MIT-6.824 分布式系统学习笔记(2)
参考资料:
Lecture 03 GFS
构建分布式系统大多都是关于如何设计存储系统,需要更加关注如何为大型分布式存储系统设计优秀的接口,以及如何设计存储系统的内部结构
分布式系统的难点
- 将数据分割放到大量的服务器上,以并行地从多台服务器读取数据——此方式称为切片(sharding)
- 需要自动的容错系统——容错(fault tolerance),最有效的是维护2-3个副本——复制(replication),此时存在数据的不一致问题(inconsistency)
bad design
- 强一致模型:用户的角度,看起来就像是和一台服务器在通信,一次只做一件事情
- 为了让服务有可预期的行为,需要定义:一个时间只执行一条请求。此时每个请求都可以看到根据先前请求顺序执行生成的数据
- worst design example:
- 有两台服务器,每个服务器都有数据的一份完整拷贝,并且在磁盘上都存储一个key-value表
- 两个表单完全一致表明,每个写请求都要在两台服务器上执行,读请求只要在一台服务器上执行
- 客户端C1和C2都想执行写,一个要写X为1,一个写X为2。C1会将“写X为1”发送给两个服务器,同理C2也会将“写X为2”发送给两个服务器——此时,没有任何保障使得两台服务器以相同的顺序处理这两个请求
GFS设计目标
- Google需要大量的磁盘来存储大量的数据,需要借助MapReduce这样的工具快速处理这些数据
- 构建一个大型、快速的文件系统,全局通用,不同的应用程序都可以从中读取数据
- 每个包含了数据的文件会被GFS自动分割并存放在多个服务器,如此可以从多个服务器上同时读取同一个文件,进而获得更高的聚合吞吐量(同时,可以保存比单个磁盘还要大的文件)
- 自动的故障修复
- 局限在一个数据中心内
- 不面向普通的用户,供Google工程师写程序用
- 对大型的顺序文件读写做了定制(为TB级别的文件而生,GFS只会顺序处理,不支持随机访问)
- 具有弱一致性——GFS不保证返回正确的数据,它的目标是提供更好的性能,并且对于错误数据,可以在应用程序中做一些补偿
GFS master节点
- 有上百个客户端和一个Master节点——Master节点保存文件名和存储位置的对应关系,还有大量的Chunk(64MB)服务器,每个Chunk服务器上有1-2块磁盘,即Master节点管理文件和Chunk信息,Chunk服务器存储实际的数据,此时两类数据的管理问题完全分隔
- 可以拿多台机器作为Master节点
- GFS的Master为Active-Standby模式,只有一个Master节点在工作
- Master节点知道每一个文件对应所有的Chunk的ID——例如,对于一个1GB的文件,Master节点知道文件的第一个Chunk存储位置,第二个Chunk存储位置,想读取文件的任意部分时,向Master节点查询对应Chunk所在服务器,便可直接从Chunk服务器读取对应的Chunk数据
- Master节点内保存的数据内容:
- 第一个表单:文件名到Chunk ID或者Chunk Handle数组的映射——即,文件对应了哪些Chunk
- 第二个表单:记录Chunk ID到Chunk数据的映射关系,包括:
- 每个Chunk存储在哪些服务器,即Chunk id: Chunk服务器列表
- 每个Chunk当前版本号
- 哪个Chunk服务器持有主Chunk(Chunk的写操作必须在主Chunk,又称Primary Chunk上顺序处理,主Chunk是Chunk的多个副本之一)
- 主Chunk的租约过期时间(主Chunk只能在特定的租约时间内担任主Chunk)
- 以上数据都在内存中,Master节点会同时将数据以log形式存储在磁盘上,因此Master节点读数据只会从内存读,写数据(有数据变更)时,Master在log中追加一条记录并生成CheckPoint
- 有些数据需要存在磁盘上,有些不用:
- 第一个表单要保存在磁盘上——标记为NV(non-volatile, 非易失)
- Chunk服务器列表不用保存到磁盘上,Master节点重启后与所有的Chunk服务器通信,查询每个Chunk服务器存储了哪些Chunk——标记为V(volatile)
- 版本号——标记为NV
- 主Chunk的ID不用写入磁盘,因为Master节点重启后会忘记谁是主Chunk,只需要等待60秒租约到期,此时Master知道当前的Chunk没有主Chunk,因此可以安全指定一个新的主Chunk——标记为V
- 租约过期时间不用写入磁盘——标记为V
- 文件扩展到达新的64MB而需要新增一个Chunk,或指定新的主Chunk而导致版本号更新时,Master节点都需要向log追加一条记录,表明给文件新加一个Chunk或者刚刚修改了Chunk的版本号
- 维护log而不是数据库:
- 数据库本质上是某种B树(b-tree)或者hash table,追加log会更加高效——使用log可以使得磁盘写入更快
- 可以将最近的多个log记录一次性的写入磁盘,因为数据都是向同一个地址追加,因此只需要等待磁盘旋转一次。对于B树,每份数据都需要在磁盘中随机找位置写入
- Master节点会在磁盘中创建一些checkpoint,重启时会从log中的最近一个checkpoint开始恢复,再逐条执行从Checkpoint开始的log,最后恢复重启之前的状态
GFS读文件
读请求:客户端有一个文件名和从文件某个位置开始读的偏移量(offset)
应用将信息发送给Master节点,Master节点查询文件名,得到Chunk ID数组,而offset除以64MB就是数组中对应的Chunk ID。Master再从Chunk表单中找存有相应Chunk ID的服务器列表,将列表返回给客户端
客户端选择一个网络上最近的Chunk服务器(Google的数据中心里IP地址连续,因此从IP地址就可以判断位置远近),发送读请求——客户端可能会连续多次读取同一个Chunk不同位置,因此客户端缓存Chunk ID和相应Chunk服务器列表
客户端将Chunk Handle和偏移量发送给最近的目标Chunk服务器。Chunk服务器以普通的Linux文件系统管理各个Chunk,因此Chunk服务器只需要根据文件名找对应的Chunk文件,从文件读取对应的数据段返回给客户端
若读取内容超过一个Chunk,则应用程序通过一个库向GFS发送RPC,该库会注意到读请求跨越了Chunk边界,从而将一个读请求擦hi分为两个读请求,再发送给Master节点
GFS写文件
- 客户端向Master节点发送请求:向文件追加数据,请告知文件最后一个Chunk的位置
- 多个客户端同时写同一个文件时,一个客户端不知道文件究竟多长(因此无法确定offset)此时,客户端向Master节点查询哪个Chunk服务器保存了文件的最后一个Chunk
- 可以从任何最新的Chunk副本读文件,但必须要通过Chunk的主副本(Primary Chunk)写文件。由于某个时间点,Master不一定指定了目标Chunk的主副本,因此写文件时还要考虑Chunk的主副本不存在的情况
- 如果Chunk主副本不存在,Master找出所有存有Chunk最新副本的Chunk服务器,即副本中保存的版本号与Master中记录的Chunk的版本号一致,然后挑选其中一个Chunk服务器作为Primary,其他的作为Secondary
- 之后Master更新版本号,将版本号写入磁盘(接下来有写操作,所以需要更新版本号)
- Master节点向Primary和Secondary副本对应的Chunk服务器发送消息,通知最新版本号,Chunk服务器存储到本地磁盘
- Master节点给Primary一个租约:接下来的60秒里,它是Primary,60秒之后不再是——该机制确保不会同时有两个Primary
- 已知Primary和Secondary后,客户端把要追加的数据发给Primary和Secondary服务器,它们将数据写入一个临时位置——这些数据不会立刻追加到文件中。当服务器都返回消息确认收到要追加的数据时,客户端向Primary服务器发送追加命令,此时Primary服务器可能收到大量的并发请求,它会以某种顺序一次只执行一个请求
- 对于每个客户端的写请求,Primary查看当前文件结尾的Chunk,确保Chunk剩余空间足够,然后将追加的数据写入Chunk末尾。Primary会通知所有的Secondary同样将数据写入自己Chunk末尾
- Secondary的写入可能会执行失败,如果Secondary执行成功,则会回复“yes”给Primary。若Primary收到所有Secondary的“yes”回复,Primary向客户端返回写入成功,否则返回写入失败
- 如果客户端写入失败,客户端应重新发起整个追加过程:重新与Master交互找到文件末尾的Chunk,重新发起对Primary和Secondary的数据追加操作——可能一个Chunk的部分副本成功完成了数据追加,而另一部分没有成功,这种状态是可接受的,此时一个客户端读取相同的Chunk,可能可以读到追加的数据,也可能读不到
- 版本号只会在Master指定一个新Primary时才会改变(只在Master节点认为Chunk没有Primary时才会增加),而通常只有在原Primary发生故障才会指定一个新的Primary
- 某个时间点Master指定一个Primary,Master会通过定期的ping检查它是否存活。如果Master发送一些ping给Primary,并且Primary没有回应,如果Master立刻为Chunk指定一个新的Primary,那么就可能同时有两个Primary处理写请求(未ping到可能只是因为短暂的网络延迟),两个Primary不知道彼此的存在,会分别处理不同的写请求,最终导致有两个不同的数据拷贝——称为脑裂(split-brain)
- 为了处理以上问题,Master指定一个Primary时为它分配一个租约,Primary只在租约内有效,当租约过期,Primary会忽略或者拒绝客户端请求
- 对新文件做追加:Master节点会发现该文件没有关联的Chunk,于是创造一个新的Chunk ID,然后创建一条新的Chunk记录并为之创建一个为1的新版本号,再随机选择一个Primary和一组Secondary,让它们将对这个空的Chunk负责,后续类似上文的追加过程
GFS的一致性
第一个客户端追加A,第二个客户端追加B,但给某个副本的消息丢失,追加数据B的消息只被两个副本收到,第三个客户端追加C(P表示Primary)
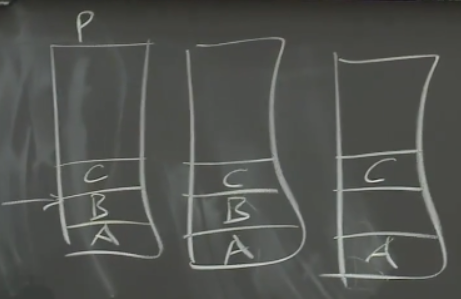
第二个客户端重新发送追加请求:
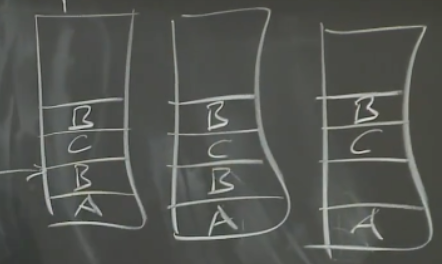
最坏的情况是,一些客户端写文件时,因为其中一个Secondary未能成功追加,客户端收到写入失败,而客户端重新发送写请求前,客户端就故障了——此时数据D出现在某些副本中,而其他副本则完全没有
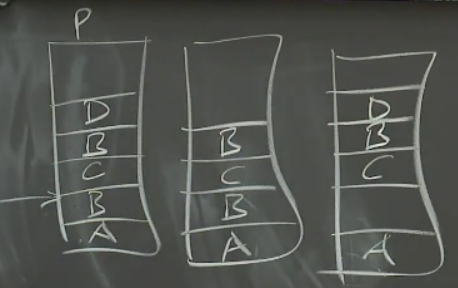
因此,Primary返回写入失败会导致不同的副本有完全不同的数据
因此,如果应用程序不能容忍乱序,应用程序要么在文件中写入序列号(读取的时候能自行识别顺序),要么对于特定的文件不要并发写入
目前还不清楚如何将GFS转变成强一致的设计
一些需要考虑的事情(为了达成强一致性)
- Primary要能够探测到重复的请求
- Secondary必须要执行而不是只返回一个错误给Primary——不允许Secondary忽略Primary的请求而没有任何补偿措施,例如将Secondary从系统中移除?
- 直到Primary确信所有的Secondary都完成追加之前,Secondary必须保护数据不暴露给读请求,即用两个阶段来处理写请求(称为两阶段提交,two-phrase commit)
- 第一阶段:Primary要求Secondary执行某个操作,等待Secondary回复能否完成该操作(此时Secondary不实际执行)
- 第二阶段:所有Secondary都回复可以执行时,Primary让所有Secondary执行回复可以执行的操作
- 新的Primary需要显式地与Secondary同步,确保操作历史最终结果相同
GFS的问题:
- Master会耗尽内存来存储文件表单
- 单个Master节点要承载数千个客户端的请求
- Master节点的故障切换不是自动的,GFS需要人工处理永久故障的Master节点
Lecture 04 VMware FT
关于容错(Fault-Tolerance)和复制(Replication)的问题
复制
- 容错是为了提供高可用性,VMware FT使用的工具为复制——复制能处理单台计算机的fail-stop故障(指,如果某些东西出了故障,比如说计算机,那么它会单纯的停止运行)
- 复制也能处理一些硬件问题
- 复制不能处理软件中的bug和硬件设计中的缺陷,例如MapReduce的Master如果有bug,计算结果错误,但其他组件会接收该错误结果
- 如果有两个副本,此时总是假设两个副本中的错误是相互独立的。但是如果错误是有关联的,那么制就无法处理此类问题
- 最后,复制的方案是否和相应服务的价值匹配?(复制的代价通常比较高)
状态转移和复制状态机
VMware FT论文介绍两种复制方法:状态转移(State Transfer)和复制状态机(Replicated State Machine)
状态转移:保持一个服务器的两个副本同步,一旦Primary出现故障,Backup有所有的信息就可以接管服务——Primary将自己完整状态拷贝并发送给Backup,Backup保存收到的最近一次状态。为了提升效率,可以每次同步只发送上次同步之后变更了的内存
复制状态机:
- 想复制的大部分服务或计算机软件都有确定的内部操作,不确定的部分是外部输入,因此如果一台计算机没有外部影响,执行指令都是计算机中内存和寄存器上确定的函数,只有当外部事件干预时,才会发生预期外的事(如某个时间点收到一个网络数据包)
- 复制状态机只让Primary将外部事件,如外部输入,发送给Backup,因此如果有两台计算机从相同的状态开始,以相同的顺序在相同的时间接收相同输入,则会一直互为副本,并且保持一致
综上,状态转移传输内存,复制状态机传输来自客户端的操作或者其他外部事件
对于一些随机操作,如获取时间、获取当前CPU的id等,Primary执行此类指令,将结果发送给Backup。Backup不执行,在应该执行指令的地方监听Primary的答案
多核机器中核心交互处理指令的行为是不确定的,即使Primary和Backup执行相同的指令也不一定产生相同的结果(论文针对单核机器)
要构建基于复制状态机的方案,需要考虑:
- 什么级别上复制状态
- 对状态的定义
- Primary和Backup之间同步的频率(Primary可能会比Backup的指令执行超前些)
- Primary故障后的切换方案
什么样的状态要被复制?
- VMware FT会复制机器的完整状态,包括所有的内存,所有的寄存器
- 机器级别实现复制,不关心机器上运行的软件——优点在于,不需要软件的源码也不需要理解软件如何运行,在某些限制条件下,将软件运行在VMware FT的复制方案
VMware FT工作原理
VMware FT需要两个物理服务器,Primary虚机在一个物理服务器上,Backup在另一个
两个物理服务器上的VMM为每个虚拟机分配一段内存,两段内存的镜像需要完全一致——每个虚拟机里面都有服务的一个拷贝,二者服务器存在网络连接
局域网里还有一些多副本服务需要与之交互的计算机(客户端),客户端向Primary发送了一个请求(网络数据包的形式发出)
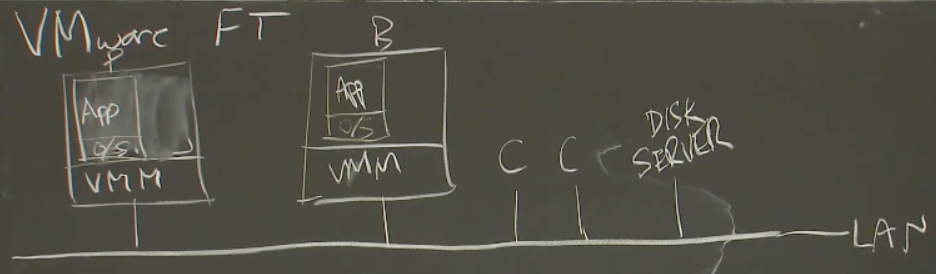
网络数据包产生一个中断,中断送到VMM。VMM发现这是发给多副本服务的一个输入,于是:
- 虚拟机的操作系统模拟网络数据包到达的中断,将相应的数据送给应用程序的Primary副本
- VMM会将网络数据包拷贝,通过网络送给Backup虚机所在的VMM
- Backup所在的VMM也会模拟网络数据包到达的中断,将数据发送给应用程序的Backup——Primary和Backup都收到该数据包,会以相同的方式处理该输入,保持同步
- Primary虚拟机内服务生成一个回复报文,通过VMM在虚机内模拟的虚拟网卡发出。VMM可以看到该报文并将这个报文发送给客户端;Backup虚机同样生成一个回复报文,但其VMM会丢弃该回复报文
VMware FT论文将Primary到Backup之间同步数据流的通道称为Log Channel,从Primary发往Backup的事件称为Log Channel上的Log Event/Entry
当Primary故障,开始执行FT(Fault-Tolerance)
- Backup的VMM如果1s内没有从Log Channel收到消息,Backup虚机会上线(Go Alive),Backup的VMM会让Backup自由执行,而不受来自Primary的事件驱动
- Backup的VMM会在网络中做一些处理,让后续的客户端请求发往Backup虚机,同时不再丢弃Backup虚机的输出——此时它是Primary,Backup虚机接管服务
Primary同样需要用一个类似的流程来抛弃Backup
非确定性事件
- 以上过程,假设若Backup虚机同样得到客户端请求并经过同样执行,它会与Primary保持一致——忽略了非确定性事件(Non-Deterministic)
- 非确定性事件分为:
- 客户端输入:可能有一个客户端请求,它的送达时间和内容不取决于服务当前的状态。先前网络数据包输入的例子中,数据包分为其中的数据和提示数据包送达的中断,Primary和Backup要在相同时间、相同位置触发中断,因此不仅要关心数据包的内容,还要关心中断的时间
- 一些指令在不同的计算机的行为不同(此类指令称为怪异指令),包括:随机数生成器、获取当前时间的指令、获取计算机的唯一ID
- 多CPU的并发——VMware FT论文完全没有讨论多CPU的并发
- 所有的事件都需要通过Log Channel,从Primary同步到Backup。Log的格式中有:
- 事件发生时的指令序号:为了同步,Primary和Backup需要在相同的指令位置看到数据。指令号是机器启动以来指令的相对序号,如正在执行第40亿条指令。对于中断/输入,指令序号是指令/中断在Primary的执行位置。对于怪异指令(Weird instructions),序号是怪异指令执行的序号,此时Backup虚机就知道在哪个指令位置让相应事件发生
- 日志条目的类型:可能是普通的网络数据输入,或者怪异指令
- 数据:对于网络数据包,日志条目中的数据是网络数据包的内容;对于怪异指令,数据是怪异指令在Primary执行的结果,此时Backup虚机可以伪造指令,获得与Primary相同的结果
- 例如:运行Primary虚机的物理服务器有一个定时器,会计时并生成定时器中断发送给VMM
- 适当的时候,VMM停止Primary虚机的指令执行,记下当前的指令序号,在指令序号的位置插入伪造的模拟定时器中断
- 恢复运行Primary虚机
- VMM将指令序号和定时器中断发送给Backup虚机
- 来自于Primary虚机的Log条目到达时,Backup虚机的VMM配合特殊的CPU特性支持,使物理服务器在相同的指令序号处产生一个定时器中断
- Backup的VMM获取这个中断,伪造一个假的定时器中断,将其送入Backup虚机的操作系统,并且定时器中断会出现在与Primary相同的指令序号位置
输出控制
系统唯一的输出是对客户端请求的响应
直到Backup虚机确认收到了相应的Log条目,Primary虚机不允许生成任何输出
举例:Primary和Backup都有一个计数为10的变量,客户端发送自增信号,要求返回变量自增后的值,此时:
- 客户端输入到达Primary
- Primary的VMM将输入的拷贝发送给Backup虚机的VMM——相应Log条目在Primary虚机生成输出前发往Backup,但有可能丢失
- Primary的VMM将输入发送给Primary虚机,Primary虚机生成输出
- Primary的VMM等到之前的Log条目被Backup虚机确认收到才将输出转发给客户端
- Backup的VMM不用等Backup虚机实际执行该输入Log,直接发送ACK报文给Primary的VMM
- Primary的VMM收到ACK后才将Primary虚机生成的输出转发到网络中
此机制限制了性能
重复输出
- 上例中,如果客户端收到回复,但Primary崩溃,Backup还没有处理完缓冲区中的Log,此时Backup会上线后产生一个输出报文,由于此时它变为了Primary,报文会再一次发给客户端——输出重复
- 对于任何有主从切换的复制系统,基本上不可能将系统设计成不产生重复输出
- 可以借助TCP协议完成重复检测(Backup回复报文的TCP序列号与Primary回复报文的TCP序列号相同,客户端的TCP栈会检测出这是重复的报文)
Test-and-Set服务
如果Primary和Backup都在运行,但是网络出现问题,并且它们各自又能与一些客户端通信,此时双方都认为自己需要上线并接管服务——脑裂(Split Brain)
论文解决此问题的方法是,向一个外部的第三方权威机构(Test-and-Set服务)求证,以决定谁上线
Test-and-Set服务不运行在Primary和Backup的物理服务器上
VMware FT需要通过网络支持Test-and-Set服务,该服务会在内存中保留一些标志位,向它发送Test-and-Set请求时,会设置标志位,并且返回旧的值
上述故障出现时,Primary和Backup同时发送一个Test-and-Set请求给Test-and-Set服务。第一个请求送达,Test-and-Set服务设置标志位为1,返回0;第二个请求送达,Test-and-Set服务检查发现标志位是1,拒绝第二个请求对应的服务器成为Primary
每次涉及主从切换,都需要向Test-and-Set服务进行查询
一个规则是,你无法判断另一个计算机是否真的挂了:当无法从目标计算机收到网络报文时,无法判断这是因为计算机挂了,还是因为网络出问题

