《SimCSE: Simple Contrastive Learning of Sentence Embeddings》(SimCSE,2021年EMNLP)
摘要
- 本文介绍SimCSE,一个简单的对比学习框架,极大促进了最优的句子嵌入
- 首先使用一种无监督的方法,该方法输入语句并在对比目标中进行预测,学习过程中仅将标准dropout用作噪声
- 从通过自然语言推理(NLI)数据集学习句子嵌入的工作中汲取灵感,并通过使用“蕴含”对作为肯定词,而“矛盾”对作为硬否定词,将NLI数据集的标注对纳入对比学习——有监督
- 评估了标准语义文本相似性(STS)任务上的SimCSE,与之前的最佳结果相比,分别提高了7.9和4.6点
介绍
提出SimCSE,一个简单的对比嵌入框架,它可以从无标记或有标记的数据中产生更好的句子嵌入
无监督SimCSE只是简单地根据dropout预测输入句子本身,如图1a
- 同一个句子传递给预训练的BERT两次——dropout两次——获得两个不同的嵌入作为“正对”(
positive pairs) - 把同一个batch中的其他句子作为“否定”(
negatives),模型预测negatives中的positive
- 同一个句子传递给预训练的BERT两次——dropout两次——获得两个不同的嵌入作为“正对”(
有监督SimCSE建立在使用自然语言推理(NLI)数据集进行句子嵌入的基础上,在对比学习中加入了注释句子对,如图1b
- 以前的工作将NLI视为一个3分类任务(蕴涵、中性和矛盾),而本文利用了蕴涵对可以自然地用作正实例的事实,本文还发现,添加相应的矛盾对作为硬否定(
hard negatives)可以进一步提高性能
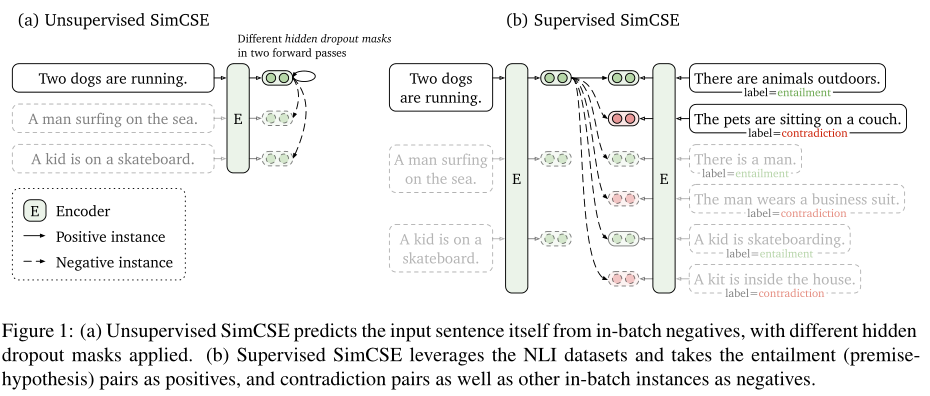
- 以前的工作将NLI视为一个3分类任务(蕴涵、中性和矛盾),而本文利用了蕴涵对可以自然地用作正实例的事实,本文还发现,添加相应的矛盾对作为硬否定(
背景:对比学习
对比学习旨在通过将语义上相近的邻居拉在一起并推开非邻居,来学习有效的表达
假设有样本对集合:$D=(x_i,x_i^+)_{i=1}^m$,其中$x_i$与$x_i^+$在语义上近似。令$h_i$和$h_i^+$表示$x_i$与$x_i^+$的表达,则一个batch(batchsize为N)的训练目标为:
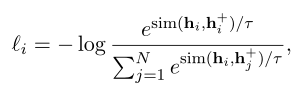
- 其中$\tau$为温度超参数,$sim(h_1,h_2)$为余弦相似度
- 本文工作中,通过BERT或RoBERTa对输入句子encode,然后使用上面的对比学习公式作为损失函数,微调所有参数
对比学习中的一个关键问题在于如何构建正例对,即构建$x_i,x_i^+$,这里可以直接利用两次输入同一个句子(利用dropout机制)来构建;其他的构建方法包括,使用dual-encoder将当前句子和下一个句子(例如问答)构建为一个正例对
无监督SimCSE
取一组句子$(x_i)_{i=1}^m$,令$x_i^+=x_i$。关键在于使用dropout来获得二者不同的encode表达,由于dropout的概率问题,每次dropout(记为$z,z’$)将mask不同的信息:
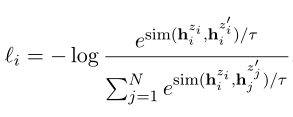
本文对比了其他的数据扩充方法,如剪裁、单词删除和替换,但发现没有一个离散的方法的性能,会优于使用dropout noise
本文还将该训练目标和“An efficient framework for learning sentence representations”的训练目标做了对比,本文的效果更好
有监督的SimCSE
这里使用有监督的NLI(自然语言推理)数据集进行训练。数据集中,一条数据表示为:sentence1,sentence2,label(蕴含、中立、矛盾)
直接从监督数据集中获取$(x_i,x_i^+)$
- 对比了多个有监督的数据集,NLI数据集效果更好
- 选择label为蕴含的两个句子作为正例对
进一步利用NLI数据集:
NLI数据集中,给定一个句子,通常会有三个相关句子和对应的label(蕴含、中立、矛盾)
取label为蕴含的sentence2为正例$x_i^+$,取label为矛盾的sentence2为负例$x_i^-$,此时一个batch内的训练目标
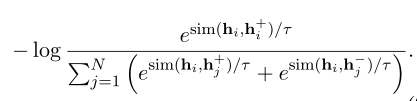
本文还考虑在SimCSE中使用dual-encoder框架,但性能更差
实验结果
Sentence embedding在STS任务中的表现
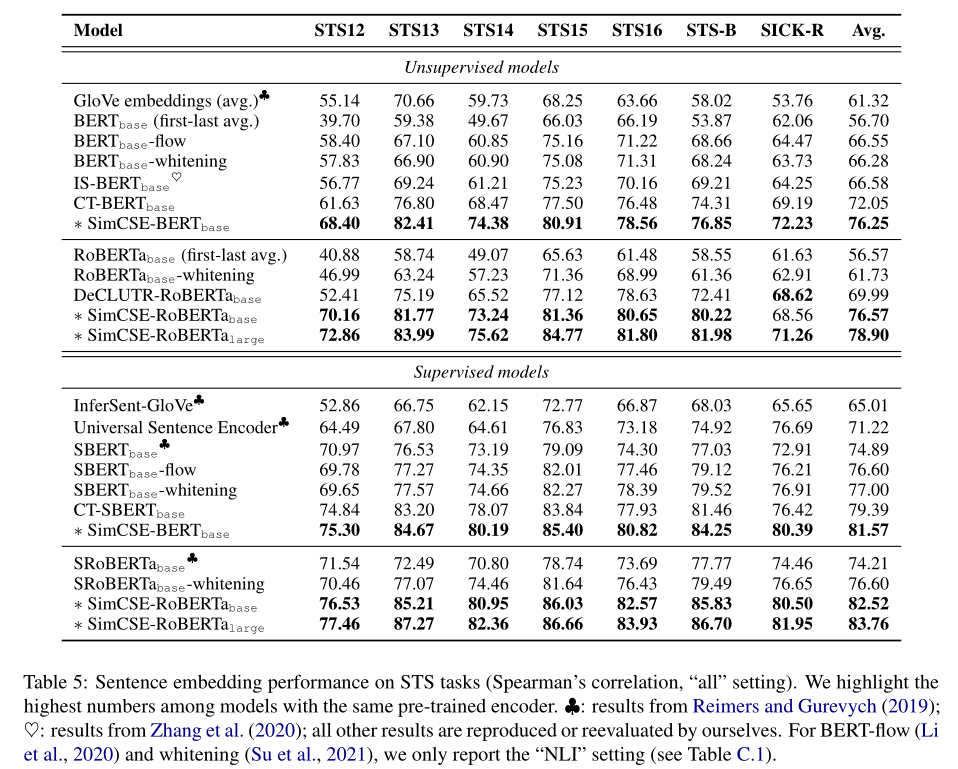
结论
- 提出SimCSE,大大提高语义文本相似性任务的句子嵌入性能
- 本文的对比目标(训练目标),尤其是无监督目标,可能在自然语言处理中有更广泛的应用。它为文本输入的数据扩充提供了一个新的视角,并可以扩展到其他连续表示和集成在语言模型预训练中
关键代码(loss计算)
无监督
collator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class CSECollator(object):
def __init__(self,
tokenizer,
features=("input_ids", "attention_mask", "token_type_ids"),
max_len=100):
self.tokenizer = tokenizer
self.features = features
self.max_len = max_len
def collate(self, batch):
new_batch = []
for example in batch:
for i in range(2):
# 每个句子重复两次
new_batch.append({fea: example[fea] for fea in self.features})
new_batch = self.tokenizer.pad(
new_batch,
padding=True,
max_length=self.max_len,
return_tensors="pt"
)
return new_batchloss计算
1
2
3
4
5
6
7
8def compute_loss(y_pred, tao=0.05, device="cuda"):
idxs = torch.arange(0, y_pred.shape[0], device=device)
y_true = idxs + 1 - idxs % 2 * 2
similarities = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=2)
similarities = similarities - torch.eye(y_pred.shape[0], device=device) * 1e12
similarities = similarities / tao
loss = F.cross_entropy(similarities, y_true)
return torch.mean(loss)有监督(不需要double输入)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51class SimcseModel(nn.Module):
"""Simcse有监督模型定义"""
def __init__(self, pretrained_model: str, pooling: str):
super(SimcseModel, self).__init__()
# config = BertConfig.from_pretrained(pretrained_model) # 有监督不需要修改dropout
self.bert = BertModel.from_pretrained(pretrained_model)
self.pooling = pooling
def forward(self, input_ids, attention_mask, token_type_ids):
# out = self.bert(input_ids, attention_mask, token_type_ids)
out = self.bert(input_ids, attention_mask, token_type_ids, output_hidden_states=True)
if self.pooling == 'cls':
return out.last_hidden_state[:, 0] # [batch, 768]
if self.pooling == 'pooler':
return out.pooler_output # [batch, 768]
if self.pooling == 'last-avg':
last = out.last_hidden_state.transpose(1, 2) # [batch, 768, seqlen]
return torch.avg_pool1d(last, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]
if self.pooling == 'first-last-avg':
first = out.hidden_states[1].transpose(1, 2) # [batch, 768, seqlen]
last = out.hidden_states[-1].transpose(1, 2) # [batch, 768, seqlen]
first_avg = torch.avg_pool1d(first, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]
last_avg = torch.avg_pool1d(last, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]
avg = torch.cat((first_avg.unsqueeze(1), last_avg.unsqueeze(1)), dim=1) # [batch, 2, 768]
return torch.avg_pool1d(avg.transpose(1, 2), kernel_size=2).squeeze(-1) # [batch, 768]
def simcse_sup_loss(y_pred: 'tensor') -> 'tensor':
"""有监督的损失函数
y_pred (tensor): bert的输出, [batch_size * 3, 768]
"""
# 得到y_pred对应的label, 每第三句没有label, 跳过, label= [1, 0, 4, 3, ...]
y_true = torch.arange(y_pred.shape[0], device=DEVICE)
use_row = torch.where((y_true + 1) % 3 != 0)[0]
y_true = (use_row - use_row % 3 * 2) + 1
# batch内两两计算相似度, 得到相似度矩阵(对角矩阵)
sim = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=-1)
# 将相似度矩阵对角线置为很小的值, 消除自身的影响
sim = sim - torch.eye(y_pred.shape[0], device=DEVICE) * 1e12
# 选取有效的行
sim = torch.index_select(sim, 0, use_row)
# 相似度矩阵除以温度系数
sim = sim / 0.05
# 计算相似度矩阵与y_true的交叉熵损失
loss = F.cross_entropy(sim, y_true)
return loss
是否可以替代rdrop中的kl-loss?

