2019年《XLNet: Generalized Autoregressive Pretraining for Language Understanding》论文阅读笔记——基于2019年《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》
摘要
- BERT这种基于去噪自动编码的预处理方法具有双向上下文建模的能力,比基于自回归语言建模的预处理方法具有更好的性能
- 但BERT的掩码破坏了输入,忽略掩码位置之间的依赖性,并且存在预训练和微调的差异
- 本文提出了XLNet,一种广义自回归预处理方法,该方法通过最大化因子分解顺序所有排列的期望似然来学习双向上下文,并且通过自回归性,克服了BERT的缺点
- XLNet将最佳的自回归模型Transformer-XL整合到预处理中
- XLNet在20项任务上显著优于BERT,包括问答、自然语言推理、情感分析和文档排名
介绍
- 无监督表示学习通常先在大规模未标记文本语料库上预训练,然后在下游任务微调模型
- 自回归语言模型和自动编码是两个最成功的预训练目标
- AR语言模型寻求用自回归模型估计文本语料库的概率分布
- 给定一个文本序列$x=(x_1,…,x_t)$,AR语言模型将似然分解为一个前向乘积$p(x) =\prod_{t=1}^T=p(x_t|x_{<t})$或后向乘积$p(x) =\prod_{t=T}^1=p(x_t|x_{>t})$
- 训练模型以模拟每个条件分布
- 自回归语言模型只被训练为编码单向上下文(向前或向后),在建模深度双向上下文时效果不好,而下游语言理解任务往往需要双向语境信息
- 基于自编码的预训练不进行显式的密度估计,旨在从损坏的输入中重建原始数据——如BERT
- 给定输入token序列,部分token被特殊符号[MASK]替换
- 模型被训练从损坏的输入中恢复原始token
- 消除了上一个方法的双向信息差距,提高了性能,但在微调时,预训练期间使用的[MASK]等人工符号不在真实数据中,真实数据存在差异导致预微调差异。此外,BERT不能像AR语言模型那样使用乘积建模联合概率——BERT假设给定未屏蔽的标记,预测的标记相互独立,忽略了自然语言中普遍存在的高阶、长距离依赖
- AR语言模型寻求用自回归模型估计文本语料库的概率分布
- 本文提出了一种广义自回归方法XLNet,该方法充分利用了AR语言模型和AE的优点,同时避免了它们的局限性
- XLNet不像传统的AR语言模型那样使用固定的前向或后向分解顺序,而是最大化分解顺序所有可能排列的序列的预期对数似然性
- 每个位置的上下文可以由左侧和右侧的token组成
- 每个位置学习利用来自所有位置的上下文信息,即捕获双向上下文
- XLNet不依赖于缺损数据恢复,因此不存在BERT所面临的pre-fine tune差异
- XLNet还改进了预训练的架构设计,Transformer-XL [9]的段递归机制和相对编码方案集成到预训练中,在长文本序列任务上提高了性能
- 将Transformer(-XL)架构直接应用于基于置换的语言建模是行不通的,因为分解顺序是任意的,目标也是模糊的。本文建议对Transformer(-XL)网络重新参数化,以消除模糊性
- XLNet在很多任务上始终优于BERT,包括GLUE语言理解任务、SQuAD和RACE这样的阅读理解任务、Yelp和IMDB这样的文本分类任务以及ClueWeb09-B文档排名任务
方法
背景
AR语言模型需要在前向自回归因式分解下,最大化似然函数
$$
max_{\theta}logp_\theta(x)=\sum_{t=1}^Tlogp_\theta(x_t|\pmb{x}{<t})=\sum{t=1}^Tlog\frac{exp(h_\theta(\pmb{x}_{1:t-1})^Te(x_t))}{\sum_{x’}exp(h_\theta(\pmb{x}_{1:t-1})^Te(x’))}
$$- $h_\theta(\pmb{x}_{1:t-1})$为神经模型生成的上下文表示
- $e(x)$为x的嵌入
BERT为去噪自动编码,对于文本序列$\pmb{x}$,BERT将一部分token掩码化,形成损坏的序列$\hat{\pmb{x}}$,假设被掩码的token为$\overline{x}$,则需要从$\hat{\pmb{x}}$恢复$\overline{x}$
$$
max_{\theta}logp_\theta(\overline{x}|\hat{\pmb{x}})\approx \sum_{t=1}^Tm_tlogp_\theta(x_t|\hat{\pmb{x}})=\sum_{t=1}^Tm_tlog\frac{exp(H_\theta(\hat{\pmb{x}})^Te(x_t))}{\sum_{x’}exp(H_\theta(\hat{\pmb{x}})^Te(x’))}
$$$m_t$为1表明$x_t$被mask
- $H_\theta$为一个Transformer,将长度为$T$的序列$\pmb{x}$转换为一个隐藏向量的序列$H_\theta(\pmb{x})=[H_\theta(\pmb{x})_1,H_\theta(\pmb{x})_2,…,H_\theta(\pmb{x})_T]$
如上所述,BERT的约等于强调了其假设所有屏蔽token都是独立的,而AR没有这个假设
BERT中的[MASK]在下游任务从未出现,会产生差异,虽然会用原始token替代[MASK],但不能解决问题,而AR模型无此问题
BERT能够双向处理文本,获得双向的上下文,但AR只能获取单向的上下文
目的:排列语言建模
提出排列语言建模,兼顾AE、AR的优点
对于长度为$T$的序列$\pmb{x}$,有$T!$种不同的自回归分解方式,如果参数在所有因子分解顺序中共享,则模型将学会从两侧所有位置收集信息
形式化定义:
设$\mathcal{Z}_t$表明所有的可能排列,$\mathcal{z}t$与$\pmb{\mathcal{z} }{<t}$表示一个排列$\pmb{z}$中第t个元素和前t-1个元素,因此目标为:
$$
max_\theta E[\sum_{t=1}^T]logp_\theta(x_{\mathcal{z}t}|\pmb{x}{\pmb{\mathcal{z}}_t})
$$对文本序列,一次采样一个因式分解顺序,根据分解的顺序,分解似然$p_\theta(x)$,由于模型参数$\theta$共享,认为$x_t$能看到其他上下文
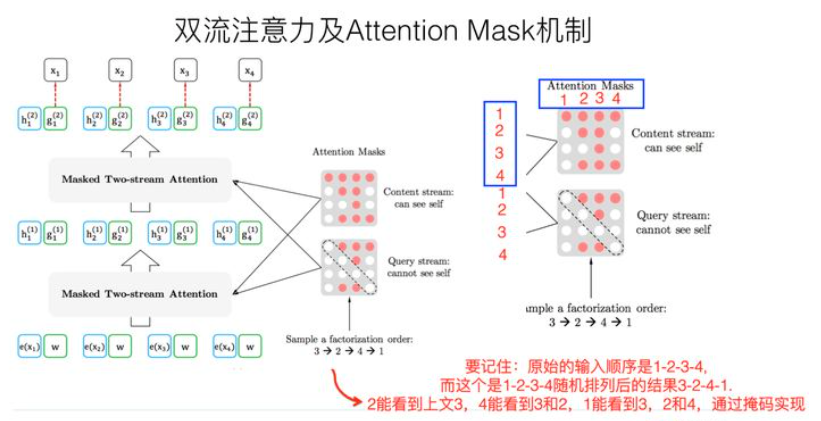
这里只排列因子分解的顺序,而不改变序列顺序,依靠Transformer中的注意力掩码来实现因子分解顺序的排列,下图显示了$x_3$在给定序列下的不同分解顺序
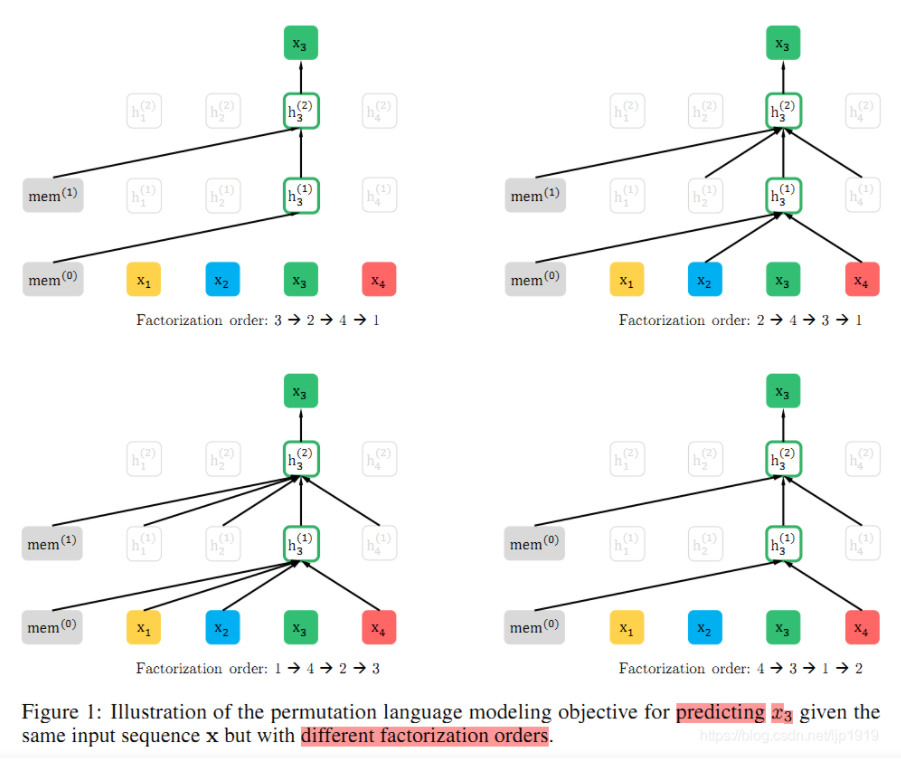
由于计算复杂度的限制,不可能计算所有的序列排列,因此对于每个序列输入只采样一个排列方式。而且在实际训练时,不会打乱序列,而是通过attention mask实现排列,这样可以保持与finetune输入顺序的一致,不会存在pretrain-finetune差异
架构:Two-Stream Self-Attention
打乱顺序时,模型不一定知道当前要预测的是什么,如需要预测$P(x_4|x_2,x_1)$,如果排列方式改变,要预测$P(x_3|x_2,x_1)$,但模型不知道下一个是$x_3$还是$x_4$,因此需要加入位置信息:$P(x_4|x_2,x_1,4)$
但同时,对每个位置,要预测的是内容信息(对应位置的词),因此输入不能包含内容信息——这导致位置信息和内容信息的割裂
为实现上述的“attention mask实现句子的排列”,本文提出双流自注意力机制,具体操作为,使用两组隐藏状态g和h,g只有位置信息,h包含内容信息
Content流注意力——传统的self-attention,h同时作为Q、K、V
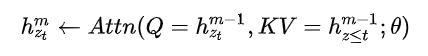
Query流自注意力——只能看到当前的位置信息,不能看到当前token的编码,用于替代BERT中的[MASK]。例如,需要预测$x_3$,BERT引入[MASK]覆盖此单词,XLnet则在内部引入Query流,以忽略该单词;g作为Q,h作为K和V
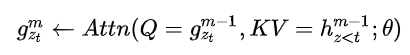
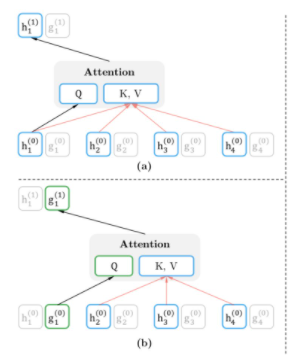
- 这里,蓝色的Content Stream的输入为$x$的嵌入,$w$之所以一样是因为使用了相对位置编码(Transformer-XL);Query steam中,将当前位置之外的h作为K和V,但实现上是所有时序上的h都作为K和V,最后上交给attention mask完成位置的遮盖
提出partial prediction进行简化
- 由于模型从第一个token预测到最后一个token,预测起始阶段,上文信息很少,不足以支持token的预测
- XLnet只预测后面一部分的Token,将前面所有的token当作上下文
- 例如,对长度为$T$的句子,选择超参数$K$,预测后面$1/K$的token,前面的token当作上下文——$K$越大,上下文越多,预测越精确
预训练阶段只使用query流
借鉴Transformer-XL
- 继承了相对位置编码和分段递归
Relative Segment Encodings
BERT还有一个Next Sentence Prediction的优化目标,有助于finetune阶段直接适应各种类型的下游任务,因此XLnet提出Relative Segment Encoding,将只判断两个token是否在一个segment中,而不是判断他们各自属于哪个segment
计算attention weight的时候,算出一个额外的权重加到原本的权重上,如果在一个segment中,则用$s_+$

总结
- XLNet是一种通用的AR预训练方法,使用排列语言建模目标来结合AR和AE方法的优点
- XLNet在各种任务上比以前的预训练方法实现了实质性的改进

