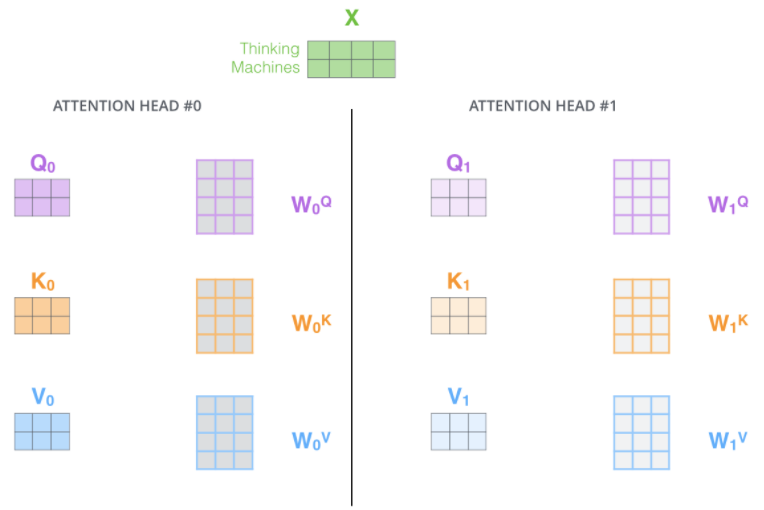
最终将获得多个当前词向量在self-attention下的输出向量,即输入句子经过self-attention后,将有多个输出矩阵。
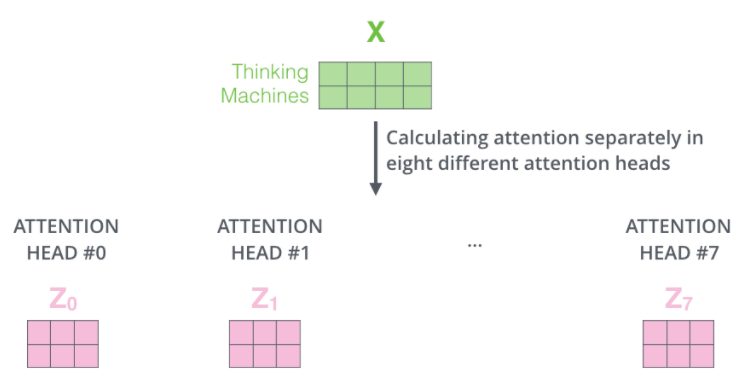
由于feed forward neural network子层需要一个矩阵(每个单词由一个向量表示)作为输入,因此需要将以上输出矩阵与一个额外的待训练权重矩阵相乘。
以上过程表示如下:
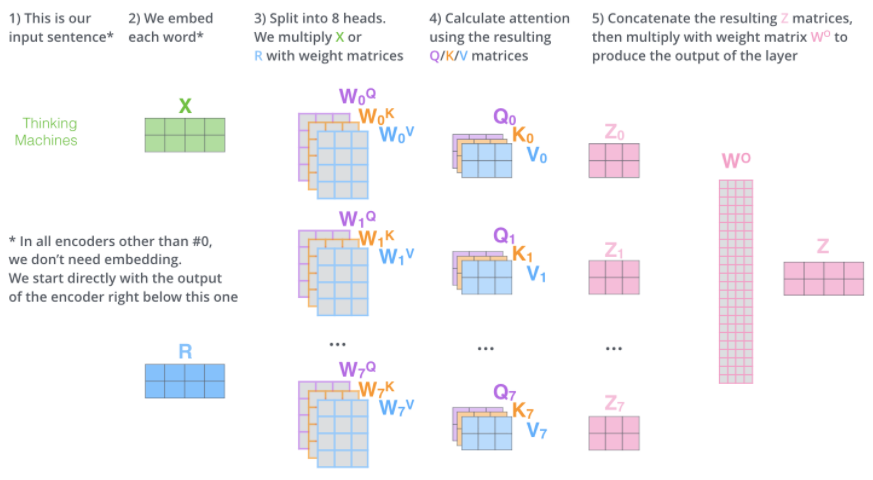
一个多头注意力的例子:
位置编码
以上过程,缺少了对输入序列中单词顺序的表达。为此,transformer 将每个词向量与一个位置向量相加。这些位置向量遵循一个特定的模式,将有助于模型获得每个单词的绝对位置和相对位置(序列中不同单词的距离)。
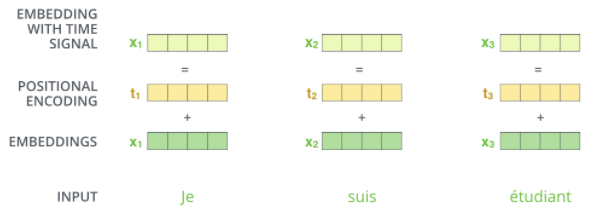
位置编码的公式论文已经给出,它不是唯一一种进行位置编码的方法,但其优势在于能扩展到更长的序列(即训练后的模型需要接收一个比训练集任何句子都长的测试句)
残差运算
此外,编码器中每个子层都进行残差连接,并归一化。
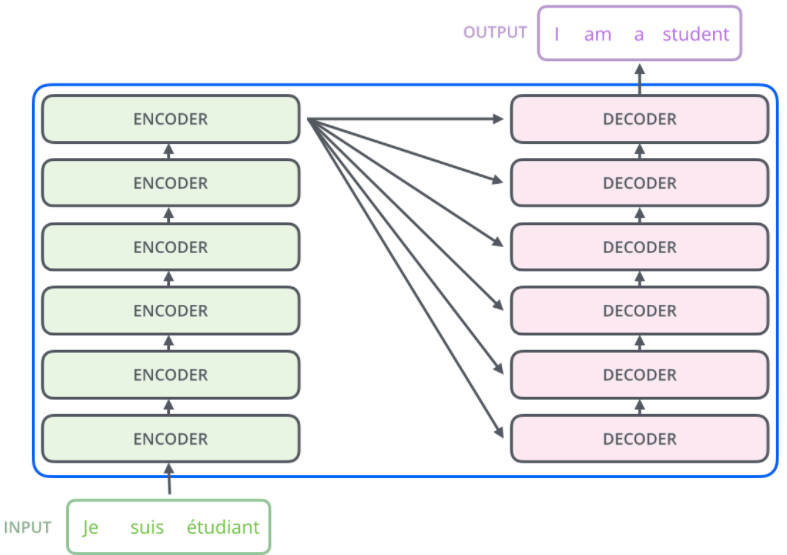
综上,一个堆叠了两层编码器、解码器的 transformer 结构如下:
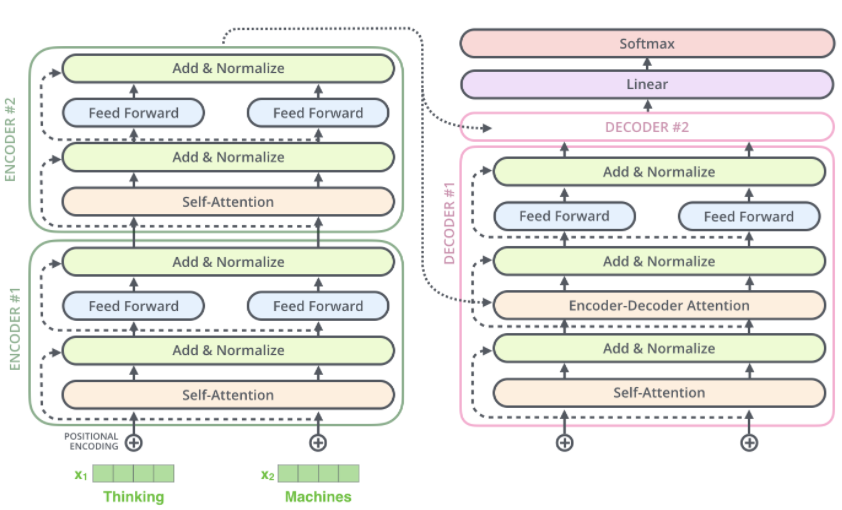
解码
编码组件首先接收一个句子,在最后的编码器上输出一组注意力向量Key与Value,每个解码器在encoder-decoder attention子层中使用,使解码器关注到输入句子的所有位置。encoder-decoder attention子层需要的Query向量来自上一层的输出。
编码完成后开始解码,每一步都输出一个元素,直到输出一个特殊符号表明解码结束。每一次输出的结果都将在下一次输出前,反馈到第一个解码器。
解码器的输入同样需要进行词嵌入和位置编码。
解码器的self-attention子层只允许关注序列中出现较早的位置,这通过在softmax前进行掩码实现。
以上就是使用一个训练好的 transformer 实现任务时的前向传递过程。
训练过程
在训练期间,初始模型的前向传递过程同上,解码组件的输入为序列下一个单词的前面内容。
例如,翻译“我/爱/机器/学习”为 “i/ love /machine/ learning”时,首先将<start>作为解码组件的初始输入,将解码组件的最大概率输出词 A1 和”i“做损失计算。将<start>,”i” 作为解码组件的输入,将解码组件的最大概率输出词 A2 和”love“做损失计算,以此类推,直至最后一次计算最大概率输出词 A5 和<end>的损失,所以从整体上来说,transformer 训练过程类似于一个有监督的多分类问题。
以上过程为串行进行,实际可以将多次的输入补全组成矩阵,乘以一个 mask 矩阵,得到最终的输入矩阵。将这个矩阵输入解码组件,每行输入得到一个输出概率分布,因此得到一个 seq_len * vocab_size 的输出概率矩阵,用于并行计算损失。
综上,transformer 的编码器组件可以并行计算,一次性将输入序列全部编码出来,但解码器组件不是一次性把所有单词预测出来的,虽然训练时可通过 mask 并行进行,测试时必须串行进行,一个单词一个单词输出。
总结
self-attention是一种自身和自身相关联的 attention 机制,因此能够得到一个更好的 representation 来表达自身,在多数情况下,自然会对下游任务有一定的促进作用。如果是 RNN 或者 LSTM,需要依次序计算,对于远距离、相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来。但是self-attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。
相比于 RNN,transformer 的并行计算能力更强,其并行化体现在self-attention模块,在编码组件可以并行处理整个序列,得到整个输入序列经过编码的结果,在self-attention模块,对于某个序列$x_1,x_2,…,x_n$,self-attention可以直接计算$x_i,x_j$的点乘结果,而 RNN 系列的模型必须按照顺序从$x_1$计算到$x_n$。
相比于 seq2seq,transformer 使用多头交互式attention,避免了将源句子的所有信息压缩到一个固定长度的向量中来预测解码组件第一个单词的隐藏状态,让编码器能关注到想要关注的信息,同时让源序列和目标序列先自己关联起来,使其表示的信息更加丰富。
此外,transformer 的特征抽取能力更强(实验结果,非严格的理论证明)——自然语言处理三大特征抽取器(CNN/RNN/TF)比较。但是 transformer 效果显著及其强大的特征抽取能力是否完全归功于其self-attention模块,还是存在一定争议的:How Much Attention Do You Need?A Granular Analysis of Neural Machine Translation Architectures。

