《Pretrained Language Models for Text Generation: Survey》(IJCAI 2021)
摘要
- 本文概述PLM(预训练语言模型)在文本生成的主要进展
- 给出通用任务定义,简要描述用于文本生成的PLMs的主流体系结构
- 讨论如何调整现有的PLM建模不同的输入数据,并满足生成文本中的特殊属性
- 进一步总结几个重要的文本生成微调策略
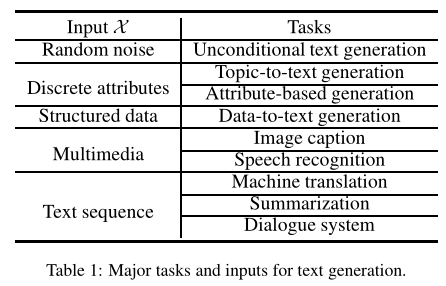
任务和典型应用
生成离散token序列$\gamma=(y_1,…,y_n)$,每个token来自字典$V$
生成任务通常受到输入$X$的约束(
conditioned on input data),即$P(\gamma|X)=P(y_1,…,y_n|X)$若不提供输入$X$,或只提供随机噪声向量$z$,则退化为语言建模或无条件生成任务[Radford, 2019],用于生成没有任何约束的文本
若$X$为一组离散的属性,如关键词、情感标签,则任务为基于主题的文本生成
若$X$为结构化的知识图、表,则任务视为从KG(
knowledge graph)到文本的生成(data-to-text)若$X$为多媒体输入,则任务视为图像字幕或语音识别
若$X$为文本序列——这是最常见的形式——主要应用为机器翻译、摘要、对话系统
文本生成的标准架构
- 几乎所有PLM都采用Transformer作为主干,主要分为两个方法
- Encoder-decoder Transformer:
- MASS [Songet 等人,2019]
- T5 [Raffelet 等人,2020]
- BART [Lewiset 等人,2020]
- Decoder-only Transformer:
- GPT [2019]
- CTRL [2019]
- 通常用于语言建模,应用单向自注意力屏蔽,每个token只能看到以前的token
- 一些模型利用仅解码器的结构来生成基于输入文本的文本,但没有独立的模块来编码输入序列——它们将输入和输出序列用一个特殊的标记(例如“[SEP]”)连接,采用了一种新的seq2seq屏蔽(UniLM),即输入句子中的每个token可以相互关注,生成的token可以关注所有输入token和之前生成的token
- seq2seq屏蔽是纯解码器PLMs解决条件生成任务的一种方式,类似于编码器-解码器架构
从输入建模不同数据类型
- 讨论如何在PLM中对以下三种输入进行建模
非结构化输入
- 《Text summarization with pretrained encoders》[2019]和《Sentence centrality revisited for unsupervised summarization》[2019]采用PLMs(例如BERT)作为文本编码器,将文本压缩成低维向量,同时保留其大部分含义
- 在某些情况下,输入文本可能是由几个句子和段落组成的长文档——在句子或短段落上训练的PLM不太能够准确地建模文档中的长期依赖关系
- 《HIBERT: document level pre-training of hierarchical bidirectional transformers for document summarization》[2019]和《Unsupervised extractive summarization by pre-training hierarchical transformers》[2020]提出分层BERT来学习句子之间的交互,用于文档编码
- 为了捕捉句子间的关系,《Discourse-aware neural extractive text summarization》[2020]在BERT的基础上使用堆叠图卷积网络(GCN)来建模结构性话语图
- 许多多语言生成任务(如机器翻译)涉及多种语言,某些语言资源不足,因此,《Cross-lingual language model pretraining》[2019]提出学习跨语言的语言模型(XLMs)来进行多语言语言理解
结构化输入
- 现实场景中,很难用真实文本收集大量带标签的结构化数据进行训练
- 《Few-shot NLG with pre-trained language model》[2020]和《Few-shot table-to-text generation with table structure reconstruction and content matching》[2020]将PLM用于Few-shot环境中,实现数据到文本的生成
- 将PLM用于结构化数据时,需要考虑如何将结构化数据送到PLM中——需要适应PLMs的序列特性
- 《Investigating pretrained language models for graph-to-text
generation》[2020]和《Gpt-too: A language-model-first approach for amr-to-text generation》[2020]将用于输入的知识图(KG)和抽象含义表示(AMR)图线性化为三元组序列, - 《Few-shot knowledge graph-to-text generation with pretrained language models》[2021]引入一个额外的图形编码器来编码输入KG
- 《Investigating pretrained language models for graph-to-text
多媒体输入
- CBT《Contrastive bidirectional transformer for temporal representation learning》[2019]和《Videobert: A joint model for video and language representation learning》[2019]对视频字幕任务进行预训练,只使用基于BERT的编码器,学习视觉和语言标记序列上的双向联合分布——需要训练一个独立的视频到文本的解码器
- 《Unified vision-language pre-training for image captioning and VQA》[2020]使用共享的多层Transformer网络进行编码和解码——在两个MLM任务上对模型进行预训练(例如为seq2seq LM设计的完形填空任务)
- 受GPT生成性预训练目标的启发,《XGPT: cross-modal generative pre-training for image captioning》[2020]提出了一种跨模态预训练模型(XGPT),该模型以图像为输入,将图像字幕(
image caption)任务作为预训练阶段的基本生成任务 - 语音识别上,《Unsupervised pre-training for sequence to sequence speech recognition》[2019]提出了一种无监督的方法来预训练不成对语音和转录本(
unpaired speech and transcripts)的encoder-decoder模型。两个预训练阶段用于从语音和文本中提取声学和语言学信息
满足输出文本的特殊要求
- 不同的文本生成任务中,生成的文本需要满足几个关键属性
相关性
- 对话系统的任务要求生成的响应与输入的对话存在历史相关性
- 除了对话历史外,对应于响应类型的条件也可以被提供作为外部输入,例如响应的主题和说话人的角色
- 《Transfertransfo: A transfer learning approach for neural network based conversational agents》[2019]和《DIALOGPT : Large-scale generative pre-training for conversational response generation》[2020年]能够产生比基于RNN的模型更相关、与对话背景一致的响应
Faithfulness
- 生成文本中的内容不应与输入文本中的事实相矛盾——例如,文本摘要任务
- 《Leveraging pre-trained checkpoints for sequence generation tasks》[2020]用BERT、GPT和RoBERTa来初始化encoder和decoder,测试不同setting下的结果
- 为了提高摘要的忠实度,《Improving abstraction in text summarization》[2018]提出将解码器分解为一个检索源文档相关部分的上下文网络,和一个包含语言生成先验知识的PLM
- 《TED: A pretrained unsupervised summarization model with theme modeling and denoising》[2020]通过主题建模损失(
theme modeling loss)来微调目标域上的PLMs。主题建模模块的作用是使生成的摘要在语义上接近原文章
保序性
- 在自然语言处理领域,顺序保持表示语义单位(词、短语等)的顺序在输入和输出文本上都是一致的——例如机器翻译任务
- 提出《CSP: code-switching pre-training for neural machine translation》,从源语言和目标语言中提取词对对齐信息,应用提取的对齐信息来增强保序性
- 为了有效地增强任何语言对的保序性,提出《Pretraining multilingual neural machine translation by leveraging alignment information》,一种预训练通用多语言机器翻译模型的方法。mRASP的关键是随机对齐替换技术,它强制多个语言中相似含义的单词和短语在表示空间中被对齐
文本生成的微调策略
数据角度
- Few-shot Learning
- 许多文本生成中没有足够的带注释数据
- 常见的方法是用预先获得的参数来填充现有的模块,然后用几个、一个甚至不用例子来微调
- 例如,在多语言翻译中,一些低资源语言缺乏足够的平行语料库,XLM提出学习跨语言模型,将在高资源语言中学到的知识转化为低资源语言
- 上一节中的Few-shot learning也可以应用于数据到文本的任务
- Domain Transfer
- PLMs不能直接适应于同预训练域分布差异较大的新域
- 一个有效的解决方案是,在对PLM进行微调之前,继续针对特定数据和预训练目标训练PLM——预训练目标通常为MLM
- 在域转移中,有多种mask的方法。《Generalized conditioned dialogue generation based on pre-trained language model》[2020]提出基于TF-IDF的掩码,以选择更多条件相关的token进行掩码,从而专注于相应领域的特征
任务角度
- 提高一致性
- 通过对比学习进行微调的模型能够很好地区分一对句子是否相似,此时PLM被迫理解两个句子之间的位置或语义关系
- NSP是一种常用的判断两个输入句子是否为连续片段的方法,可应用于摘要和对话系统
- CBT在跨模态训练中提出了噪声对比度估计(NCE),以鼓励模型识别正确的视频-文本对
- 去噪自编码(DAE)以损坏的文本为输入,目的是恢复原始文本。TED 利用DAE提炼基本语义信息进行抽象摘要。XGPT尝试使用图像条件去噪自编码(IDA)对底层文本对齐进行建模,迫使模型重构整个句子
- Preserving Fidelity
模型角度
- 当对有限的数据进行微调时,很可能会出现过拟合
- 《A tailored pre-training model for task-oriented dialog generation》[2020]使用一个固定的GPT来保存在另一个微调GPT中编码的知识
- 《Distilling knowledge learned in BERT for text generation》[2020a]提出利用BERT模型(教师)作为监督,指导Seq2Seq模型(学生)以获得更好的生成
- 《Text summarization with pretrained encoders》[2019]利用两个优化器分别更新PLM和初始模块的参数,以解决两个模块之间的差异

