Spark内核:组件(Driver、Executor)通信、Job的调度(Stage调度、Task调度)
Yarn环境
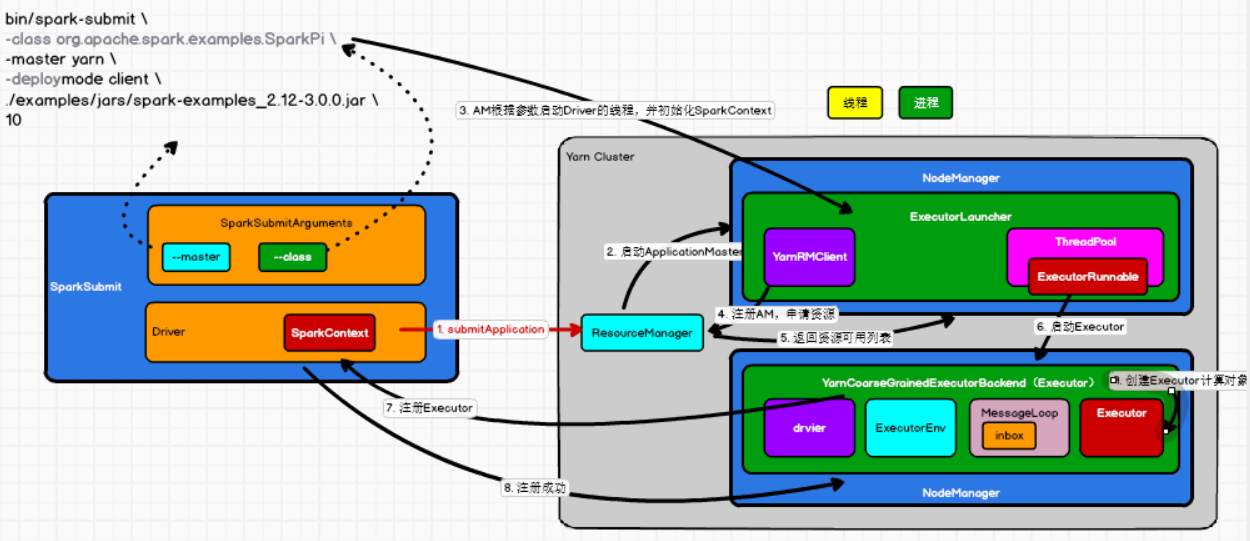
Yarn Client
过程:
- 执行脚本提交任务(spark-submit),实际是启动一个 SparkSubmit 的 JVM 进程
- SparkSubmit 类中的 main 方法反射调用用户代码的 main 方法
- 启动 Driver 线程,执行用户的作业,创建 ScheduleBackend
- YarnClientSchedulerBackend 向 RM 发送指令:bin/java ExecutorLauncher
- Yarn 框架收到指令后在指定的 NM 中启动 ExecutorLauncher(还是调用 ApplicationMaster 的 main 方法)
- AM 向 RM 注册,申请资源
- 获取资源后 AM 向 NM 发送指令:bin/java CoarseGrainedExecutorBackend
- CoarseGrainedExecutorBackend 进程接收消息,跟 Driver 通信,注册已经启动的 Executor;启动计算对象 Executor 等待接收任务
- Driver 分配任务并监控任务的执行
SparkSubmit、ApplicationMaster 和 CoarseGrainedExecutorBackend 是独立的进程,Executor 和 Driver 是对象
Yarn Cluster模式
过程:
- 执行脚本提交任务,实际是启动一个 SparkSubmit 的 JVM 进程;
- SparkSubmit 类中的 main 方法反射调用 YarnClusterApplication 的 main 方法
- YarnClusterApplication 创建 Yarn 客户端,向 Yarn 服务器发送执行指令:bin/java ApplicationMaster
- Yarn 框架收到指令后在指定的 NM 中启动 ApplicationMaster
- AM 启动 Driver 线程,执行用户的作业
- AM 向 RM 注册,申请资源
- 获取资源后 AM 向 NM 发送指令:bin/java YarnCoarseGrainedExecutorBackend;
- CoarseGrainedExecutorBackend 进程接收消息,跟 Driver 通信,注册已经启动的 Executor;启动计算对象 Executor 等待接收任务
- Driver 线程继续执行,完成作业的调度和任务的执行
- Driver 分配任务并监控任务的执行
SparkSubmit、ApplicationMaster 和 YarnCoarseGrainedExecutorBackend 是独立的进程;Driver 是独立的线程;Executor 和 YarnClusterApplication 是对象
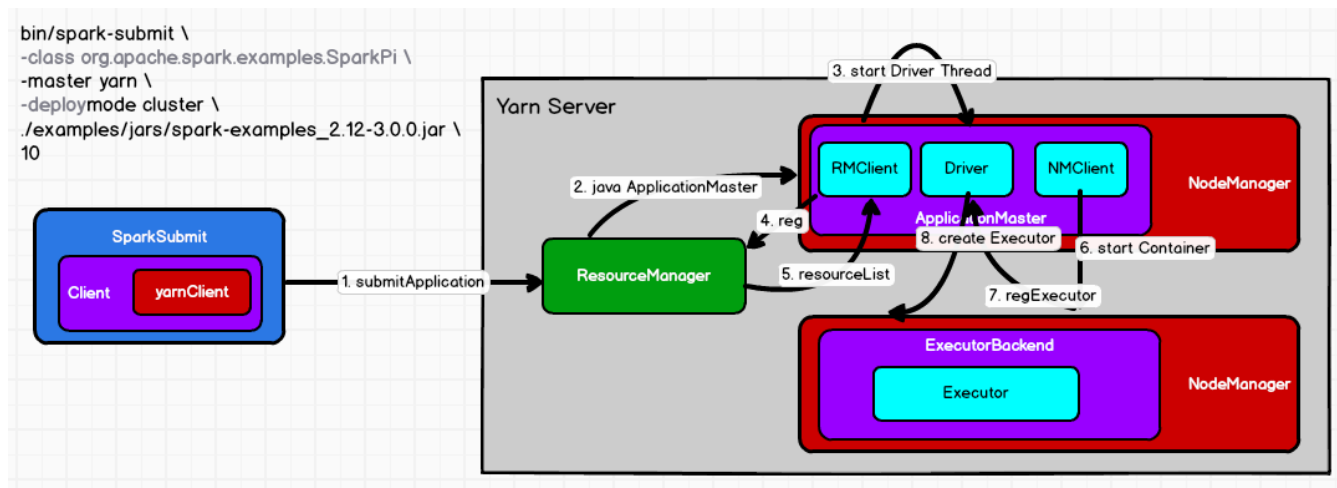
两个模式的区别在于driver的运行位置!
组件通信
Netty通信框架,AIO
- AIO:异步非阻塞式IO,客户端在请求数据的过程中,不用保持一个连接,可以做其他事情。一个通知机制,客户端请求数据。服务端若有则返回数据,若无则客户端断开连接做其他事情,服务端有数据后主动通知客户端并返回数据
- BIO:阻塞式IO,客户端在请求数据的过程中,保持一个连接,不能做其他事情。对于客户端和服务端而言,都需要一个线程来维护这个连接,如果服务端没有数据给客户端,则客户端需要一直等待
- NIO:非阻塞式IO,客户端在请求数据的过程中,不用保持一个连接,不能做其他事情。客户端建立连接请求数据,服务端没有数据时客户端断开连接,一段时间后重新建立连接询问
- 同步、异步:客户端在请求数据的过程中,能否做其他事情;阻塞、非阻塞:客户端与服务端是否始终有一个持续连接,占用通道
Linux采用Epoll方式模拟AIO
通信环境:
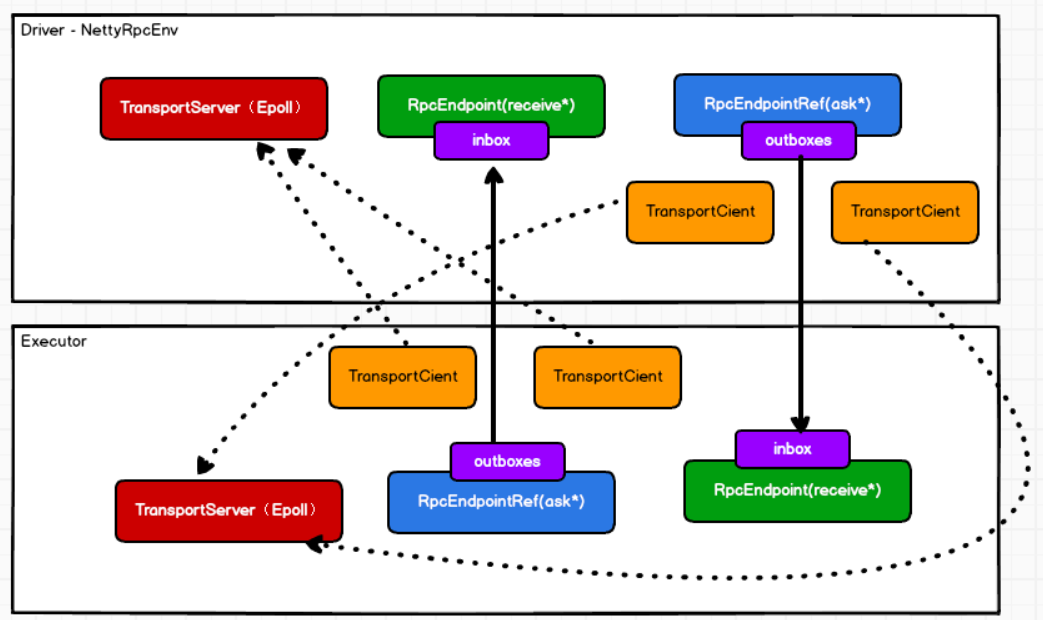
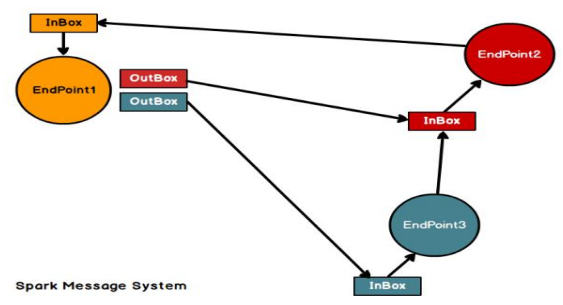
框架中各个组件(Client/Master/Worker)可以认为是独立的实体,各实体通过消息通信,Endpoint(Client/Master/Worker)有1个InBox和N个OutBox(N取决于该Endpoint与多少其他Endpoint通信),接收到的消息写入InBox,发送的消息写入OutBox并发到其他Endpoint的InBox
终端driver的类:
class DriverEndpoint extends IsolatedRpcEndpoint;executor的类:class CoarseGrainedExecutorBackend extends IsolatedRpcEndpoint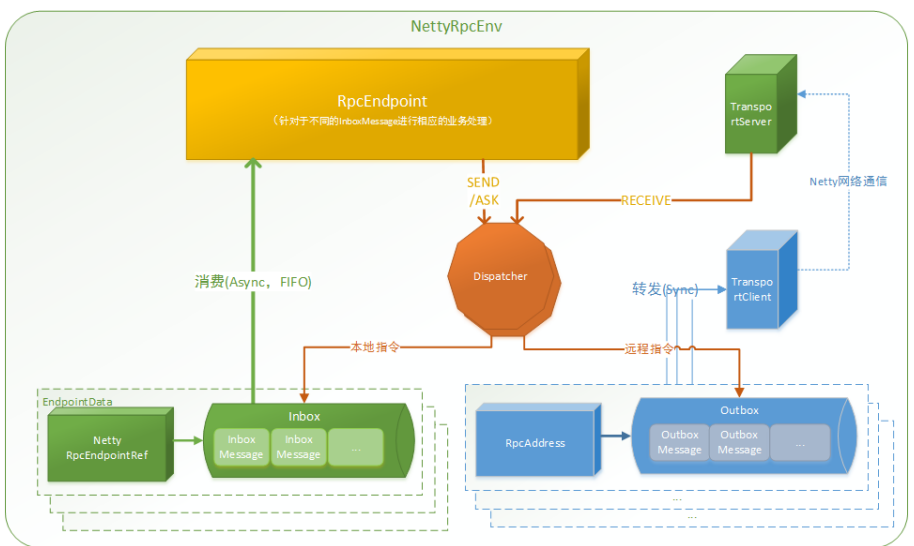
NettyRpcEnv:RPC 上下文环境,每个RPC终端运行时依赖的上下文环境
RpcEndpoint:RPC终端
- 每个节点(Client/Master/Worker)都称为一个RPC终端,实现RpcEndpoint接口
- 根据不同端点的需求,设计不同的消息和不同的业务处理
- 需要发送(询问)则调用Dispatcher
Dispatcher:消息调度(分发)器,将RPC终端发送、接收的远程消息分发至对应的指令收件箱(发件箱)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// class NettyRpcEnv
private[netty] def send(message: RequestMessage): Unit = {
// 获取接收者地址信息
val remoteAddr = message.receiver.address
if (remoteAddr == address) {
// Message to a local RPC endpoint.
// 把消息发送到本地的 RPC 端点 (发送到收件箱)
try {
dispatcher.postOneWayMessage(message)
} catch {
case e: RpcEnvStoppedException => logWarning(e.getMessage)
}
} else {
// Message to a remote RPC endpoint.
// 把消息发送到远程的 RPC 端点. (发送到发件箱)
postToOutbox(message.receiver, OneWayOutboxMessage(serialize(message)))
}
}Inbox:指令消息收件箱
- 一个RpcEndpoint对应一个收件箱
- Dispatcher向Inbox存入消息时,将对应EndpointData加入内部ReceiverQueue
- Dispatcher创建时会启动一个线程轮询ReceiverQueue,进行收件箱消息消费
RpcEndpointRef:对远程RpcEndpoint的一个引用。当需要向一个具体的RpcEndpoint发送消息时,需要获取该RpcEndpoint的引用,通过该引用发送消息
OutBox:指令消息发件箱
- 一个目标RpcEndpoint对应一 个发件箱
- 消息放入Outbox后,通过TransportClient发送消息,消息放入发件箱和发送在同一个线程中进行
RpcAddress:RpcEndpointRef的地址,Host + Port
TransportClient:Netty通信客户端
- 一个OutBox对应一个TransportClient
- TransportClient不断轮询OutBox,根据OutBox消息的receiver信息,请求对应的远程TransportServer
TransportServer:Netty 通信服务端
- 一个RpcEndpoint对应一个TransportServer
- 接收远程消息后调用Dispatcher分发消息至收发件箱
Spark任务调度
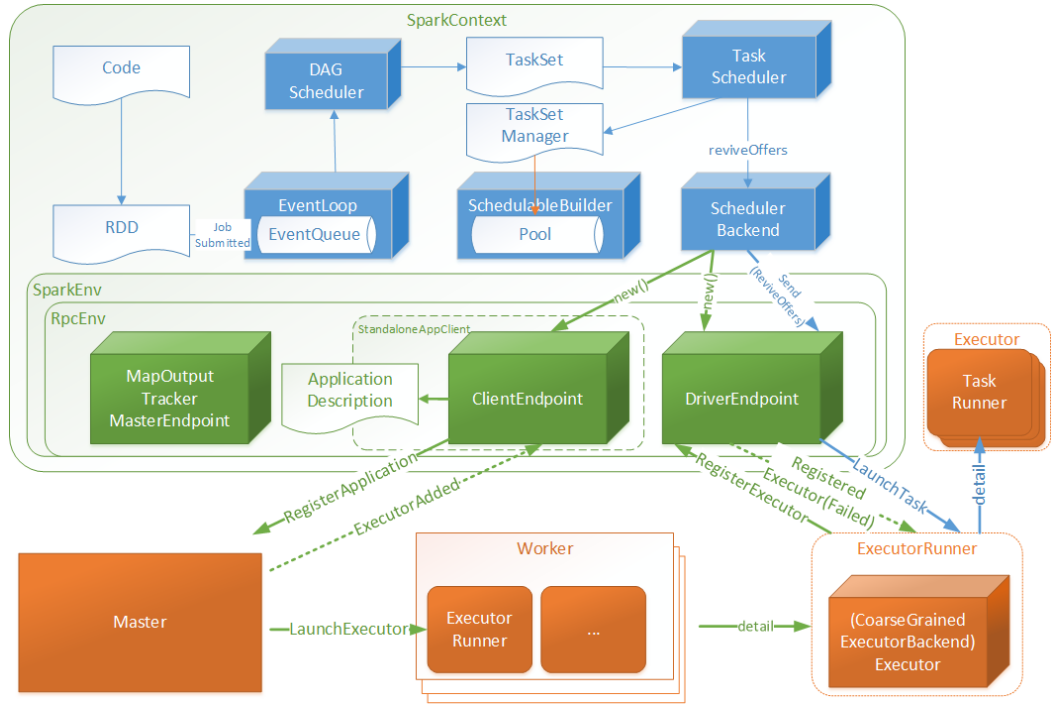
Yarn-Cluster模式下,任务提交,启动Driver线程后,Driver初始化SparkContext对象,准备运行的上下文,保持与ApplicationMaster的RPC连接,通过ApplicationMaster申请资源,同时根据用户业务逻辑调度任务,将任务下发到已有的空闲Executor。ResourceManager向ApplicationMaster返回Container资源时,ApplicationMaster尝试在对应的Container启动Executor进程,启动后Executor向Driver反向注册,保持与Driver的心跳,等待Driver分发任务,执行完分发任务会将任务状态上报给Driver
一个Spark任务包括:
Job:以Action算子为界,遇到一个Action算子则触发一个Job
Stage:Job的子集,以RDD宽依赖(Shuffle)为界
Task:Stage的子集,以并行度(分区数)衡量,分区数多少则有多少个task
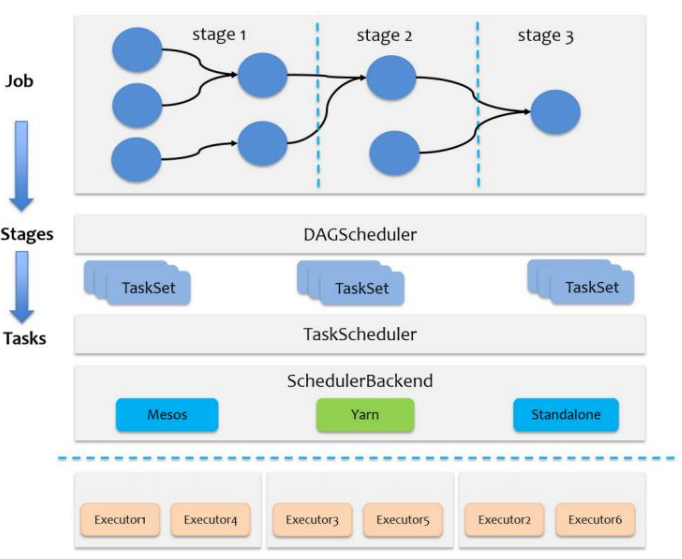
Spark RDD通过转换算子形成了RDD血缘(依赖)关系图DAG,通过Action的调用,触发Job并调度执行,执行中创建两个调度器:DAGScheduler、TaskScheduler
- DAGScheduler:负责Stage级调度,将job切分成若干Stages,将每个Stage打包成TaskSet交给TaskScheduler调度
- TaskScheduler:负责Task级调度,将TaskSet按指定的调度策略分发到Executor执行
- 调度过程中SchedulerBackend提供可用资源,SchedulerBackend有多种实现,对应不同资源管理系统
Driver初始化SparkContext时:
- 初始化DAGScheduler、TaskScheduler、SchedulerBackend(通信后台)、HeartbeatReceiver、SparkConf(配置对象)、SparkEnv(通信环境),启动SchedulerBackend、HeartbeatReceiver
- SchedulerBackend通过ApplicationMaster申请资源,从TaskScheduler拿到合适的Task分发到Executor执行
- HeartbeatReceiver负责接收Executor心跳信息,监控Executor存活状况,通知TaskScheduler
Stage级调度
Job提交的方法调用流程:
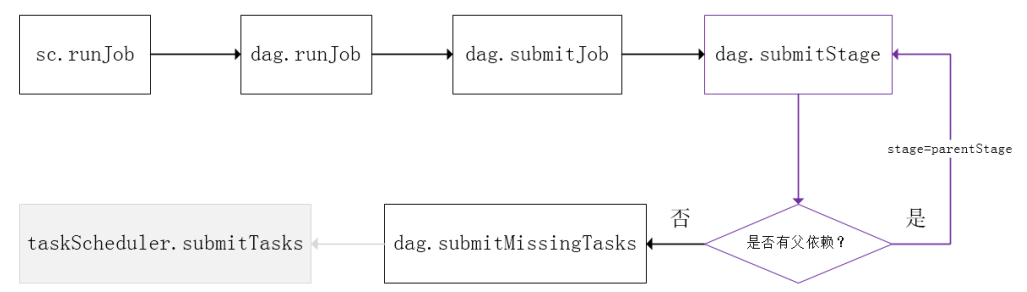
Job由最终的RDD和Action算子封装成
SparkContext将Job交给DAGScheduler,DAGScheduler根据RDD的血缘关系构成的DAG划分多个Stage:
由最终RDD不断通过依赖回溯判断父依赖是否是宽依赖,窄依赖的RDD之间划分到同一个Stage
划分的Stages分两类: ResultStage(DAG最下游的Stage,由Action方法决定),ShuffleMapStage(为下游Stage准备数据)
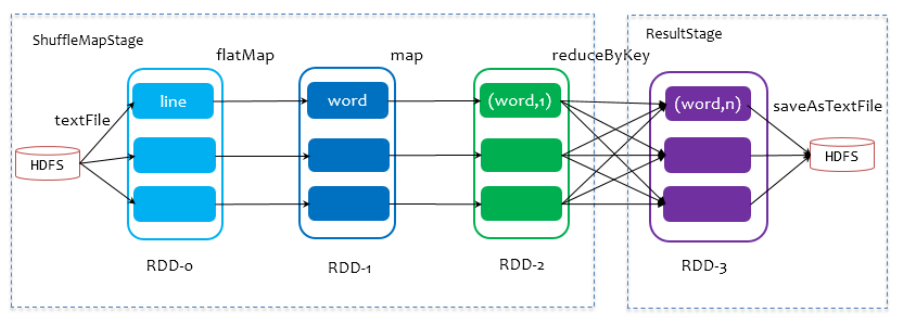
一个Stage是否被提交,需要判断父Stage是否执行,父Stage执行完毕才能提交当前Stage。Stage提交时会将Task信息(分区信息、算子等)序列化并打包成TaskSet交给TaskScheduler,一个Partition对应一个Task
TaskScheduler监控Stage的运行状态,只有Executor丢失或Task由于Fetch失败才重新提交失败的Stage,其他类型Task失败在TaskScheduler的调度中重试
Stage级调度的源码
SparkContext初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 用来与其他组件通讯用
private var _schedulerBackend: SchedulerBackend = _
// DAG 调度器, 是调度系统的中的中的重要组件之一, 负责创建 Job, 将 DAG 中的 RDD 划分到不同的 Stage, 提交 Stage 等.
// SparkUI 中有关 Job 和 Stage 的监控数据都来自 DAGScheduler
private var _dagScheduler: DAGScheduler = _
// TaskScheduler 按照调度算法对集群管理器已经分配给应用程序的资源进行二次调度后分配给任务
// TaskScheduler 调度的 Task 是由DAGScheduler 创建的, 所以 DAGScheduler 是 TaskScheduler的前置调度器
private var _taskScheduler: TaskScheduler = _
// 创建 SchedulerBackend 和 TaskScheduler
val (sched, ts):(SchedulerBackend, TaskScheduler) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
// 创建 DAGScheduler
_dagScheduler = new DAGScheduler(this)
// 启动 TaskScheduler, 内部会也会启动 SchedulerBackend
_taskScheduler.start()Action算子的runJob方法
1
2
3
4
5
6
7
8
9
10
11
12
13def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
// 作业的切分
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
}DAGScheduler类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
// 提交任务 返回值 JobWaiter 用来确定 Job 的成功与失败
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
}
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// 创建 JobWaiter 对象
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
// 向内部事件循环器发送消息 JobSubmitted
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
// 处理提交的 Job
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
}
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
// Stage 的划分是从后向前推断的, 所以先创建最后的阶段
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
}
submitStage(finalStage)
}
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
// 1. 获取所有父 Stage 的列表
val parents: List[Stage] = getOrCreateParentStages(rdd, jobId)
// 2. 给 resultStage 生成一个 id
val id = nextStageId.getAndIncrement()
// 3. 创建 ResultStage
val stage: ResultStage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
// 4. stageId 和 ResultStage 做映射
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
// 获取所有的 Shuffle 依赖(宽依赖)
getShuffleDependencies(rdd).map { shuffleDep =>
// 对每个 shuffle 依赖, 获取或者创建新的 Stage: ShuffleMapStage
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
// 得到所有宽依赖
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 获取所有的父 Stage
val missing = getMissingParentStages(stage).sortBy(_.id)
// 如果为空, 则提交这个 Stage
if (missing.isEmpty) {
submitMissingTasks(stage, jobId.get)
} else { // 如果还有父 Stage , 则递归调用
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
}
}
private def submitMissingTasks(stage: Stage, jobId: Int) {
// 任务划分. 每个分区创建一个 Task
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
} catch {
}
// 提交任务
if (tasks.size > 0) {
// 使用 taskScheduler 提交任务
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
} else {
}
}TaskScheduler类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
this.synchronized {
// 创建 TaskManger 对象. 用来追踪每个任务
val manager: TaskSetManager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
// manage 和 TaskSet 交给合适的任务调度器来调度
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
}
// 跟 ExecutorBackend 通讯
backend.reviveOffers()
}CoarseGrainedSchedulerBackend
1
2
3
4override def reviveOffers() {
// DriverEndpoint 给自己发信息: ReviveOffers
driverEndpoint.send(ReviveOffers)
}DriverEndpoint
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28private def makeOffers() {
// 过滤出 Active 的Executor
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
// 封装资源
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
// 启动任务
launchTasks(scheduler.resourceOffers(workOffers))
}
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
// 序列化任务
val serializedTask = ser.serialize(task)
if (serializedTask.limit >= maxRpcMessageSize) {
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
// 发送任务到 Executor. CoarseGrainedExecutorBackend 会收到消息
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}CoarseGrainedExecutorBackend
1
2
3
4
5
6
7
8
9
10
11
12
13override def receive: PartialFunction[Any, Unit] = {
//
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
// 把要执行的任务反序列化
val taskDesc = ser.deserialize[TaskDescription](data.value)
// 启动任务开始执行
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
}
Task级调度
Task的调度由TaskScheduler完成,TaskScheduler将TaskSet封装为TaskSetManager,加入调度队列——TaskSetManager监控管理同一个Stage中的Tasks,TaskScheduler以TaskSetManager为单元调度任务
Driver初始化TaskScheduler后,会启动SchedulerBackend,接收Executor注册信息、维护Executor状态、定期询问TaskScheduler是否有任务运行
TaskScheduler在SchedulerBackend询问时,从调度队列按照指定的调度策略选择TaskSetManager去调度运行
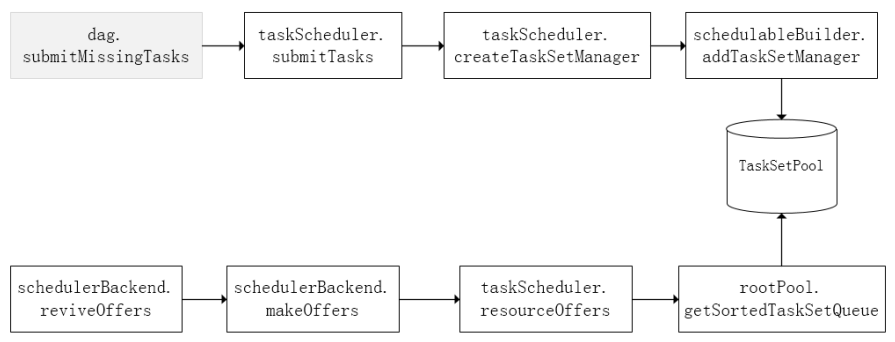
- 将TaskSetManager加入rootPool调度池后,调用SchedulerBackend.reviveOffers给driverEndpoint发送ReviveOffer消息
- driverEndpoint收到ReviveOffer消息后调用makeOffers方法,过滤得到活跃状态的Executor,将Executor封装成WorkerOffer对象
- 准备好计算资源 (WorkerOffer)后,taskScheduler基于计算资源调用resourceOffer在Executor上分配task
调度策略
TaskScheduler支持两种调度策略:FIFO(默认的调度策略)、FAIR
TaskScheduler初始化中会实例化rootPool(树的根节点,Pool类型)
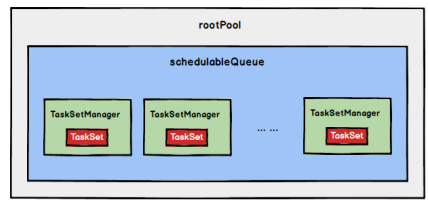
FIFO 调度策略:TaskSetManager按照先来先到的方式入队,树结构如下所示
FAIR 调度策略:树结构如下所示
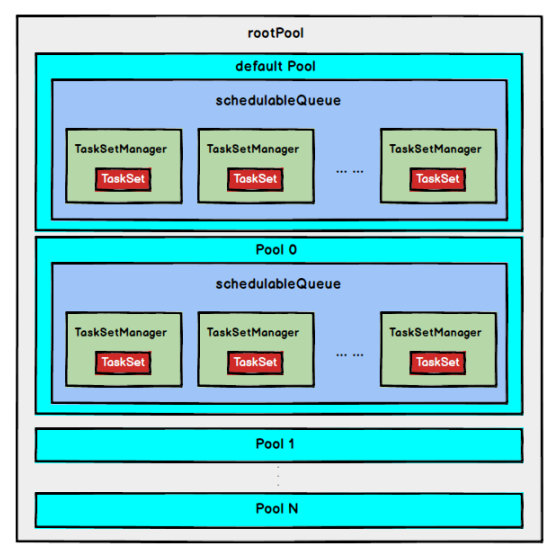
一个rootPool和多个子Pool,子Pool存储待分配的TaskSetMagager
先对子Pool排序,再对子Pool中的TaskSetMagager排序(排序算法相同)
排序过程的比较基于Fair-share,每个排序的对象包含三个属性: runningTasks值(正在运行的Task数)、minShare值、weight值,比较时综合考量runningTasks 值,minShare值、weight值(minShare使用率和权重使用率少——实际运行 task比例较少的先运行)
minShare、weight的值均在公平调度配置文件fairscheduler.xml指定,调度池在构建阶段读取此文件的相关配置
如果A对象的runningTasks大于它的minShare,B对象的runningTasks小于它的minShare, B排在A前面(runningTasks比minShare小的先执行)
A、B 对象的runningTasks都小于各自的minShare,比较runningTasks与minShare的比值(minShare使用率),minShare使用率低的先执行
A、B 对象的runningTasks都大于各自的minShare,比较runningTasks与weight的比值(权重使用率),权重使用率低的先执行
如果上述比较均相等,则比较名字
排序完成后,所有的TaskSetManager放入一个ArrayBuffer,依次被取出并发送给Executor执行
从调度队列中拿到TaskSetManager后,TaskSetManager按照一定的规则取出Task给TaskScheduler,TaskScheduler将Task交给SchedulerBackend发到Executor执行
失败重试与黑名单机制
- Task提交到Executor启动执行后,Executor会将执行状态上报给SchedulerBackend,SchedulerBackend告诉TaskScheduler,TaskScheduler找到该Task对应的TaskSetManager并通知,从而TaskSetManager知道Task的失败与成功状态
- 对于失败的Task,TaskSetManager记录失败的次数,如果次数没有超过最大重试次数,则放回待调度的Task池中,否则整个Application失败
- 记录Task失败次数过程,会记录Task上一次失败所在的Executor Id和Host,以及其对应的“拉黑”时间,下次再调度该Task时,使用黑名单机制,避免它被调度到上一次失败的节点
Task级调度源码
FIFO调度
1
2
3
4
5
6
7
8
9
10
11
12
13
14private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm {
// 是不是先调度 s1
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val priority1 = s1.priority
val priority2 = s2.priority
var res = math.signum(priority1 - priority2)
if (res == 0) {
val stageId1 = s1.stageId
val stageId2 = s2.stageId
res = math.signum(stageId1 - stageId2)
}
res < 0 // 值小的先调度
}
}Fair调度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0)
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0)
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
var compare = 0
if (s1Needy && !s2Needy) { // 谁的 runningTasks1 < minShare1 谁先被调度
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) { // 如果都 runningTasks < minShare
// 则比较 runningTasks / math.max(minShare1, 1.0) 的比值 小的优先级高
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
// 如果都runningTasks > minShare, 则比较 runningTasks / weight 的比值
// 小的优先级高
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
// 如果前面都一样, 则比较 TaskSetManager 或 Pool 的名字
s1.name < s2.name
}
}
}

