《Understanding Password Choices : How Frequently Entered Passwords are Re-used Across Websites》(SOUPS 2016)
摘要
- 将自我报告调查结果与六周内从134名参与者收集的实际在线行为的测量结果相结合
- 人们确实倾向于在1.7-3.4不同的网站上重复使用每个密码
- 倾向于重复使用必须频繁输入的密码
- 用户可以通过在网站上选择一个复杂的密码来应对记忆多个密码的问题
介绍
- 用户认为,他们重复使用的主要是他们认为很强的密码
- 分析了一个数据集,该数据集测量web帐户实际密码的使用和重复使用情况
- 捕获了134个受试者的Web浏览器在大约六周内发生的密码输入事件
- 研究期间调查了同样的受试者,收集与密码相关的自我报告的统计特征、态度和意图
- 怀疑频繁输入密码是记忆强密码的一种方式
- 用户使用特定密码进行身份验证的频率与他们在其他帐户上重复使用该密码的程度有关
1
how often a user is forced to authenticate with a particular password is related to how much they re-use that password on other accounts.
相关工作
密码创建与管理
- 以往研究发现:受试者有9到51个账户,中位数为27;人们每天使用大约12个账户
- 一般而言,建议用户创建对每个帐户都是唯一的和随机的密码
- 对大多数人来说,创建密码主要目标是让密码容易记住,身份验证是次要的任务
- 记忆密码比其他存储密码的机制更为常见,如在浏览器中保存密码、使用密码管理软件、或在电子文件或纸张上记下密码
密码强度和抗猜测能力
- 受试者相信,在他们已经在其他地方使用的密码中添加一个数字或符号,会使密码更强大、更安全
- 传统上,密码强度是用Hartley熵来衡量
- Hartley熵大多测量复杂性,在涉及到离线猜测攻击时并不是一个很好的目标密码强度测量方法
- 熵和猜测阻力的测量方法不同。熵没有考虑到用户的密码创建选择中存在非随机模式
- 密码合成策略可能会增加熵,但坚持合成策略并不能保证抵抗猜测
密码重用
- 人们称,在低重要性帐户上更多地重复使用密码,而在更需要安全性的高重要性帐户上则避免重复使用密码
- 可以使用一个通用的密码列表和在“较低级别”帐户条件下创建的受试者密码,有33%的可能在一定时间内成功猜测其“较高级别”帐户条件密码
研究问题
- 密码重用
- 文献中关于人们更经常重复使用哪些密码的结果是矛盾的
- 大多数涉及重复使用的密码数据都是来自用户研究的自我报告——更频繁使用弱密码
- 在实验中,受试者创建的口令密码强度没有差异
- 本文的研究中,收集了特定个体数的数据——可以检查哪些密码被特定的个人重用,以及频繁输入的密码被重用的不同帐户的数量
- 人们更多地重用他们的强密码,还是弱密码?
- 人们重复使用频繁输入的密码比不经常输入的密码多?
- 密码意图
- 本文研究中,收集了关于个人行为的日志数据和询问其意图的调查数据,可以将用户对密码的看法与密码强度联系起来
- 人们对他们创建的密码的看法是否与他们实际密码的特征相关?
- 人们更多地重用哪些密码?
方法
数据收集和受试者
- 受试者在个人电脑和网络浏览器上安装自定义日志数据收集软件,平均持续时间为6周,并在数据收集期开始和结束时进行调查
- 数据收集软件包括一个用于Google Chrome和Mozilla Firefox的web浏览器插件
- 插件记录了web浏览器访问的所有url,以及web页面上的任何表单提交
- 插件还记录了所有与安全相关的设置,并记录了所有已安装和/或正在运行的插件(扩展)的信息
- 当用户处于私人浏览模式(Firefox)或匿名模式(Chrome)时,插件没有记录任何内容
- 服务器的所有连接都经过加密以保护用户隐私
- 表单提交中检测到password HTML元素时,记录
- 输入密码时,用户输入的是哪个网页
- 输入的是哪个密码
- 每个密码的强度
- 对密码哈希——在不知道每个受试者的实际密码的情况下,在不同的网站上检查哪些密码被每个受试者重复使用
- 一所大型大学招募了学生,要求注册官通过电子邮件随机抽取学生样本
- 收到了134名受试者的可用数据
结果
密码重用描述
- 受试者平均访问了5613个网页,平均每天访问118个网页
- 将网页按域名分组到网站中。受试者在17.5个不同网站中输入密码
- 研究对象倾向于在多个网站上重复使用相同的密码——114名受试者(85%)的唯一密码比他们输入密码的网站少
- 可能正确的密码
- 用户可能在一个网站中输入多个密码;尝试根据一段时间的使用模式来识别哪个密码可能是正确的
- 给定的网站中输入最频繁的密码可能是正确的密码
- 选择在较大天数内使用的密码
- 选择该用户在其他网站上使用最多的密码(重复使用假设)
- 密码强度
- 数据收集软件在哈希密码并记录哈希之前,为每个密码计算一个标准熵度量
- 这里,熵并不是精确地衡量一个给定密码的抗破坏能力,而是在不同人群和不同网站比较同一个人创建和使用的密码
- 只考虑可能正确的密码,那么样本的平均熵是49.5
- 密码特性
- 从记录的熵值中反向工程密码的字符
- 对于每个可能的字符集大小,都可以计算一个估计的密码长度
- 平均受试者使用长度为8.98的密码,使用2.29个不同的字符集(小写字母、大写字母、数字、基本符号、扩展符号)
- 发现本研究的受试者经常使用更复杂的密码
- 参考文献A large-scale study of web password habits.
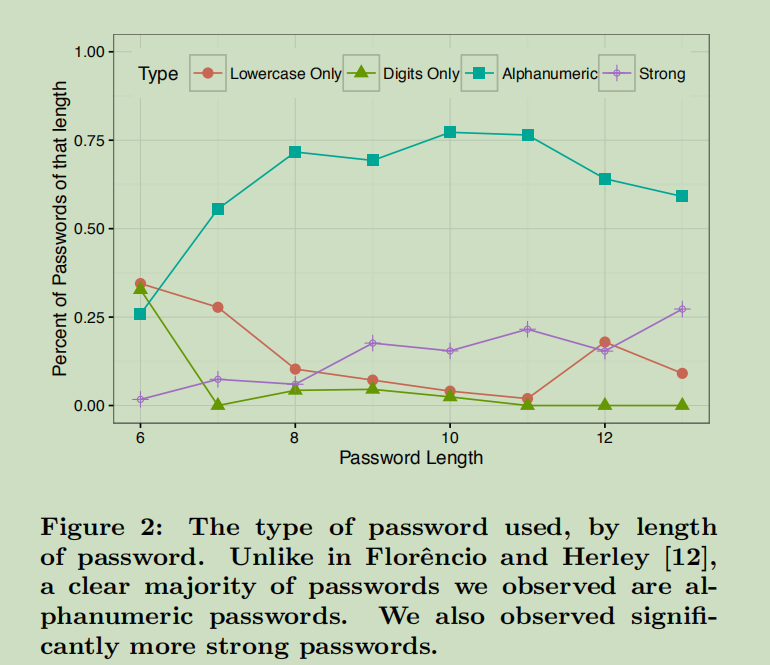
人们重用什么样的密码
在确定哪个密码可能是正确的时,做了一个重复使用的假设:在同样经常使用的密码中,在大多数其他网站上使用的密码最有可能是正确的——每个密码在3个网站上使用
重复使用强密码
密码熵与输入密码的网站数量之间存在0.063的相关性(p=0.007)。这种积极的,统计上显著的相关性表明,一个受试者的强密码是被重复使用的
将密码熵和个人的密码排名放在同一个回归中,但密码熵和密码排名高度相关(r=-0.628),在同一回归模型中包含两个预测因子可能导致共线性问题——运行了三个独立的多层次线性回归模型:一个具有熵的模型,一个具有排名的模型,以及一个同时具有熵和排名的模型
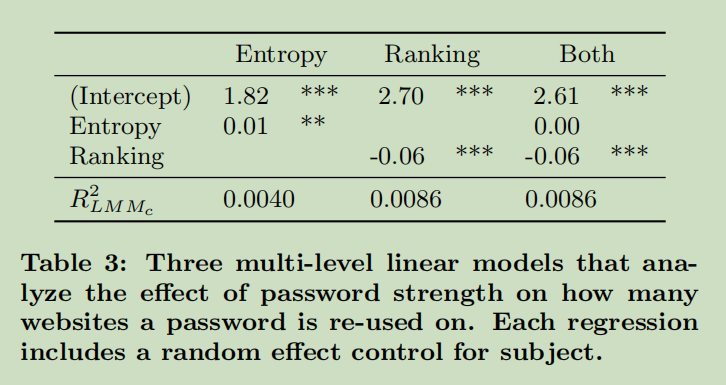
个人排名比绝对熵更能预测密码重复使用
人们正在重新使用他们认为的最强大的密码,但不一定是客观上强大的密码
重复使用频繁输入的密码
密码被输入的次数,除以使用密码的网站数量,得到密码被输入到任何一个网站的平均次数
运行额外的回归来检查受试者是否重复使用了频繁输入的密码——输入频率越高的密码被重复使用的可能性就越大

中间列的logistic回归生成的密码被重用的概率的图形
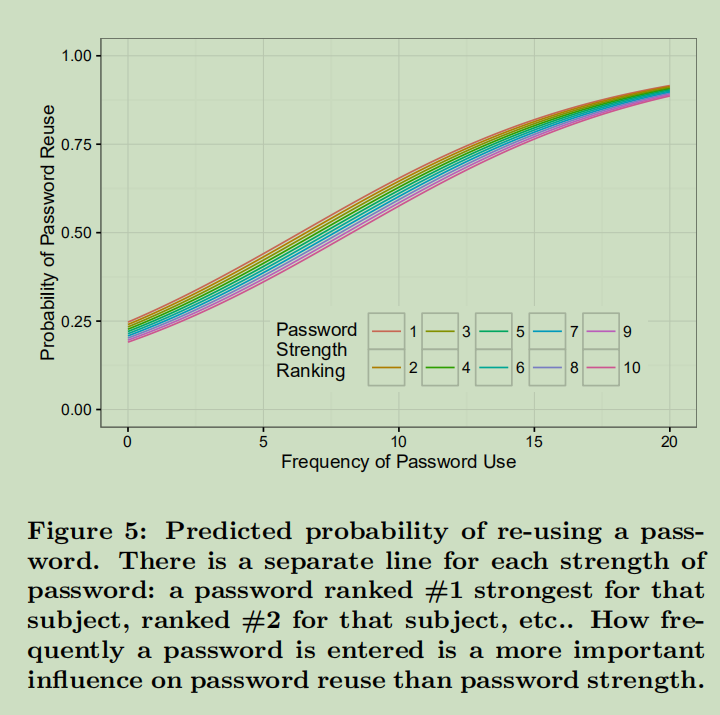
重复使用大学密码
密码管理器不影响重复使用
- 无法识别浏览器内置的密码保存功能何时填写密码,但插件记录了研究期间在每个受试者的web浏览器上安装和/或启用的所有插件
- 运行密码管理器的受试者使用的密码比不使用密码管理器的受试者使用的复用密码多0.02个网站,这种差异在统计学上并不显著
- 无法判断这是否是因为许多受试者正在使用内置于web浏览器中的密码保存功能
人们从其他帐户猜测密码
- 识别出相当确定是错误猜测的密码条目
- 在网站上只输入一次的密码
- labeled as incorrect any password entered into a website less than half as often or on less than half as many days as the password we identified as correct
- 识别出相当确定是错误猜测的密码条目
人们自报密码使用是否准确?
人们了解密码强度
- 当人们自我报告说他们打算使用好的密码时,他们的密码会更强大,但只是稍微强一点
- 意图/行为链接的更详细的回归结果如下

人们自我报告什么?
- 自我报告是否“使用好密码”时,他们在想什么密码?
- 第一行:使用好密码的意图是否与受试者拥有的最强密码相关
- 第二行:是否与最弱密码相关
- 第三行:是否与平均熵的相关
- 第四行:是否与每个不同帐户上使用的密码平均强度的相关
- 第五行:是否每次输入密码时都会考虑密码强度

- 受试者并不认为特定密码是最强或最弱的密码;相反,当受试者回答这个问题时,他们可能会考虑他们拥有帐户的所有网站,并查看这些密码的平均强度
人们也了解密码的重复使用
局限
- 结果可能不适用于更广泛的人群
- 可能不会捕获所有密码输入事件
- 不能区分成功和失败的身份验证尝试——无法判断受试者在研究期间是否或何时更改了密码
- 大约六周的数据收集是不够的
讨论与结论
- 虽然密码复用的中间值为3,但每个受试者最常使用的密码平均在9个不同的网站上使用
- 倾向于重复使用他们必须频繁输入的密码,而这些密码往往是用户最强大的密码之一
- 可能存在一个实际的限制,即对大多数人能够记住的密码数量限制
- 经常使用密码登录是记住强密码的有效方法——如果用户必须在必须在频繁登录的网站上记住一个强密码,那么他们就会在其他地方重新使用它
- 大多数非专家用户相信密码强度比密码重用重要
- 从成本/效益的角度来看,一定量的重复使用实际上可能是好的
- 当人们考虑使用强密码意味着什么时,每个帐户被单独考虑,而不考虑重复使用——用户对密码强度的看法与每个不同帐户上使用的密码的平均熵最相关
- 为重复使用不同强度的密码定义适当的网站类别是一个开放的研究领域:
- 应该根据用户对信息的重视程度或攻击者获得的信息量[1]来定义?
- 根据网站在安全性方面的投资额来定义?

