2018年《Improving Language Understanding by Generative Pre-Training》阅读笔记(GPT)
摘要
- 语料丰富但具有标签的文本数据稀少,使得针对性训练的模型泛用性不足
- 本文证明,通过在不同的未标记文本语料库对模型进行生成性预训练后,对每个特定任务上微调,将提高各类任务的效果
- 与过去的方法相比,微调期间只需要稍微更改模型架构,利用任务感知输入转换
task-aware input transformations - 在多个任务上,本文的通用模型(不需指定任务)优于专门为各任务设计的模型
介绍
- 大多数深度学习方法需要大量手动标记的数据,这限制了它们在许多缺乏注释资源的领域的适用性
- 即使在相当多的监督可用的情况下,以无监督的方式学习良好的表示可以提供显著的性能提升
- 学习利于迁移的文本表示时,哪种类型的优化目标是最有效的,目前还不清楚
- 对于将这些习得的表征转化到目标任务的最有效方法,目前还没有共识——现有技术包括:使用复杂的学习方案、对模型结构进行特定更改、添加辅助的学习目标等
- 本文探索了一种结合无监督预训练、监督微调的语言理解任务方法——这是一种半监督方法
- 学习一种普适性的表征,此表征可以不需要适应广泛的任务
- 采用两阶段的训练:
- 假设可以访问大量未标记文本的语料库,和几个带有手动注释的数据集(目标任务),不要求目标任务与未标记的语料库处于同一个域中
- 在未标记数据上学习神经网络模型的初始参数
- 使用相应的监督目标,调整这些参数以适应目标任务
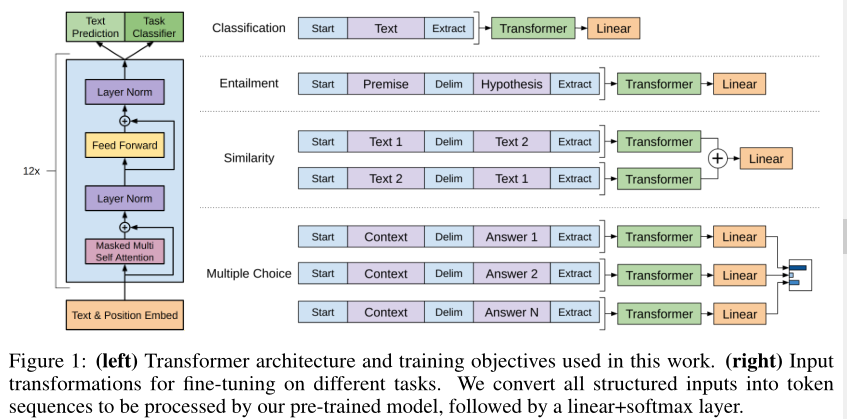
- 模型结构使用Transformer,因为Transformer能提供更为结构化的记忆,以处理文本中的长期依赖关系,在不同任务之间能更鲁棒地迁移
- 将结构化的输入文本,处理为单个连续的令牌序列
- 在自然语言推理、问答、语义相似性、文本分类上评估本文方法
相关工作
NLP的半监督学习
- 可以用于序列标注和文本分类任务
- 最早方法中使用未标注数据计算单词级别、短语级别的统计数据,作为监督模型的特征
- 单词嵌入:在未标记的语料库训练
- 其他嵌入:使用未标记语料库训练短语级、句子级嵌入,以将文本编码成向量
无监督预训练
- 目标是找到好的初始化参数
- 应用:图像分类、语音识别、实体消歧、机器翻译
- 接近本文的方法:
- 对网络进行预训练然后微调,但使用了 LSTM 网络,预测范围较小
- 使用来自预训练模型的隐藏表示作为辅助特征,同时在目标任务上训练监督模型,这需要添加大量新的参数
辅助训练目标
- 添加辅助的无监督训练目标,以替代半监督学习
- 本实验也使用了一个辅助目标
框架
无监督预训练
给定一个无监督的语料库$U={u_1,…,u_n}$,使用一个标准的语言建模目标来最大化似然函数:
$$
L_1(U)=\sum_{i}logP(u_i|u_{i-k},…,u_{i-1};\theta)
$$使用一个多层的 Transformer decoder(Transformer 的变体),模型对输入的上下文 tokens 使用
multi-headed self-attention,并经过position-wise feedforward layer,以产生一个目标token的输出分布,下式中$W_e$为 token embedding 矩阵,$W_p$为 position embedding 矩阵
$$
h_0=UW_e+W_p
$$$$
h_l=transformer_block(h_{l-1})
$$$$
P(u) = softmax(h_nW_e^T)
$$
有监督微调
无监督训练后,将参数调整到目标任务上
假设一个有标记的数据集$C$,每条数据由序列$x_1,…,x_m$和标记$y$组成,数据输入预训练模型,获得最终的激活结果$h_l^m$,输入到一个参数为$W_y$的线性输出层以预测$y$,即
$$
P(t=y|x_1,…,x_m)=softmax(h_l^mW_y)
$$
最大化似然函数:
$$
L_2(C)=\sum_{(x,y)}logP(y|x^1,…,x^m)
$$将预训练的似然函数作为微调的辅助目标,将有助于改进监督模型的泛化能力并加速收敛,因此最终似然函数为:
$$
L_3(C)=L_2(C)+\lambda*L_1(C)
$$
基于目标任务的输入转换
对于一些任务(如文本分类)可以直接按上述过程微调模型
某些任务(如问答和文本蕴含)有结构化的输入——有序的句子对,文档、问题和答案的三元组——预训练模型针对连续的文本序列进行训练,因此需要对结构化输入进行一些修改
本文使用遍历风格的方法
traversal-style approach,将结构化输入转换为预先训练好的模型可以处理的有序序列,以避免为了目标任务对架构进行广泛的更改,例如:- 文本蕴含:将前提 p 和假设 h 的 token 序列连接,中间有一个分隔符标记(<Delim>)
- 文本相似度:相似性任务中,被比较的两个句子没有内在的顺序,因此修改输入序列,使其包含两种可能的句子顺序(中间有分隔符),并分别独立处理每一种顺序,以产生两个序列表示,最后在输入线性层之前将其向量按元素相加
- 问答与常识推理:此类任务的输入是三元组(上下文文档、问题、回答),将三者连接,如果有n个回答就将产生n个序列,在问题与回答之间插入分隔符。每个序列都独立处理,最后由softmax归一化,产生可能答案的输出分布
- 所有的转换包括添加随机初始化的开始和结束标记 <start> <extract>
下图为具体说明,图左为 Transformer 的结构,图右为不同任务下输入的调整,所有结构化输入都将转换为 token 序列
实验
环境
- 无监督预训练
- 使用 BooksCorpus 数据集训练
- 备用数据集为 1B Word Benchmark,此数据集被 ELMo 使用,但在句子级别上打乱,破坏了长范围的结构
- 模型
- 12层仅有 decoder 的 Transformer
- 带掩码的自注意力头,768个隐藏单元,12个自注意力头
- 前馈网络为3072维
- Adam优化器,最大学习率为2.5e-4,最初2000次迭代,学习率从0线性增加,使用余弦 schedule 退火到0
- 100个 epoches,batchsize 为64
- 初始化权重服从$N(0, 0.02)$
- dropout 为0.1,使用 L2 正则化的改进版本,激活函数使用 GELU
- 使用 position embedding 代替原来用正弦函数表示位置
- 使用 spaCy tokenizer,使用 ftfy 清理 BooksCorpus 中的文本
- 微调细节
- 除非指定,重复使用无监督模型中的超参数
- 分类器的 dropout 为 0.1
- 大多数模型,batchsize 为32,学习率为 6.25e-5
- 训练3个 epoches
- 线性学习率下降计划
linear learning rate decay schedule(当训练内容超过0.2%),其中$\lambda$为0.5
有监督微调
自然语言推理(NLI)
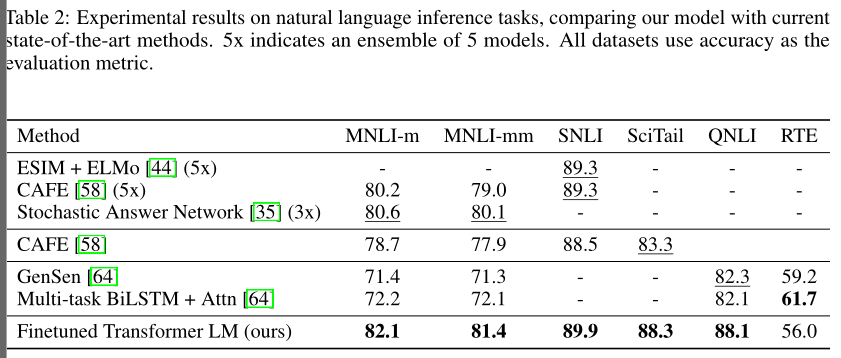
也称文本蕴含,任务是阅读一对句子,判断它们之间的关系(蕴含、矛盾和中立)
评估了五个不同来源的数据集,包括图片说明(SNLI)、演讲、小说、政府报告(MNLI)、维基百科(QNLI)、考试(SciTail)、新闻文章(RTE)
下表说明本文模型和过去最佳模型,在不同 NLI 任务上的结果,本文方法在4个数据集上显著优于基准方法
问答与常识推理
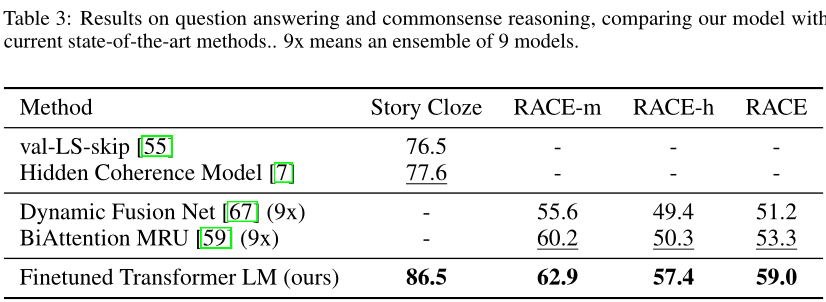
使用 RACE 数据集,数据集包含了初中和高中英语考试的短文和问题,与 CNN 和 SQuaD 数据集相比,此数据集包含更多的推理类型问题
还利用故事的完型测试
Story CLoze Test评估模型,即从两个选项中选择故事的正确结尾模型优于过去的最佳结果,表明模型能够有效处理长范围的上下文
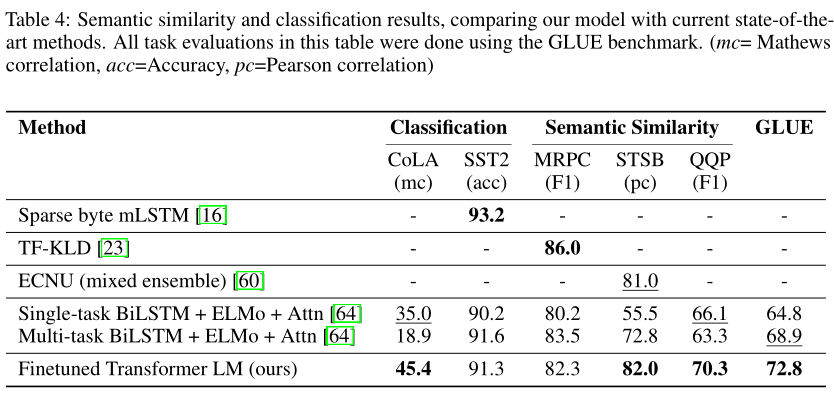
语义相似性
- 预测两个句子在语义上是否等价,其困难在于理解否定、处理句法起义、概念的重新措辞
- 三个数据集:微软释义语料库(MRPC),Quora 问题对(QQP),STS-B
- 模型在其中两个数据集获得最佳效果,在 QQP 上的性能比 BiLSTM+ELMo+Attn 提高 4.2%
分类
- CoLA 数据集和 SST-2 数据集,前者包含专家对句子是否符合语法的判断,后者为标准的二元分类任务
- 在 CoLA 上获得显著提高,SST-2 与过去最好的模型相当,在 GLUE 基准测试上也取得了最佳
结论
- 引入了一个框架,通过生成性的预训练和辨别性的微调,通过单一的任务不可知模型实现强大的自然语言理解。
- 模型具有处理长期依赖的能力,并成功地转移到解决歧视性任务,如问题回答、语义相似度评估、隐含判断、文本分类
- 使用无监督(预)训练提高识别任务的效果一直是机器学习研究的一个重要目标,本文工作提供了关于使用这种方法的模型(transformer)和数据集(具有长期依赖关系的文本)

