《The Curious Case of Neural Text DeGeneration》2020 ICLR
摘要
- 文本生成的最佳解码策略仍然是一个悬而未决的问题
- 即使使用最大似然作为训练目标的模型,在使用基于最大化的解码方法(如Beam Search)时仍然会生成平淡无奇、不连贯或陷入重复循环的文本
- 本文提出了一种简单而有效的方法,从语言模型中解码出更高质量的文本——截断概率分布的不可靠尾部,从包含绝大多数概率的token的dynamic nucleus中采样,以避免文本的退化
- 为了查验当前基于最大化的随机解码方法,本文比较了各个方法生成文本的似然性、多样性等分布,结果表明
- 最大化对于开放式文本生成来说是一个不合适的解码目标
- 当前最佳语言模型的概率分布有一个不可靠的尾部,需要在生成过程中截断
- Nucleus Sampling是当前用于生成长文本的最佳解码策略,生成的文本质量高(根据专家评估来衡量)并且丰富度高
介绍
19年提出的GPT-2,使用top-k解码策略,从最可能的k个选择中采样下一个单词,而不是解码出最大可能性的文本——针对高概率输出进行优化的解码策略(如Beam Search)会导致文本严重退化,因为较长文本的最高分通常是通用的、重复的
本文证明,“不可靠的尾部”是主要原因——不可靠的尾部由数万个概率相对较低的候选token组成,这些候选token在聚合中被过度表示
This unreliable tail is composed of tens of thousands of candidate tokens with relatively low probability that are over-represented in the aggregate.
本文引入了Nucleus采样——抽样的关键直觉是,每个时间步的绝大多数概率质量集中在Nucleus(词汇的一个小子集,往往有1到1000个候选token)。与依赖固定的top-k或使用温度参数来控制分布形状——这会带来不可靠的尾部——不同,本文从概率质量top-p部分抽样,动态地扩展和收缩候选池
相关工作
语言模型解码
open-ended generation需要在给定m个token作为上下文情况下,生成n个连续的token,以获得一个完整的序列$x_1,…,x_{m+n}$
假定模型以常见的从左到右分解文本概率的方法,计算$P(x_{1:m+n})$
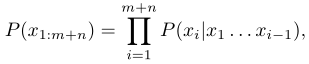
基于最大化的解码:
- 假设模型将更高的概率分配给更高质量的文本
- 此类解码策略搜索具有最高似然概率的生成文本
- 通常使用Beam Search
NUCLEUS SAMPLING
本文提出新的随机解码策略:nucleus sampling
给定一个分布$P(x|x_{1:i-1})$,定义top-p字典$V^{(p)}\subset V$为最小集,并且
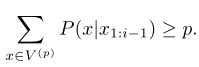
定义$p’=\sum_{x\in V^{(P)}}P(x|x_{1:i-1})$,则原来的分布转为一个新的分布:
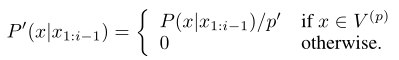
这表明,需要选择累计概率超过阈值的tokens作为采样集,采样集的大小根据每个时间步的概率分布形状动态调整。阈值时占据大部分概率的字典子集,这个子集称为nucleus
Top-k 采样
- nucleus sampling和top-k sampling都是从被截断的语言模型分布中采样,区别在于截断策略
- 每个时间步上,采样top k个下一个可能的token
- 形式化定义:给定一个分布$P(x|x_{1:i-1})$,定义top k的字典子集为$V^{(k)}\subset V$,令$p’=\sum_{x\in V^{(k)}}P(x|x_{1:i-1})$,则采样可以化为上面的形式,区别在于,此时每个时间步上的缩放因子$p’$的差别可能很大
- k的选择非常困难——而对于Nuclues Sampling,候选token的数目是动态变化的
SAMPLING WITH TEMPERATURE
通过温度形成一个概率分布
给定logits $u_{1:|V|}$和温度$t$,此时softmax为:
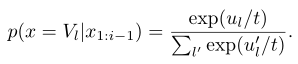
温度t倾向于高概率事件,一定程度上减少了尾部分布
虽然降低t可以提高生成质量,但生成文本的多样性下降
似然性评估
略
分布统计评估
略
人工评估
略

