《R-Drop: Regularized Dropout for Neural Networks》(2021年NeurIPS)
摘要
- Dropout用于正则化深度神经网络的训练,引入的随机性导致训练和推理之间不可忽视的不一致
- 本文引入一种简单的一致性训练策略R-Drop来正则化dropout——迫使由dropout产生的不同子模型的输出分布彼此一致
- 具体来说,对于每个训练样本,R-Drop最小化由dropout采样的两个子模型输出分布之间的KL-散度
- 5个学习任务(总共18个数据集)的实验——包括神经机器翻译、抽象概括、语言理解、语言建模和图像分类——表明R-Drop普遍有效的
- 当应用于微调大规模预训练模型(例如ViT、RoBERTa-large和BART)时,具有实质性的改进,在多个任务上实现SOTA
介绍
- 现有文献[41,81]揭示了dropout的可能副作用,即dropout模型的训练和推断阶段之间存在不可忽视的不一致,训练期间随机抽样的子模型(dropout造成的)与推断期间的完整模型(无dropout)不一致
- 通过对不一致的隐藏状态施加L2正则化可以在一定程度上缓解不一致问题
- 本文方法为R-Drop,在每个batch训练中,每个数据样本经历两次前向传递,每次传递由不同的子模型通过随机丢弃一些隐藏单元来获得。R-Drop通过最小化两个分布之间的双向KL散度来强制两个分布相同,使两个子模型输出的数据样本彼此一致
- 与传统神经网络训练中的dropout策略相比,R-Drop只增加了KL-散度损失,而没有任何结构修改
- R-Drop对隐藏单元和Drop采样的子模型的输出都起作用
- 对5个任务和18个数据集的广泛实验表明R-Drop非常有效
方法
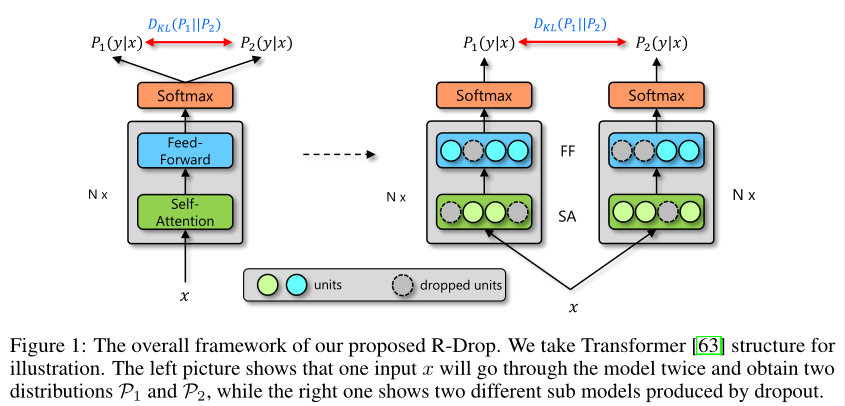
- 具体框架如图1所示
- 给定数据集$D={(x_i,y_i)}_{i=1}^n$,训练目标是学习一个模型$P^w(y|x)$,$n$为训练样本数目,$(x_i,y_i)$为标记数据
- 两个分布的KL散度表示为:$D_{KL}(P_1||P_2)$
R-Drop正则化
深度学习模型的主要学习目标是最小化负对数似然损失:
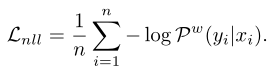
给定每个步骤的输入数据$x_i$,前向传播两次获得$P^w_1(y_i|x_i)$和$P^w_2(y_i|x_i)$,由于dropout存在,两个其实是不同的子模型,如图1右边所示。R-Drop试图最小化相同样本的这两个输出的双向KL散度,即:
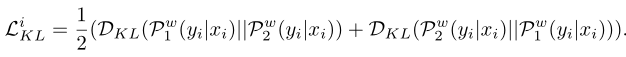
再加上样本的负对数似然损失:
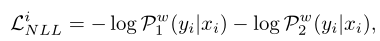
最终训练目标为最小化数据$(x_i,y_i)$的$L^i$,即
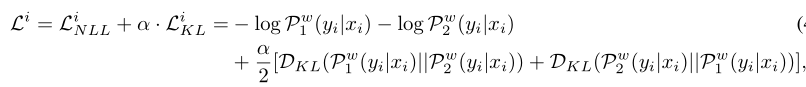
其中权重$\alpha$用于控制KL散度
训练算法

- 实际训练中,不需要重复输入相同的数据两次,而是可以重复、连接输入数据为$[x; x]$,即,将batch-size放大一倍
- 后文的实验显示,R-Drop需要更多的训练才能收敛,但性能也更好
理论分析
略
实验
NMT的应用

- 在Fairseq上进行
语言理解的应用
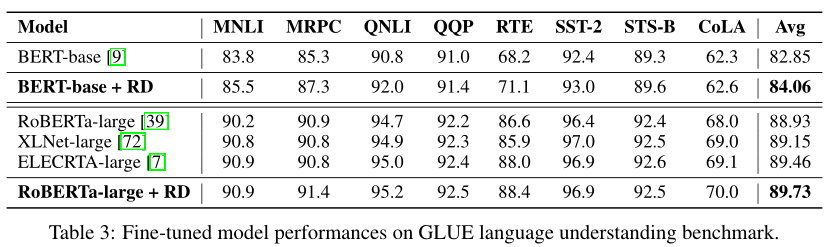
- 在GLUE上实验
- 对比BERT-base和RoBERTa-large
摘要的应用
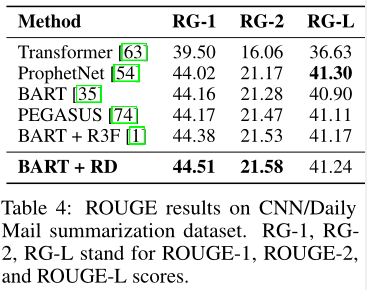
- 对比BART模型
- 超参数同原文,$\alpha$为0.7
语言建模的应用
- 对比Transformer decoder与Adaptive Input Transformer——在Transformer中引入自适应输入的嵌入
图像分类的应用
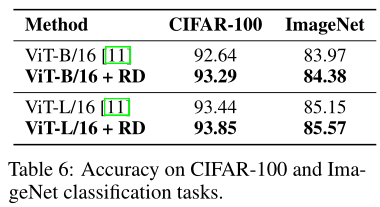
- 使用Vision Transformer做对比
其他研究
正则化和成本分析
如图2所示,随着训练的进行,Transformer很快变得过拟合,并且train与valid的loss的的差距较大,而Transformer R-Drop的valid loss较低——证明了R-Drop可以在训练过程中提供持久的正则化
早期训练阶段,Transformer快速提高BLEU得分,Transformer R-Drop逐渐提高BLEU分数,并取得了优越得多的性能,但需要更多的训练才能收敛
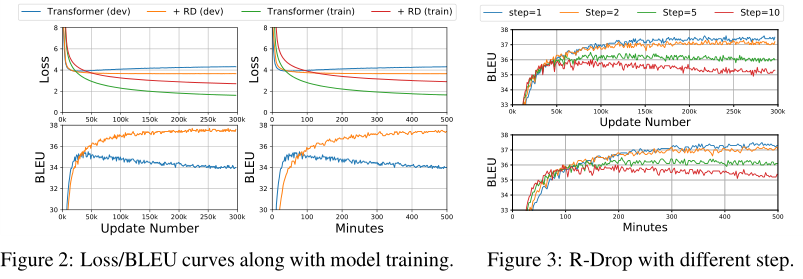
k-step R-Drop
- 由上知,R-Drop的训练次数更多,因此改为每$k$步执行一次R-Drop来提高训练效率——使用[1,2,5,10]
- valid的BLEU曲线以及训练更新次数和训练时间如图3所示
- 虽然用较大的$k$收敛更快,但训练没有进入最优解,很快过拟合,并且增加$k$时,BLEU分数越来越低
m-time R-Drop
- 上面是将同样数据输入两次,本节测试输入$m$此,此时KL散度为:$L_{KL}=\frac{\alpha}{m*(m-1)}\sum_{i、j\in 1,…,m}^{i \neq j}D_{KL}(P_i^w(y|x)||P_j^w(y|x))$
- $m=3$时效果类似于$m=2$,表明在两个分布之间已经具有较好的正则化效果,不需要更强的正则化
权重的影响

- $\alpha$过大,则表明过于关注KL正则化
- 每个任务的数据大小和模型大小导致过拟合发生的程度,决定$\alpha$的选择
总结
- 本文提出一种简单而又非常有效的基于dropout的一致性训练方法
- 在18个流行的深度学习数据集上的实验结果表明,R-Drop不仅能有效增强强模型,而且在大规模数据集上也能很好地工作,甚至达到SOTA性能

