《SpanBERT: Improving Pre-training by Representing and Predicting Spans》(SpanBert)2019
摘要
- 提出SpanBERT,旨在更好地表示和预测文本的跨度
- 扩展了BERT:
- 屏蔽连续的随机跨度,而不是随机token
- 训练跨度边界表示来预测屏蔽跨度的整个内容,而不依赖于其中的单个token表示
- SpanBERT始终优于BERT
介绍
许多自然语言处理任务涉及推理两个或多个文本区间之间的关系
本文介绍一种span-level预处理方法,它始终优于BERT,在跨度选择任务(如问答和共指解析)中获得最大收益
与BERT的不同之处在于掩蔽方案和训练目标
- 屏蔽随机的连续跨度,而不是随机的单个token
- 引入了一个新的跨度-边界目标(span-boundary-objective,SBO),使得模型可以从观察到的边界token中学习预测mask的跨度,基于跨度的mask迫使模型仅使用它们出现的上下文来预测整个跨度
- SBO鼓励模型在boundary-token处存储这种span-level信息
单个segment的预训练,而不是两个半长segment的下一句预测(NSP)目标,大大提高了大多数下游任务的性能,因此在调整后的单序列BERT baseline上增加了本文的修改
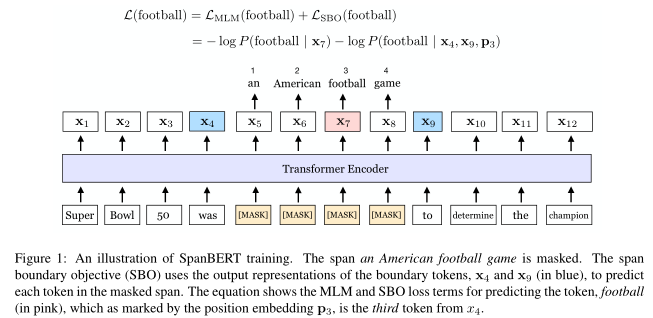
模型
- 与BERT的差别:
- 使用一个不同的随机过程来屏蔽span,而不是单个token
- 引入一个新的辅助目标SBO,试图仅使用boundary-span(边界跨度)处的representation(表示)来预测整个被mask的span
- SpanBERT为每个训练采样采样单个连续的文本段,因此不使用NSP作为预训练任务
Span Masking
给定token序列$X=(x_1,…,x_n)$,通过迭代采样span直到采样的规模为15%的$X$,得到子集$Y \subseteq X$
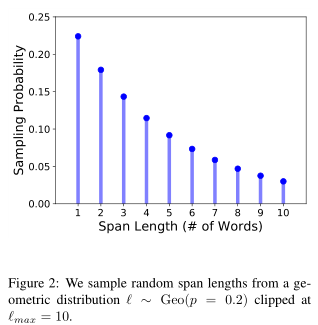
每次迭代中,首先从几何分布$l\to Geo(p)$中采样跨度长度(token数目),该分布向更短的跨度倾斜;然后随机(均匀分布)选择要mask的跨度的起点
总是采样一系列完整的单词(而不是子单词的token),起点必须是一个单词的开头
将p设置为0.2,将$l$最大值设置为10(如果大于10,则重新再采样一次)
和BERT一样,总共mask了15%的token:用[mask]替换80%的屏蔽token,用随机token替换10%,用原始token替换10%。但这里在span level中执行这种替代,即所有在一个span中的token都被[mask]替代
SBO
跨度选择模型通常使用边界标记来创建跨度的固定长度表示
SBO:仅使用边界处观察到的token的表示来预测被mask的span中每一个token
$x_1,…,x_n$表示transfomer的encoder对于序列每个token的输出,$x_s,…,x_e$表示$Y$的一个元素,其中s和e表示开始和结束的位置,使用外部的边界token$x_{s-1},x_{e+1}$的encoding输出,以及目标token的位置嵌入$p_{i-s+1}$来表示span中的每一个token
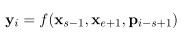
函数f实现为2-layer feed-forward网络,激活函数为GeLU和layer normalization
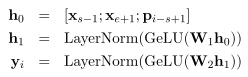
利用$y_i$预测$x_i$,像MLM一样计算交叉熵
SpanBERT对每个token$x_i\in (x_s,…,x_e)$的span boundary和mlm任务的损失求和,同时对MLM和SBO重用目标token的输入嵌入
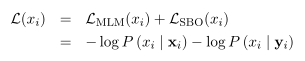
Single Sequence Training
- BERT的输入为两个文本序列,使用NSP预测是否相连——这种设置几乎总是比简单地使用单个序列而不使用NSP更糟糕
- 推测单序列训练优于使用NSP的双序列训练,因为
- 模型受益于更长的全长上下文
- 来自另一个文本的通常不相关的上下文对mlm增加了噪声
- SpanBERT中,删除了NSP目标,简单地对最长为512个token的单个连续段进行采样
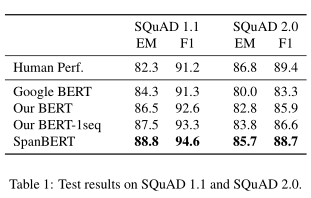
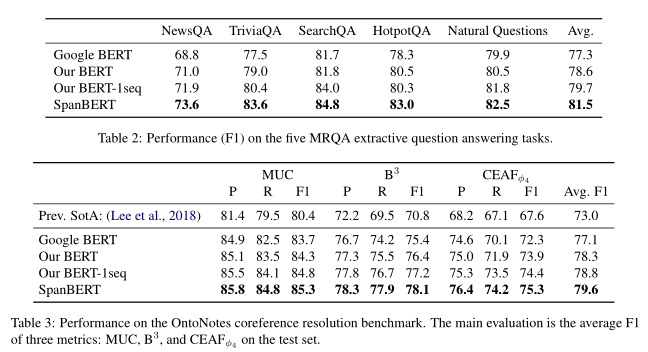
实验
- 抽取式问答
- 共指解析
- 关系抽取
- GLUE
- warmup:10000,lr:1e-4,Adam:0.9+0.999,权重衰减:0.1,dropout:0.1,Adamw:epsilon为1e-8,batchsize:256,位置嵌入:200维
实验结果