MIT-6.824 分布式系统学习笔记(1)
参考资料:
Lecture 01
概述
分布式系统的核心:通过网络来协调,共同完成一致任务的一些计算机,例如大型网站的储存系统、大数据运算(MapReduce)、点对点文件共享
分布式提供更高的计算性能(大量并行运算和大量磁盘并行)、容错,解决一些天然的空间上分布的事务(银行转账),并实现一些安全目标(例如限制代码出错时的影响范围)
挑战:
- 并发编程、时间依赖(同步、异步)问题
- 局部错误,以及各种故障问题——有的故障了,有的没有,还有网络不稳定问题
- 性能的提升需要更好的设计
分布式系统的实现工具:
- RPC:Remote Procedure Call:掩盖我们正在不可靠网络上通信的事实
- 线程:利用多核计算机
- 并发控制,如锁
可扩展性
- 使用多一倍的设备,能节约一半的时间或提高一倍的性能或吞吐
- 以网站为例,为了缓和用户人数增长带来的访问压力,增加多个Web服务器(假设只有一个后端数据库,用户访问Web服务器,服务器和后端数据库通信),之后会遇到数据库瓶颈,此时增加Web服务器
可用性
- 容错,使得系统能够屏蔽错误,或者能够在出错时继续运行
- 可用:在特定的故障范围内,系统仍能提供服务,系统仍是可用的
- 自我可恢复性(recoverability):问题出现时会停止服务,不响应请求,但修复之后系统可以正确地重新运行——比可用性弱的需求
- 实现可用性的方案:
- 非易失存储(non-volatile storage,类似于硬盘):存放checkpoint或者系统状态的log,恢复时从硬盘中读出最新状态——但更新的代价很高
- 复制:任何一个多副本的系统,其中每个服务器应当有相同的状态,但它们会意外偏离同步状态,即不再互为副本;lab2和lab3通过管理多个副本实现容错
一致性
- KV服务为例:put操作将value存入一个key,get操作取出某个key的value
- 分布式系统里,服务器不止一个,因此可能有多个版本的key-value对(例如在传递更新消息时断网)——put和get操作需要确定一些规则,以确保一致性
- 强一致性:每次get都会得到最近一次put请求写入的值;弱一致性:get操作可能获得一个旧数据
- 强一致性带来通信开销更大(如果两个副本距离很远,通信时间会更长,影响计算性能),而弱一致性只需要更新最近的数据副本,并且从最近的副本获取数据
MapReduce
背景:需要一种框架,使普通码农也可以完成、运行大规模的分布式运算
思想:只用写Map函数和Reduce函数,不需要知道其他分布式的事情,MapReduce框架会自行处理
过程:
输入被分割为大量的不同文件或数据块(如input1、input2、input3)
MapReduce为每个输入文件同时运行Map函数,函数输出一个key-value列表。以单词统计为例,input1为”ab”,input2为”b”,input3为”ac”,则输出分别为
[(a,1),(b,1)]、[(b,1)]、[(a,1),(c,1)],这些输出称为中间输出(intermediate output)运行Reduce函数:
收集每个Map函数输出的每个单词的统计,即第一个reduce收集map输出的key为a的key-value,MapReduce会为所有Map输出的每个key调用一次Reduce
本例中Reduce只需要统计传入参数的value内容即可
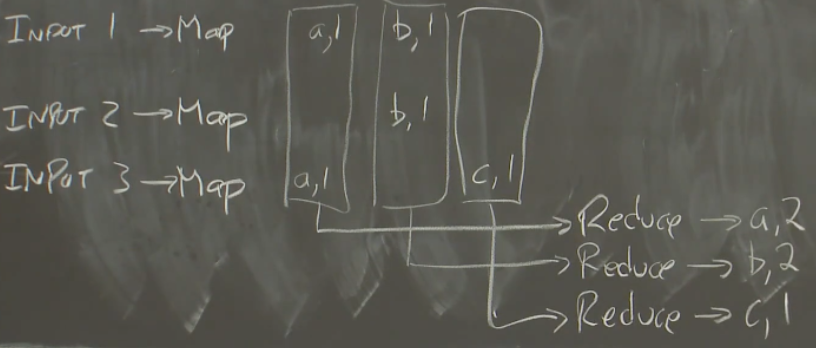
其中,整个MapReduce计算称为Job,每次MapReduce调用称为Task,即一个完整的Job由一些Map Task和Reduce Task组成
Map函数
Map(k,v):- k为输入文件名(通常被忽略),v为输入文件内容
- 仍为上例,将文本拆分为单词,对每个单词调用
emit(key, value)(框架的一个函数,也属于Map函数,key为单词,value为字符串”1”)
Reduce函数
Reduce(k,v):参数为某个特定key的所有value组成的列表- 仍为上例,value为数组,元素为Map函数输出的某个key的value,即”1”
- reduce也有一个自己的
emit(),接收参数value,上例中value为len(v)
一些细节:
- 整个过程里,会有一个Master节点组织整个计算过程,向各个worker服务器分发输入数据块
- Map函数中调用emit的结果,是在worker的磁盘上创建文件,文件包含了当前worker的Map函数生成的所有的key和value,之后worker将这些数据移动到Reduce所需要的位置
- Reduce worker会询问集群中的其他服务器,是否存在key=tmp_key的value并让其发送给该Reduce worker,Reduce函数中的emit会将输出写入一个共享文件服务(Google File System)中——想要灵活地在任意worker上读取数据,就需要某种网络文件系统(network file system)存放输入数据
- GFS会自动拆分存储大文件,以64MB的块平均分布到多个服务器上
- 当年的MapReduce的瓶颈之一为网络吞吐——分发数据块给Map worker需要网络通信,收集特定key的输出并传递给某个Reduce worker也需要网络通信
- 论文将Map worker存储数据格式转换为Reduce worker存储数据格式的过程,称为洗牌(shuffle)
- 典型的现代数据中心网络,会有很多的root交换机而不是一个交换机(spine-leaf架构),流量在多个root交换机之间做负载分担
Lecture 02 RPC和线程
Go提供一个远程过程调用包,C++标准库中没有RPC包
RPC:RPC采用客户端/服务端的模式,通过request-response消息模式实现,可以理解为一个节点请求另一个节点提供服务
如果线程在同一时间执行,每个线程都会各有一个单独的程序计数器,一组独有的寄存器,一个单独的堆栈——但这些线程的堆栈都在主程序的地址空间中
使用多线程的原因:
- 允许程序不同部分在不同活动中有自己的活动行为——IO并发
- 为每个要启动的RPC创建一个线程,给RPC发送请求信息,等待响应,当响应返回时继续执行——多线程使得能将所有请求同时发送出去
- 不同活动进展的重叠
- 多核并行
- 做一些定期的检查
- 允许程序不同部分在不同活动中有自己的活动行为——IO并发
异步程序(事物驱动编程)来实现类似一个不适用多线程的程序,该程序可以同时和多个不同的客户端通信,或者一个客户端与多个服务器通信,开销比线程小, 可以实现IO并发性,但无法获得CPU的并行性
多线程的挑战:
- 如何处理共享数据——多线程共享相同的地址空间,如果有一个全局变量N,一个线程在读取或者写入时,同进程内其他线程可能也在读取或者写入
- Race(临界区/竞态):解决方式为使用互斥锁(Go中,锁和任何变量都没有关联,只需要知道调用锁的第一个线程获得锁,其他线程必须等待直到unlock)
- 线程之间如何协调——go中用channel进行通信
- 死锁问题

