《Non-Autoregressive Text Generation with Pre-trained Language Models》(EACL,2021)
摘要
- 现有NAG模型的生成质量仍然落后于自回归模型
- BERT可以作为NAG模型的主干来大大提高性能
- 设计了一些机制来缓解普通NAG模型的两个常见问题:前缀输出长度的不灵活性和单个token预测的条件独立性
- 为了进一步提高模型的速度优势,提出一种新的解码策略,ratio-first,用于预先近似估计输出长度。
- 在文本摘要、句子压缩和机器翻译上测试了所提出的模型,模型明显优于现有的非自回归基线,并与许多强自回归模型取得了竞争性能
- 开源代码
介绍
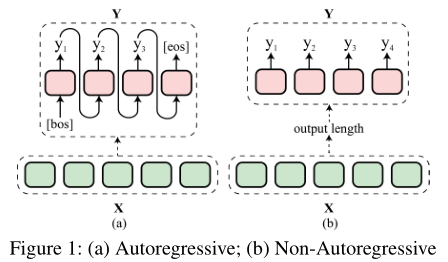
- 自回归生成模型在文本生成任务上实现了最先进的性能,这种模型以从左到右、逐个token的方式生成token序列,对下一个令牌的预测以所有先前生成的令牌为条件,这导致推理中相对较高的运行时间
- 非自回归生成(NAG)模型省略了输出端序列中的顺序依赖关系,一旦预先确定了输出长度,就可以同时预测所有位置的标记——生成质量往往落后于自回归模型
- 本文利用BERT作为NAG建模的主干,利用CRF输出层扩展BERT的架构以更好地捕捉输出端相关性
- 分析了NAG模型目前面临的两个重要限制,并设计两个解决方案
- 前缀输出长度的不灵活性
- 现有的NAG模型要求在令牌生成之前确定输出长度,总是需要一个额外的输出长度预测模块
- 但来自预测模块的最可能的长度不一定是最适合令牌生成模型的长度
- 本文提出了一个简单的解码机制,让模型动态确定输出长度。具体来说,模型在所有输出位置发出[eos],以标志生成序列结束,从而避免预测输出长度
- 单个token预测的条件独立性
- 大多现有的NAG模型假设不同位置的令牌预测是条件独立的——倾向于产生重复的不合语法的结果
- 本文提出了一个上下文感知的学习目标,该目标促使模型在相邻位置输出不同的标记,从而减少重复生成的可能性
- 前缀输出长度的不灵活性
- 为进一步提高模型的推理效率,引入ratio-first解码策略
- ratio-first不是对所有源端隐藏状态执行推理,而是仅基于源隐藏状态的子集生成结果
- 子集大小由源长度和比率$\alpha$共同确定,该比率基于从数据统计中获得的先验知识设置。
- 在文本摘要、句子压缩和机器翻译上评估了该模型,模型明显优于许多非自回归基线,甚至与几个强自回归模型竞争
模型
模型结构
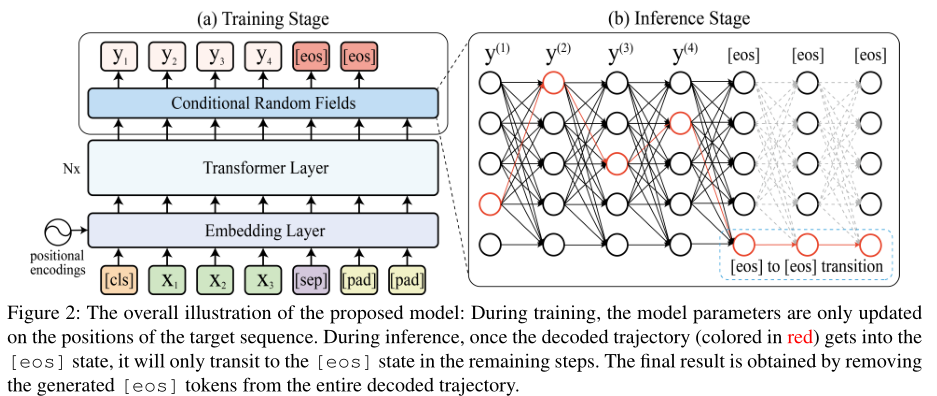
如下图,Transformer层和嵌入层使用BERT初始化
输入:
- 同BERT的设置,在源序列两端附加[cls]和[sep],尾部附加[pad]
- 如果源长度一定大于等于输出长度(如文本摘要任务),则不添加[pad]
Transformer Layers:
同相关论文一致
多头注意力
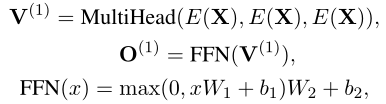
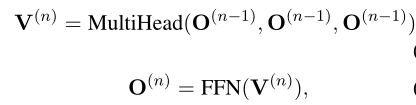
输出序列表达$H\in \mathbb{R}^{T\times d_{model}}$——$T$为源序列长度,$d_{model}$为model size
CRF:
长度为$T’$的目标序列$Y$建模为:
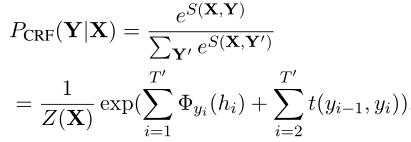
$Z(X)$为正则化函数,$\phi_{y_i}(h_i)$表示位置$i$上标签为$y_i$的label score
$\phi$由网络参数化,将BERT输出状态映射到label空间
$t(y_{i-1},y_i)=T_{y_{i-1},y_i}$表示从标签$y_{i-1}$到标签$y_i$的转换分数
近似:
- 标签空间非常大,很难直接对转换矩阵$T$和归一化因子$Z(X)$建模,因此需要做近似
- $T$近似为两个低秩矩阵的乘积
- $Z(X)$在每个时间步上不会搜索所有的可能路径
- 以上方案来自:《Fast structured decoding for sequence models》
输出长度
基本思路:希望模型通过输出一个特殊的[eos]来动态停止生成
在训练中将两个连续的[eos]附加到目标序列末尾——图2左上角所示——模型以此学习两个[eos]状态之间的确定性转换,即$t([eos],[eos])=max_{v\in V}t([eos],v)$(模型没有见过其他的[eos]转换)
在推理时,输出序列$\hat{Y}=argmax_{Y’}S(X,Y’)$,CRF sorce function$S(X,Y’)$可以进一步分解:
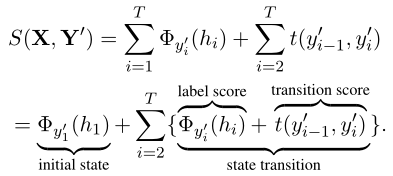
推理过程中,一旦进入[eos]状态,$S(X,Y’)$的状态转移项将由转移得分项$t([eos],[eos])$决定,因此剩余的时间步中模型继续生成(或者说转移到)[eos](如图2)
推理过程结束后,移除所有[eos]
ratio-first解码
如图2右侧,BERT的输出可以分成两个子集
- 第一个:从开始到发出第一个[eos]的位置
- 第二个:剩余的内容
这表明为了提高推理速度,只考虑BERT输出的开始部分就足够了——可以只使用BERT的前$[\alpha\cdot T]$个输出来执行推理,$T$表示输入源序列长度,$\alpha\in(0.0,1.0)$,根据数据统计设置,$[\cdot]$是整数舍入运算
形式上,给定源序列$X$,ratio-first解码为:
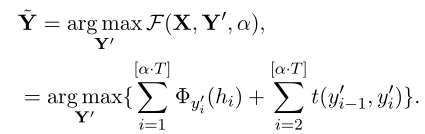
- 如果$\alpha$为1.0,则退化为基于CRF的模型的标准解码策略
- 这里策略只约束生成结果的最大长度,实际输出长度(去除[eos])由模型本身决定
训练
由于输出令牌的条件独立性近似,NAG模型往往倾向于生成重复令牌
缓解这个问题的一种方法是在输出端引入隐式依赖——本文建议在NAG的上下文中使用《Neural text generation with unlikelihood training》提出的unlikelihood,其中将否定候选集定义为预定义上下文窗口$c$周围的token
we define the set of negative candidate as the surrounding tokens within a predefined context window c.
形式上,给定源序列$X$和目标序列$Y$(长度为$T’$),上下文感知目标(
context-aware objective)为: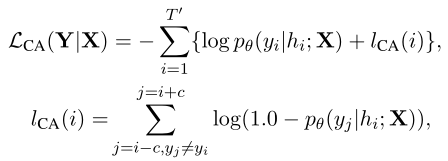 * 其中,$h_i$为位置$i$上模型的输出状态
* 在位置$i$,该目标最大化token $y_i$的概率并最小化周围token的概率,因此阻止模型在不同的时间步生成重复的token
* 其中,$h_i$为位置$i$上模型的输出状态
* 在位置$i$,该目标最大化token $y_i$的概率并最小化周围token的概率,因此阻止模型在不同的时间步生成重复的token
总体的学习目标定义为:
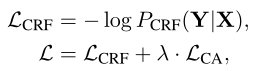
$\lambda$控制不同损失项的重要性
实验
- 使用Hugging Face的bert-base-uncased
- 设置低秩矩阵的维度为32
- 设置$Z(X)$的搜索beam size为256
- 设置窗口大小$c=3$,训练目标的$\lambda$为1.0
- 使用Adam优化器
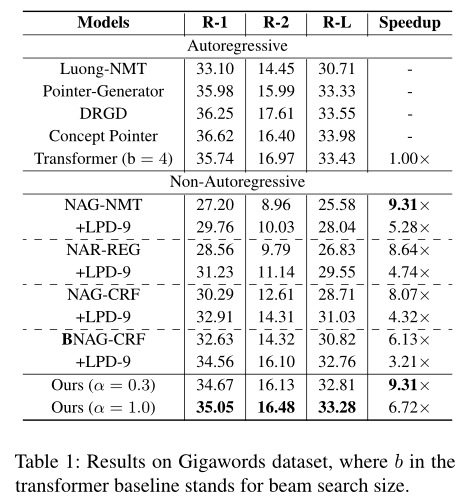
Text Summarization
Gigawords dataset作为benchmark
对比模型:
- NAG:
- NAG-NMT:《Non-autoregressive neural machine translation.》
- NAG-REG:《Non-autoregressive machine translation with auxiliary regularization》
- NAG-CRF:《Fast structured decoding for sequence models》
- BNAG-CRF:使用BERT作为NAG-CRF的编码器
- AG:
- Luong-NMT:《Effective approaches to attention-based neural machine translation》
- Pointer-Generator:《Get to the point: Summarization with pointer-generator networks》
- DRGD:《Deep recurrent generative decoder for abstractive text summarization》
- Concept Pointer:《Concept pointer network for abstractive summarization》
- 以transformer作为推理加速的baseline
- NAG:
结果:
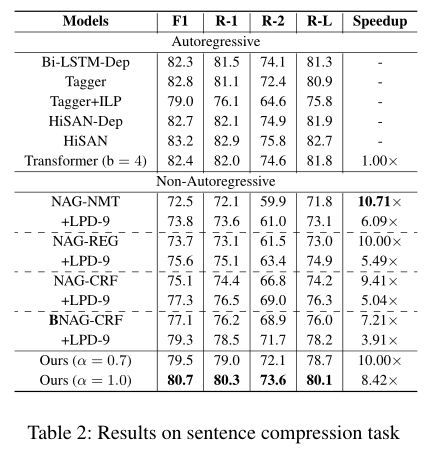
Sentence Compression
- Google sentence compression dataset作为benchmark
- 对比模型:
- Bi-LSTM-Dep:《Sentence compression by deletion with lstms》
- Tagger and Tagger+ILP:《Can syntax help? improving an lstm-based sentence compression model for new domains》
- HiSAN-Dep and HiSAN:《Higher-order syntactic attention network for longer sentence compression》
- 以transformer作为推理加速的baseline
- 结果:
机器翻译
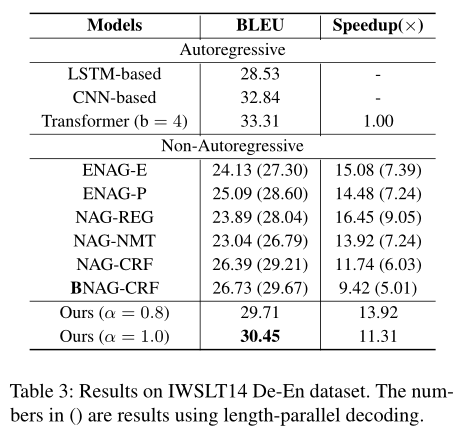
IWSLT14 German-to-English作为benchmark
训练中使用句子级别的知识蒸馏
对比模型
- NAG
- NAG-NMT
- NAG-REG
- NAG-CRF
- BNAG-CRF
- ENAG-E and ENAG-P:《Non-autoregressive neural machine translation with enhanced decoder input》
- AG
- LSTM-based:《Google’s neural machine translation system: Bridging the gap between human and machine translation》
- CNN-based:《Convolutional sequence to sequence learning》
- Tranformer
- NAG
结果: