《Multilingual Denoising Pre-training for Neural Machine Translation》(mBART 2020)
摘要
- mBART:seq2seq降噪自编码预训练模型(多语种语料库,使用BART训练目标)
- 第一次通过多语言全文去噪,预训练一个完整的seq2seq模型——能够直接对有监督和无监督的机器翻译任务做微调
介绍
- 当前MT方法只预训练encoder或decoder,或者预训练任务只恢复部分文本——mBART is a complete autoregressive Seq2Seq model
- trained by applying the BART to large-scale monolingual corpora across many languages
- 输入文本通过mask phrase或者重排句子加入噪音
- 如果使用back translation做微调,效果更好
- 不在预训练语料库中的语言,仍然受益于mBART
多语种去噪预训练
数据:CC25语料库
在CC25的子集上预训练——CC25:从Common Crawl中提取
采样以平衡不同语言的语料:(语言i的比例为$\lambda_i$,$p_i$为相应语言在语料中的比例,平滑参数$\alpha=0.7$)
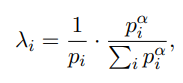
使用Sentence-piece模型做分词(SPM,2018),该模型在包含250000个subword token的CC数据上学习
不使用其他的预处理方法,如do lower case或者标点符号归一化
mBART模型
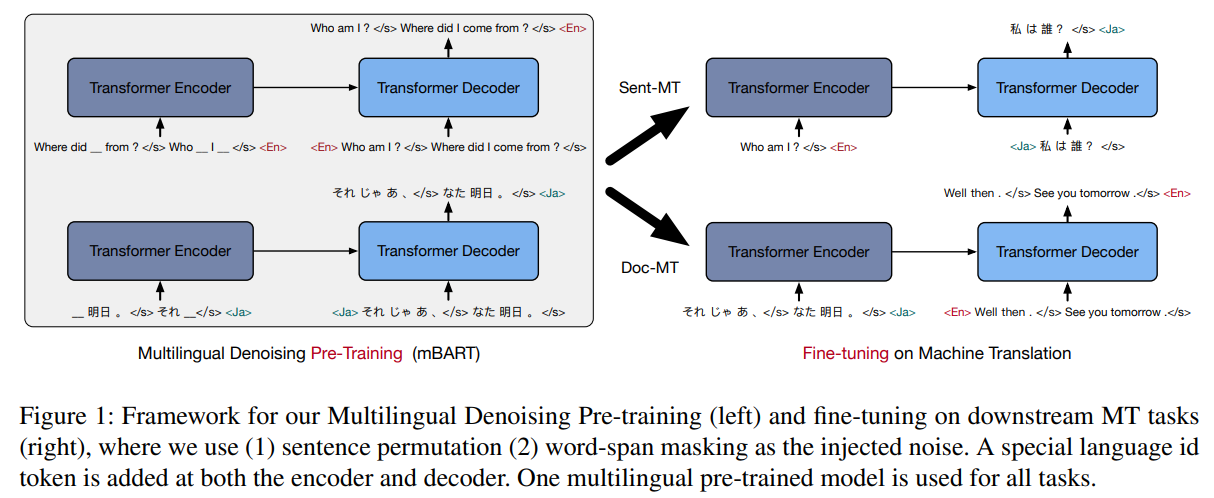
遵循BART的Seq2Seq预训练目标和预训练框架
Transformer结构,12个encoder,12个decoder,16个head,隐藏层1024(680M个参数),在encoder和decoder的顶部添加额外的layer-normalization layer,以在FP16的精度上稳定训练
在K个语言$D=(D_1,…,D_K)$上训练,$g$为噪音函数,$X$为原始文本,分布$P$由mBART定义,最大化$L_\theta$:
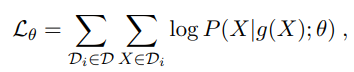
噪音:
- 删除spans of text,替换为一个mask token;每个实例有35%的token被mask,span length通过泊松分布采样确定($\lambda=3.5$)
- 每个实例的语句顺序被被重新排列
- decoder的输入为原始文本,并有一个位置的偏移
- 语言id标志 <LID>作为预测句子的初始token
实例的格式:每个实例,采样一个语言id,从相应的语料库中尽可能多的抽取连续的句子,直到文档结束,或者长度为512。实例中的各个句子由特殊token </S>分割,并在末尾加上语言id token作为结束标记
优化器:
- 在32G的显卡上训练500k steps
- 使用Adm优化器,学习率1e-6,$\beta_2=0.98$,linear learning rate decay scheduling
- dropout开始为0.1,250k步骤后为0.05,400k步骤后为0
- 使用Fairseq框架写代码
预训练模型:
- mBART25:在所有的25个语言上训练
- mBART06:探索在相关性强的语言的预训练效果,在6个欧洲语言(Ro、It、Cs、Fr、Es、En)上训练,使用1/4 of mBART25的batchsize,以迭代相同次数
- mBART02:三个语言对(En-De,En-Ro,En-It),使用1/12 of mBART25的batchsize
- BART-En/Ro:Baseline
- Random:额外的baseline,没有任何预训练
所有模型使用相同的vocabulary(见上文)——这种大规模的vocabulary能够提高多语言的泛化性,即使某个语言没有出现在语料库中
Sentence-level 翻译
略
Document-level 翻译
略
无监督翻译
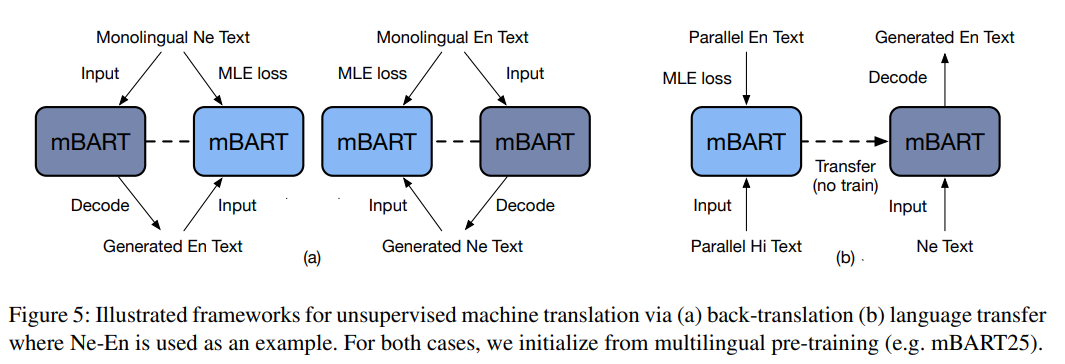
没有任何形式的双语文本:使用back-translation翻译
target pair没有双语文本,但两种语言都出现在其他语言对的语料库中——过去的方案显示,zero shot transfer可用通过大规模多语言机器翻译,或者distillation through pivoting实现,本文重点仅限于对单一语言对建立MT模型——即,学习X和Y的翻译,但没有(X,Y)语料,有额外语言Z并有(X,Z)和(Y,.Z)语料
target pair没有双语文本,但there is bi-text for translating from some other language into the target language——即存在(X,Z)语料
总结
略

