《Unified Language Model Pre-training for Natural Language Understanding and Generation》(UniLM)2019 NIPS
摘要
提出了一种新的预训练语言模型UNILM,可以针对自然语言理解和生成任务进行微调
使用三种类型的语言建模任务进行预训练:单向、双向和seq2seq预测
使用共享的Transformer并利用特定的self-attention-mask控制预测内容所处的上下文
control what context the prediction conditions on
UNILM在GLUE、SQuAD 2.0和CoQA问答任务上与BERT一致,在五个自然语言生成数据集上实现了state-of-art的结果
介绍
预训练的语言模型(LM)通过基于单词的上下文预测单词,来学习上下文化的文本表示,并微调以适应下游任务
不同预训练LM采用了不同的预测任务和训练目标
- ELMo:学习前向LM与后向LM
- GPT:从左到右的transformer逐字预测文本序列
- BERT:双向Transformer编码器来融合左右上下文,以预测被mask的单词——其双向性使其难以应用于NLG任务

本文提出一种预训练LM,可以应用于NLU和NLG任务:UNILM是一个多层Transformer,在大量文本上联合预训练,针对三种类型的无监督语言建模目标进行优化
本文特别设计了一组cloze tasks——根据上下文预测被屏蔽的单词。这些cloze task在如何定义上下文方面有所不同
- 从左到右的单向LM:预测的单词的上下文由它左边的所有单词组成
- 从右向左的单向LM:上下文由右边的所有单词组成
- 双向LM:上下文由右边和左边的单词组成
- seq2seq的LM:目标序列中待预测单词的上下文由源序列中的所有单词、目标序列中其左侧的单词组成
UNILM可以同时用于NLU和NLG任务
- 统一的预训练过程产生一个Transformer LM,不同类型的LM使用共享的参数和架构
- 参数共享使得所学习的文本表示更加通用,减轻对任何单个LM任务的过度拟合
- 在五个NLG数据集上展示了UNILM的有效性——生成性问答、对话响应等

UniLM预训练
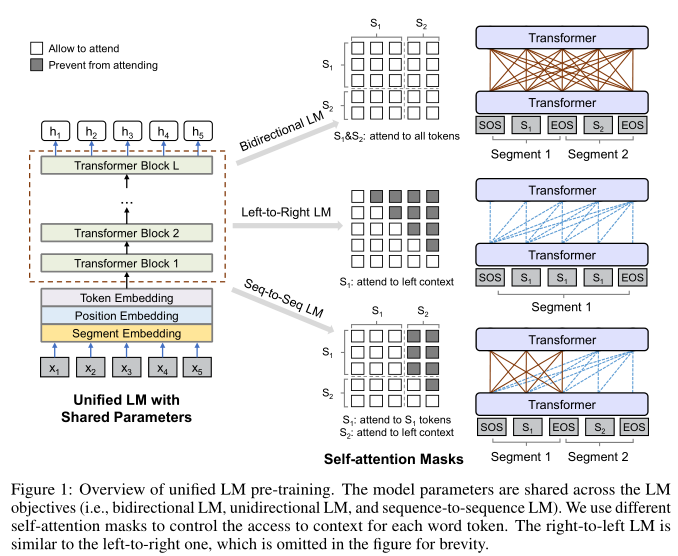
Input Representation
- 输入x是一个单词序列:单向LM的文本段、一对用于双向LM的句子对、用于seq2seq的句子对
- 在输入的开头添加[sos],结尾添加[eos],输入的表示遵循BERT的表示——每个输入token,通过相应的token嵌入、位置嵌入、段嵌入求和,计算嵌入向量
- 文本由WordPiece分词
- UNILM使用多个LM任务进行训练的,段嵌入也扮演了LM标识符的角色——对不同的LM任务使用不同的段嵌入
Backbone:multi-layer Transformer
输入转换成$H^0=[x_1,…x_{|x|}]$,送入L层的Transformer
骨干网络由24层Transformer组成,每一层编码输出为$H^l=Transformer_l(H^{l-1})$
每层的一个自注意力头$A_i$的输出计算过程如下:

- 通过掩码矩阵$M\in R^{|x|\times |x|}$控制每个词的注意力范围,0表示关注,负无穷为不关注,被mask
- 上一层的输出为$R^{|x|\times d_h}$,参数矩阵$W_l^Q、W_l^K、W_l^V\in R^{d_h\times d_k}$
预训练目标
使用四个cloze task预训练UniLM——针对不同LM目标
cloze task:随机选择输入的一些WordPiece tokens,用[mask]替换,然后送入Transformer网络计算相应输出向量,送入softmax以预测屏蔽token——最小化预测token和原始token的交叉熵损失
单向LM:
- 要预测“x1x2[mask]x4”的屏蔽token,只能使用x1、x2
- 通过使用一个self-attention-mask矩阵实现——矩阵的上三角形部分被设置为负无穷,其他元素被设置为0
双向LM:
允许所有token在预测中相互关注
self-attention-mask是一个零矩阵,因此允许每个token注意输入序列的所有位置
so that so that every token is allowed to attend across all positions in the input sequence.
seq2seqLM:
- 源段tokens从段内的两个方向关注,目标段tokens只能关注自身、左侧上下文、源段所有tokens
- 例如,给定源段t1 t2及其目标段t3 t4 t5:输入“[sos] t1 t2 [eos] t3 t4 t5 [eos]”送入模型,t1 t2都可以看到包括[sos]和[eos]的前四个tokens,t4只能处理前六个tokens
- figure 1显示了用于seq2seq的self attention mask
- 训练过程中,两个segment中随机选择token用[mask]替换,该模型需要恢复被屏蔽的token——源文本和目标文本对在训练中被打包为连续的输入文本序列,隐含地鼓励了模型学习这两个segment之间的关系
下一句预测:在双向LM中,还加入了next sentence prediction的任务
预训练设置
- 24层Transformer,1024个hidden size,16个attention heads
- 采用Bert-Large的参数初始化
- GELU激活
- dropout:0.1;权重衰减:0.01;batch size:330;学习率:3e-5;adam参数:0.9、0.999
- 混合训练:对于一个batch,1/3时间采用双向LM的目标训练,1/3的时间采用seq2seq的目标训练,1/3时间平均分配给两种单向LM
- softmax的权重矩阵和token embedding的权重矩阵相同
- 15%的token被mask,其中80%为mask(80%只mask一个值,20%mask一个二元组或三元组),10%为不变,10%为真实值
微调下游NLU和NLG任务
- NLU:直接微调为双向Transformer编码器,同BERT一样(这里以文本分类为例)
- NLG:以seq2seq为例,构建输入“[sos] s1 [eos] s2 [eos]”,微调中随机掩盖target序列中一定比例的tokens,模型学习恢复被mask的词——微调时只有target的token被掩盖,甚至[eos]也可以被掩盖
实验
以下NLG任务的实验
抽象式文摘(abstractive summarization)
- 自动生成摘要内容
- 利用UniLM的seq2seq模型来完成
- 在训练集上微调30个epochs,微调的超参数与预训练的时候一致,target token被mask的比例为0.7,batch size设置为32,最大长度768,标签平滑设置为0.1
- 解码采用集束搜索策略,beam宽度为5
- 标签平滑:假设多分类的原label=[0,1,0],经过骨干网络+softmax之后输出预测值=[0.15,0.7,0.15],根据交叉熵公式会得到一个loss,此时从预测标签中能看出哪个类别概率大了,但基于loss函数的反向优化会继续减少损失,让0.7越来越靠近1,容易过拟合。故使用标签平滑,将原label修正,相互之间差别不要那么大,例如修改为[0.1,0.8,0.1],以防止模型过拟合
生成式问答(Generative QA)
- 给一段文本和一个问题,生成形式自由的答案,利用seq2seq模型完成
- 源序列是一段文本和问题,目标序列是答案
- 微调10个epochs,target token被mask的比例为0.5,batch size设置为32,最大长度为512,标签平滑设置为0.1
- 解码的时beam宽为3
问题生成(Question Generation)
- 给定一个输入段落和一个答案范围,生成一个询问该答案的问题
- target token被mask的比例为0.7,batch size为32
多轮对话响应生成(Response Generation)
- 给定一段多轮对话历史,将网络文档作为知识源,生成适合对话并且能反映网络文档内容的自然语言响应
- 源序列为对话历史+知识源,目标序列为响应的对话
- 微调20个epochs,batch size为64,target token被mask的比例为0.5
Future Work
- 通过在网络规模的文本语料库上训练更多的epoch和更大的模型
- 终端应用和消融实验上进行更多的实验,以研究模型能力和用同一网络预训练多语言建模任务的好处
- 当前的实验专注于单语的NLP任务——未来进行跨语种的NLP任务
关键代码
构造mask矩阵
1 | """ |
预训练时模型的输入
1 | if self.args.has_sentence_oracle: # 摘要生成任务 |
forward
1 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, masked_lm_labels=None, |
self.bert.forward
重点在于get_extended_attention_mask
huggingface中bertmodel也是要把attention_mask([bs, num_head, seq_len, seq_len])和attention_score相加,unilm和bertmodel的差别在于,bertmodel将extend attention_mask的步骤封装了起来,而且只做了简单的extend(即broadcast),而unilm则在数据预处理时,就将attention_mask设计好,之后只需要unsqueeze一下就得到四维的attention_mask
1 | def get_extended_attention_mask(self, input_ids, token_type_ids, attention_mask): |
对比huggingface中对attention mask的处理
forward:(重点关注attention_mask)
1 | # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length] |
extend:
1 | def get_extended_attention_mask(self, attention_mask: Tensor, input_shape: Tuple[int], device: device) -> Tensor: |

