《When and Why is Unsupervised Neural Machine Translation Useless》(EAMT 2020)
摘要
- 研究无监督学习在NMT的实用性
- 十个不同数据的翻译任务中,分析了无监督方法无法产生合理翻译的原因
- 发现性能和源和目标语言之间的差异、二者语料代表领域是否相近有关,如果差异大、领域无关(这种情况常发生于低资源的语言中),则监督和半监督的baseline均优于非监督结果
介绍
- 无监督NMT:仅用单语语料库训练翻译模型
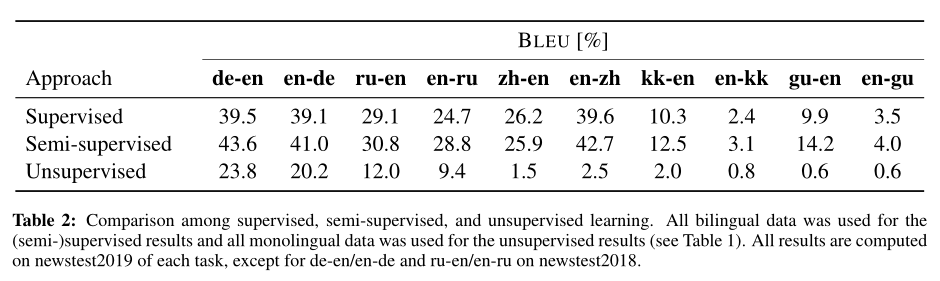
- 本文实验包含了5个语言对,10个翻译任务
- 德语-英语:语言相似,双语、单语语料丰富
- 俄语-英语:语言不相似,双语、单语语料丰富
- 中文-英语:语言不相似,双语、单语语料丰富,字母表规模差异极大
- 英语-哈萨克语:语言不相似,双语数据少,单语数据多
- 英语-古吉拉特语:语言不相似,双语、单语数据少
无监督NMT
- 主要无监督NMT框架,以及潜在的问题
Bidirectional Modeling
- 大多数NMT在源->目标和目标->源之间共享模型参数,并共享一个联合的字典
- 在不同的翻译任务之间共享模型,在多语言的NMT是有效的,能提高低资源语言性能——自然语言存在共性,学习一种语言的representation有助于表示其他语言
- 无监督NMT几乎没有双语信息,它基于假设:翻译本质上是双向的,源->目标和目标->源在概念上是相互关联的。已有的关于无监督NMT的工作,在共享程度上有所不同:有共享整个编码器、中间层、整个模型
- 但是如果词形(morphology)或词序(word order)有很大不同,知识迁移会更加困难
Iterative Back-Translation
上一个方法,需要两个翻译方向的双语数据
下图为Iterative Back-Translation的解释。模型首先翻译单语句子(实线箭头),然后以译文为输入原文为输出(虚线箭头)进行训练。此过程在源->目标和目标->源之间交替(所以称为iterative)
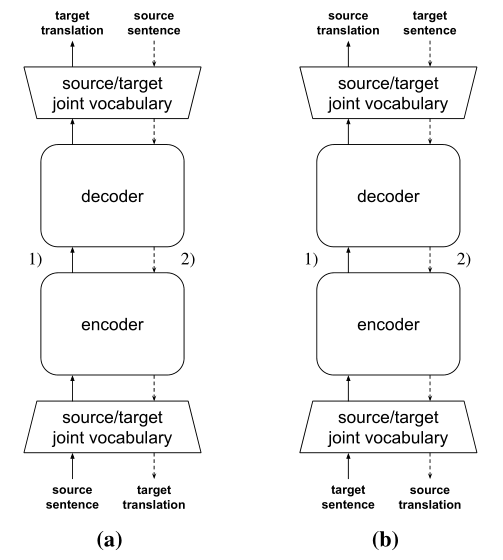
可以调整每次迭代时反向翻译的量
但如果初始的模型太差,就很难跳出”差“的最优
Initialization
- 多语言embedding为上一个问题提供很好的初始化选择
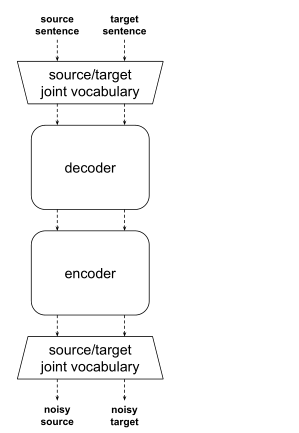
Denoising Autoencoder
多语言LM对不同语言中的单词序列进行编码,但是它们没有被明确地训练出将源单词重新排序到目标语言语法,并且没有初始化重新排序的关键:编码器-解码器的注意力,解码器状态的recurrence——因此,无监督NMT的初始模型倾向于生成几乎没有重新排序的逐字翻译,源语言和目标语言具有不同的词序时,会非常不流畅
因此无监管的NMT采用额外的训练目标:降噪自编码,去噪目标使得训练模型将有噪声的输入重新排序为正确的语法
实验和分析
实验中,无监督翻译使用XLM,细节略,结果分析略,数据如下