Redis(3)主从复制、Redis应用问题(缓存穿透、击穿、雪崩,实现分布式锁)
redis主从复制
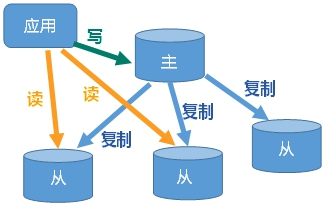
master/slaver机制:master数据更新后根据配置和策略,自动同步slave。master以写为主,slave以读为主,实现读写分离,容灾快速恢复
配置过程:
- 开启daemonize、修改Pid文件名 pidfile、指定端口port、修改Log文件名、修改dbfilename、Appendonly 关掉或者换名字
- slave-priority:从机的优先级,越小优先级越高,选举主机时使用。默认100
- 查看主从配置信息:info replication
- 从机执行
slaveof <ip> <port>成为某个实例的slave——会停止从旧的主节点复制,丢弃已经同步的旧的数据,并开始从新的节点同步数据。如果slaveof no one,则slave成为master,不丢弃已复制的数据(Redis 5.0后,用replicaof) - master挂掉,重启即可;slave挂掉需重设,或者修改conf文件以永久生效
一主二从时,主机挂掉,重启后仍为master并且有两个slave,slave仍然为slave
链式时,将master去中心化,a为master,b为a的slave,c为b的slave;如果一个slave的master换了一个ip,则slave会清除前面的数据,重新拷贝最新的
复制原理
slave连接到master后发送一个psync命令(三个组件支持,主从节点各自的offset,主节点的复制积压缓冲区,主节点的runid)
offset:master和slave会维护自己的主从复制偏移量,master有写入命令时,offset=offset+命令的字节长度,slave收到master的命令后,也会增加自己的offset,并将offset发送给master,此时master同时有自己和slave的offset,以判断是否数据一致获得原master数据最全
复制积压缓冲区:master中一个固定长度的先进先出队列,默认大小1MB,slave连接时创建。master响应写命令时,命令发送给从节点的同时也写入复制缓冲区
runid:每个redis实例启动后都会随机生成一个40位的runid
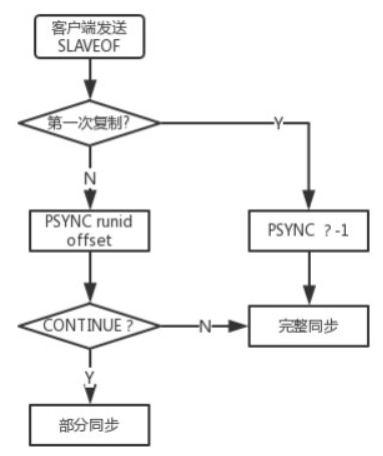
master接到命令启动bgsave,持久化得到rdb文件,传送rdb到slave,到slave加载数据完成这段时间,master的写命令放入缓冲区。slave清理自己的rdb,加载master的rdb,如果slave开启了aof,则异步rewrite aof文件,完成一次全量复制;之后master将缓冲区的数据发送给slave,实现增量复制
全量复制:slave接收到数据库文件数据后,存盘并加载到内存
增量复制:slave将自己的offset发送给master(offset见下文),master对比自己和slave的offset和消息中的runid,如果offset后面的数据在缓冲区中,则master将新的修改命令依次传给slave,完成同步,否则进行全量复制
如果是重新连接master,将会自动执行一次全量复制
哨兵(sentinel)
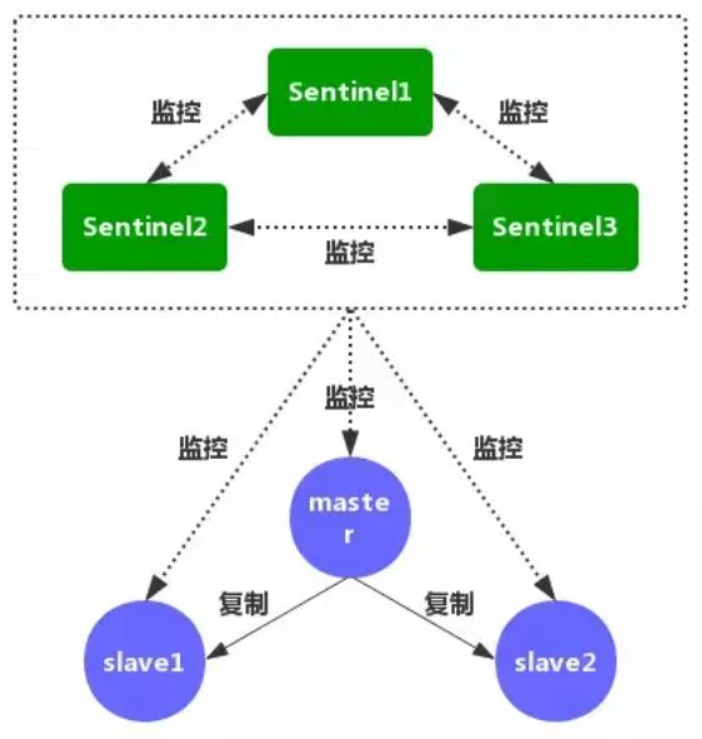
- slave在master挂掉后,根据投票数自动成为master(上面需要主动执行slave no one)
- sentinel实时监控所有redis实例是否可用(sentinel通常也会集群部署)
- 每个Sentinel节点以每秒一次的频率,向它所知的master、slave以及其他的Sentinel实例发送一个PING命令
- 如果一个实例距离最后一次有效回复PING命令的时间超过down-after-milliseconds所指定的值,那么这个实例会被Sentinel标记为主观下线
- 如果一个master被标记为主观下线,正在监视这个服务器的所有Sentinel节点,以每秒一次的频率确认master的确进入了主观下线状态
- 如果一个master被标记为主观下线,并且有足够数量的Sentinel(至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断,那么这个master被标记为客观下线
- 每个Sentinel会以每10秒一次的频率向它已知的所有master和slave发送INFO命令,当一个master被标记为客观下线时,Sentinel向下线master的所有slave发送INFO命令的频率,会从10秒一次改为每秒一次
- Sentinel和其他Sentinel协商客观下线的master的状态,如果处于SDOWN状态,则投票自动选出新的master,剩余slave指向新的master进行数据复制
- 配置(需要sentinel.conf文件)
- 文件中
sentinel monitor mymaster 127.0.0.1 6379 3,mymaster为自定义的被监控的服务器名,3为至少有多少个哨兵同意迁移,即有多少个哨兵认为mater挂掉 - 启动:
redis-sentinel ./sentinel.conf
- 文件中
- 当master挂掉,根据slave-priority选举最小的为master(选择条件为:priority小的、偏移量大的、runid小的),master重启后成为slave
参考:
redis集群
上面的内容,master只有一个,写入都由master负责,成为性能瓶颈
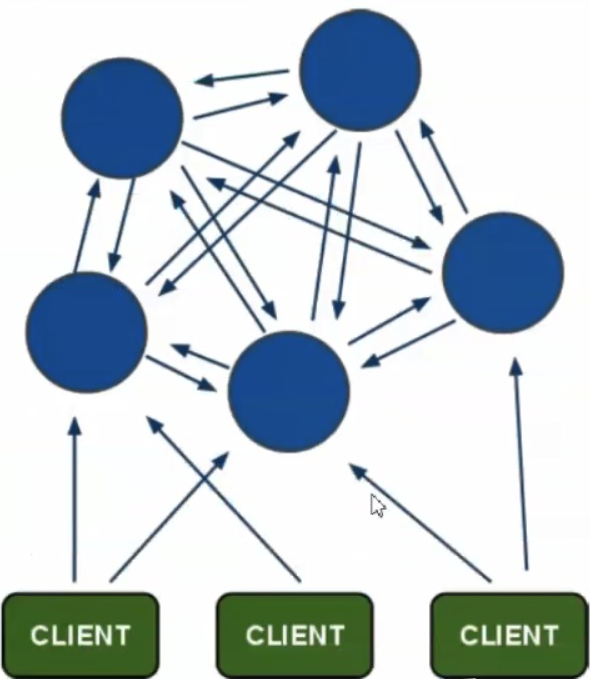
cluster通过分片方式保存key-value,保证高可用、高性能、高可扩展性,没有leader节点
每个节点都拥有全部集群的信息,每个节点都要配置集群中其他节点的信息(自动配置)
架构细节:
所有的redis节点彼此互联(
PING-PONG)节点失效判定,需要集群中超过半数的节点检测失效
客户端与任何一个可用redis节点直连
cluster把所有的物理节点映射到[0-16383]slot上,cluster维护node<->slot<->value
- 集群创建时,给每个redis节点分配hash槽,集群总共有16384个hash槽,每个slot都有序号
- 对于一个key,计算
crc16(key)的值,对其取%16384,将key-value数据存储到指定序号的hash槽中
投票:
节点失效判断:集群中所有master参与投票,半数以上master与一个master节点通信超过
cluster-node-timeout,认为该master节点挂掉集群失效判断:
- 如果集群任意master挂,,且挂掉master没有slave,集群进入fail状态——集群的[0-16383]slot映射不完全时进入fail
- 集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态
命令:
创建集群:
./redis-cli --cluster create 192.168.10.135:7001 192.168.10.135:7002 192.168.10.135:7003 192.168.10.135:7004 192.168.10.135:7005 192.168.10.135:7006 --cluster-replicas 1,其中cluster-replicas表示每个主节点有几个从节点,执行后每个节点目录下会有nodes.conf,记录所有其他节点的信息、主从节点、槽分配等连接集群:
./redis-cli –h 127.0.0.1 –p 7001 –c(7001为集群中一个节点的redis端口)查看集群:
cluster info查看集群节点:
cluster nodes添加master:
./redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001重新分配hash槽(添加主节点后,需要重新分配):
./redis-cli --cluster reshard 127.0.0.1:7007,输入要分配的槽数目、接收槽的结点id(这里通过cluster nodes查看7007结点id)、源节点id(可以为all)、yes(开始分配槽)为7007添加从节点7008:
./redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7007 --cluster-slave --cluster-master-id d1ba0092526cdfe66878e8879d446acfdcde25d8,删除节点(需要先将该节点占有的slot分配出去):
/redis-cli --cluster del-node 127.0.0.1:7008 41592e62b83a8455f07f7797f1d5c071cffedb50
Jedis连接集群:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public void testJedisCluster() throws Exception {
//创建一连接,JedisCluster对象,在系统中是单例存在
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.10.133", 7001));
nodes.add(new HostAndPort("192.168.10.133", 7002));
nodes.add(new HostAndPort("192.168.10.133", 7003));
nodes.add(new HostAndPort("192.168.10.133", 7004));
nodes.add(new HostAndPort("192.168.10.133", 7005));
nodes.add(new HostAndPort("192.168.10.133", 7006));
JedisCluster cluster = new JedisCluster(nodes);
//执行JedisCluster对象中的方法,方法和redis一一对应。
cluster.set("cluster-test", "my jedis cluster test");
String result = cluster.get("cluster-test");
System.out.println(result);
//程序结束时需要关闭JedisCluster对象
cluster.close();
}
redis应用问题与解决
- 用户发起请求,系统查询redis集群,如果redis有数据则返回,如果没有则查询数据库,如果有数据则存入redis,redis再返回给用户,没有则直接返回给用户
缓存穿透
key对应的数据在数据库和redis中都没有,用户仍然不断发起请求,使得每次请求都会到数据库,从而压垮数据库——比如,用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有
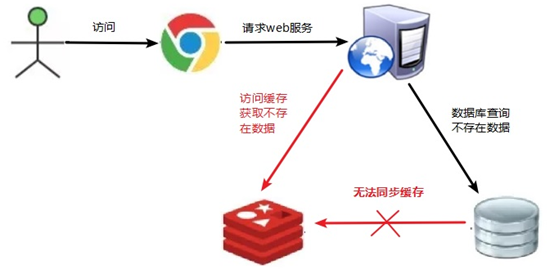
由于redis缓存是在不命中时被动写的,并且出于容错考虑如果数据库查不到数据则不写入缓存,导致不存在的数据每次请求都要到数据库查询,失去了缓存的意义
方案:
- 业务层校验:校验用户发过来的请求参数
- 对空值缓存:一个查询返回的数据为空(无论数据是否不存在),仍然把null缓存——null的过期时间很短,不超过五分钟
- 设置可访问的名单(白名单):bitmaps定义一个白名单,名单id作为bitmaps的偏移量,如果访问id不在bitmaps里面则不允许访问
- 采用布隆过滤器(Bloom Filter):
- 过滤器是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数),用于检索一个元素是否在(或者可能在)一个集合中,空间效率和查询时间都远超过一般算法,但有一定的误识别率并且删除困难
- 所有可能存在的数据都hash到一个足够大的Bloom Filter,一定不存在的数据会被filter拦截,避免了对底层存储的查询压力
- 实时监控:发现Redis的命中率开始急速降低时,排查访问对象和访问的数据,设置黑名单限制访问
缓存击穿
热点key(一定时间内超高并发地访问)对应的数据存在,但在redis中过期,此时大量并发请求过来,大并发的请求同时从后端DB加载数据并加载到缓存,压垮数据库——例如,秒杀时间点,大量用户访问一个商品,但商品信息在redis中过期,大量请求同时到达数据库
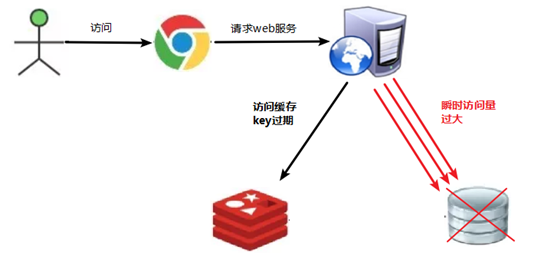
方案:
预先设置热门数据:一些热门数据提前存入到redis
实时调整:监控热门数据,实时调整key的过期时长
设置热点数据永不过期
互斥锁:
key的value为空时,不立即去load db,先对该key上锁(利用redis中某些带成功操作返回值的命令,如setnx,set一个mutexkey,此时该命令返回值为ok),再load db,完成后释放锁(删除这个mutexkey)
若线程B也请求该key,此时setnx命令返回值为fail,说明线程A在load db,则线程B睡眠100ms后重试
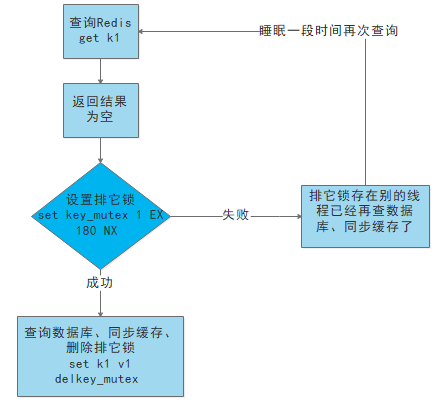
缓存雪崩
key对应的数据存在,但redis中数据大面积同时过期,或Redis宕机,此时大量请求直接发到数据库,压垮数据库(缓存雪崩与缓存击穿的区别,雪崩针对很多key缓存,击穿则是某一个热点key)
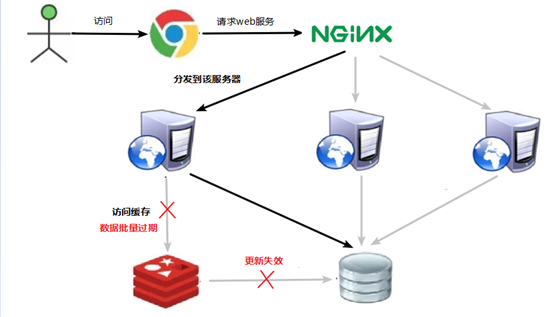
方案:
构建多级缓存:nginx缓存 + redis缓存 +其他缓存(ehcache等)
使用锁或队列:加锁或者队列,保证不会有大量的线程同时对数据库读写,不适用高并发情况
数据预热:对于即将来临的大量请求,提前走一遍系统,数据提前缓存在Redis中,并设置不同的过期时间
key的过期时间均匀分布:原有的失效时间基础上增加一个随机值
分布式锁
跨JVM的互斥机制控制共享资源的访问
主流实现方案:
- 基于数据库实现分布式锁
- 基于缓存(Redis等)——性能最高
- 基于Zookeeper——可靠性最高
setnx作为分布式锁!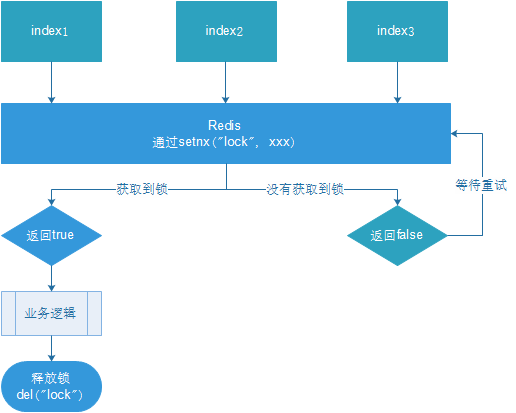
释放方式可以主动del该key,或者设置过期时间,过期时间在上锁后设置。为了实现上锁和设置过期时间的原子性,防止上锁后服务器突然出问题导致无法设置过期时间,需要上锁的同时,设置过期时间:
set <key> nx ex <time>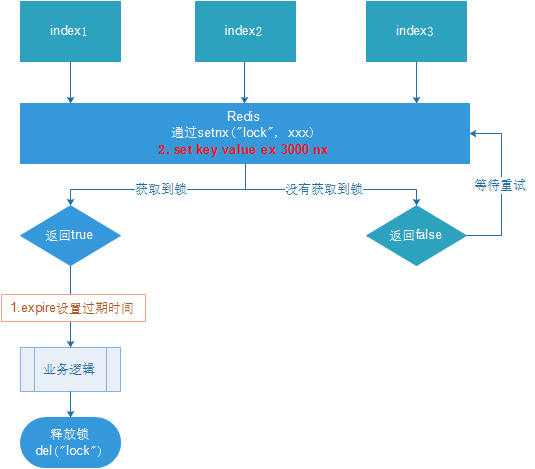
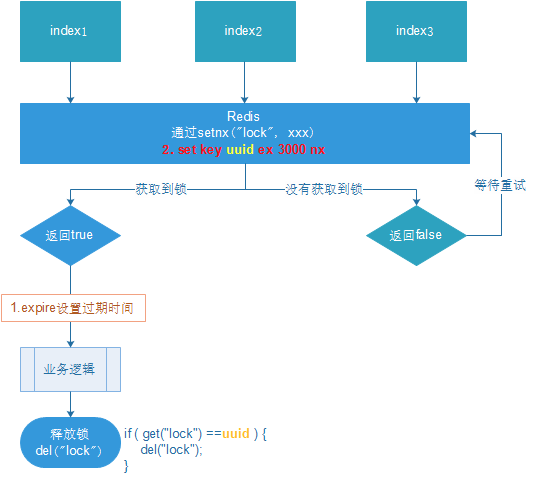
防止释放其他服务器的锁:设置uuid,即获取锁时,设置一个指定的唯一值,释放前再次获取这个值,判断是否为自己的锁
- index1业务逻辑没执行完,3秒后锁被自动释放。index2获取到锁,执行业务逻辑,3秒后锁被自动释放。index3获取到锁,执行业务逻辑。index1业务逻辑执行完成,开始调用del释放锁,这时释放的是index3的锁,导致index3的业务只执行1s就被别人释放
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31public void testLock(){
String uuid = UUID.randomUUID().toString();
//1获取锁,setne
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 3, TimeUnit.SECONDS);
//2获取锁成功、查询num的值
if(lock){
Object value = redisTemplate.opsForValue().get("num");
//2.1判断num为空
if(StringUtils.isEmpty(value)){
return;
}
//2.2有值就转成成int
int num = Integer.parseInt(value+"");
//2.3把redis的num加1
redisTemplate.opsForValue().set("num", ++num);
//2.4释放锁,del
//判断比较uuid值是否一样
String lockUuid = (String)redisTemplate.opsForValue().get("lock");
if(lockUuid.equals(uuid)) {
redisTemplate.delete("lock");
}
}else{
//3获取锁失败、每隔0.1秒再获取
try {
Thread.sleep(100);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}LUA脚本保证删除的原子性,即判断uuid一致和锁删除要是原子的(上面不具有原子性,index1判断uuid一致,但此时刚好过期,锁自动删除,index2获取锁,然后index1刚好删除这个锁)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47public void testLockLua() {
//1 声明一个uuid ,将做为一个value 放入我们的key所对应的值中
String uuid = UUID.randomUUID().toString();
//2 定义一个锁:lua 脚本可以使用同一把锁,来实现删除!
String skuId = "25"; // 访问skuId 为25号的商品 100008348542
String locKey = "lock:" + skuId; // 锁住的是每个商品的数据
// 3 获取锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid, 3, TimeUnit.SECONDS);
// 第一种: lock 与过期时间中间不写任何的代码。
// redisTemplate.expire("lock",10, TimeUnit.SECONDS);//设置过期时间
// 如果true
if (lock) { // 执行的业务逻辑
// 获取缓存中的 num 数据
Object value = redisTemplate.opsForValue().get("num");
// 如果是空直接返回
if (StringUtils.isEmpty(value)) {
return;
}
int num = Integer.parseInt(value + "");
// num+1 放入缓存
redisTemplate.opsForValue().set("num", String.valueOf(++num));
/*lua脚本解锁*/
// 定义lua 脚本
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// redis执行lua
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置返回值类型为Long(
// lua在判断的时候,返回的0为整数,这里如果不设置为long,默认返回 String 类型,和0的类型不匹配
redisScript.setResultType(Long.class);
// 第一个参数是script 脚本,第二个参数是要判断的key,第三个参数是ARGV
redisTemplate.execute(redisScript, Arrays.asList(locKey), uuid);
} else {
// 其他线程等待
try {
// 睡眠
Thread.sleep(1000);
// 睡醒了之后,调用方法。
testLockLua();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}为了确保分布式锁可用,要确保锁的实现同时满足:
- 互斥性。在任意时刻,只有一个客户端持有锁
- 无死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁
- 加锁和解锁必须是同一个客户端
- 加锁和解锁必须具有原子性

