《BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data》(BoB)2021ACL
摘要
- 保持一致的人物角色对于对话代理来说至关重要。有限的、带注释的、人物密集数据仍然是训练健壮和一致的基于人物的对话模型的障碍
- 通过一个新颖的BERT-over-BERT (BoB)将基于角色的对话生成分解为两个子任务
- 模型由一个基于BERT的编码器和两个基于BERT的解码器组成,其中一个解码器用于响应生成,另一个用于一致性理解
- 为了从大规模非对话推理数据中学习一致性理解的能力,以unlikelihood训练第二解码器
- 在不同的有限数据设置下,自动和人工评估都表明,BoB在响应质量和角色一致性方面优于baseline
介绍
- persona(角色)定义为身份元素的组合,例如个人资料、背景
- 基于角色的对话中,生成的响应不仅取决于对话上下文,还取决于一些预定义的persona
- 现有的基于角色的对话模型大量利用了一组与角色相关的对话数据,如PersonaChat。这种众包数据集涵盖了丰富的角色特征,但规模受到限制,并且日常生活中的对话并不总是与角色相关,即存在“角色稀疏性”——基于有限个性化数据训练的模型不能充分理解角色一致性
- 基于角色的对话生成中,需要模型:
- 理解角色-响应的一致性,
- 给定对话上下文的情况下生成与角色相关的响应
- 因此将基于角色的对话生成分解为两个子任务:一致性理解和对话生成,此时可用的数据就会多很多
- 一致性理解:利用大规模非对话推理数据作为训练数据
- 对话生成:已经有了各种大规模的稀疏数据集
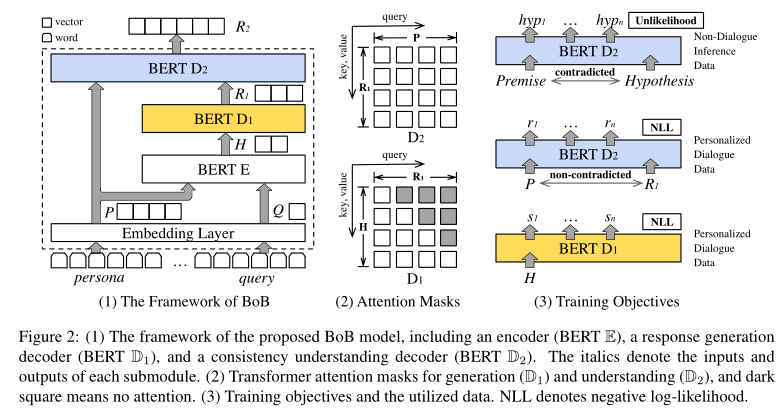
- 给定角色P和对话查询Q,编码器E和解码器D1以encoder-decoder的方式共同工作,捕获典型的查询到响应的映射$F_G(S|Q,P)$,生成粗略的响应表示R1;R1和P输入到双向decoder D2,学习将R1映射到最终响应表示R2:$F_U(R_2|S,P)$;一致性理解部分$F_U(R_2|S,P)$独立于对话查询Q,可以在非对话推理数据集上学习
- 应用unlikelihood作为训练目标,降低推理数据中矛盾案例的可能性,从而使D2获得一致性理解的能力
- 使用BERT初始化所有模块
相关工作
- 基于角色的对话:
- 最近的研究从个性化的对话数据集中学习人物角色相关的特征
- 在人物密集数据集上微调预训练的GPT可以提高生成响应的质量
- 利用BERT模型生成对话
- 不同的大规模预处理
- Unlikelihood:
- likelihood最大化目标序列的概率
- unlikelihood通过最小化负候选的概率来校正已知的偏差
模型
给定个人角色信息P和对话输入Q,E和D1共同以编码器-解码器模式中工作,学习典型的从输入到回复的映射$f_G(R_1|P,Q)$ ,生成初步的对话回复表示$r_1$,$r_1$和人物角色信息P被送入双向解码器,以将$r_1$映射到最终响应表示$r_2:$$f_U(R_2|S,P) $。由于学习一致性理解的部分$f_U(R_2|S,P)$独立于对话输入Q,该部分可以在非对话推理数据集上学习
在D2引入Unlikelihood目标函数,减少一致性理解中预测出矛盾(contradiction)数据的可能性
使用预训练后的BERT来初始化所有模块
自回归解码器D1:
D1以自回归解码器的方式工作
BERT预测某一个掩码词时,会利用这个词语左右双向的信息,但在自回归的生成任务中,词语自左向右逐个预测
在训练和预测过程中对D1使用了figure 2中所示的上三角的掩码矩阵,确保生成的回复词只能依赖已有的信息
在E和D1之间添加了交叉注意力机制(cross attention)——不同于self-attention中query、key和value完全相同,cross attention的query来自D1的前一层信息

E和D1有N个层
双向解码器D2:
D2的输入没有添加上三角的掩码矩阵
D2学习如何理解一致性关系,并将这种能力应用于回复生成任务
D2同时通过标准的用于生成的交叉熵损失和用于一致性理解的Unlikelihood损失训练,交叉熵损失计算类似D1,但D2的输入是角色信息P和$r_1^N$,输出仍然是对话回复——这一特点使得D2的工作方式更加类似于降噪自编码器,而非seq2seq中的解码器
D2同样有N层,对于每一层:

每层产生的$r_2^i$融合了来自P和$R_1$的信息,最后一层的输出连接一个线性输出层,可以得到最终对话恢复R
实验
略

