《Password Guessing via Neural Language Modeling》(ML4CS 2019)
摘要
- 本文将密码猜测视为一项语言建模任务,使用一个更深、更健壮、收敛更快的模型
- 受Transformer启发,用它对密码进行双向MLM建模——很难给出归一化的概率估计,因此将transformer的知识提取到提出的模型中,进一步提高其性能
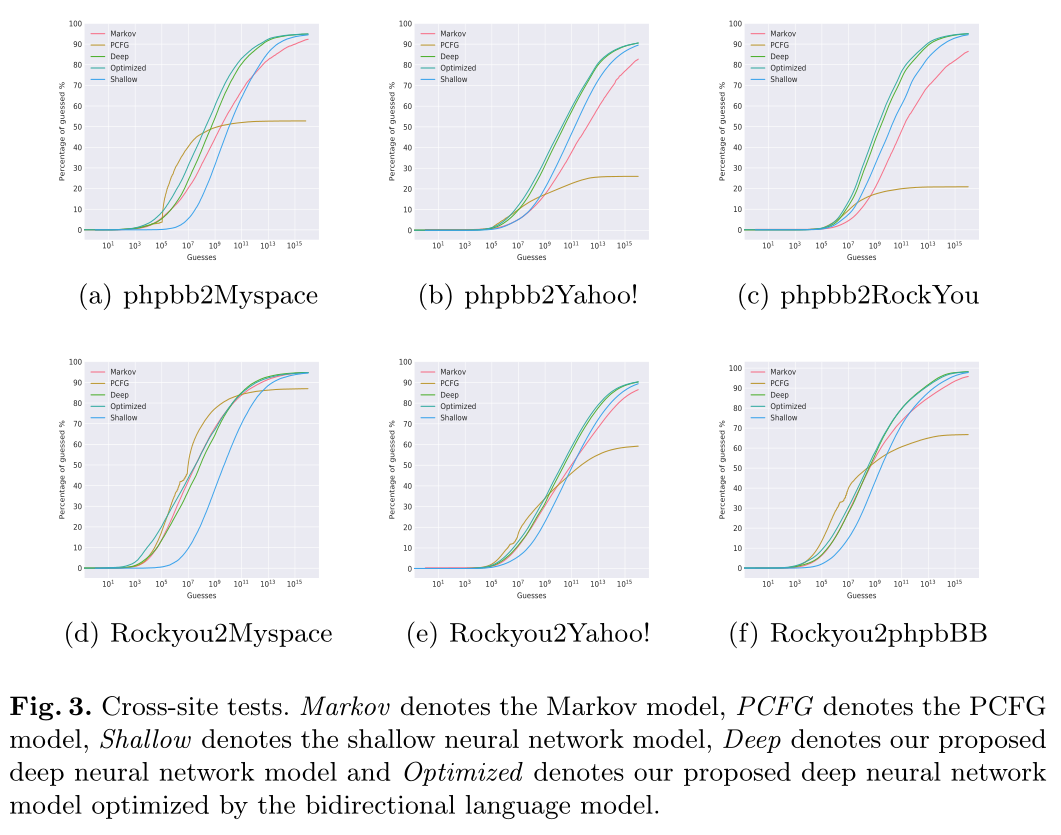
- 与PCFG、马尔可夫和FLA、PassGAN相比,模型在单网站测试和跨网站测试中都有显著的提高
- 通过控制输出分布的熵,模型对密码策略具有鲁棒性
介绍
- 常用的密码猜测工具,如JTR和HashCat,将字典攻击与许多启发式方法结合
- Weir等人提出了第一个概率模型PCFG
- Ma等人表明,近似表示自然语言的马尔可夫模型可以有效生成密码
- Melicher等人、Xu等人、Liu等人使用神经网络提取密码特征并自动估计其概率
- 本文借鉴语言建模的思想对密码进行建模和猜测,因为具有有意义的序列字符的密码可以视为简短的自然语言
- 本文首先介绍一个深度神经网络,在建模密码的性能更好
- 因为Transformer对语言建模效果极好,因此引入一个用MLM训练的双向模型,但它不能为一个密码提供归一化概率——借鉴知识蒸馏的思想,使用Transformer作为教师来指导所提出的模型,这提高了本文模型的效果
- 执行单站点测试和跨站点测试,将本文的深度模型与最先进的密码猜测模型进行比较,用蒙特卡罗方法评估这些模型的性能。大多数情况下,本文的深度模型优于以前的方法
方法
Perplexity:度量不同语言模型的性能,该指标和联合概率$P(x_{1:T})$具有关联,困惑度只适用于那些给每个密码分配一个非零概率的模型
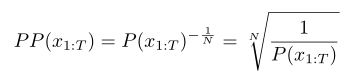
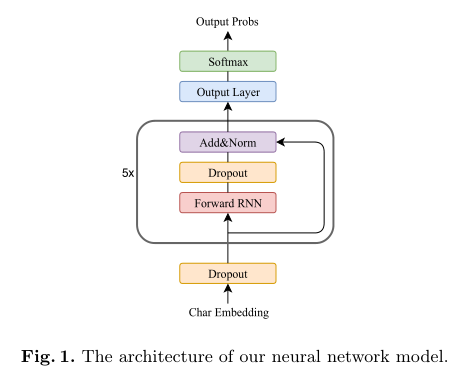
网络结构
Normalize Output Layer’s Weight
Output Layer是一个线性变换+softmax
将所有字符的范数归一,从而所有字符都被同等对待
We should diminish the impact of L2 norm to get better feature representationf, a straightforward way is to normalize all characters’ norm to 1, so that all characters are treated equally.
Layer Normalization:归一化每个LSTM层的输出和它的门的输出
残差连接:每一层的输入添加到其激活的输出
Dropout:在LSTM层之间增加dropout,而且在嵌入层也采用了dropout——可以看作随机删除密码中的一些字符,从而使网络变得健壮
控制输出的Entropy:不同的密码集可能具有不同的密码策略,训练集分布可能不同于测试集。使用超参数T(温度)来控制输出的熵(logits为$Z=(z_1,…,z_V)$)
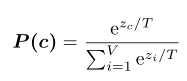
- 当T趋近于0,则$P(c)$趋近于独热码
- 当T趋近于无穷,则$P(c)$趋近于熵很高的标准分布
- 如果训练集的策略与测试集的策略非常不同,应该选择更高的T获得更平滑的输出分布
双向语言模型(Bert)与知识蒸馏
利用BERT提取密码的特征表示,其中的知识通过知识提炼转移到我们的密码猜测模型
知识蒸馏:
知识是从输入向量到输出向量的学习映射,对于语言建模任务,知识是包含在序列中的语义。知识蒸馏是迁移学习的一种形式,使用well-trained model的预测来训练其他子模型
由教师模型产生的后验概率(softmax输出)称为“软目标”,传统训练目标中使用的一次性目标被称为“硬目标”。软目标除了指出正确的类别之外,还包含了很多信息——例如教师模型的输出[0.08,0.9,0.02]保留了非目标类的等级信息,表明第二类比第三类更类似于第一类。学生模型应该由教师模型和实际数据共同指导——本文使用BERT双向语言模型作为教师模型,指导和改进单向语言模型
在训练过程中,单向模型不仅被实际数据引导,也需要最小化双向模型生成的软目标之间的KL散度
- 第二项为softmax output和实际数据之间的crossEntropy,第一项为KL散度,$\alpha$为超参数
minimize the Kullback-Leibler divergence between its softmax outputs and the soft targets generated by the bidirectional model
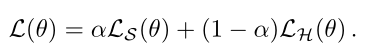
结果
- 蒙特卡洛估计时,抽样100w
- capacity of bidirectional model:双向模型基于其双向上下文预测被mask的字符,单向模型基于其先前的上下文预测被mask的字符,使用分类准确性进行度量——结论:
- 双向模型的准确率远高于单向模型
- 双向模型比单向模型更有效地使用数据(训练集增大时,双向模型的准确率提升更多)
- 跨站点攻击:
同站点攻击:0.8训练,0.2测试
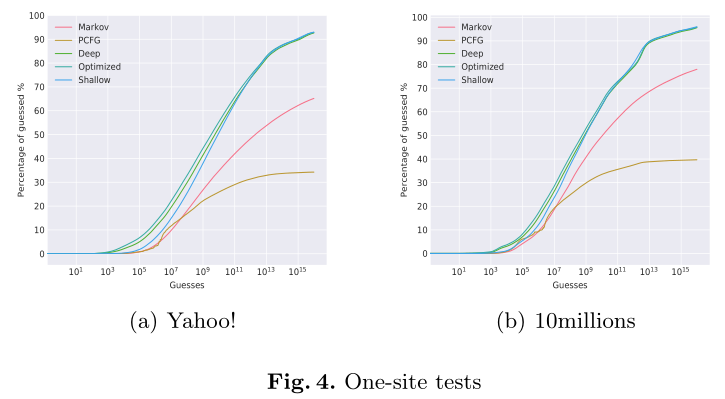
密码策略:
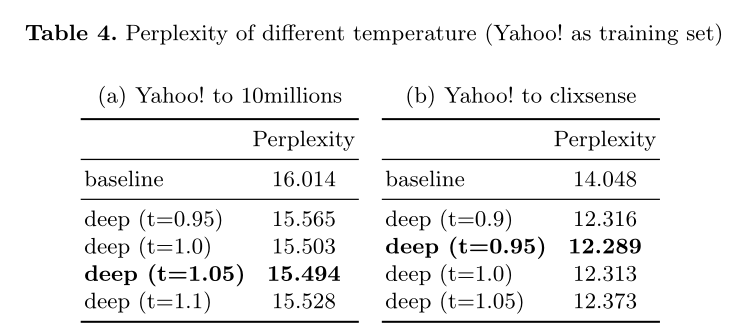
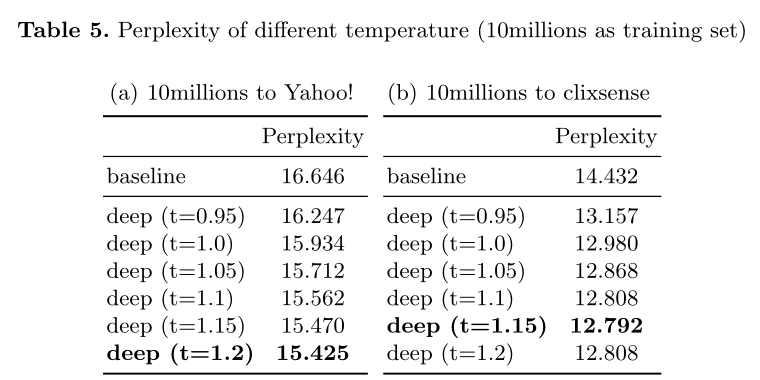
- 使用困惑都来评估结果,baseline为FLA
- 当10millions库作为训练集,增加T会降低困惑度——训练库和目标库Yahoo不同,因此增加T可以解决过拟合问题
疑问:bert的softmax输出,如何指导lstm的softmax输出?是指,对于abcd123,bert分别产生mask bcd132、a mask bcd123等对应logits,然后和mask,a mask等lstm的logits进行知识蒸馏吗?

