MIT-6.824 分布式系统学习笔记(5)
参考资料:
- chaozh/MIT-6.824: Basic Sources for MIT 6.824 Distributed Systems Class (github.com)
- MIT6.824 (gitbook.io)
- 2020 MIT 6.824 分布式系统_bilibili
Lecture 10 Aurora——Cloud Replicated DB
背景
- Aurora是一个高性能、高可靠的数据库,作为云基础设施一个组成部分,建立在Amazon的设施上
- 处理事务的速度上,Aurora宣称比其他数据库快35倍
- 抛弃通用存储,构建应用定制(Application-Specific)的存储
- EC2:Elastic Cloud 2,帮助用户在Amazon的硬件上创建类似网站的应用
- Amazon的服务器VMM(Virtual Machine Monitor),用户租用虚拟机来运行Web、数据库等服务——一个服务器上有一个VMM和一些EC2实例,每一个实例出租给不同的云客户
- 每个实例运行一个操作系统,在操作系统之上运行应用程序
- 每一个服务器都有一块硬盘,EC2实例会本地硬盘中分到一片硬盘空间
- EC2对于无状态的Web服务器来说是完美的,客户端通过浏览器连接到EC2实例上,如果新增大量客户,可以向Amazon租用更多的EC2实例,很容易就实现Web服务的扩容
- EC2实例上还常常运行数据库服务,Web服务所在的EC2实例与数据库所在的EC2实例交互,完成数据库记录的读写
- 场景:Amazon基础设施,一些客户端浏览器(C1,C2,C3),一些运行Web服务的EC2实例(Amazon基础设施内),一个运行数据库的EC2实例
- 对运行数据库的EC2实例,访问其本地硬盘即可获取存储,如果宕机则丢失数据——对运行Web的EC2实例,由于Web服务没有状态,因此另起一个实例即可
- Amazon有实现块存储的服务S3,可以定期对数据库做快照并存储在S3上,基于快照实现故障恢复
- EBS(Elastic Block Store)服务:
- 容错的且支持持久化存储的服务,向用户提供EC2实例所需的硬盘且硬盘数据不会随着服务器故障而丢失
- EBS底层是一对互为副本的存储服务器,看起来就像是一个普通的硬盘
- 运行数据库时相应EC2实例将一个EBS volume挂载成自己的硬盘,两个EBS服务器使用Chain Replication进行复制——实现了数据库的可用性
- 缺陷:
- EBS无法共享,每个EBS volume只能被一个EC2实例使用
- 有大量的数据通过网络传递,且有有CPU和存储空间的限制(Aurora论文不太关心CPU和存储空间的消耗,认为网络负载更重要)
- EBS容错性不够:Amazon将EC2实例和EBS volume的两个副本存放在同一个数据中心(AZ,Availability Zone)
- Amazon在一个城市范围内有多个独立的数据中心(大概2-3个相近的数据中心,通过高速网络连接在一起)
故障可恢复服务(数据库相关)
- Aurora使用与MySQL类似的机制实现,但实现了加速
- 本节主要介绍数据库中的事务(Transaction)和故障可回复(Crash Recovery)
- 事务:将多个操作打包成原子操作,确保多个操作顺序执行,要确保故障恢复之后,要么所有操作都执行完成,要么一个操作也没有执行
- 此外用户期望数据库通知事务的状态(是否完成并提交,提交后事务的效果持久保存)
- 通过对涉及到的每一份数据加锁来实现,确保他人不能访问,只有当事务结束、提交并且持久化存储后释放锁
- 具体实现:
- 一个简单的数据库模型:
- 单个服务器上运行,使用本地硬盘存储记录,以B-Tree构建索引
- 一些data page存放数据库的数据,一个存放X的记录,一个存放Y的记录。data page会存储大量的记录,X和Y的记录为page中的一些bit位
- 硬盘有一个预写式日志(Write-Ahead Log,WAL),有助于容错
- 数据库缓存最近从磁盘读取的page
- 执行一个事务的各个操作时(X=X+10),读取X的记录,给数据加10,此时数据的修改停留在缓存中;为了使数据库故障恢复后能提供同样的数据,先在WAL中添加Log条目来描述事务,写入磁盘
- 第一个Log:要修改X,旧数据是500,要将改成510
- 第二个Log:一个Commit Log,表明事务结束
- 通常第一条Log会附加事务的ID作为标签,故障恢复时,根据第二条commit log找对应的Log记录,以得知哪些操作属于已提交事务
- 数据库累积更新,cache写入一次磁盘会包含很多更新操作
- cache写入磁盘前数据库崩溃,则重启时恢复软件扫描WAL日志,发现对应事务的log和其commit log,恢复软件将新数值写入磁盘中——称为redo
- 一个简单的数据库模型:
- MySQL基本以此方式实现故障可恢复事务
关系型数据库(Amazon RDS)
Amazon开发改进的MySQL:RDS(Relational Database Service),尝试将数据库在多个AZ之间复制
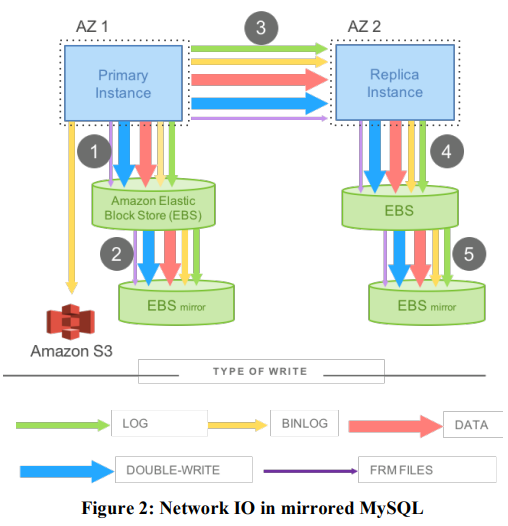
有且仅有一个EC2实例作为数据库,数据库将data page和WAL Log存储在EBS,而非相应服务器的本地硬盘,写Log或者写page操作通过网络发送到EBS服务器
每次数据库执行一个写操作,Amazon会将写操作复制一次,发送到另一个AZ中(另一个EC2实例),执行与主数据库相同的操作——此时,数据除了发送给AZ1的两个EBS副本外,还要通过网络发送到AZ2的副数据库,以及相应的两个EBS副本。副数据库将写入成功的回复返回给AZ1的主数据库,主数据库收到回复后才会认为写操作完成
这种Mirrored MySQL比Aurora慢得多,因为它通过网络传输大量的数据
此架构增强容错性,在一个不同的AZ有了第二个副本拷贝,但性能太差
概述
依然有一个数据库服务器,但运行的是Amazon提供的定制软件Aurora(运行在某个AZ中)
Aurora的架构中:
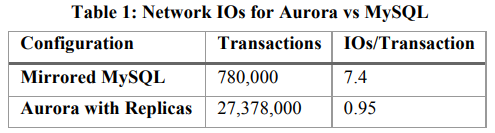
- 原本EBS的位置上有6个副本,位于3个AZ——写请求要以某种方式发送给6个副本,但通过网络传递的数据只有Log条目(每一条Log条目只有几十个字节,之前RDS对每个事务传递的是data page,至少8k字节)
- 存储系统不再是通用(General-Purpose)存储,而是可以理解MySQL Log条目的、定制的(Application-Specific)存储系统
- EBS是通用存储,模拟了磁盘,只需要支持读写数据块,不理解数据块以外的其他事物
- 不需要6个副本都回复写入成功才继续执行操作,只要Quorum形成(任意4个副本确认写入),就可以继续执行操作——只需要等待6个服务器中最快的4个即可
- 原本EBS的位置上有6个副本,位于3个AZ——写请求要以某种方式发送给6个副本,但通过网络传递的数据只有Log条目(每一条Log条目只有几十个字节,之前RDS对每个事务传递的是data page,至少8k字节)
性能对比:
Aurora的容错目标
- 对于写操作,如果只有一个AZ彻底挂了,不受影响
- 对于读操作,当一个AZ和一个其他AZ的服务器挂了,读操作不受影响
- Aurora期望能够容忍暂时的慢副本,即允许某个副本存在卡顿
- Aurora的Quorum系统有点类似于Raft,只能从局部故障中恢复,因此需要快速生成新的副本(Fast Re-replication),如果一个服务器看起来永久故障,期望根据剩下的副本尽快生成一个新副本
- 这里只针对存储服务器的故障,而非数据库服务器本身故障——Aurora有一个机制,可以在发现数据库服务器挂了时,创建一个新的实例来运行新的数据库服务器
Quorum复制机制
- Quorum:
- 通过复制构建容错的存储系统,确保即使一些副本故障,读请求仍然能看到最近写入的数据
- Quorum系统通常是简单的读写系统,支持Put/Get,不直接支持更高级的操作
- 典型的Quorum配置:
- N个副本,为了执行写请求,要确保写操作被W个副本确认,为了执行读请求,要从至少R个副本读取信息
- 数字W称Write Quorum,数字R称Read Quorum
- 要求接收写请求的W个服务器必须与接收读请求的R个服务器有重叠——R+W>N,此时读请求可以从至少一个记录了最新写请求结果的服务器得到回复
- 对于写,会将新数值和版本号发给所有N个服务器,但只等待W个服务器确认;对于读,将读请求发给所有服务器,但只等待R个服务器的数值和版本号
- 客户端如何知道从R个服务器得到的R个结果中,哪一个正确?Quorum系统中使用版本号(Version),每次执行写请求需要将新写入的值与一个增加的版本号绑定,客户端在R个结果中选择其中最高版本号的数值,从而平滑地处理慢服务或者挂了的服务
- 如果不能与R个或者W个服务器通信,则只能不停重试,直到服务器重新上线,或者重新联网
- 通过调整Read Quorum和Write Quorum,调整系统性能
- 为了实现上一节的Aurora容错目标,设置N=6,W=4,R=3
- W=4:一个AZ彻底下线时,剩下2个AZ中(4个服务器)能完成写请求
- R=3:一个AZ和一个其他AZ的服务器下线时,剩下的3个服务器能完成读请求,不能完成写请求——有足够的服务器支持读请求并据此重建更多的副本,在新的副本创建出来之前,系统不支持写请求
Aurora读写存储服务器
本节介绍了存储服务器是如何定制的
Aurora的写请求只会在当前Log中追加Entry(Append Entries),不覆盖数据——每个新Entry必须至少追加在4个存储服务器中,才认为写请求完成
存储服务器要存储数据库服务器磁盘中的page
- 当一个写请求(只是一个log entry)到达,需要应用到相关的page,可以等数据库服务器要查看该page再更新,因此存储服务器会在内存中缓存一个旧版本的page,以及一系列修改该page的entry,这相当于page是snapshot,snapshot后有记录更新的entry列表
- 当一个读请求到达,请求发送到存储服务器,此时存储服务器才会将Log Entry的新数据更新到page,并写入磁盘,再更新的page返回数据库服务器
- 数据库服务器写入的是Log条目,读取的是page
数据库服务器可以避免触发Quorum Read:
- Log条目有编号,存储服务器收到数据库服务器发送一条新的Log条目时会返回收到Log的最高编号
- 数据库服务器记录最高编号,执行读操作时只挑选拥有最新Log的存储服务器,只向该服务器发送读取page的请求
新的数据库服务器在故障恢复时会执行Quorum Read
数据分片(Aurora如何处理大型数据库)
- 以上的设置下,不能拥有一个数据量大于单个磁盘空间的数据库,因为每个副本存储的数据相同
- 策略:
- 将数据分割存储(每份10G,称为Protection Group,PG)到多组存储服务器上,每一组都是6个副本,因此对于20G的数据分为两个PG,分别存储6个副本
- 两组PG可能使用相同的6个存储服务器(但通常不同)
- 可以根据data page做sharding。当Aurora发送一个Log Entry时,会查看Log所修改的数据,找到存储该数据的PG,Entry只发给这个PG的6个存储服务器,因此每个PG存储data page的一个子集,以及相关的Log Entry
- 恢复挂掉的存储服务器(简单地重传数据耗时太长):
- 数据分片后,每个存储服务器可能包含数百个数据库PG
- 如果一个存储服务器挂了,假设上面有100个PG,可以找100个不同的存储服务器,每一个要恢复一个PG——并行的通过网络将100个数据块从各自的5个PG副本拷贝到100个目的块
- 有足够多的服务器,大概率这100个存储服务器不会重合,从而如果一个存储服务器挂了,可以并行、快速地用数百台服务器恢复
只读数据库
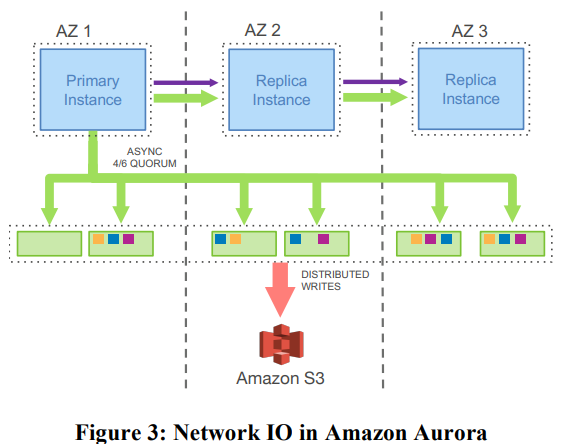
Aurora不仅有主数据库实例,同时有多个数据库的副本,用于应对大量地只读数据库查询
写请求可以只发给一个数据库,因为如果有多个数据库以非协同的方式处理写请求,为Log Entry编号非常困难
读请求可以发送给多个数据库,Aurora有多个只读数据库,从后端存储服务器读取数据,此时读请求可以分担给这些只读数据库
- 只读数据库向存储服务器发送读取page的请求,并缓存读取到的page——局部性原理,对以后的一些读请求,可以根据缓存数据返回
- 只读数据库也要更新缓存:主数据库会将Log的拷贝发送给每一个只读数据库(即上图蓝色矩形中间的横线),只读数据库据此更新它们缓存的page数据——只读数据库会稍微落后主数据库,客户端会感受到一点延迟
- 主数据库发给只读数据库的Log流中,需要指出哪些事务commit了,只读数据库忽略未commit的事务,只应用commit的事务到自己的缓存
- 当一个只读数据库向存储服务器请求一个data page时,存储服务器要么展示微事务之前的状态,要么展示微事务之后的状态,不会展示中间状态——避免看到存储数据库rebalance B-tree的中间过程
总结:
- 事务型数据库如何工作,事务型数据库与后端存储之间交互带来的影响——性能,故障修复
- Quorum思想:通过读写Quorum的重合,确保总能看见最新的数据,又具备容错性——Raft可以认为是一种强Quorum的实现(读写都要过半服务器认可)
- 定制了存储系统,而非通用的存储
- 云基础架构的隐含信息:
- 需要担心整个AZ出现故障
- 需要担心短暂的慢副本
- 网络是主要的瓶颈

