2019年《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》论文阅读笔记
摘要
- 新的语言表示模型,根据未标记文本,来预训练深度双向表示,只需要一个输出层即可对预训练的 BERT 微调,无需对特定任务调整体系结构
- 在11个NLP任务上获得最佳
介绍
- 预训练语言模型对许多NLP任务有帮助,包括句子级别的任务如自然语言推理、句子关系分析,以及token级别任务如命名实体识别和问答
- 预训练模型通过
feature-based和fine-tuning应用到下游任务,前者如ELMo使用特定于任务的体系结构,预训练的表达作为附加特征;后者如GPT,通过简单微调所有预训练参数对下游任务进行训练,二者在训练前的目标函数一致,均为单向语言模型——即先生成a,再生成ab,以此类推 - 本文认为i,对于微调方法,以上技术限制了预训练模型的表达能力,每个token只能关注到自注意力层中先前的token,一些任务需要(如问答)从两个方向合并上下文
- 本文改进了基于
fine-tuning的方法,提出BERT(Bidirectional Encoder Representations from Transformers)- BERT在完形填空(
Cloze)任务的启发下,使用MLM(masked language model)缓解以上限制——MLM随机屏蔽输入中的一些token,其目标是预测屏蔽token在词表中的id - 同时加入了预测了两个句子是否连续的任务,以结合预训练的文本对表示
- BERT在完形填空(
- 本文贡献:
- 证明了双向预训练对语言表征的重要性
- 表明预训练能够避免为特定任务设定框架,BERT是第一个基于微调的表示模型,优于许多应用于特定任务的体系结构
相关工作
无监督的基于特征的方法
- 预训练的词嵌入比从头学习词嵌入的效果更好
- 09年人们使用从左向右的语言模型,预训练词嵌入向量
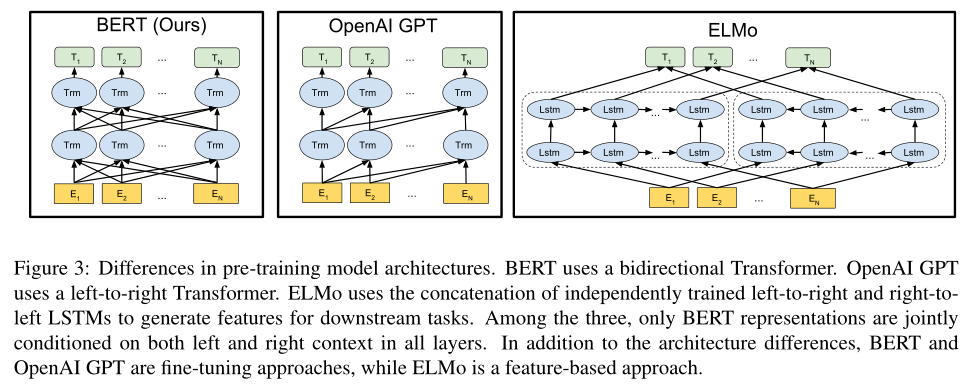
- 17年,ELMo使用从左到右、从右到左的语言模型提取上下文特征,每个token的上下文表示是两个单向表示的串联,ELMo(上下文词嵌入)可以与各种特定任务的体系结构集成
- 16年,人们提出使用LSTM从左、从右的上下文预测单个单词的方式,来学习token的上下文表示,此模型与ELMo类似,是基于特征的,不是深度双向的
无监督的基于微调的方法
- 几乎不需要从头学习参数
- 自左向右的模型,以及自动编码器常用于此类模型
BERT
- 两个步骤:预训练+微调,每个下游任务都有单独的微调模型,但不同的任务有统一的框架
模型结构
- 模型结构为一个多层双向Transformer encoder,基于17年的原始版本,这里省略对模型结构的说明,具体参照
The Annotated Transformer - 定义Block数目为$L$,隐藏层大小为$H$,自注意力头为$A$,并且前馈单元数为$4H$
- $BERT_{Base}$:$L=12,H=768,A=12$,大约110M,与GPT的尺寸相同,但GPT只能注意到每个token左边的上下文
- $BERT_{Large}$:$L=24,H=1024,A=16$,大约340M
输入输出表示
为了让BERT处理下游任务,将输入表示为单个句子和一对句子
- 句子可以是连续文本的任意范围,不一定是实际地语言句子
- 序列是输入到BERT的token序列,可以是单独的一个句子,可以是一对句子
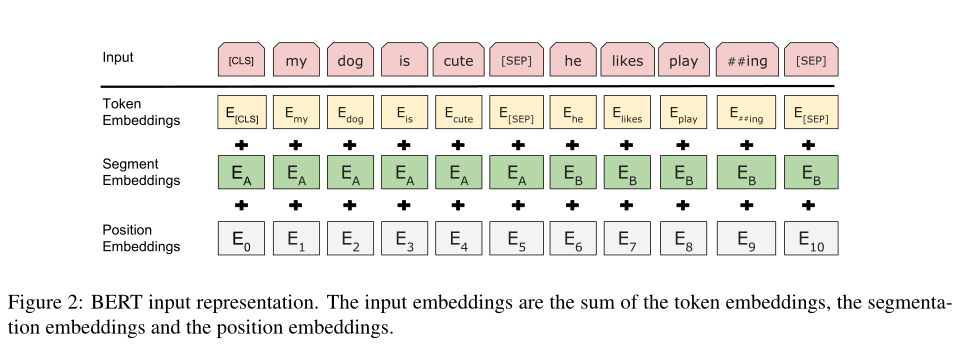
本文使用WordPiece词嵌入,其中包含30000个token的嵌入,每个序列的第一个token为[CLS],此token的最终隐藏状态将用于分类任务中整个序列的聚合表示
一对句子打包为一个序列,使用特殊标记[SEP]分隔,为每个token添加一个嵌入(已学习到的嵌入,原文为
a learned embedding)一个token的输入将为对应令牌、对应位置、对应所述句子的三个嵌入之和,具体参看下图
预训练BERT
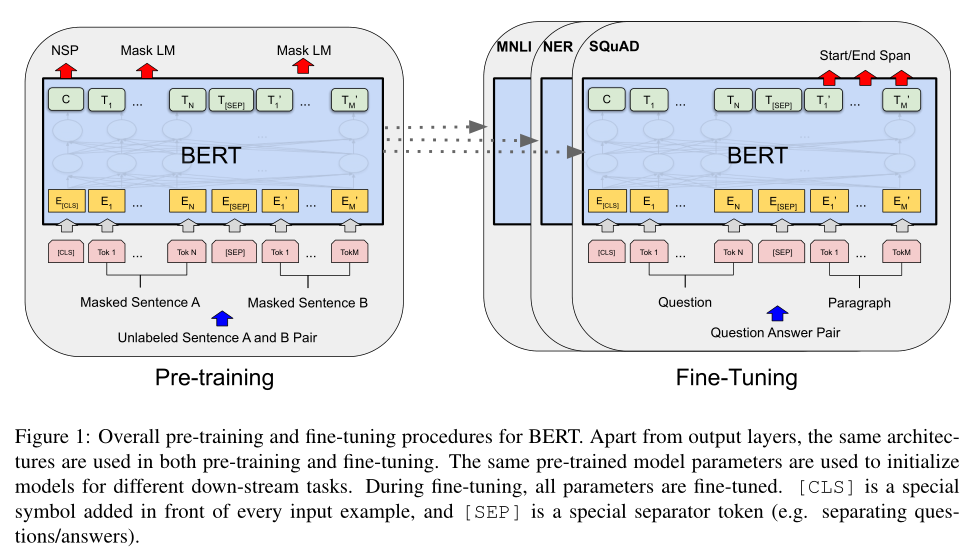
- 与18年两个文章不同,本文使用两个无监督的任务对BERT进行预训练,如第一个图左,其中$C$为[CLS]的最终隐藏向量,$T_i$为第$i$个token的最终隐藏向量
Masked LM
- 直觉上,深度双向模型比从左到右、从右到左的浅层连接模型更能建模语言表示,但标准的条件语言模型只能是单向的,因为双向条件作用将允许单子间接“看到自己”
- 为此,随机屏蔽一些输入token,并预测被屏蔽的token(最后通过softmax确定相应token在词汇表中的id)
- 随机屏蔽序列中所有token的15%,并且不同于去噪自动编码器
denoising auto-encoder,只预测屏蔽词,不重建整个输入 - 缺点在于,预训练和微调过程存在差异,微调过程没有
masktoken,因此在需要mask的token中,10%用随机token替换,10%用原先token,80%用mask - 附录中对比了此过程的不同类型
Next Sentence Prediction
- 许多下游任务需要理解两个句子的关系——预训练二值化任务,预测一对句子是否为连续的句子
- 50%的句子对,后面句子为前一个句子的下一句,余下的为随机匹配
- 如第一个图左所述,根据$C$来决定二值化预测结果
预训练数据
- 数据使用BooksCorpus和English Wikipedia,后者只提取文本段落,忽略列表、表格、标题
- 关键在于使用文档级别的语料库,而不是Billion Word Benchmark这样句子级别的语料库,以提取长的连续序列
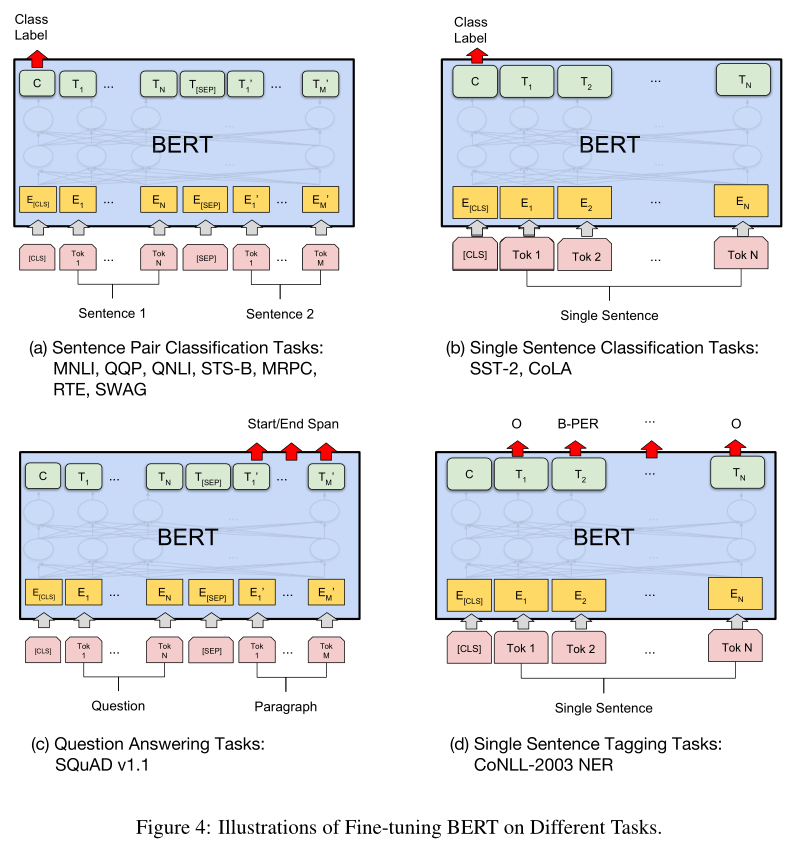
微调BERT
- 对于每个任务,只需要将输入和输出连接到BERT,端到端微调所有参数
- 输入端,句子A和句子B类似于:
- 释义(
paraphrasing)中的句子对 - 蕴含(
entailment)中的假设、前提对 - 问答中的问题、回答对
- 文本分类和序列标签中的文本、None对——相当于一种退化,句子B为空
- 释义(
- 输出端,token的表示被送入token级别的输出层,如序列标签和问题回答,[CLS]的表示被送入用于分类的输出层
- 本文所有微调的结果,可以在GPU上训练几个小时获得
实验
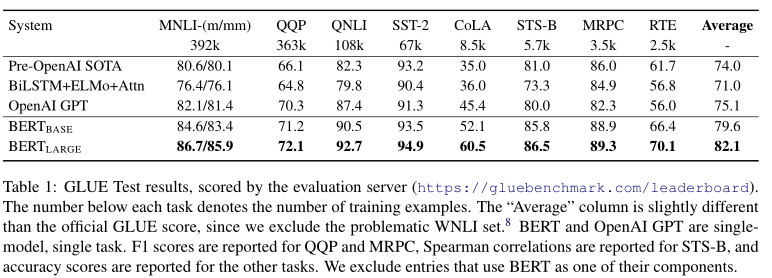
GLUE
GLUE benchmark是一个多种自然语言理解任务的集合
使用上面的方法表示输入序列,用[CLS]的最终隐藏状态$C$作为句子的聚合表示
微调期间引入的新参数为分类层的权重,用对数计算分类损失:$log(softmax(CW^T))$
微调期间,batchsize为32,epoch为3,选择Dev上的最佳学习速率
结果如下,BERT达到最优,其中$BERT_{Large}$明显优于$BERT_{Base}$,特别是训练数据少的任务中
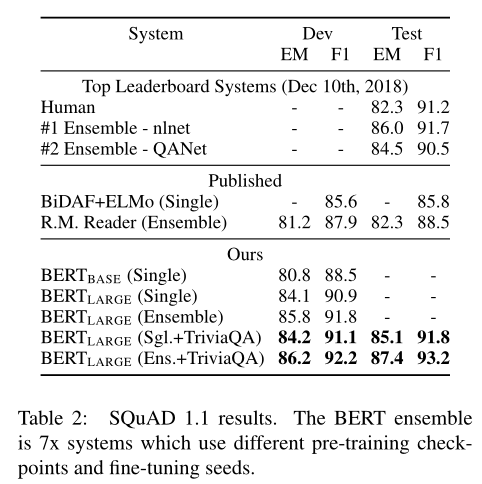
SQuAD v1.1
此数据集(The Stanford Question Answering Dataset)为10万个问答对的集合,给定文章和问题,预测答案文本在文章中的跨度
将问题和文章表示为一个打包后的序列(如第一个图右),其中问题使用嵌入$A$,文章使用嵌入$B$
微调过程只引入一个开始向量$S$和结束向量$E$,单词$i$为答案开始的概率为$T_i$和$S$之间的点积除以所有单词和$S$的点积(softmax):$P=\frac{e^{S\cdot T_i}}{\sum_je^{S\cdot T_j}}$,同理得到单词$j$为答案结束的位置,相应跨度的得分定义为$S\cdot T_i+E\cdot T_j$,得分最大的结果即为预测结果
epoch为3,batchsize为3,学习率为5e-5,结果如下
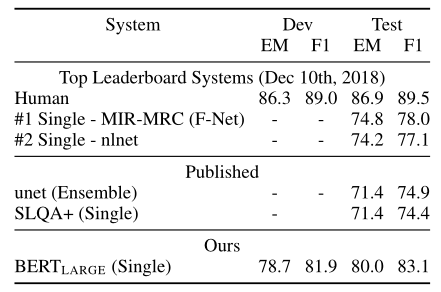
SQuAD v2.0
此数据集为上一个数据集的扩展,允许文章中没有答案
解决方案为,将没有答案的情况,视为答案从[CLS]开始,从[CLS]结束,因此表征开始、结束的概率扩建扩展到[CLS]的位置
在预测一个文章、问题对时,对比$s_{null}=S\cdot C+E\cdot C$和当前最高的$s_{i,j}=S\cdot T_i+S\cdot T_j$,如果满足$s_{null}+\tau>s_{i,j}$,则认为无答案,其中超参数$\tau$要求能让验证集的$F_1$最大
epoch为2,batchsize为48,学习率为5e-5
SWAG
此数据集用于评估常识推理任务:给定一个句子,在四个选项中寻找最合理的下一句
构建四个输入序列, 每个序列为句子A和句子B的连接结果,引入唯一的参数为一个向量,与[CLS]的点积表明相应选项的分数,最终四个分数用softmax归一化
epoch为3,batchsize为16,学习率为2e-5

消融实验
- 对BERT进行多个方面的消融实验(
ablation experiments),以研究它们的相对重要性
预训练任务的影响
- 评估BERT深度双向特征的重要性
- No NSP:预训练只有MLM任务
- LTR & No NSP:预训练为从左到右(LTR)的语言模型(即Transformer decoder),且没有NSP任务,这与GPT类似
- BERT与No NSP的对比,表明了预训练中NSP任务的影响,其显著影响了QNLI、MNLI以及SQuAD 1.1
- No NSP与LTR & No NSP的对比,表明训练双向表示的影响,LTR模型在所有任务上的表现都比No NSP任务差
- 为了提高LTR & No NSP,在顶部添加一个随机初始化的BiLSTM,虽然有提高,但仍远低于双向训练的模型
- 虽然可以训练单独的LTR和RTL模型,并将token表示为二者的串联(如ELMo),但成本高,并且一些任务并不合适(例如不应该从答案反推问题),同时深度双向模型可以在每一层都使用左右上下文,此方案不行
模型尺寸的影响
- 训练了不同层数、隐藏单元、注意力头的模型
- 结果表明,模型更大则效果更好,即使数据集比较小——此前,一些基于特征的预训练模型并不能达到这个效果,因此本文假设,当模型直接对下游任务进行微调,并且只使用非常少量随机初始化的附加参数时,其结果可以从更大的、更具表达性的预训练表示中受益,即使下游任务的数据非常少
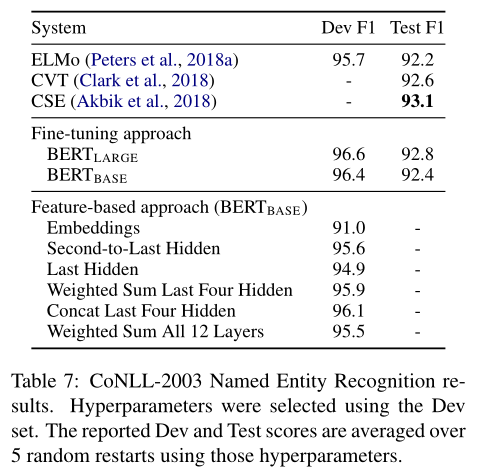
BERT和基于特征的方法
以上方案都是将分类层添加到预训练模型中,但基于特征(从预处理模型中提取固定特征)的方案仍有意义,因为不是所有任务都可以用Transformer encoder的架构表示
本文将BERT应用于命名实体识别,来对比这两个方案
BERT的输入使用保持大小写的WordPiece模型,并包含数据中的文档上下文
视其为标记任务,BERT与token级别的分类器连接,将第一个token的表示作为分类器的输入,但不在输出中使用CRF层
在基于特征的方法中,固定BERT的参数,在一个或多个层中提取激活结果,作为两层BiLSTM的输入,BiLSTM的输出再送入分类器
对比结果表明,性能最好的方法是将最后四层的token状态连接起来后,输入BiLSTM+分类器,这说明BERT对基于微调、基于特征的方法都有效
总结
- 提出BERT模型,将无监督预训练模型推广到深度双向架构