SparkSQL——DataFrame、DataSet
概述
Spark Streaming用于流式数据的处理,基于Spark Core
- 数据处理方式:
- 流式数据处理(一条条处理)
- 批量数据处理(积攒一批数据,一起处理)
- 数据处理延迟长短:
- 实时数据处理(毫秒级别)
- 离线数据处理(小时/天级别)
- 数据处理方式:
Spark Streaming支持的数据源:Kafka、Flume、HDFS、TCP套接字,处理结果可以保存在HDFS、数据库
类似于RDD,Spark Streaming使用离散化流(discretized stream)作为抽象表示——准实时(秒为单位)、微批次(一批数据的量小)
- DStream是随时间推移而收到的数据(RDD)序列
- 每个时间区间收到的数据都作为RDD存在,DStream是这些RDD所组成的序列
- DStream是对RDD在实时数据处理场景的一种封装
特点:
- 易用
- 容错
- 可整合到Spark体系
架构:工作节点采集输入数据,分割后传给Driver,Driver封装为RDD,分发给其他工作节点执行任务
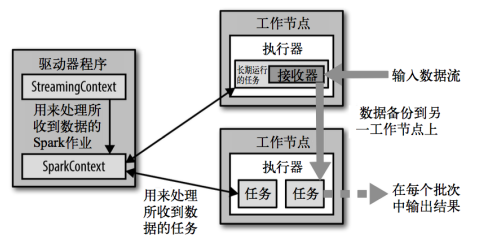
背压机制
- 上述架构存在“接收数据-消费数据”的速率问题,要防止数据的积压或资源的浪费
- 限制Receiver的数据接收速率,设置静态配制参 数
spark.streaming.receiver.maxRate - 背压机制能动态控制数据接收速率,以适配集群数据处理能力——根据JobScheduler反馈作业的执行信息,动态调整Receiver数据接收率
- 通过属性
spark.streaming.backpressure.enabled控制是否启用backpressure机制,默认false
DStream
WordCount示例
使用 netcat 工具向 9999 端口不断的发送数据,通过 SparkStreaming 读取端口数据并 统计不同单词出现的次数
添加依赖
1
2
3
4
5<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.3</version>
</dependency>代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22object RDDStream {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDStream")
//SparkStreaming上下文
val ssc = new StreamingContext(conf, Seconds(4)) // 批量处理(采集数据)的时间周期
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999) // 获取端口数据
val words = lines.flatMap(_.split(" "))
val wordToOne = words.map((_,1))
val wordToCount: DStream[(String, Int)] = wordToOne.reduceByKey(_+_)
wordToCount.print() // 自动打印时间戳
// 长期执行的任务,所以不能直接关闭(ssc.stop),并且不能让main方法结束
// 启动采集器
ssc.start()
// 等待采集器的关闭
ssc.awaitTermination()
}
}解析:
DStream代表持续性的数据流和经过各种Spark原语操作后的结果数据流。内部实现上,DStream是一系列连续的RDD表示,每个RDD含有一段时间间隔内的数据
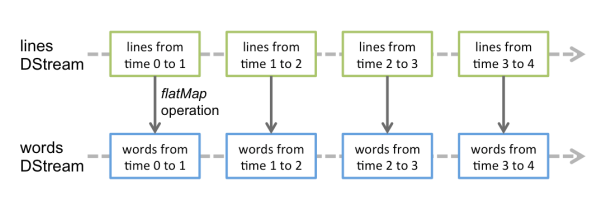
对数据的操作按照RDD为单位进行
计算过程由Spark Engine完成
DStream创建
RDD队列
通过
ssc.queueStream(queueOfRDDs)创建 DStream,每一个推送到该队列的RDD,都会作为一个DStream处理举例:创建多个RDD放入队列,创建DStream,计算WordCount
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23object RDDStream {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDStream")
val ssc = new StreamingContext(conf, Seconds(4))
//创建 RDD 队列
val rddQueue = new mutable.Queue[RDD[Int]]()
//创建 QueueInputDStream
val inputStream = ssc.queueStream(rddQueue, oneAtATime = false)
//处理队列中的 RDD 数据
val mappedStream = inputStream.map((_, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
//打印结果
reducedStream.print()
//启动任务
ssc.start()
//循环创建并向 RDD 队列中放入 RDD
for (i <- 1 to 5) {
rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
}
自定义数据源
继承Receiver,实现onStart、onStop方法自定义数据源采集
自定义数据源的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val messageDS: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver())
messageDS.print()
ssc.start()
ssc.awaitTermination()
}
//自定义数据采集器:继承Receiver,定义泛型, 传递参数,重写方法
class MyReceiver extends Receiver[String](StorageLevel.MEMORY_ONLY) {
private var flg = true
override def onStart(): Unit = { // 启动采集器时的操作——独立于当前线程的新线程
new Thread(new Runnable {
override def run(): Unit = {
while (flg) {
val message = "采集的数据为:" + new Random().nextInt(10).toString
store(message) // 封装数据,封装级别为MEMORY_ONLY
Thread.sleep(500)
}
}
}).start()
}
override def onStop(): Unit = {
flg = false;
}
}监控某个端口号,获取该端口号内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class CustomerReceiver(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {
//最初启动的时候,调用该方法,作用为:读数据并将数据发送给 Spark
override def onStart(): Unit = {
new Thread("Socket Receiver") {
override def run() {
receive()
}
}.start()
}
//读数据并将数据发送给 Spark
def receive(): Unit = {
//创建一个Socket
var socket: Socket = new Socket(host, port)
//端口传过来的数据
var input: String = null
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream, StandardCharsets.UTF_8))
//读取数据
input = reader.readLine()
//当 receiver 没有关闭并且输入数据不为空,循环发送数据给 Spark
while (!isStopped() && input != null) {
store(input)
input = reader.readLine()
}
//跳出循环则关闭资源
reader.close()
socket.close()
//重启任务
restart("restart")
}
override def onStop(): Unit = {}
}
Kafka数据源
ReceiverAPI:需要一个专门的Executor接收数据,给其他的Executor计算
- 接收数据Executor、计算Executor速度不同,若接收数据Executor速度大于计算的 Executor速度,将使得计算节点内存溢出
- 早期版本中提供此方式,当前版本不适
DirectAPI:计算Executor主动消费Kafka的数据,速度由自身控制
添加依赖
1
2
3
4
5
6
7
8
9
10<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.1</version>
</dependency>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
* 代码
```scala
package TestSparkStreaming
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{
ConsumerStrategies, KafkaUtils,
LocationStrategies
}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaReceiver {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")
val ssc = new StreamingContext(sparkConf, Seconds(3))
//定义 Kafka 参数
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "test", // 消费者组
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
//读取 Kafka 数据创建 DStream
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("test"), kafkaPara) //
)
//将每条消息的 KV 取出
val valueDStream: DStream[String] = kafkaDStream.map(record => record.value())
//计算 WordCount
valueDStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
ssc.start()
ssc.awaitTermination()
}
}
DStream转换
- DStream的操作与RDD类似,分为Transformations(转换)、Output Operations(输 出)
- 转换操作还有一些特殊的原语,如:
updateStateByKey()、transform()以及Window相关的原语
无状态转化操作
把RDD转化操作应用到每个批次上——转化DStream中的每个RDD
针对键值对的DStream转化操作(如reduceByKey())要添加
import StreamingContext._才能在Scala中使用
Transform
DStream上执行任意的RDD-to-RDD函数(获取底层的RDD进行转换)
该函数每一批次调度一次——也是对DStream中的RDD应用转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19val newDS: DStream[String] = lines.transform(
rdd => {
// Code: Driver端,(周期性执行)
rdd.map(
str => {
// Code : Executor端
str
}
)
}
)
// Code : Driver端
val newDS1: DStream[String] = lines.map(
data => {
// Code : Executor端
data
}
)
join
- 两个流之间的join需要两个流的批次大小一致,才能做到同时触发计算
- 计算过程是对两个流当前批次各自的RDD执行join,与两个RDD的join效果相同
有状态转化操作
UpdateStateByKey
- 在DStream中跨批次维护状态(如,流计算中累加wordcount)
updateStateByKey()提供对一个状态变量的访问,用于键值对形式的DStream- 一个由KV构成的DStream,一个根据新事件更新Key对应状态的函数,返回一个新的DStream,RDD序列为每个时间区间对应的(键,状态)对
- 需要:
- 定义状态——状态可以是一个任意的数据类型。
- 定义状态更新函数——如何使用之前的状态和来自输入流的新值对状态进行更 新
- 配置checkpoint目录,会使用检查点保存状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
val conf = new SparkConf().setMaster("local[*]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("./ck")
val lines = ssc.socketTextStream("linux1", 9999)
val words = lines.flatMap(_.split(" "))
// Count each word in each batch
val pairs = words.map(word => (word, 1))
// 使用 updateStateByKey 来更新状态,统计从运行开始以来单词总的次数
val stateDstream = pairs.updateStateByKey[Int](updateFunc)
stateDstream.print()
ssc.start()
ssc.awaitTermination()WindowOperation
设置窗口的大小和滑动窗口的间隔,动态获取当前Steaming的允许状态。所有基于窗口的操作都需要参数:窗口时长、滑动步长
窗口时长:计算内容的时间范围,应当为采集周期的整数倍
滑动步长:隔多久触发一次计算,应当为采集周期的整数倍(默认滑动幅度为1个采集周期)
1
2
3
4
5
6
7val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_,1))
val windowDS: DStream[(String, Int)] = wordToOne.window(Seconds(6), Seconds(6))
val wordToCount = windowDS.reduceByKey(_+_)
wordToCount.print()
其他Window操作:
window(windowLength, slideInterval):基于对源 DStream 窗化的批次进行计算countByWindow(windowLength, slideInterval):返回一个滑动窗口中的元素个数reduceByWindow(func, windowLength, slideInterval):使用自定义函数,整合滑动区间的元素来创建一个新的流reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]):在一个(K,V) 对的DStream上调用,返回一个新(K,V)对DStream;对滑动窗口中批数据使用reduce函数,整合每个key的value
DStream输出
- 如果一个DStream及其派生出的DStream没有被执行输出操作,这些DStream都不会被求值——如果StreamingContext中没有设定输出操作,整个context都不会启动
- 输出操作如下:
print():打印DStream中每一批次数据的最开始10个元素saveAsTextFiles(prefix, [suffix]):以text文件形式存储DStream的内容。每一批次的存储文件名基于参数中的prefix和suffixsaveAsObjectFiles(prefix, [suffix]):Java对象序列化的方式将Stream中的数据保存为SequenceFiles。每一批次的存储文件名基于参数中的prefix和suffixsaveAsHadoopFiles(prefix, [suffix]):将Stream中的数据保存为Hadoop files。每一批次的存储文件名基于参数中的prefix和suffix,”prefix-TIME_IN_MS[.suffix]”。foreachRDD(func):最通用的输出操作,将函数func用于产生于stream的每一个 RDD。函数func应该将每一个RDD中数据推送到外部系统,例如将RDD存入文件或通过网络将其写入数据库
关闭
计算节点不再接收新的数据,等当前数据处理结束后结束线程——启动采集器后,应当创建一个新的线程,负责关闭
ssc.stop(stopSparkContext = true, stopGracefully = true)利用第三方的存储(外部文件系统)作为flag,标识着线程是否需要关闭——例如,Redis的一个kv,MySQL的一个table,hdfs、zk的一个文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
wordToOne.print()
ssc.start()
// 如果想要关闭采集器,那么需要创建新的线程
// 而且需要在第三方程序中增加关闭状态
new Thread(
new Runnable {
override def run(): Unit = {
// 计算节点不接收新的数据,而是将现有的数据处理完毕,然后关闭
// Mysql : Table(stopSpark) => Row => data
// Redis : Data(K-V)
// ZK : /stopSpark
// HDFS : /stopSpark
Thread.sleep(5000)
val state: StreamingContextState = ssc.getState()
if (state == StreamingContextState.ACTIVE) {
ssc.stop(true, true)
}
System.exit(0)
}
}
).start()
ssc.awaitTermination() // block 阻塞main线程
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class MonitorStop(ssc: StreamingContext) extends Runnable {
// 借助hdfs
override def run(): Unit = {
val fs: FileSystem = FileSystem.get(new URI("hdfs://linux1:9000"), new Configuration(), "atguigu")
while (true) {
try
Thread.sleep(5000)
catch {
case e: InterruptedException =>
e.printStackTrace()
}
val state: StreamingContextState = ssc.getState
val bool: Boolean = fs.exists(new Path("hdfs://linux1:9000/stopSpark"))
if (bool) {
if (state == StreamingContextState.ACTIVE) {
ssc.stop(stopSparkContext = true, stopGracefully = true)
System.exit(0)
}
}
}
}
}

