《Targeted Online Password Guessing》(CCS 2016)
摘要
- 有针对性的在线猜测,即攻击者利用受害者的个人信息,猜测特定受害者的服务密码
- 一个关键挑战是选择最有效的候选密码,而服务器锁定或限制机制允许的猜测次数通常非常少
- 提出TarGuess框架,使用七个数学模型,系统地描述典型的目标猜测场景,每个模型都基于攻击者可用的各种数据
- 在10个大型密码数据集上的实验表明了TarGuess的有效性
- TarGuess I∼IV捕获了四个最具代表性的场景,并且在100个猜测中:
- TarGuess-I在对安全性要求较高的用户方面比最主要的同类产品高142%,对普通用户则高46%
- TarGuess-II在对安全性要求较高的用户方面比最主要的同类产品高169%,对普通用户则高72%
- TarGuess-III和IV对普通用户的成功率超过73%,对安全性较高的用户的成功率超过32%。并且TarGuess-III和IV,在给出姊妹密码和部分PII(个人验证信息)时,第一次实现跨站点在线猜测,
介绍
- 一些概率猜测模型已经提出,如Markov n-grams和概率上下文无关文法(PCFG),描述了一个离线猜测攻击者的特征。攻击者主要处理泄漏的密码文件,目的是破解尽可能多的帐户
- 离线猜测攻击,无论是拖网式攻击还是有针对性的攻击,仅在非常有限的情况下才引起真正的关注:服务器的密码文件被泄漏,泄漏未被检测到,并且密码也被适当地哈希
- 网站应该通过安全地存储密码文件来保护用户密码不被离线猜测,而普通用户只需要选择能够在抵抗在线猜测的密码
- 任何使用浏览器的人都可以随时针对公开服务器启动在线猜测,主要限制是允许的猜测次数
- 密码选择不同
- 用户的PII具有高度的异构性
- 用户用多种转换规则来改变密码
- 规则优先级不确定
- 转换规则的选择常取决于上下文,因此上下文依赖性需要一个自适应的、语义感知的跨站点猜测模型
相关工作
- 已有的跨站点破解算法,以及预测同一账户的未来密码算法,他们对于有针对性的在线猜测不是最优的
- 不涉及重用行为或用户PII的常用密码
- 假设所有用户以固定的优先级使用转换规则
- 算法没有考虑综合规则
- 是启发式的算法
- PCFG算法是基于长度的PII匹配和替换方法,它在捕捉用户PII使用方法上是不准确的,而TarGuess-I通过使用基于类型的PII匹配方法克服了这个问题
贡献
- 提出了TarGuess,一个用可靠的概率模型(而不是特别模型或启发式)来描述典型的有针对性的在线猜测攻击的框架。TarGuess针对七个典型的场景,每个场景中攻击者使用信息组合不同
- 四种概率算法。算法都明显优于现有技术,并可应用于七个典型场景
- 广泛的评估。进行了一系列的实验来证明算法的有效性和通用性。绝大多数用户的密码容易受到有针对性的在线猜测的影响
- 新见解。
- 简单地将多种PII合并到算法中不会提高成功率
- 基于类型的PII标记比基于长度的PII标记更有效
- 猜测的成功率随着猜测列表中该猜测的等级的增加而降低
前提条件与安全模型
公开的个人信息
- 用户的个人信息是“与”这个用户相关的任何信息,比PII(个人识别信息)更广泛
- 用户个人信息分为三类,每一类信息都有不同程度的保密性
- 第一类:用户PII(例如,姓名和性别)。在本地半公开,对陌生人不公开
- Type-1:可以是密码的构建块
- Type-2:如性别和教育,可以影响用户创建密码的行为,但不直接用于密码
- 第二类:用户身份凭证。部分(如用户名)公开,部分(如密码)专用
- 第三类:剩下的用户个人资料
- 第一类:用户PII(例如,姓名和性别)。在本地半公开,对陌生人不公开
安全模型
- 主要研究客户-服务器体系结构
- 三个实体参与了有针对性的在线猜测攻击:用户U、身份验证服务器S和攻击者A
- S强制执行安全机制,例如可疑登录检测和锁定——A的猜测次数有限
- 假设A可以获得所有公共信息(如泄漏的PW列表和站点策略)
- 只考虑A最多有一个用户U的姊妹密码的情况——54756万个泄露密码帐户中,少于1.02%的账户以电子邮件用户名为依据进行多次匹配;另一份796万个账户中,只有152人(0.00191%)通过电子邮件进行了多次匹配
密码创建
数据集
- 五个来自中文网站,五个来自英文网站,它们已被泄漏
- 两个数据集包含各种类型的PII
- 采用两个辅助PII数据集,以通过邮件匹配来增强密码数据集
- 语料库是迄今收集到的最大最多样化的语料库
广泛使用的密码
- 下表显示了来自不同服务的用户选择常用密码的频率。通过选取前十个密码,可以猜出0.79%∼10.44%的密码

- 语言和服务在塑造用户最受欢迎的密码方面都扮演着重要的角色
- 通过数据集分析得出:
- 000webhost强制执行密码创建策略,要求密码同时包含字母和数字
- csdn要求密码长度至少为8
密码重用
- 通过匹配电子邮件,将12306与Dodonew两个数据集相交,得到新的数据集。其中每个用户有两个密码。以此得到2个相交的中文数据集,三个相交的英文数据集
- 利用Levenshtein距离度量来度量给定用户的两个不同密码之间的相似性;最长公共子序列进行度量,得到的结果相似
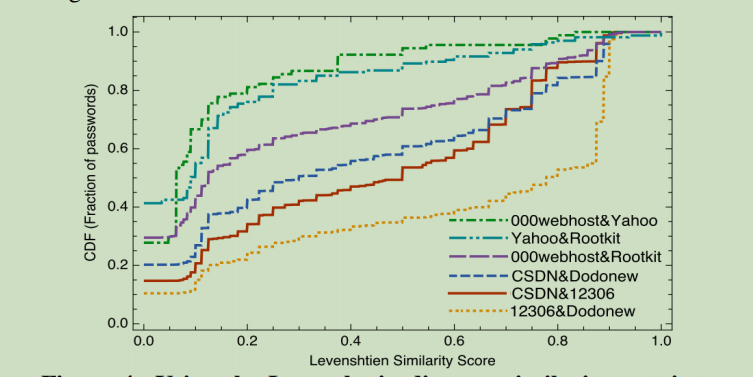
- 中文用户的姊妹密码比英文用户具有更高的相似性——英文的两个网站是程序论坛,因此他们的重复使用较少
- 修改后——一般的中英文用户具有相似的重用行为
密码包含的个人信息
- 高度异构的PII成为密码的组成部分,用户喜欢使用名称、生日及其变体
- 一部分用户只使用自己的全名(0.75%∼1.87%)作为密码,1.00%∼5.16%的中国用户只使用自己的生日作为密码
- 电子邮件和用户名在密码中都占主导地位,分别为0.77%到5.07%和0.54%到2.34%
- Type-2 PII的影响:
- 年龄≤24岁和年龄≥46岁的用户的密码具有非常相似的长度分布
- 女性用户的密码更为集中
- 基于类型的PII匹配
- 在传统的基于PCFG的L,D,S标签外,还使用了几种PII标签(例如,N代表姓名,B代表生日)
- 不同标签的下标表示一种特性的子类型,如生日年份等
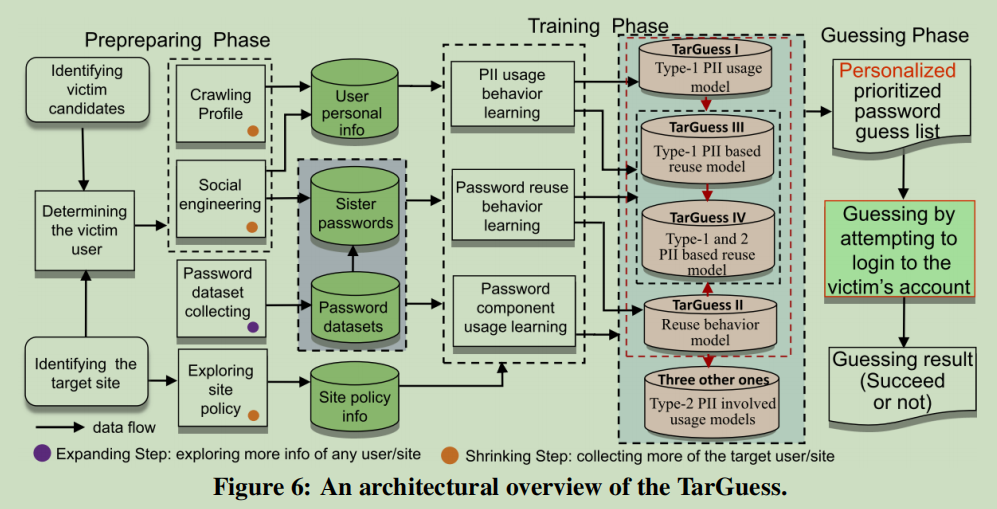
TarGuess框架
- 攻击者获得的信息:
- I 只有Type-I PII
- II 一个姊妹密码
- III I和II的结合
- IV III和Type-II PII
- 对应的四种模型利用了概率的知识,如PCFG、Markov和Bayesian理论
TarGuess-I
- 密码的组成除了L(letter),D(digit),S(symbol)外——love@123,记为L4S1D3——引入基于类型的PII标签,如N1表示全名,N2表示名字的缩写等
- PII的上下文无关文法的扩充:G = (V, Σ, S’, R)
- S’是开始符号
- V是标签
- N:
- N3为姓
- N4为名
- N5为名的首字母+姓
- N6为姓+名的首字母
- N7为姓,且姓的首字母大写
- B:
- B1为出生年月日
- B2为出生月日年
- B3为出生日月年
- B4为出生月日
- B5为出生年
- B6为出生年月
- B7为出生月年
- B8为出生年份后两位+出生月日
- B9为出生月日+出生年份后两位
- B10为出生日月+出生年份后两位
- A是账户名
- A1为用户名
- A2为用户名的字母部分
- A3为用户名的数字部分
- E是电子邮件地址
- E1为完整邮件地址
- E2为邮件地址的字母部分
- E3为邮件地址的数字部分
- P是手机号
- P1为完整手机号
- P2为手机号前三位
- P3为手机号后四位
- N:
- Σ为可打印的95个ASCII码,以及空串
- R是产生规则
- 为了提高准确性:
- 使用最长前缀规则进行匹配,并且只考虑长度不小于2的PII段——john06071982 匹配到用户名 “john0607”,则分作A1B5而不是N3B2
- 只考虑月日都为两位数的表示形式,因此如果发现缩写,则先补全再查找对应标记
- 当给定该用户的电子邮件、帐户名、姓名、生日、电话号码和NID时,平均破解概率为20.26%。电子邮件、帐户名、姓名和生日对在线攻击者来说是非常有价值的
- Personal PCFG比TarGuess-I’多利用了两个PII属性,但效果要差得多——简单地将更多的PII信息合并到算法中并不一定会产生更好的效果。
TarGuess-II
- 根据姊妹密码猜测:
- 可猜测次数少
- 转换种类多
- 使用两个密码列表作为训练集,一个从类似目标站点的策略/服务泄漏的PWA,另一个是与姐妹密码相似的PWB。在这两个列表中通过匹配电子邮件查找相同的用户。这一步骤创建了一个新的不重复的姊妹PW对{PWA,PWB}列表,测量如何从PWA修改PWB
- 从各种泄漏的列表中为目标服务建立一个10000项的列表,以确定PWB的较高概率的形式。L={pw |len(pw)≥ 8 and the value of Pcsdn(pw) ∗ P126(pw) ∗ Pdodonew(pw) ranks top-10000}
- TarGuess-II的训练阶段,首先要确定PWB∈L
- 属于:PWB∈L的出现次数加1
- 不属于:先进行结构级训练,再进行字段级训练
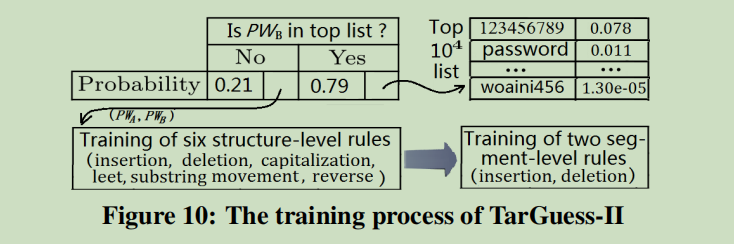
转换的规则:
- 结构级
- 将PWA解析为解析具有L,D,S标签的密码
- 六种结构级转换规则:
- 插入(例如,L3D3→L3D3S2)
- 删除(例如,L3D3S2→L3D3)
- 大写字母(C)
- leet(L)
- 子串移动(SM)(例如,abc123→123abc)
- 反向(R)(例如abc123→321cba)
- 字段级
- 插入
- 删除
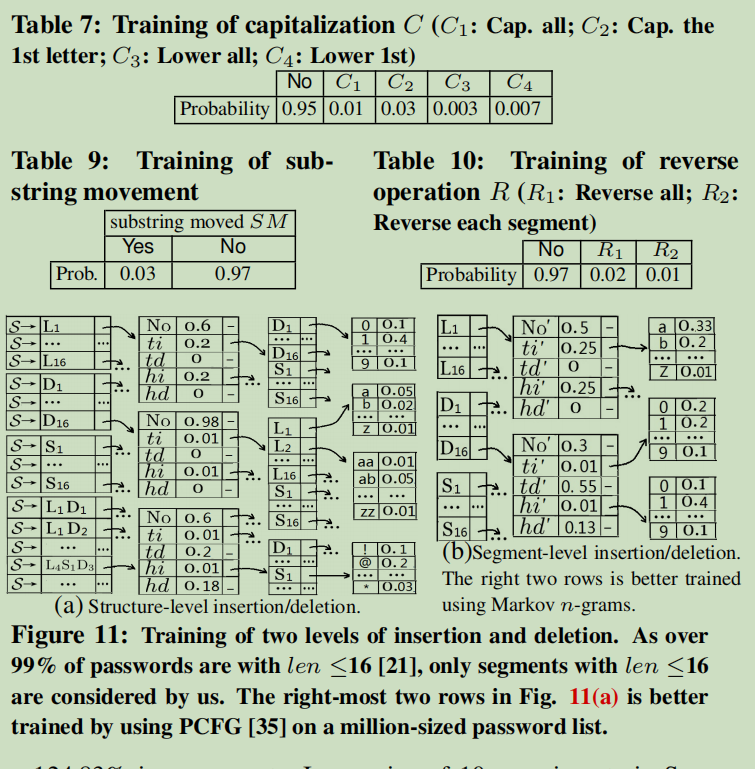
结构级训练
- 使用Levenshtein距离(LD)算法(仅启用插入和删除)来测量PWA和PWB之间的相似性1
- 其他四种的流行顺序:C>L>SM>R
- 以C,L,R,SM顺序来基于PWA获得PW’A
- 计算d2 = LD(PW’A,PWB)。如果d2> d1,则将这样的规则称为“有效”规则,然后将PWA更新为PW’A,对应规则的出现次数+1。在PW’A上执行下一条规则以产生PW’’A,并计算d3 = LD(PW’’A,PWB)。如果d3> d2,则此规则“有效”并计数。
- 假设最终获得PW’’A
- 若LD(PW’’A,PWB)小于某一个设定好的阈值:取消先前的计数,训练下一个密码对
- 否则,PW’’A拆分。结构化阶段不考虑长度,因此L3D3只考虑LD。计算d3=LD(“LDS”,“LS”),并返回一个创建过程
字段级训练
- 使用LD度量来度量它们各个字段的相似性
- 与结构级训练一样,LD度量用于更新图11(b)中所有对应规则的出现
GII文法
- GII是一种概率上下文无关语法
- GII类似于G,不同的是V代表L,D,S,和一些规则
当给出用户的Dodonew密码时,Das等人的算法在100次猜测中,对用户的CSDN帐户密码猜测的成功率为8.98%,而TarGuess-II的成功率为20.19%
TarGuess-III
- TarGuess-III旨在利用用户的一个姐妹密码和一些PII,在线猜测用户的密码
- 将基于PII的标记(TarGuess-I中)引入到TarGuess-II的语法GII中,使得TarGuess-III可以实现这一目标
- 所有基于PII的密码段,只涉及GII中定义的六种转换规则,GIII中的所有其他内容与GII中的相同
- 因此,GIII可以将Alice1978Yahoo解析为N4B5W1,即生成猜测Alice1978eBay的概率最高
TarGuess-IV
主要的挑战是,不能使用任何基于PII标签的PCFG语法或Markov n-gram直接测量Type-2 PII
定理:
令pw表示由用户U为服务选择密码pw的事件,pw’表示由U为另一项服务选择密码pw’并被泄露的事件,Ai(i = 1,2,…,n) 表示一种用户PII属性,包括Type-1和Type-2。 假设A1,A2,…,An是相互独立的,并且在事件pw’和(pw,pw’)下它们也相互独立。我们有:
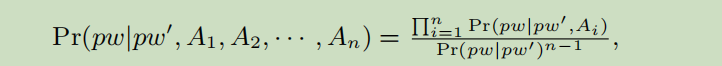
定理表明,在给定用户U的PII信息A1,A2,…,An和另一服务下的姊妹密码pw’时,可以通过“分而治之”来解决在一个服务上预测用户U的pw的问题
当Ai为Type-1 PII时,可以使用TarGuess-II计算Pr(pw | pw’),可以使用TarGuess-III获得Pr(pw | pw’,Ai)
Ak是Type-2 PII时计算Pr(pw | pw’,Ai)
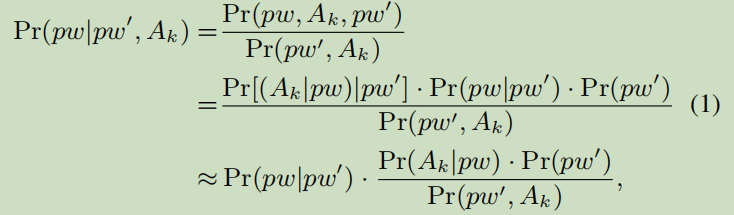
- 使用TarGuess-II计算Pr(pw | pw’)
- Pr(pw’,Ak)= c1是一个常数,Pr(pw’)= c2是一个常数,因为当攻击用户U时事件(pw’,Ak)和(pw’)是已知的固定事实
- Pr(Ak | pw)可以通过对训练集进行计数来计算——密码pw是根据具有属性Ak的用户比例来选择的
某些PII属性在本质上是相互依赖的(例如,生日与年龄)。但大多数给出的PII属性彼此独立,定理的实用性不会受到太大影响
以往未考虑的Type-2 PII,确实会对攻击者A有帮助
其他三种场景
攻击者拥有:
Type-2 PII
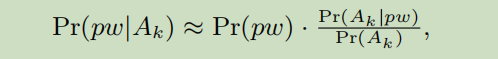
- Pr(Ak)是常数,其他两项在训练集中计数获得
Type-1 PII + Type-2 PII
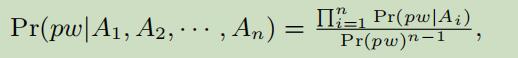
- Pr(pw|Ai)可由TarGuess-I(为Type-1 PII)或前一个场景的公式(为Type-2 PII)获得
一个姐妹密码 + Type-2 PII
- TarGuess-II生成猜测列表
- 根据定理调整猜测概率
多个姐妹密码
- 以上模型不能解决
多个姐妹密码 + 一些PII
- 以上模型不能解决
实验
- 9个待评估的算法:
- TarGuess-I∼IV
- Markov[21]、
- PCFG和Personal PCFG
- Das等人的算法
- Trawling optimal
- 使用电子邮件地址对原始数据集进行处理,获得10个实验场景,并获得训练数据集
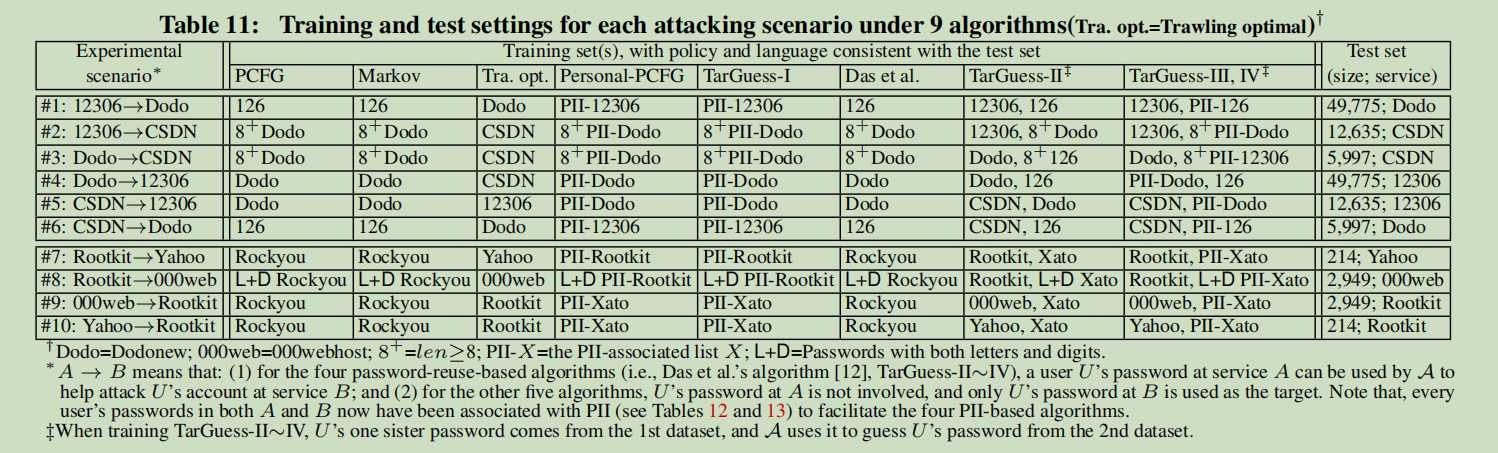
- 对给定测试集(攻击场景)的训练集的选择遵循三个规则:
- (1)它们从不来自同一服务
- (2)它们具有相同的语言和密码策略
- (3)训练集应尽可能大
实验结果
- 这十个实验中,每一个实验的训练阶段都可以在不到65.3秒的时间内在一台普通PC机上完成,而每个用户1000个猜测的生成时间不到2.1秒
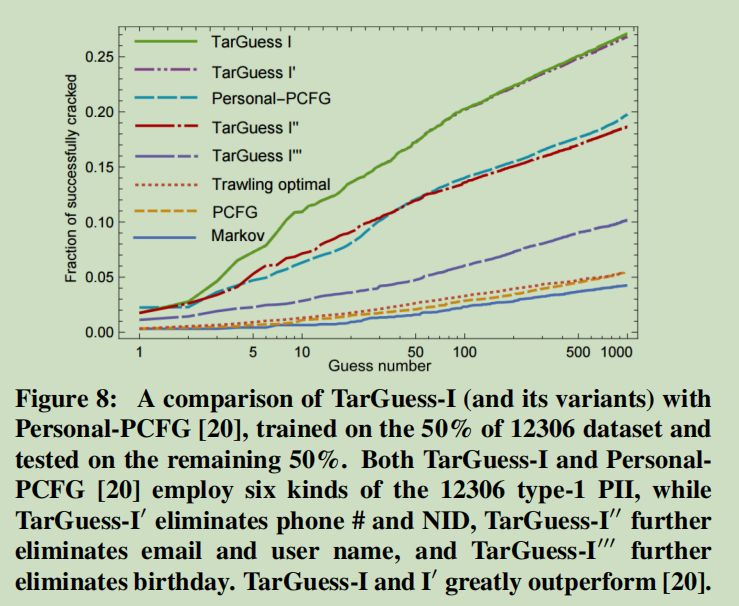
- TarGuess-I显著优于Personal-PCFG
- TarGuess-II性能优于Das等人的算法
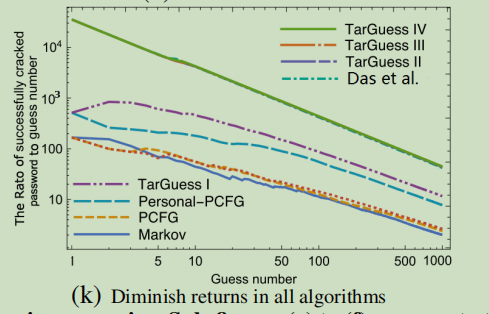
- 攻击中国用户时,TarGuess-III和IV的成功率分别为73.09%和31.61%
- 随着猜测次数的增加,在大多数情况下,TarGuess-I∼IV的优势进一步增强
- TarGuess IV,可以利用受害者的一个姐妹密码以及1型和2型PII启动跨站点猜测
- 三种猜测算法:拖网,有针对的使用PII,有针对的使用姐妹密码,均有一个递减的原则:如果收益不超过它的成本,攻击者A在某一点上停止攻击,并且会有三个这样的点对应于三种不同的攻击策略
进一步验证
- 测试集是纯文本的,破解小米云密码进一步验证
- 验证集包含5284个小米散列,这些散列是使用电子邮件将8M小米数据集与130K 12306数据集匹配后获得的
- 在10∼1000次猜测中,TarGuessI的性能优于Personal-PCFG 70.58%∼119%;TarGuessII的性能优于Das等人的算法73.66%∼405%;TarGuess III和IV的成功率为63.61%∼73.56%。
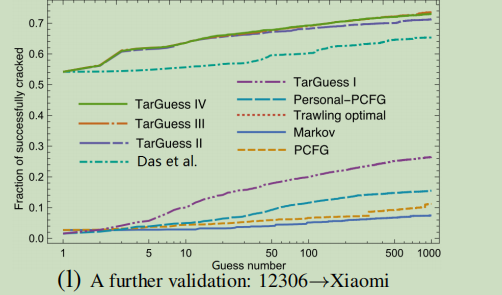
- 当姐妹密码可用时,TarGuess-IV对正常用户的破解成功率可以达到77%(100次猜测里);即使姐妹密码不可用,TarGuess-I对正常用户的成功率仍然可以达到20%(100次猜测里)
结论
- TarGuess-I~IV描述了4种最具代表性的场景,并且首次很好地解决了如何建模上下文感知、语义丰富的跨站点密码猜测攻击的问题
- 目前使用的安全机制在对付有针对性的在线猜测威胁方面基本上是无效的

