SparkSQL——DataFrame、DataSet
概述
Spark用于结构化数据(structured data)处理的Spark模块
Shark基于Hive,SparkSQL基于Shark,SparkSQL兼容Hive,可以从RDD、parquet文件、JSON文件
简化RDD开发,提供两个编程抽象(类似RDD):DataFrame、DataSet
特点:
- 易整合:无缝整合SQL查询和Spark编程
- 统一的数据访问:相同的方式连接不同的数据源
- 兼容Hive:已有的数据仓库上可以直接运行SQL、HiveQL
- 标准数据连接:通过JDBC、ODBC连接
写SQL语句时,自动将封装好的模型(DataFrame、DataSet)转换为RDD
DataFrame:
以RDD为基础的分布式数据集,类似传统数据库的二维表格
与RDD主要区别在于,DataFrame带有schema元信息(DataFrame所表示的二维表数据集的每一列都带有名称和类型),这使得Spark SQL对作用于DataFrame的变换进行针对性的优化,提升运行效率;RDD不知道所存数据元素的具体内部结构,Spark Core 只在stage层面进行简单、通用的流水线优化
DataFrame支持嵌套数据类型(struct、array 和 map)
DataFrame API提供高层的关系操作,比函数式的RDD API友好
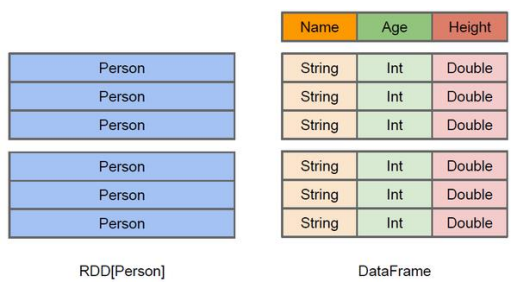
左侧RDD[Person]虽然以Person为类型参数,但本身不了解Person类的内部结构,DataFrame提供详细的结构信息,Spark SQL知道该数据集中包含哪些列,每列的名称和类型——DataFrame为数据提供Schema的视图
DataSet:
- 分布式数据集合,是DataFrame的一个扩展
- 可以使用功能性的转换(操作map,flatMap,filter等等)
- 具有类型安全检查、DataFrame的查询优化特性
- 用样例类对DataSet定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet中的字段名称
- DataSet是强类型的,可以有 DataSet[Car]、DataSet[Person]
- DataFrame是DataSet的特例,DataFrame=DataSet[T] ,因此可以通过as方法将DataFrame转换为DataSet
SparkSQL
SQL查询起点
Spark Core执行应用程序需要先构建上下文环境对象SparkContext,SparkSQL同样有上下文环境对象SparkSession——SparkSession内部封装SparkContext,计算实际上是由SparkContext完成
使用spark shell时,spark自动创建一个名为spark的SparkSession对象(同样的,会自动创建一个名为sc的SparkContext)
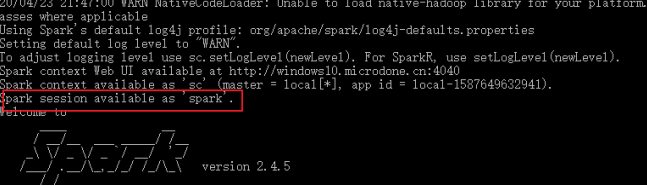
一个示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27scala> val df = spark.read.json("./user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> df.show
+---+--------+
|age|username|
+---+--------+
| 20|zhangsan|
| 30| lisi|
+---+--------+
scala> df.createTempView("user")
scala> spark.sql("select * from user").show
+---+--------+
|age|username|
+---+--------+
| 20|zhangsan|
| 30| lisi|
+---+--------+
scala> spark.sql("select avg(age) from user").show
+--------+
|avg(age)|
+--------+
| 25.0|
+--------+
DataFrame
- DataFrame API既有transformation操作也有action操作
创建DataFrame
- SparkSession是创建DataFrame和执行SQL的入口
- 创建DataFrame的三种方式:
- 通过Spark数据源创建
- Spark支持的数据源格式:csv format jdbc json load option options orc parquet schema table text textFile
- 读取json文件创建DataFrame:
val df = spark.read.json("data/user.json") - 文件读取时,数据字段按照字典序排序。例如,有字段username和age,即使数据源中age在username之后(
{"username": "thomas", "age": 10}),DataFrame的元数据中age会在username之前([age: bigint, username: string]) - 如果从内存获取数据,数字默认为Int,但从文件中读取的数字会用bigint接收,bigint可以和Long转换,不能和Int转换
- 从一个存在的RDD转换
- 从Hive Table进行查询返回
- 通过Spark数据源创建
SQL语法
用SQL语法查询:SQL语法的查询必须要有临时视图或全局视图辅助——普通的临时表是Session范围内的,如果要在应用范围内有效,使用全局临时表。全局临时表需要全路径访问,如:global_temp.people
对DataFrame创建一个临时视图(createOrReplaceTempView:防止多次创建导致重复),注意,视图和表不同,视图只能查询不能改,因为这个视图源于DataFrame
1
scala> df.createOrReplaceTempView("people")
使用SQL查询(临时视图people只在当前的会话中有效,如果换一个连接则无法访问)
1
2
3
4
5scala> val sqlDF = spark.sql("SELECT * FROM people")
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> spark.newSession().sql("SELECT * FROM people")
报错,table or view not found创建一个全局视图
1
2
3
4
5
6
7
8
9
10scala> df.createGlobalTempView("people")
scala> spark.sql("SELECT * FROM global_temp.people").show()
+---+--------+
|age|username|
+---+--------+
| 20|zhangsan|
| 30| lisi|
| 40| wangwu|
+---+--------+
DSL语法
特定领域语言(domain-specific language, DSL)(略)
RDD、DataFrame相互转换
RDD转DF:
RDD与DF、DS 之间互相操作需要引入
import spark.implicits._,这里spark是创建的SparkSession对象的变量名,即先创建SparkSession对象再导入。spark对象不能使用var声明,因为Scala只支持val修饰的对象的引入spark-shell中无需导入,自动完成此操作
1
2
3
4
5
6
7
8
9
10scala> val idRDD = sc.textFile("data/id.txt")
scala> idRDD.toDF("id").show
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
+---+实际开发中,一般通过样例类将RDD转换为DataFrame
1
2
3
4
5
6
7
8
9
10scala> case class User(name:String, age:Int)
defined class User
scala> sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1,
t._2)).toDF.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 30|
| lisi| 40|
+--------+---+
DF转RDD
DataFrame是对RDD的封装,可以直接获取内部的RDD
1
2
3
4
5
6
7
8scala> val df = sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> val rdd = df.rdd
rdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[46] at rdd at <console>:25
scala> val array = rdd.collect
array: Array[org.apache.spark.sql.Row] = Array([zhangsan,30], [lisi,40])此时RDD的存储类型为Row
1
2
3
4
5
6
7
8scala> array(0)
org.apache.spark.sql.Row = [zhangsan,30]
scala> array(0)(0)
Any = zhangsan
scala> array(0).getAs[String]("name")
String = zhangsan
DataSet
- 强类型的数据集合,需要提供类型信息——DataFrame可以叫DataSet[Row],每一行类型是Row,不解析,每一行有哪些字、各个字段是什么类型都无从得知
创建DataSet
样例类序列创建DataSet
1
2
3
4
5
6
7
8
9
10
11
12scala> case class Person(name: String, age: Long)
defined class Person
scala> val caseClassDS = Seq(Person("zhangsan",2)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: Long]
scala> caseClassDS.show
+---------+---+
| name|age|
+---------+---+
| zhangsan| 2|
+---------+---+Scala基本类型的序列创建DataSet
1
2
3
4
5
6
7
8
9
10
11
12scala> val ds = Seq(1,2,3,4,5).toDS
ds: org.apache.spark.sql.Dataset[Int] = [value: int]
scala> ds.show
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
| 4|
| 5|
+-----+实际使用中,很少将序列转换成DataSet,更多通过RDD得到DataSet
RDD、DataSet相互转换
RDD转换DataSet
自动将包含有case class的RDD转换成 DataSet
case class定义了table的结构,case class属性通过反射变成表的列名
case class可以包含诸如Seq或者Array等复杂的结构
1
2
3
4
5scala> case class User(name:String, age:Int)
defined class User
scala> sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS
org.apache.spark.sql.Dataset[User] = [name: string, age: int]
DataSet转换RDD:DataSet也是对RDD的封装
1
2
3
4
5
6
7
8
9
10
11scala> case class User(name:String, age:Int)
defined class User
scala> sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS
org.apache.spark.sql.Dataset[User] = [name: string, age: int]
scala> val rdd = res11.rdd
rdd: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[51] at rdd at <console>:25
scala> rdd.collect
Array[User] = Array(User(zhangsan,30), User(lisi,49))
DataFrame、DataSet转换
DataFrame是DataSet的特例
DataFrame转换DataSet
1
2
3
4
5
6
7
8
9scala> case class User(name:String, age:Int)
defined class User
scala> val df = sc.makeRDD(List(("zhangsan",30),
("lisi",49))).toDF("name","age")
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> val ds = df.as[User]
ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int]DataSet转换DataFrame
1
2
3
4
5scala> val ds = df.as[User]
ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
scala> val df = ds.toDF
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
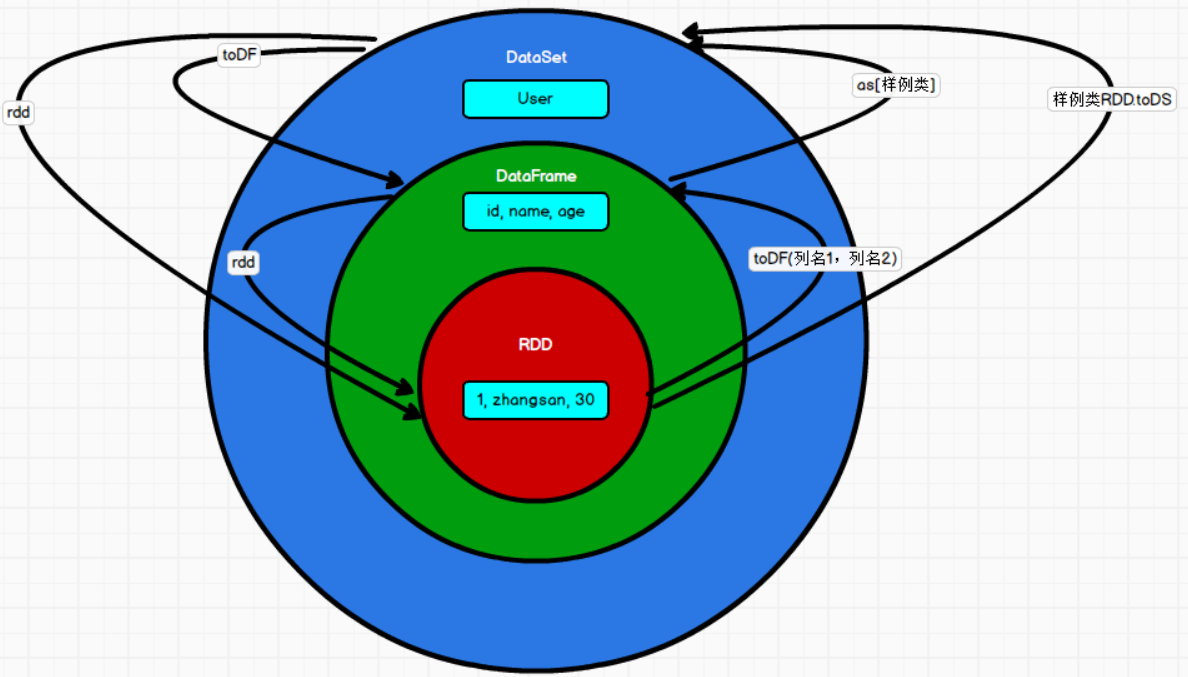
RDD、DataFrame、DataSet三者关系
- DataSet有可能逐步取代RDD和DataFrame成为唯一的API接口
- 共性:
- spark平台下的分布式弹性数据集
- 都有惰性机制,在创建、转换(如map方法)时不会立即执行,只有遇到Action方法时,才会开始运算
- 会根据Spark的内存情况自动缓存运算——不会内存溢出
- DataFrame和DataSet均可使用模式匹配,获取各个字段的值和类型
- 区别:
- DataFrame每一行的类型固定为Row,每一列的值无法直接访问,只有通过getAs、模式匹配获得特定字段
- Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同
- 相互转换
IDEA开发SparkSQL
添加依赖
1
2
3
4
5<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49package TestSparkSQL
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object Demo {
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
//创建 SparkSession 对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._ //spark 不是包名,是上下文环境对象名
val df: DataFrame = spark.read.json("src/main/resources/testSql.json")
df.show()
//SQL 风格语法
df.createOrReplaceTempView("user")
spark.sql("select avg(age) from user").show
//*****RDD=>DataFrame=>DataSet*****
val rdd1: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(
List((1, "zhangsan", 30), (2, "lisi", 28), (3, "wangwu", 20))
)
val df1: DataFrame = rdd1.toDF("id", "name", "age")
df1.show()
val ds1: Dataset[User] = df1.as[User]
ds1.show()
//*****DataSet=>DataFrame=>RDD*****
val df2: DataFrame = ds1.toDF()
//返回的 RDD 类型为 Row,getXXX 方法获取字段值,类似 jdbc 处理结果集,索引从 0 开始
val rdd2: RDD[Row] = df2.rdd
rdd2.foreach(a => println(a.getString(1)))
rdd1.map {
case (id, name, age) => User(id, name, age)
}.toDS()
//*****DataSet=>=>RDD*****
val rdd3 = ds1.rdd
rdd3.foreach(a => println(a.id + "\t" + a.name + "\t" + a.age))
//释放资源
spark.stop()
}
case class User(id: Int, name: String, age: Int)
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36+---+--------+
|age|username|
+---+--------+
| 15| Thomas|
| 20| David|
| 30| Bob|
+---+--------+
+------------------+
| avg(age)|
+------------------+
|21.666666666666668|
+------------------+
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 30|
| 2| lisi| 28|
| 3| wangwu| 20|
+---+--------+---+
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 30|
| 2| lisi| 28|
| 3| wangwu| 20|
+---+--------+---+
lisi
wangwu
zhangsan
3 wangwu 20
1 zhangsan 30
2 lisi 28
用户自定义函数
额外的功能补充
注册、应用udf(给字段username添加一个前缀为例)
1
2
3
4
5
6
7
8
9
10spark.udf.register("addPrefix", (x:String) => "Name:"+x)
spark.sql("Select addPrefix(username), age from people").show()
+-------------------+---+
|addPrefix(username)|age|
+-------------------+---+
| Name:Thomas| 15|
| Name:David| 20|
| Name:Bob| 30|
+-------------------+---+UDAF(用户自定义聚合函数)
强类型的Dataset和弱类型的DataFrame都提供相关的聚合函数,如
count()、max()等继承 UserDefinedAggregateFunction实现用户自定义弱类型聚合函数
Spark3.0后,UserDefinedAggregateFunction不推荐使用,可以统一采用强类型聚合函数Aggregator
以计算平均年龄为例
RDD:
1
2
3
4
5
6
7
8
9val res: (Int, Int) = data.map {
case (name, age) =>
(age, 1)
}.reduce {
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
}
println(res._1 / res._2)UDAF弱类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52import spark.implicits._ //spark 不是包名,是上下文环境对象名
val dataFrame = data.toDF("username", "age")
dataFrame.createOrReplaceTempView("user")
spark.udf.register("ageAvg", new MyAvgUDAF())
spark.sql("select ageAvg(age) from user").show()
...
class MyAvgUDAF extends UserDefinedAggregateFunction {
// 输入数据的结构: 这里只有年龄,Int
override def inputSchema: StructType = {
StructType(Array(StructField("age", LongType)))
}
// 缓冲区数据的结构: 临时的结构
override def bufferSchema: StructType = {
StructType(
Array(StructField("total", LongType), StructField("count", LongType)
)
)
}
// 函数计算结果的数据类型:Out
override def dataType: DataType = LongType
// 函数的稳定性
override def deterministic: Boolean = true
// 缓冲区初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
// 计算均值,需要cnt和sum
buffer.update(0, 0L)
buffer.update(1, 0L)
}
// 根据输入的数据更新缓冲区数据
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0, buffer.getLong(0) + input.getLong(0))
buffer.update(1, buffer.getLong(1) + 1)
}
// 缓冲区数据合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0, buffer1.getLong(0) + buffer2.getLong(0))
buffer1.update(1, buffer1.getLong(1) + buffer2.getLong(1))
}
// 计算平均值
override def evaluate(buffer: Row): Any = {
buffer.getLong(0) / buffer.getLong(1)
}
}UDAF强类型(也可以用DSL语法来做,这里略),IN:输入数据类型、BUF:缓冲区数据类型、OUT:输出数据类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37case class Buff(var total: Long, var count: Long)
class AvgUDAFStrong extends Aggregator[Long, Buff, Long] { // [In, Buff, Out]
// 缓冲区的初始化
override def zero: Buff = {
Buff(0L, 0L)
}
// 根据输入的数据更新缓冲区的数据
override def reduce(buff: Buff, in: Long): Buff = {
buff.total = buff.total + in
buff.count = buff.count + 1
buff
}
// 合并缓冲区
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.total = buff1.total + buff2.total
buff1.count = buff1.count + buff2.count
buff1
}
//计算结果
override def finish(buff: Buff): Long = {
buff.total / buff.count
}
// 缓冲区的编码操作,用于序列化,一般是固定写法
override def bufferEncoder: Encoder[Buff] = Encoders.product
// 输出的编码操作
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
...
dataFrame.createOrReplaceTempView("user")
spark.udf.register("ageAvg", functions.udaf(new AvgUDAFStrong()))
spark.sql("select ageAvg(age) from user").show()
数据加载、保存
- 使用相同的API,根据不同的参数读取、保存不同格式的数据(默认读取和保存的文件格式 为parquet)
- 加载数据:
spark.read.format("…")[.option("…")].load("…")- format:指定加载的数据类型,csv、jdbc、json、orc、parquet、textFile
- load:传入加载数据路径
- option:jdbc格式下,传入JDBC的相应参数,url、user、password、dbtable
- 保存数据:
dataframe.write.format("…")[.option("…")].save("…")- format:指定保存的数据类型,csv、jdbc、json、orc、parquet、textFile
- load:传入保存数据的路径
- option:jdbc格式下,传入JDBC的相应参数,url、user、password、dbtable
- 设置save mode(不是原子操作,没有加锁):
df.write.mode("append").json("/opt/module/data/output"),mode包括error、append、overwrite、ignore
Parquet
- Parquet是能存储嵌套数据的列式存储格式,数据源为Parquet文件时上述加载、保存操作不需要使用format——修改配置项spark.sql.sources.default,可修改默认数据源格式
- 加载:
val df = spark.read.load("...") - 保存:
df.write.mode("append").save("...")
Json
SparkSQL自动推断Json数据集结构,加载为Dataset[Row]——Spark读取的JSON文件不是传统的JSON文件,每一行是一个JSON串
1
2{"name":"Michael"}
[{"name":"Justin", "age":19},{"name":"Justin", "age":19}]加载:
spark.read.json(path)
CSV
- CSV文件第一行为字段名:
spark.read.format("csv").option("sep", ";").option("inferSchema", "true").option("header", "true").option("header", "true").load("data/user.csv")
MySQL
导入依赖
1
2
3
4
5<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>数据读取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25val ds: Dataset[User2] = rdd.toDS
//方式 1:通用的 load 方法读取
spark.read.format("jdbc")
.option("url", "jdbc:mysql://linux1:3306/spark-sql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123123")
.option("dbtable", "user")
.load().show
//方式 2:通用的 load 方法读取 参数另一种形式
spark.read.format("jdbc")
.options(
Map(
"url"->"jdbc:mysql://linux1:3306/spark-sql?user=root&password=123123",
"dbtable"->"user","driver"->"com.mysql.jdbc.Driver"
)
).load().show
//方式 3:使用 jdbc 方法读取
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123123")
val df: DataFrame = spark.read.jdbc("jdbc:mysql://linux1:3306/spark-sql", "user", props)数据保存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//方式 1:通用的方式 format 指定写出类型
ds.write
.format("jdbc")
.option("url", "jdbc:mysql://linux1:3306/spark-sql")
.option("user", "root")
.option("password", "123123")
.option("dbtable", "user")
.mode(SaveMode.Append)
.save()
//方式 2:通过 jdbc 方法
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123123")
ds.write.mode(SaveMode.Append).jdbc("jdbc:mysql://linux1:3306/spark-sql", "user", props)
Hive
略(若要把Spark SQL连接到一个部署好的Hive上,要把hive-site.xml复制到Spark配置文件目录)

