2019年《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》论文阅读笔记——基于2018年《Character-Level Language Modeling with Deeper Self-Attention》(vanilla Transformer)
摘要
- vanilla Transformer有学习长期依赖的能力,但是固定长度上下文的限制
- 本文提出一种新的体系结构Transformer-XL,在不破坏时间一致性的前提下学习固定长度之外的依赖性:段级别的递归机制+新位置编码方案
- Transformer-XL学习序列的依赖性比Rnn多80%,比Transformer多450%,评估期间比Transformer快1800倍
- 给定训练集WikiText-103,能够生成数千个token的连贯样本文章
介绍
神经网络对顺序数据建模长期依赖性一致是一个挑战,递归神经网络已经是一个标准解决方案,但梯度爆炸和梯度消失一直影响RNN的效果,即使有LSTM和梯度剪裁技术——经验上,LSTM平均能够使用200个上下文词语
注意力机制使模型能学习长距离单词对之间的联系,18年的vanilla Transformer大大优于LSTM,但此工作在数百个字符的独立固定长度片段上执行,没有跨片段的信息,即模型很难捕获超过预定义上下文长度的任何长期依赖关系——比如当前输入和下一个输入的依赖关系,因此模型缺少必要的上下文信息来预测最开始的几个单词,导致性能不够;同时,在预测时vanilla Transformer需要一个一个输出,效率低下
本文提出Transformer-XL以解决固定长度上下文的上述限制
- 不再为每个新片段从头开始计算隐藏状态,而是重用在之前片段中获得的隐藏状态(在内存里保存)
- 展示了使用相对位置编码而不是绝对位置编码的必要性
- 引入了一个简单但更有效的相对位置编码公式,以”注意“到比训练样本更远的内容
本文在自注意力模型中引入递归的概念,并推导一种新的位置编码方案,实验结果显示,Transformer-XL是第一个在字符级和单词级建模上比RNN好得多的自注意力模型
模型
- 给定一段语料$x=(x_1,…,x_T)$,语言模型的任务是估计联合概率$P(x)$,$P(x)$通常可以分解为$P(x)=\prod_tP(x_t|x_{<t})$,从而简化为估计多个条件概率
- 估计条件概率时,通常使用一个训练好的神经网络将上下文编码为一个隐藏状态,单词嵌入与其相乘得到logits,logits送入softmax函数,得到下一个令牌的概率分布
Vanilla Transformer
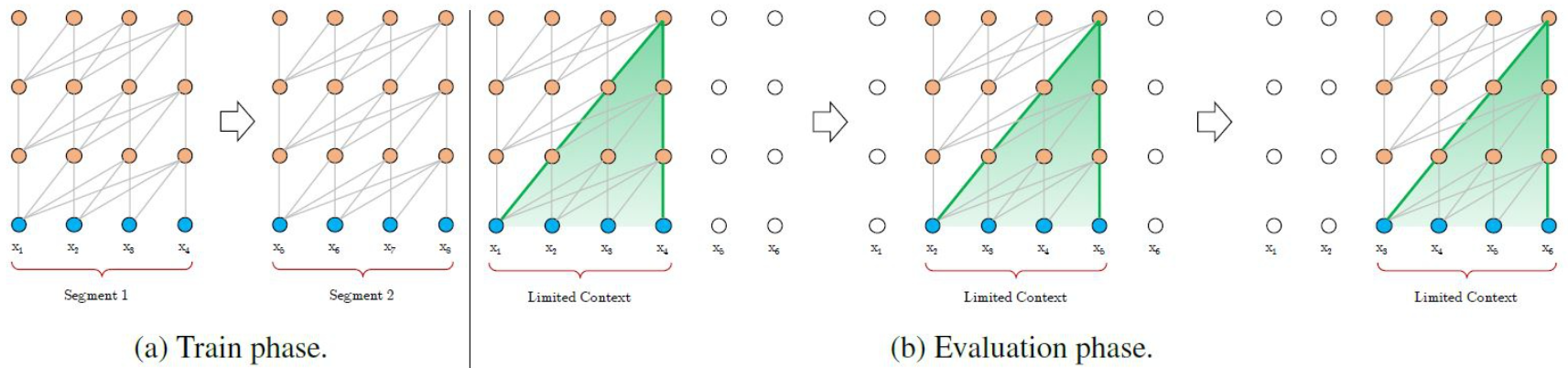
- vanilla transformer将整个语料库分割成更短的segment,并只在每个segment上训练模型,忽略之前segment的所有上下文信息
- 此时依赖长度上限是segment的长度
- 导致上下文碎片问题
- 评估过程里,每一步都使用与训练长度相同的segment,只在最后一个位置进行一次预测,之后segment向右移动一位。此过程尽可能利用了训练过程中学到的上下文,但成本高,速度慢
- 具体过程见第一个图
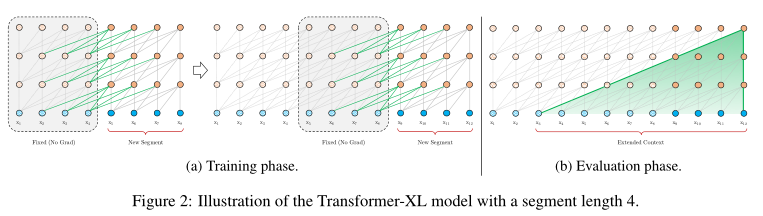
状态重用的段级递归
本文在Transformer中引入递归机制,训练中为前一个segment计算的隐藏状态序列被保留,当模型处理下一个segment时,缓存中的状态序列作为扩展的上下文被重用,此时网络能够利用历史信息,建模长期依赖关系
形式化表述如下:
两个连续segment长为$L$,$s_r=[x_{r,1},…,x_{r,L}]$,$s_{r+1}=[x_{r+1,1},…,x_{r+1,L}]$
假设第$r$个segment($s_r$)生成的第$n$层隐藏状态序列为$h_r^n\in R^{L\times d}$,其中$d$为隐藏层维度,则第$r+1$个segment($s_{r+1}$)对应的第$n$层隐藏状态序列为:

其中,函数$SG$代表stop-gradient,符号$\circ$表明将两个隐藏序列沿长度维度连接,$W$代表模型的参数
与标准的Transformer相比,主要差异在于$k_{r+1}^n$与$v_{r+1}^n$为基于扩展的上下文$\widetilde{h}_{r+1}^{n-1}$,因此获得了上一个segment的缓存$h_r^{n-1}$
此机制创建了隐藏状态下的segment级别递归,因此利用的有效上下文可以超过这两个部分。但是这里循环依赖项$h_{r+1}^n$与$h_{r}^{n-1}$在每个segment上,向下移动一层,这与一般的RNN是不同的,即可能的最长依赖长度随层的数目和segment的长度线性增长,如第二个图的(b)
此机制还提高了计算速度,在评估期间能够重用前面的状态
相对位置编码
还有一个问题是,在重用隐藏状态时,如何保持位置信息的一致性,若按以往的编码方式,则模型无法区分相对位置相同的两个token
解决方案为,只编码隐藏状态下的相对位置信息
位置编码提供关于信息如何收集的时间线索,因此将相同的信息注入到每一层的注意力得分中,而不是加入初始的嵌入
例如,query不需要知道每个key的绝对位置,只需要知道key之间的相对距离即可,通过将相对距离动态地插入注意力得分,query根据距离的不同,可以区分$x_{r,j}$和$x_{r+1,j}$,此时绝对距离可以通过相对距离递归恢复
标准的Transformer中,同一个segment中,query和key之间的注意力得分可以分解为:
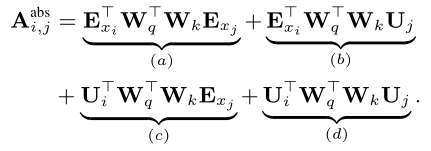
之后更改为下式,其中(a)表示基于内容的寻址,(b)捕获依赖于内容的位置偏差,(c)控制全局内容偏差,(d)编码全局位置偏差
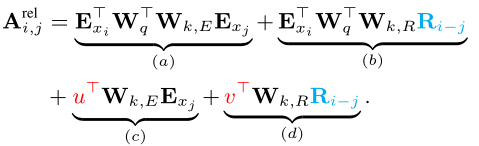
最终Transformer-XL的架构为:

实验
主要结果
将Transformer-XL应用于单词级和字符级的数据集,如WikiText-103、enwik8、text8、One Billion Word、Penn Treebank
WikiText-103是目前可用的最大的具有长期依赖性的词级语言建模基准,包含来自28K篇文章的1.03亿个token,在训练期间将注意力长度设置为384,在评估期间设置为1600
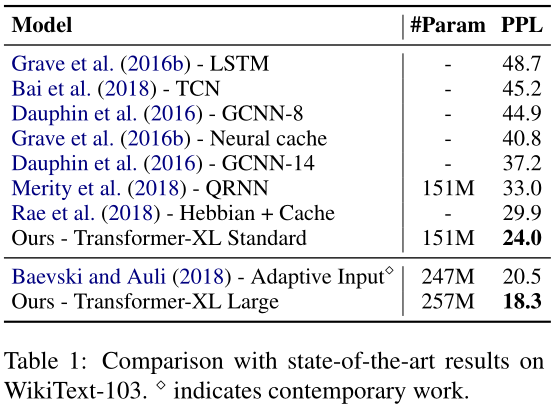
enwik8包含1亿字节未经处理的维基百科文本,将本文架构与表2中的结果进行了比较,12层Transformer-XL实现了新的SoTA结果;同时为了看是否可以通过增加模型尺寸获得更好的性能,训练了18层和24层的模型,最终获得了一个新的SoTA结果——Transformer-XL不需要任何辅助损失函数,所有优势都归功于更好的架构
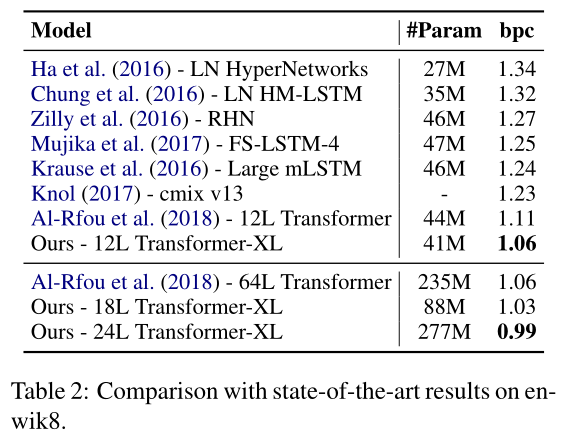
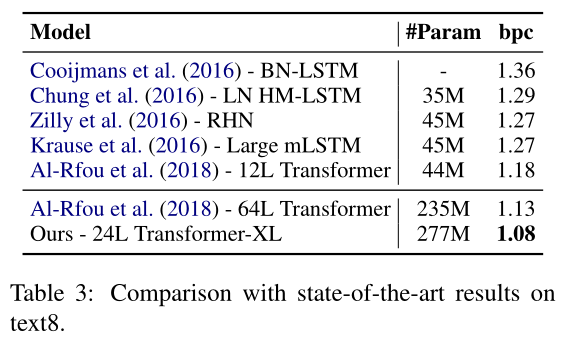
text8和enwik8相似,包含1亿个经过处理的维基百科字符,但text8的文本均为小写、删除26个字母和空格之外的任何字符,因此只需将enwik8上的最佳模型根据相同的超参数调整为text8上的模型即可,同样Transformer-XL获得了新的SoTA结果
数据集One Billion Word、Penn Treebank采取类似的方式进行对比,均为SoTA
消融实验
- 进行了两组消融研究,以检查Transformer-XL中使用的两种机制的效果:递归和相对位置编码
- 略
结论
- Transformer-XL获得了很好的结果,建立了比RNN和Transformer更长时间的依赖模型,并且评估阶段的运行速度更快

