《自然语言处理入门》阅读笔记(4) 第七章+第八章+第九章
词性标注
词性:单词的语法分类;词性的集合称为词性标注集
词性标注:句子中每个单词都预测词性标签
- 汉语中常见一个单词有多个词性(称为兼类词)
- OOV是任何nlp的难题——如何预测OOV的词性(OOV:未登录词)
词性标注视为中文分词的后续任务
将${B,M,E,S}$标签与词性标签联合作为复合式标签:

同时进行多个任务的模型:联合模型
- 语料库必须同时标注分词和词性——语料库少
- 联合模型的特征数目是独立模型的数十倍
语料库
语料库中的句子,都可转为如下格式(PKU格式):
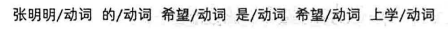
人民日报语料库与PKU标注集(其中,名动词的定义较为含糊)

国家语委语料库与863标注集
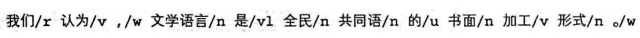
《诛仙》语料库与CTB标注集

序列标注模型用于词性标注
HanLP中的POSTagger接口:HMM、感知机、CRF
基于HMM的词性标注:
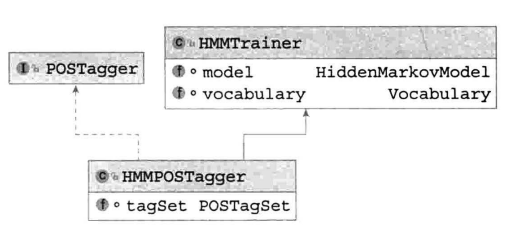
- model:任意的一阶或二阶HMM
- vocabulary:将单词映射为id
- tagSet:存储词性标注集
- HMM可以应对兼类词问题,但无法应对OOV
基于感知机的词性标注:
感知机词性标注器的特征模板:($x_t$为当前单词,$y_t$为当前单词的词性)

- 前三个状态特征为词语级别,捕捉上下文信息,其他为字符级别,推测OOV的词性
成功识别OOV的词性
基于CRF的词性标注:
词性标注评估:精确率、召回率、综合$F_1$
- 可对每一个标签都计算一遍,或者退化为相等的准确率
自定义词性
- 将自己关注的词语和自定义的词性,以词典的形式挂载到HanLP
- 标注一份语料库,训练统计模型
命名实体识别
词性标注仅作用于单个单词
命名实体:一些描述实体的词汇,如人名、地名、组织机构名、专业术语等
- 数量无穷
- 构词灵活
- 类别模糊(命名实体的区别模糊,如地名和机构名)
命名实体识别:识别句子中命名实体的边界和类别——统计为主,规则为辅
- 规则性较强的命名实体(网址、ISBN等),通过正则表达式处理,未匹配到的片段交给统计模型
- 较短的命名实体(人名),通过分词确定边界,通过词性标注确定类别
- 对于一些大颗粒度的语料库,分词+词性标注可以代替命名实体识别
- 对命名实体边界外的单词,统一标注为O(outside)
基于规则的命名实体识别
用于不精确地识别音译人名、日本人名,可用于应付语料匮乏地领域
基于规则的音译人名识别
音译人名用字较为固定

对于待识别的文本,若音译字符连续出现,则认为来自一个音译人名
音译人名较长,不易产生歧义,但不能全部收录——一套启发式规则:粗分结果中,如果某词语的备选词性含有音译人名,则从此词语向右扫描,遇到音译人名词库中的词语,则合并,否则终止扫描
例如:粗分结果如下
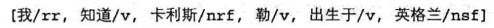
由于”勒“在人名词库中,合并结果为:
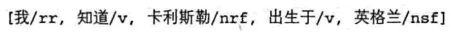
此过程无法识别未知的人名片段,但能够查到较长、构词常规的音译人名
基于规则的日本人名识别
- 在文本中匹配日本人名的姓氏和名字
- 将连续的姓氏和名字合并为日本人名,标注为nrj;存在一些黑名单规则,以区别特殊情况,如”龟山公园“
基于规则的数词英文识别
- 将相同类型的连续字符分别合并
- 获取每个字符的类型——包括单字节、分隔符(标点符号)、中文字符、字母、数字、序号等——将类型相同的字符合并,利用类型确定词性
命名实体识别语料库
1998年《人民日报》语料库
只关注人名、地名、机构名,则PKU语料可视为命名实体识别语料库,其中nr为人名,ns为地名,nt为机构名

其余复合词视为普通词汇
微软命名实体识别语料库(MSRA-NE)
- 实体类型包括:专有名词NAMEX,时间表达式TIMEX,数字表达式NUMEX,度量表达式MEASUREX,地址表达式ADDREX 五个大类及30个下属子类
- 除命名实体外的词语没有标注词性
- 原始数据为xml格式
基于层叠HMM的角色标注框架
角色标注框架类似日本人名的思路:
- 为构成命名实体的短词语打标签
- 标签序列满足某种模式,则识别为某个命名实体
- 根据HMM的预测进行标注
- 角色标注模块的输入是分词模块的输出
- 角色标注模块于分词模块均使用HMM,因此称为层叠HMM模型
基于角色标注的中国人名识别
举例:分词结果为”王国/n,维和/vn,服务员/nnt“,其中”王国维“的前半部分和后半部分是字符串在构成中国人名时充当的角色,确定粗分结果中各个词语的角色后,即可识别中国人名
定义中国人名的构成角色表如下:

根据上表编写规则,将词性标注语料转换为角色标注语料,训练HMM,利用HMM进行标注,最后通过模式匹配识别人名
基于角色标注的地名识别
原理类似,但需要定义新的角色标注集

基于角色标注的机构名识别
同上,但预测环节中由于机构名通常含有其他命名实体,需要进行第三次识别——层叠HMM的第一层用于得到粗略的分词结果,第二层识别其他实体,第三层识别机构名
角色标注集如下:

此框架没有考虑OOV问题,标注集需要根据具体问题手工编制,不够灵活,普通语料到角色标注语料的转换也需要专门设计
基于序列标注的命名实体识别
命名实体识别可视为分词+词性标注:实体边界通过${B,M,E,S}$确定,类别通过附加类别的标签如B-nt确定
将通用语料库转换为序列标注命名实体识别语料库:
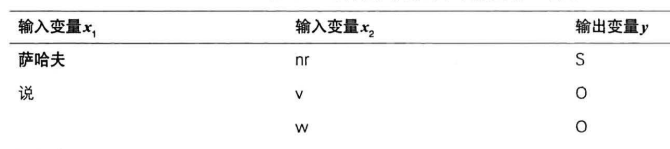
- 输入变量分别为词语和词性,由分词模块和词性标注模块给出
- 输出变量为复合型标签,由${B,M,E,S}$和实体类别标签组成
组合策略:
- 组合出S-nr之类的单个单词命名实体,提供用户改写词性标签的计回
- 将单个单词的命名实体标注为S,具体实体类型由词性标签决定
特征模板:(对于HMM,只能使用特征$y_{t-1},word_t$两个特征)

基于HMM序列标注的命名实体识别:
输入分别为单词和词性序列,输出B-nt之类的命名实体识别标签

根据B、M、E合并整个nt,以识别出”华北电力公司“
无法识别的原因:
- 语料库中,短语a没有作为实体的一部分出现过
- HMM无法利用词性特征
基于感知机序列标注的命名实体识别
基于CRF序列标注的命名实体识别
自定义领域命名实体识别
- 以上是通用领域上的语料库,无法识别专用领域中的命名实体
- 收集文本,作为标注语料库的原料——生语料
- 可在HanLP的标注基础上校正——先输出标注结果,然后定义新的标签,人工更新标注结果
- 后续过程同上
信息抽取
- 从非结构化文本中提取结构化信息的技术——基于规则的正则匹配、有监督学习、无监督学习
- 本章使用无监督学习的方法
新词提取
新词:词典外的词,即未登录词OOV
新词提取:1)从生语料提取词语,无论新旧;2)用词典过滤已有的词语,得到新词——关键在于1),即给一段文本,随机选取一个片段,如何判断这个片段是否为一个词
- 如果此片段左右搭配丰富,片段内部成分搭配固定,可认为这是一个词
- 片段左右的丰富程度,用信息熵衡量;内部搭配的固定程度,用子序列的互信息衡量
信息熵:某消息含有的信息量
离散型随机变量X的信息熵:
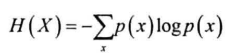
给定字符串S,若X定义为该字符串左边可能出现的字符(左邻字),则H(X)为S的左信息熵,同理得到右信息熵
例如:

蝴蝶的左邻字为:只、些
左右信息熵越大,说明搭配越丰富
互信息:两个离散型随机变量的相关程度
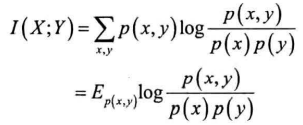
互信息越大,两个随机变量关联越密切,即同时发生的可能性越大
随机变量X代表一个子串,Y代表S剩余部分

关键词提取
只需要一个文档即可得到关键词:单文档算法(词频统计、TextRank);需要多个文档得到关键词:多文档算法(TF-IDF,容易受到噪音干扰)
词频统计:
- 认为关键词会在文章中反复出现——但根据齐夫定律,词频高的还会包括一些标点符号和助词
- 词频统计前通常需要过滤停用词
- 流程:分词、过滤停用词、按词频取前n个(通常使用最大堆算法获得m个元素中前n大的元素,复杂度为O(mlogn))
TF-IDF(词频-倒排文档频次):
综合考虑了词语的稀有程度:一个词语的重要度正比于其在文本中的频次,反比于包含它的文档数目,即越多文档包含它,这个词越宽泛,无法体现文档特色
基本公式为:
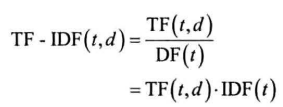
- t:单词
- d:文档
- TF(t, d):t在d中出现频次
- DF(t):包含t的文档数目
常用变换:加一平滑、取对数等
同样涉及分词、停用词过滤
需要大型语料库和较大内存
TextRank:
是PageRank在文本上的应用——PageRank:排序网页的随机算法
将互联网视为有向图,网页为节点,节点之间超链接为有向边,初始化时每个节点权重均为1,迭代的方式更新节点权重,公式如下:
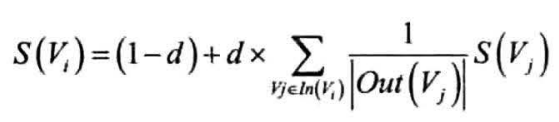
- d:常数因子,模拟用户点击链接后跳出当前网站的概率
- In(V):链接到当前节点的节点集合
- Out(V):从此节点出发链接到的节点集合
单词被视为节点,每个单词的外链来自前后固定大小的窗口内单词
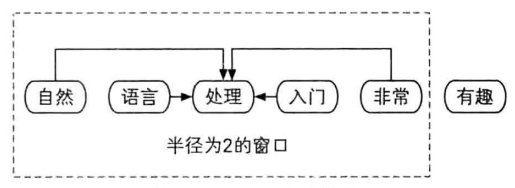
- 窗口半径为2,则”处理“的外链为周围四个单词
- 窗口内词语用于解释中心词,相当于给中心词投票,每一票权重被窗口词所有投出去的票平分
- 中心词左右搭配越多,则给自己做解释的词越多——类似于互信息
- 单词频次越高,被投票的机会越多——类似于词频统计
短语提取
- 新词提取推广到短语提取——字符替换为单词,字符串替换为单词列表即可
关键句提取
将PageRank应用到句子颗粒度上:BM25衡量句子的相似度,改进链接的权重计算,此时相似的句子会有更高的投票
BM25:
定义Q为查询语句,有单词$q_1,…,q_n$组成,D为被检索文档,Q和D的相似度BM25定义为:
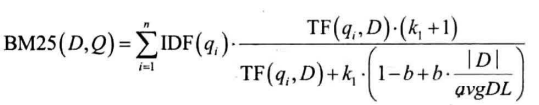
- IDF和TF的定义同TF-IDF部分
- $k_1,b$为两个常数:前者越大,TF对文档得分的正面影响越大;后者越大,文档长度对得分的负面影响越大
- avgDL为所有文档的平均长度
- BM25对查询语句中所有单词的IDF加权求和
TextRank:
将一个句子视为查询语句,相邻句子视为待查询文档,得到相似度,相似度作为PageRank中链接的权重:
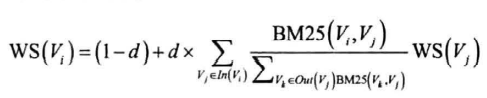
- $WS(V_i)$为文档中第i个句子的得分
- 迭代后得到所有句子得分,排序输出前N个句子,即为关键句
- 不再考虑窗口问题,认为所有句子都是相邻的:
- 句子几乎不重复
- 文档中句子数量远小于单词的数量

