spark学习(1)Yarn环境,运行架构,SparkCore(RDD算子、累加器、广播变量)
概述
- 基于内存的快速、通用、可扩展的分析计算引擎Spark Core:提供 Spark 基础与核心的功能
- Spark SQL:Spark 用于操作结构化数据的组件,使用SQL或者HQL查询数据。
- Spark Streaming:Spark针对实时数据进行流式计算的组件,提供处理数据流的API
- Spark MLlib:Spark的一个机器学习算法库
- Spark GraphX:Spark的面向图计算的框架与算法库
- 对比hadoop:
- Hadoop:
- Java编写,分布式服务器存储数据,并运行分布式分析应用的框架
- HDFS:Hadoop生态圈最下层,存储所有的数据,支持Hadoop的服务,源于Google的The Google File System论文
- MapReduce:一种编程模型,基于MapReduce论文
- HBase:对Google的Bigtable的开源实现,一个基于HDFS的分布式数据库,实时随机读/写大规模数据
- MapReduce设计初衷不满足循环迭代式数据流处理,在多并行运行的数据可复用场景(机器学习、图挖掘算法、交互式数据挖掘算法)存在计算效率问题——Spark将计算单元缩小到更适合并行计算和重复使用的RDD计算模型
- Spark Task的启动时间快(采用fork线程的方式,Hadoop则创建新的进程)
- Spark和Hadoop根本差异是多个作业之间的数据通信方式不同:Spark多个作业数据通信基于内存,Hadoop基于磁盘
- Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会 由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以 Spark 并不能完全替代 MR。
- Hadoop:
运行环境(以wordcount为例)
IDEA中运行
前提:
- 安装IDEA的scala插件
- 安装scala2.12.13并配置Path
- 安装hadoop2.7.7并配置环境变量、修改配置文件
- 安装spark3.1.3并配置环境变量
SPARK_HOME、Path
IDEA新建maven项目,选择JDK1.8
建一个与
java同级的scala文件夹,Project Structure下选择Modules,新增scala的sdk(由于已经配置了环境变量,因此IDEA能直接识别scala2.12.13,直接引入即可)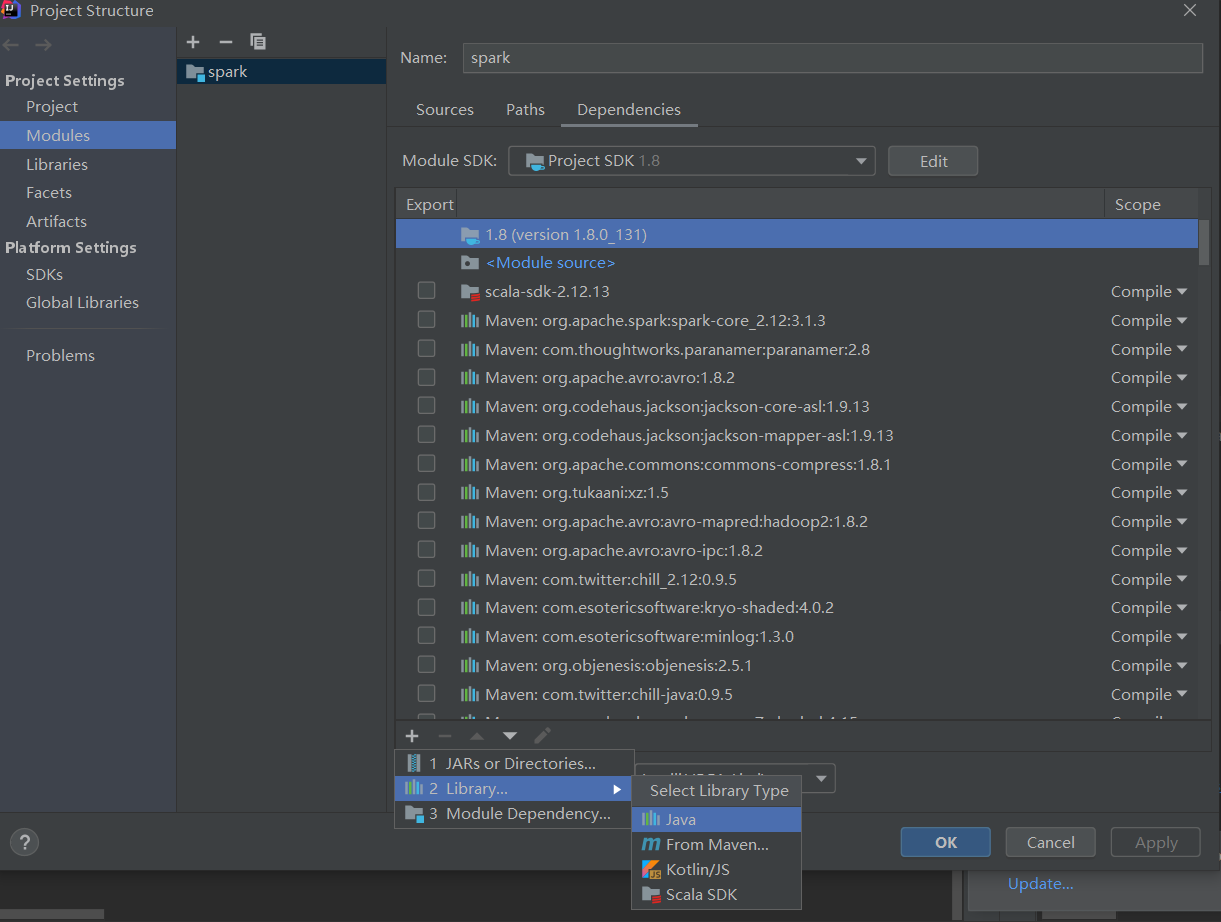
pom.xml中引入项目依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.maven.plugins/maven-assembly-plugin -->
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
</dependency>
</dependencies>scala文件夹建wordcount包,new一个object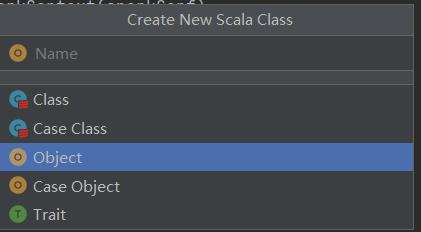
resources文件夹下,新建log4j.properties和word.txt,前者保存日志配置信息,能减少无效的日志信息输出,以查看程序的执行结果,后者保存测试用的word。内容分别为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent
UDFs=in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR1
2
3shao shao shao
nai yi yi nai
hello hello wordobject中的代码与输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27package wordcount
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object TestWC {
def main(args: Array[String]): Unit = {
// 创建 Spark 运行配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 创建 Spark 上下文环境对象(连接对象)
val sc: SparkContext = new SparkContext(sparkConf)
// 读取文件数据
val fileRDD: RDD[String] = sc.textFile("src/main/resources/word.txt")
// 将文件中的数据进行分词
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
// 转换数据结构 word => (word, 1)
val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
// 将转换结构后的数据按照相同的单词进行分组聚合
val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_ + _)
// 将数据聚合结果采集到内存中
val word2Count: Array[(String, Int)] = word2CountRDD.collect()
// 打印结果
word2Count.foreach(println)
//关闭 Spark 连接
sc.stop()
}
}1
2
3
4
5(word,1)
(hello,2)
(nai,2)
(yi,2)
(shao,3)
本地模式
命令行运行:
- 输入spark-shell
- 直接执行
sc.textFile("src/main/resources/word.txt").flatMap(_.split(" )).map((_,1)).reduceByKey(_+_).collect
提交应用:
修改代码(输入参数确定wc的数据和输出路径):
1
2
3val fileRDD: RDD[String] = sc.textFile(args(0))
...
word2CountRDD.saveAsTextFile(args(1))IDEA中用maven打包(点package)
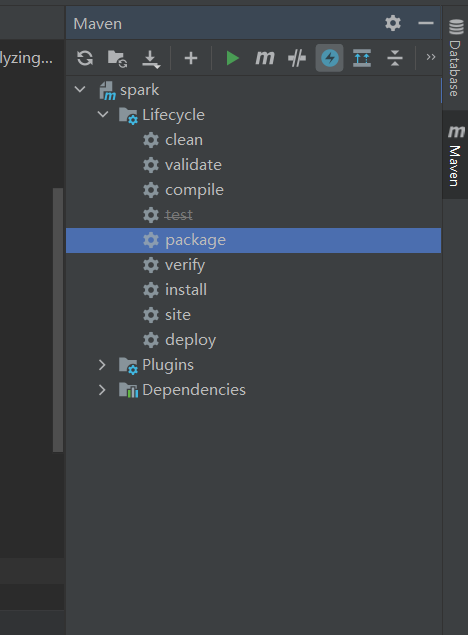
命令行执行:
1
$ spark-submit --class wordcount.TestWC --master local[2] ./spark-wc.jar ../src/main/resources/word.txt ./wc
当前目录下生成文件夹wc,内容如下,其中part-00000、part-00001包含了被拆分的输出结果
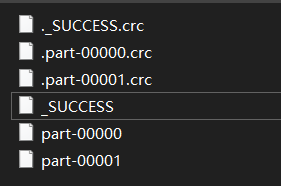
参数:
--class:要执行程序的主类--master local[2]:部署模式为本地模式,数字表示分配的虚拟CPU核数量./spark-wc.jar:类所在的jar包../src/main/resources/word.txt与./wc:函数所需的输入参数
Standalone模式
- 略
Yarn模式
同local模式,新增:
- 环境变量
YARN_CONF_DIR(hadoop2.7.7/etc)
- 环境变量
管理员模式运行cmd,启动hdfs和yarn
上传wc.txt
再次修改代码并打包:
1
val sparkConf = new SparkConf().setAppName("WordCount")
管理员模式在target路径下运行:
1
$ spark-submit --master yarn --deploy-mode client --class wordcount.TestWC ./spark-wc.jar hdfs://localhost:9000/spark/data/word.txt hdfs://localhost:9000/spark/data/wc
其中,
hdfs://localhost:9000/spark/data/word.txt为wc数据的上传路径,hdfs://localhost:9000/spark/data/wc为wordcount的输出文件夹查看结果:
1
2
3
4
5
6$ hadoop fs -cat /spark/data/wc/*
(word,1)
(hello,2)
(nai,2)
(yi,2)
(shao,3)
端口号设置:
- Spark查看当前Spark-shell运行任务情况端口号:4040(计算)
- Spark Master内部通信服务端口号:7077
- Standalone模式,Spark Master Web端口号:8080(资源)
- Spark历史服务器端口号:18080
- Hadoop YARN任务运行情况查看端口号:8088
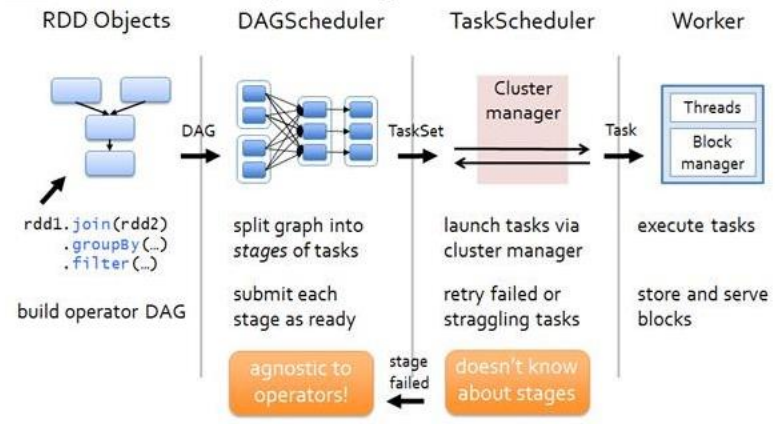
Spark架构
运行架构
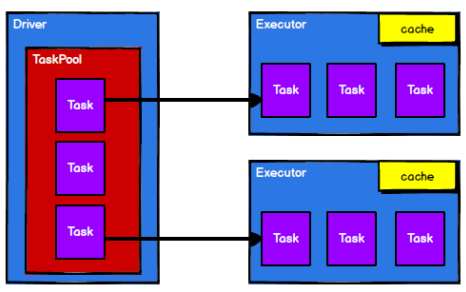
master-slave结构,Driver表示master,管理整个集群中的作业任务调度,Executor是slave,实际执行任务
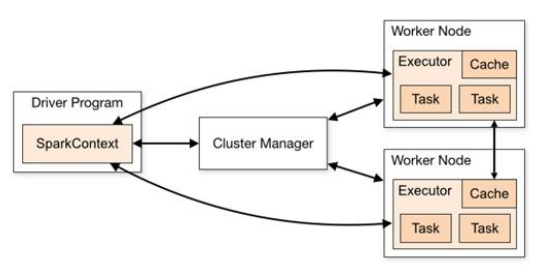 * 一个master节点作为协调,与一系列的worker节点沟通,worker节点之间可以互相通信
* worker节点包含一个或者多个executor,一个executor包含多个task。task是实现并行计算的最小工作单元
* 一个master节点作为协调,与一系列的worker节点沟通,worker节点之间可以互相通信
* worker节点包含一个或者多个executor,一个executor包含多个task。task是实现并行计算的最小工作单元
组件:
Driver:一个Java进程,执行Spark任务的main方法
执行用户提交的代码,创建SparkContext或者SparkSession
将用户代码转化为Spark任务(Jobs)
- 血缘(Lineage)
- 逻辑计划(Logical Plan)
- 物理计划(Physical Plan)
在Cluster Manager的辅助下,分发调度task任务
跟踪任务的执行情况
Spark Context/Session:driver创建,每个Spark应用有一个,是程序和集群交互的入口,可以连接到 Cluster Manager
Cluster Manager:集群资源管理器,负责部署整个Spark集群
- Standalone:spark原生的资源管理,由Master负责资源的分配
- Apache Mesos
- Yarn:ResourceManager
Executor:创建在worker节点的进程
一个Executor有多个slots(线程)并发执行多个 tasks
每个Application都有各自独立的一批Executor,Worker Node上的Executor服务于不同的Application,之间不共享数据
通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储——RDD直接缓存在Executor进程内,运行时充分利用缓存数据加速运算
内存分为三块:
- task执行代码时使用,默认占Executor总内存的20%
- task通过shuffle过程拉取上一个stage的task的输出,进行聚合等操作时使用,默认是占Executor总内存的20%
- RDD持久化时使用,默认占Executor总内存的60%
提交应用时,可以提供参数指定计算节点的个数,以及对应的资源(Executor的内存大小和使用的虚拟CPU核Core的数量)

Master节点:实际生产中有多个Master,只有一个Master处于active;从master节点提交应用,将串行任务变成可并行执行的任务集Tasks(类似Yarn中的RM)
Worker节点:与master节点通信,负责执行任务并管理executor进程,为集群中任何可以运行Application代码的节点。在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark on Yarn模式下是NoteManager节点
Stage:
- 每个Job被拆分成多组Task,一组Task为一个Stage
- Stage的划分和调度由DAGScheduler负责
- Stage分为非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage),Stage的边界是发生shuffle的地方
DAGScheduler:
- 根据Job构建基于Stage的DAG,提交Stage给TASkScheduler
- 划分Stage的依据:根据RDD之间的依赖关系,找到开销最小的调度方法
TaskScheduler:
- 将Stage提交给worker运行,决定每个Executor运行什么Task
- Executor向Driver发送心跳时,TaskScheduler根据资源剩余情况分配相应的Task
- TaskScheduler维护所有Task的运行标签
并行度:整个集群并行执行任务的数量
DAG(有向无环图)
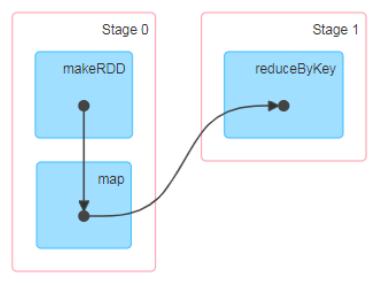
- MapReduce:将计算分为Map和Reduce阶段,上层应用要拆分算法甚至实现多个Job的串联以完成一个完整的算法
- 支持DAG的框架:如Tez以及Oozie,大多实现批处理
- Spark:支持Job内部的DAG,实时计算。此时DAG是由Spark程序直接映射成的数据流的抽象模型,将整个程序计算的执行过程用图形表示出来,直观表示程序的拓扑结构
Spark与Cluster Manager无关,只要能够获取 Executor 进程,并能保持相互通信即可
提交流程
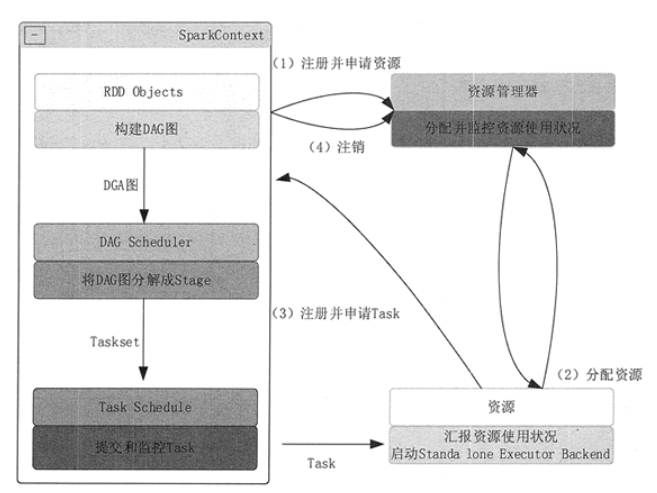
- 构建Spark Application的运行环境(启动 SparkContext),SparkContext向 Cluster Manager注册,申请运行Executor资源
- Cluster Manager为 Executor分配资源并启动Executor进程,Executor运行情况随着“心跳”发送到Cluster Manager
- SparkContext构建DAG,将DAG分解成多个Stage,每个Stage的Task发送给Task Scheduler (任务调度器)。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor,SparkContext将应用程序代码发放给Executor
- Task在Executor运行,执行结果反馈给Task Scheduler,再反馈给DAG Scheduler。运行完毕写入数据,SparkContext向Cluster Manager注销并释放所有资源
Spark Core
- 三种数据结构
- RDD : 弹性分布式数据集
- 累加器:分布式共享只写变量
- 广播变量:分布式共享只读变量
RDD
Resilient Distributed Dataset(弹性分布式数据集),Spark中最基本的数据处理模型,代码中为一个抽象类,代表一个弹性的、不可变、可分区、元素可并行计算的集合
- 弹性
- 存储的弹性:内存与磁盘的自动切换
- 容错的弹性:数据丢失可以自动恢复
- 计算的弹性:计算出错重试机制
- 分片的弹性:根据需要重新分片(分区),例如有新的executor加入集群
- 可分区:一份数据切割为多个区,作为多个task分到多个executor并行执行(不是并发)
- 分布式:数据存储在集群不同节点
- 数据集:RDD封装了计算逻辑,不保存数据,第二个rdd开始计算数据时,前一个rdd已经是空的
- 数据抽象:RDD是一个抽象类,需要子类具体实现
- 不可变:RDD封装了计算逻辑,不可以改变的,要改变只能产生新的RDD并封装新的计算逻辑
- 核心属性:
- 分区列表(list of partitions):用于执行任务时并行计算
- 分区计算函数(function for computing each split): Spark计算时使用分区函数对每一个分区进行计算
- RDD之间的依赖关系(list of dependencies on each RDDs):当需要将多个计算模型组合时,对多个RDD建立依赖关系
- 分区器(可选,partitioner for key-value RDDs):当数据为KV类型数据时,可以通过设定分区器,自定义数据的分区——RDD is hash-partitioned
- 首选位置(可选):计算数据时,根据计算节点的状态,选择不同的节点位置进行计算(判断task发给哪个节点是最优的)
- 弹性
执行原理
Spark执行时,先申请资源,将应用程序的数据处理逻辑分解成多个计算任务,将任务发到已分配资源的计算节点上,按指定的计算模型进行数据计算
RDD在整个流程中将逻辑进行封装,对数据分区生成独立的Task,发送给Executor节点执行计算
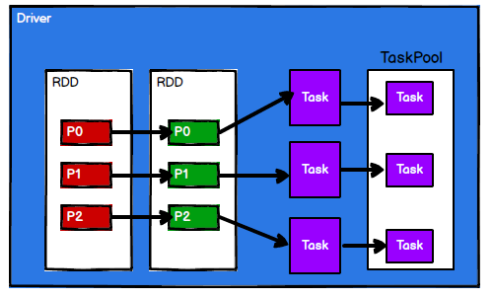
例如:
client(driver)将一个任务(将一个数组中各个元素乘2)发送给server(executor)执行,此时需要将任务的逻辑以及相应数据封装为一个RDD,client和server的通信(这里是通过本地的JVM实现两个进程的通信)使用socket
当前的任务拆分成两个,给不同的executor执行
client.scala:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35package TestRDD
import java.io.{ObjectOutputStream, OutputStream}
import java.net.Socket
object client {
def main(args: Array[String]): Unit = {
// 建立socket
val client1 = new Socket("localhost", 9999)
val client2 = new Socket("localhost", 8888)
val out1: OutputStream = client1.getOutputStream
val out2: OutputStream = client2.getOutputStream
val objectOut1 = new ObjectOutputStream(out1) // 对象输出流
val objectOut2 = new ObjectOutputStream(out2) // 对象输出流
val task = new task()
val subTask1 = new subTask()
subTask1.logic = task.logic
subTask1.data = task.data.take(2)
val subTask2 = new subTask()
subTask2.logic = task.logic
subTask2.data = task.data.takeRight(2)
objectOut1.writeObject(subTask1) // 发送数据给executor1
objectOut1.flush()
objectOut1.close()
client1.close()
objectOut2.writeObject(subTask2) // 发送数据给executor2
objectOut2.flush()
objectOut2.close()
client2.close()
}
}两个executor.scala,区别仅在于端口号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23package TestRDD
import java.net.{ServerSocket, Socket}
import java.io.{InputStream, ObjectInputStream}
object server1 {
def main(args: Array[String]): Unit = {
val server = new ServerSocket(9999)
val client: Socket = server.accept() // 监听
val in: InputStream = client.getInputStream
val objectInputStream = new ObjectInputStream(in)
val task: subTask = objectInputStream.readObject().asInstanceOf[subTask]
val result: List[Int] = task.compute()
println("计算结果为:" + result)
objectInputStream.close();
client.close();
server.close()
}
}task.scala与subtask.scala:必须是可序列化的,因此extends Serializable;subtask的计算逻辑相同,区别只是传入的数据;可以认为这里的task是一个RDD,RDD将一个个subtask发送给executor(RDD不保存数据,这里只是为了方便把数据放到task里)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17package TestRDD
class task extends Serializable {
val data = List(1,2,3,4)
// 匿名函数
val logic : (Int)=>Int = _ * 2
}
class subTask extends Serializable {
var data: List[Int] = _
var logic: (Int) => Int = _
// 计算
def compute() = {
data.map(logic)
}
}
RDD只有在调用collect方法时,才真正执行业务逻辑,前面都是功能的扩展——参考装饰者设计模式
下图展示了之前的wordcount代码里,对rdd的功能扩展,从读取文件,到展平,到分别统计,到合并
每个方法(如textfile、flatMap、map)都创建了新的rdd,并将当前的rdd作为新的rdd的参数,具体可以看源码
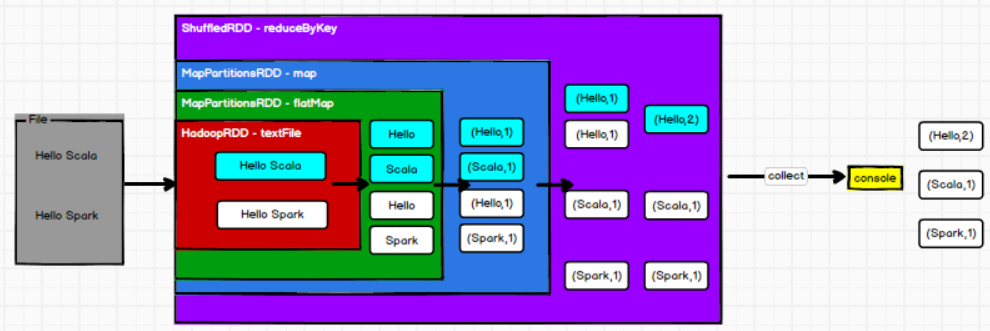
创建RDD与RDD的分区
从内存(集合)中创建:
sparkContext.parallelize和sparkContext.makeRDD,后者是对前者的封装。能并行计算的任务数量称为并行度,可以在makeRDD函数指定,读取内存数据时,数据按照并行度的设定进行分区操作(第三块代码),如果不传入参数,则取默认值taskScheduler.defaultParallelism,为totalCore,当前环境的最大可用核数1
2
3
4
5
6
7
8
9
10
11
12
13def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
val rdd1 = sparkContext.parallelize(
List(1, 2, 3, 4)
)
val rdd2 = sparkContext.makeRDD(
List(1, 2, 3, 4), 4
)
rdd1.collect().foreach(println)
rdd2.collect().foreach(println)
sparkContext.stop()
}1
2
3
4def makeRDD[T: ClassTag] (
seq: Seq[T],
numSlices: Int = defaultParallelism):
RDD[T] = withScope {parallelize (seq, numSlices)1
2
3
4
5
6
7
8
9
10def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map {
i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
// 左闭右开
// length:传入的数据列表长度,numSlice:并行度读取文件创建(将文件中的数据作为处理的数据源),同样,用textFile函数指定并行度(这里的参数为最小分区数,和上面的不太一样)
1
2
3
4
5
6
7
8
9def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
// 从文件中创建RDD,将文件中的数据作为处理的数据源
// path路径默认以当前项目的根路径为根。可以是文件具体路径、目录名称、使用通配符*(1*.txt)、hdfs路径
val rdd: RDD[String] = sc.textFile("datas/1.txt", 4)
rdd.collect().foreach(println)
sc.stop()
}textFile:以行为单位读取数据wholeTextFiles:以文件为单位读取数据,读取结果为元组,元组中第一个元素为文件路径,第二个元素为文件内容读取文件数据时,数据按照Hadoop文件读取的规则进行切片分区,切片规则和内存读取的规则不同,具体源码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public InputSplit[] getSplits(JobConf job, int numSplits) throws IOException {
long totalSize = 0 // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath())
}
totalSize += file.getLen()
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits)
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize)
...
for (FileStatus file: files) {
...
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize()
long splitSize = computeSplitSize(goalSize, minSize, blockSize)
...
}
protected long computeSplitSize(long goalSize, long minSize, long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize))
}- 统计文件的字节数(假设为13byte)
- 每个分区字节数为13/最小分区数(假设为5)=2byte,因此为7个分区
- 不能跨文件读取字节
- 文件内以行为单位读取,按数据偏移分区
转换算子
可以认为算子就是RDD的方法
功能的补充,封装更为复杂的逻辑(旧的RDD包装为新的RDD),例如:flatMap、map,不会立刻执行
Value类型算子:对一个RDD操作(下面的算子,是对RDD中的不同分区做操作!)
map:同一个分区内数据逐条映射转换(转换数据类型或值),元素个数计算前后不变,不同分区之间计算无序——逐条表明,当数据为List[Int]时,相应函数的参数为Int类型mapPartitions:数据以分区为单位发送到计算节点进行处理(任意的处理,即使是过滤数据)mapPartitions 算子以分区为单位进行批处理操作,需要传递一个迭代器,返回一个迭代器,不要求元素的个数保持不变——这表明,相应处理函数的参数为迭代器,返回类型也为迭代器
性能较高,但长时间占用内存
一个例子(一般是用匿名函数直接实现,省去函数的定义)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def mapPartitions(data: Iterator[Int]): Iterator[(Int, Int, String)] = {
var res = List[(Int, Int, String)]()
while (data.hasNext) {
val cur = data.next;
res :+= (cur, cur * 2, "now " + cur)
}
res.iterator
}
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sparkContext = new SparkContext(sparkConf)
val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
val mapPart = dataRDD.mapPartitions(mapPartitions)
mapPart.collect().foreach(println)
sparkContext.stop()
}
mapPartitionsWithIndex:数据以分区为单位发送到计算节点进行处理,处理的同时获取当前分区的索引1
2
3
4
5
6
7
8
9
10
11
12
13
14val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
val mapPartWithIndex = dataRDD.mapPartitionsWithIndex(
(index, curData) => {
// cur_data.map(num => {(index)}) // 获取每个数据所在分区号
// List[Int](index).iterator // 获取分区号
// 获取第二个分区的数据
if (index == 1) {
curData
} else {
Nil.iterator
}
}
)
mapPartWithIndex.collect().foreach(println)flatMap:将数据扁平化后,再进行映射处理1
2
3
4
5
6
7
8
9
10
11// flatMap
val flatMapRDD = sparkContext.makeRDD(List(List(1,2),3,List(4,5)))
val flatRDD = flatMapRDD.flatMap {
data => {
data match {
case list:List[_] => list
case dat => List(dat)
}
}
}
flatRDD.collect().foreach(println)glom:同一分区的数据转换为相同类型的内存数组,分区不变(对比flatMap,flatMap将List变为Int,这里将Int变为Array)1
2
3
4
5
6
7
8
9var dataRDD: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
val glomRDD1 = dataRDD.glom() // 将两个分区里的数字转为列表
glomRDD1.collect().foreach(data => println(data.mkString(",")))
val glomRDD2 = dataRDD.glom().map( // 分区内取最大值,分区间最大值求和
data => {
data.max
}
)
print(glomRDD2.collect().sum)- 分区不变:分区数目不变,数据转换前后所属的分区相同
groupBy:def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])],数据根据指定的规则分组,分区默认不变,数据被打乱重组(shuffle),极端情况下数据可能被分到一个分区中——一个组的数据在一个分区中,一个分区可能有多个组1
2
3
4
5
6
7val data = sparkContext.makeRDD(List("Hello", "hive", "hbase", "Hadoop"), 2) // 根据单词首写字母分组
val groupby = data.groupBy(
num => {
num.charAt(0)
}
)
groupby.collect().foreach(println)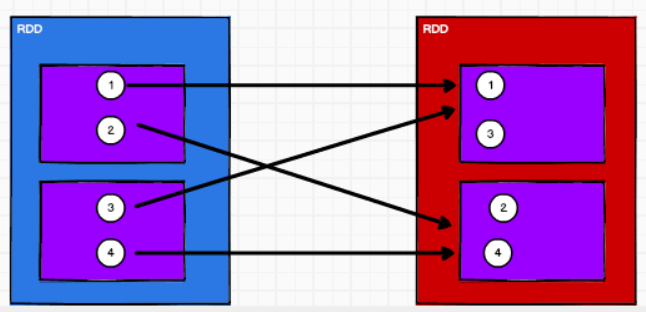
filter:def filter(f: T => Boolean): RDD[T],数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。筛选后,分区不变,但分区内的数据可能不均衡1
2
3
4
5
6val filter = dataRDD.filter(
num => {
num % 2 == 0
}
)
filter.collect().foreach(println)sample:根据指定的规则从数据集中 抽取数据,参数1:抽取数据是否放回(放回为泊松,不放回为伯努利),参数2:抽取概率,参数3:随机数种子——可以用于检查一个分区里的数据倾斜程度distinct:数据去重coalesce:根据数据量缩减分区。一般在大数据集过滤后使用,合并分区,减少分区个数,提高小数据集的执行效率。参数为缩减后分区数目- 默认情况下,不会将分区数据打乱重组,即如果原来数据分三个区,分别为1+2、3+4、5+6,合并为两个区时,结果为1+2、3+4+5+6
- 第二个参数为shuffle,如果为true,则分区结果均衡,但数据被随机打乱
- 本算子可以扩大分区,但此时shuffle必须为true
repartition:内部其实执行coalesce,参数shuffle默认值为true。无论将RDD分区增多,还是将RDD分区减少,都可以使用repartition1
2
3def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}sortBy:排序数据排序前,数据通过f函数处理,之后按照处理结果排序,默认升序排列——函数处理后的结果,只是作为排序的key,不对数据本身造成影响(下面代码的输出为(11,3) (1,2) (2,1))
排序后的RDD分区数与原RDD分区数一致,存在shuffle过程
1
2
3
4
5
6
7val data = sparkContext.makeRDD(List(("1", 2), ("11", 3), ("2", 1)), 2)
val sortby = data.sortBy(
num => {
num._2*num._2
}, ascending = false
)
sortby.collect().foreach(println)
双Value类型算子:两个RDD的数据操作
intersection:def intersection(other: RDD[T]): RDD[T],对源RDD和参数RDD求交集,返回一个新的RDDunion:def union(other: RDD[T]): RDD[T],对源RDD和参数RDD求交集,返回一个新的RDDsubtract:def subtract(other: RDD[T]): RDD[T],去除两个RDD中重复元素,保留源RDD剩余元素(交集、并集、差集的两个RDD数据类型要相同)zip:def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)],两个RDD的元素以键值对的形式合并,key为第1个RDD的元素,value为第2个RDD相同位置的元素(两个RDD数据类型可以不同,但RDD中的元素数目要相同)- 如果两个RDD数据分区不同,会报错(unequal numbers of partitions)
- 如果两个分区的数据数目不同,会报错(only zip same number of elements in each partition)
Key-Value类型算子:数据为key value格式(例如二元元组)
partitionBy:数据按照指定分区规则(Partitioner)重新分区。Spark默认的分区器是HashPartitioner——先前的coalesce只是改变分区数目- HashPartitioner:key的hashcode对分区数目取模得到分区号
- 其他分区器:RangePartitioner(排序时使用)、PythonPartitioner(特定的包里才能使用)
- 自建分区器
reduceByKey:def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)],数据按照相同的key对value进行聚合(两两计算),如果key只有一个,则不会参与运算——这里的聚合,表明value最后只会是一个元素,而非列表groupByKey:数据根据key对value进行分组形成新的元组,第一个元素为key,第二个元素为相应value的集合1
2val groupby: RDD[(Char, Iterable[Int])] = dataRDD2.groupByKey()
groupby.collect().foreach(println)与上面的
groupBy相比,这里固定使用key作为分组依据与上面的
reduceByKey相比,groupByKey+map可以实现reduceByKey,但groupByKey有shuffle操作,而spark中shuffle操作必须写入磁盘一次,因为要等待不同分区的计算一起完成后才进行下一步的RDD计算。虽然reduceByKey也有shuffle操作,但可以在shuffle前的分区里聚合一次,此时数据也要落盘,但落盘的数据量更少——reduceByKey有预聚合功能,减少落盘的数据量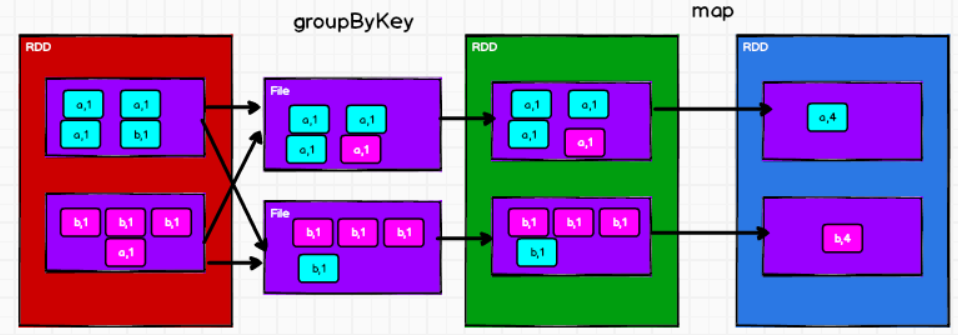
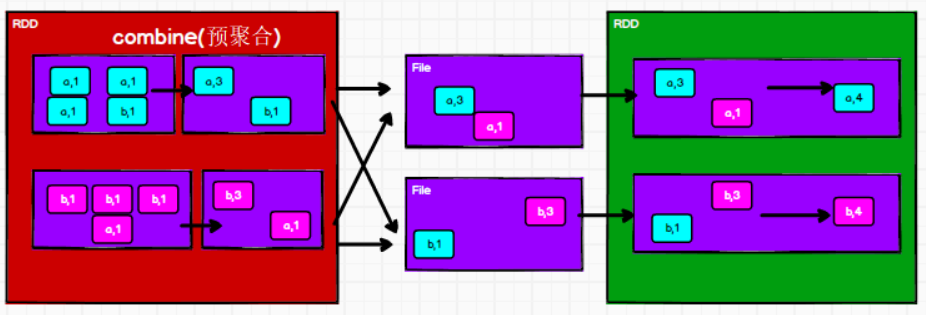
aggregateByKey:数据根据不同的规则进行分区内计算和分区间计算——上面的reduceByKey中,预聚合(分区内计算)和聚合(分区间计算)的运算规则相同第一个参数列表:遇到第一个key时,和value进行分区内计算
第二个参数列表:分区内计算函数,分区间计算函数
下图为,第一个参数不同时的运算过程(两个分区,初始值分别为0和5)
1
2
3
4
5
6
7
8
9
10
11val dataRDD3: RDD[(Char, Int)] = sparkContext.makeRDD(List(('a', 1), ('a', 2), ('c', 3), ('b', 4), ('c', 5), ('c', 6)), 2)
val aggregate = dataRDD3.aggregateByKey(0)(
(x: Int, y: Int) => {
if (x > y)
x
else
y
},
(x: Int, y: Int) => x + y
) // 分区内取最大,分区间求和
aggregate.collect().foreach(println)
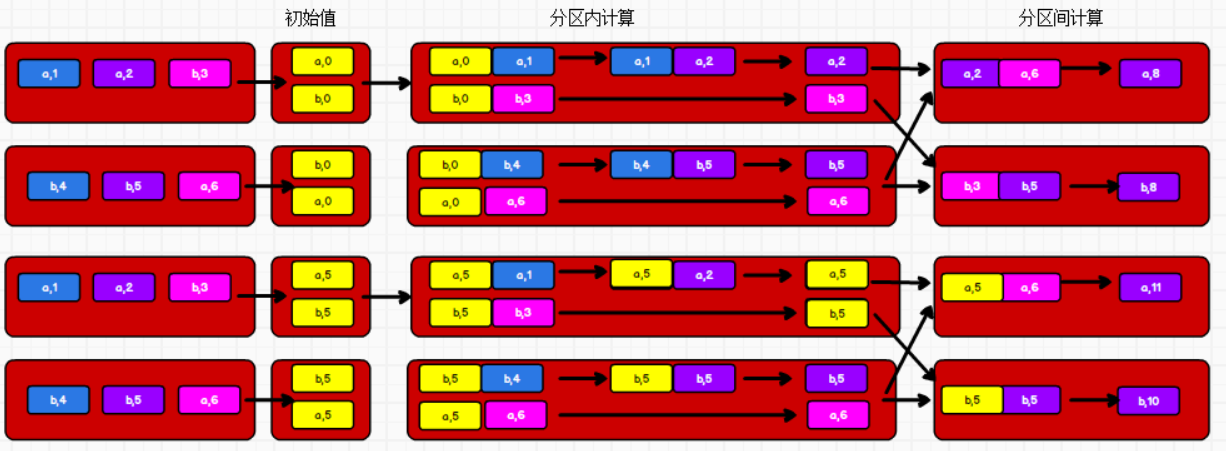
第二个例子,参数列表为tuple
1
2
3
4
5
6aggregate.collect().foreach(println)
val aggregate_new: RDD[(Char, (Int, Int))] = dataRDD3.aggregateByKey((0, 0))(
(x, y) => (x._1 + y, x._2 + 1),
(x, y) => (x._1 + y._1, x._2 + y._2)
) // 求每个key的均值
aggregate_new.mapValues {case (num, cnt) => num/cnt }.collect().foreach(println)
foldByKey:分区内计算规则和分区间计算规则相同时,aggregateByKey可以简化为foldByKey1
val fold = dataRDD3.foldByKey(0)(_+_)
combineByKey:对key-value类型RDD进行聚集操作的聚集函数- reduceByKey:相同key的第一个数据不进行任何计算,分区内和分区间计算规则相同
- FoldByKey:相同key的第一个数据和初始值进行分区内计算,分区内和分区间计算规则相同
- AggregateByKey:相同key的第一个数据和初始值进行分区内计算,分区内和分区间计算规则可以不相同
- CombineByKey:当计算时,发现数据结构不满足要求时,可以让第一个数据转换结构。分区内和分区间计算规则不相同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27reduceByKey:
combineByKeyWithClassTag[V](
(v: V) => v, // 第一个值不会参与计算
func, // 分区内计算规则
func, // 分区间计算规则
)
aggregateByKey :
combineByKeyWithClassTag[U](
(v: V) => cleanedSeqOp(createZero(), v), // 初始值和第一个key的value值进行的分区内数据操作
cleanedSeqOp, // 分区内计算规则
combOp, // 分区间计算规则
)
foldByKey:
combineByKeyWithClassTag[V](
(v: V) => cleanedFunc(createZero(), v), // 初始值和第一个key的value值进行的分区内数据操作
cleanedFunc, // 分区内计算规则
cleanedFunc, // 分区间计算规则
)
combineByKey :
combineByKeyWithClassTag(
createCombiner, // 相同key的第一条数据进行的处理函数
mergeValue, // 表示分区内数据的处理函数
mergeCombiners, // 表示分区间数据的处理函数
)sortByKey:返回一个按照key排序的RDD(key必须实现Ordered接口)join:类型为(K,V)和(K,W)的RDD上调用,返回一个将相同key对应的元素连接起来的 (K,(V,W))RDD;如果一个key只在一个RDD中出现,则忽略该keyleftOuterJoin、rightOuterJoin:类似于SQL的左外连接cogroup:类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD
举例:统计出每一个省份每个广告被点击数量排行的 Top3(agent.log:时间戳,省份,城市,用户,广告)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20val testRDD: RDD[String] = sparkContext.textFile("src/main/resources/agent.log", 3)
val data = testRDD.map(
x => {
val curStr = x.split(" ")
((curStr(1), curStr(4)), 1)
}
)
val counter = data.reduceByKey(
(x, y) => {
x + y
}
).map(
x => (x._1._1, (x._1._2, x._2))
).groupByKey()
val sort = counter.map(
x => {
(x._1, x._2.toList.sortBy(curTuple => curTuple._2)(Ordering.Int.reverse).take(3))
}
)
sort.collect().foreach(num => println(num.toString()))
行动算子
触发任务的调度、作业(Job)的执行,底层代码调用
sc.runJob()、dagScheduler.runJob()主要算子:
reduce:def reduce(f: (T, T) => T): T,聚集RDD中所有元素(先聚合分区内数据,再聚合分区间数据)1
2val dataRDD1: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
val i = dataRDD1.reduce(_+_) // 10collect:def collect(): Array[T],以数组Array的形式返回数据集的所有元素count:def count(): Long,返回RDD元素的个数first:def first(): T,RDD的第一个元素take:def take(num: Int): Array[T],一个RDD前num个元素组成的数组takeOrdered:def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T],RDD排序后前num个元素组成的数组aggregate:def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U,分区的数据通过初始值在分区内进行聚合,和初始值进行分区间的数据聚合- aggregateByKey:初始值只会参与分区内的计算,aggregate的初始值会参与分区间的计算
fold:def fold(zeroValue: T)(op: (T, T) => T): T,aggregate的简化版(分区间、分区内的计算规则相同)countByKey:def countByKey(): Map[K, Long],统计每种key的个数;同理有countByValue(其结果为map,map的key为元素,value为元素出现次数)1
2
3
4
5val countValue = dataRDD1.countByValue()
// Map(4 -> 1, 2 -> 1, 1 -> 1, 3 -> 1)
val countKey = sparkContext.makeRDD(List(("a", 1), ("a", 4), ("b", 5))).countByKey()
// Map(a -> 2, b -> 1)save相关算子:path均为文件夹路径saveAsTextFile:def saveAsTextFile(path: String): UnitsaveAsObjectFile:def saveAsObjectFile(path: String): UnitsaveAsSequenceFile:def saveAsSequenceFile(path: String, codec: Option[Class[_ <: CompressionCodec]] = None): Unit,要求数据格式必须为Key-Value
foreach:分布式遍历(Executor端)RDD中每一个元素,调用指定函数——不一定按照RDD中数据的顺序遍历!如果collect后遍历,则是在Driver端执行1
2
3
4
5
6val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2)
// 收集后打印
rdd.map(num=>num).collect().foreach(println) // 1 2 3 4
// 分布式打印
rdd.foreach(println) // 2 1 3 41
2
3
4def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
序列化
算子以外的操作在Driver端执行,算子内部的逻辑代码在Executor端执行
闭包检测:
算子内会用到算子外的数据(形成闭包),如果算子外的数据无法序列化(以在网络中传递),则无法传值给Executor端,此时报错
在执行任务计算前,需要检测闭包内的对象是否可以序列化——闭包检测
1
2
3
4
5
6
7// 报错,rdd算子传递的函数包含闭包操作,则会进行闭包检测。user类无法序列化
val user = new User()
rdd.foreach(
num => {
println("age = " + user.age)
}
)
样例类(case class)会在编译时自动实现序列化接口
序列化方法:让类继承Serializable
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// main
...
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hive", "spark"))
val search = new Search("hello")
search.getMatch(rdd).collect().foreach(println)
...
}
}
class Search(query: String) extends Serializable {
def isMatch(s: String): Boolean = {
s.contains(query)
}
def getMatch(rdd: RDD[String]): RDD[String] = {
rdd.filter(x => x.contains(query))
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#### RDD依赖关系
* 相邻的两个RDD的关系称为依赖——`val rdd1 = rdd.map(_*2)`,rdd1依赖于rdd
* 血缘关系:
* 多个连续的rdd依赖关系,称为血缘关系
* 每个RDD会保存血缘关系,但不保存数据。血缘关系提高了容错性:一旦RDD出现错误,可以根据血缘关系回溯,重新读取数据源,重新计算
<img src="hadoop学习5/image-20220806175221761.png" alt="image-20220806175221761" style="zoom:80%;" />
* 查看一个RDD的血缘关系:`rdd.toDebugString`
* 如果有shuffle操作,则血缘会中断
* 窄依赖与宽依赖
* 窄依赖:每一个父(上游)RDD 的Partition最多被子(下游)RDD 的一个Partition使用
```scala
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd)宽依赖:同一个父(上游)RDD 的Partition被多个子(下游)RDD的Partition依赖,会引起 Shuffle
1
2
3
4
5
6
7
8class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false
) extends Dependency[Product2[K, V]]
Stage、Task
如果没有shuffle,则task数目等于分组的数目
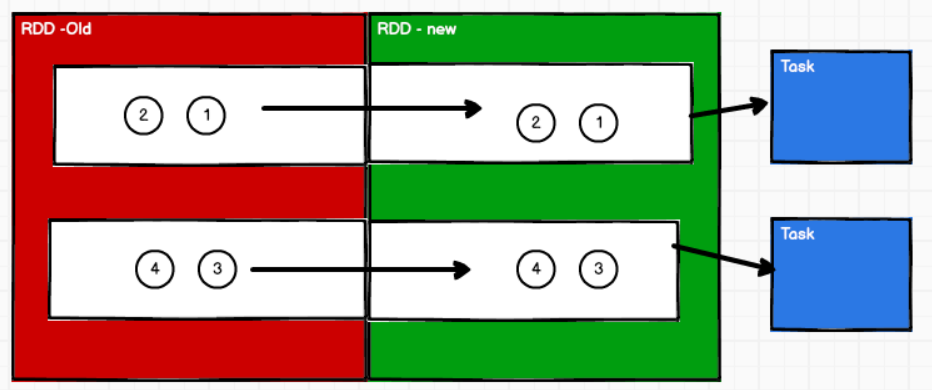
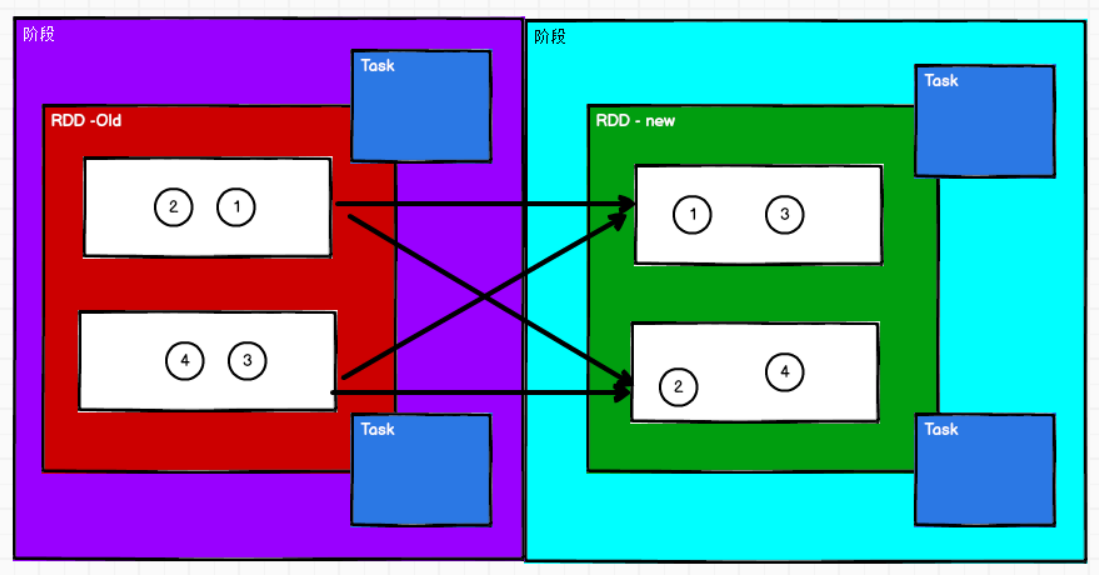
如果有shuffle,则task数目等于前后分组的数目乘积
Application:初始化一个SparkContext即生成一个Application
Job:一个Action算子生成一个 Job
Stage:Stage等于宽依赖的个数加1
Task:一个Stage中,最后一个RDD的分区个数是Task个数
Application->Job->Stage->Task之间,为1对n的关系
持久化
如果一个RDD重复使用,则它会从头再次执行来获取数据——RDD对象重用了,但数据不会重用
1
2
3
4
5
6
7val mapRDD = flatRDD.map(word=>{
println("@@@@@@@@@@@@")
(word,1)
})
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
val groupRDD = mapRDD.groupByKey()避免从头执行:RDD先将数据放到一个文件(内存),即持久化;持久化操作在行动算子执行时进行
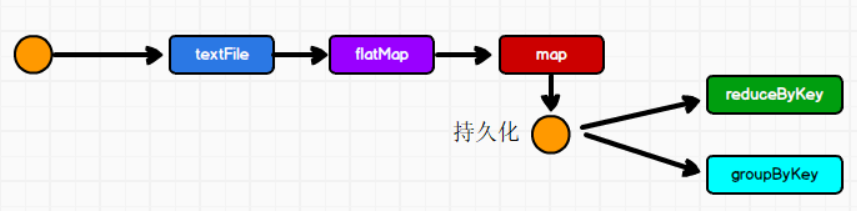
1
2
3
4
5
6
7
8
9
10val mapRDD = flatRDD.map(word=>{
println("@@@@@@@@@@@@")
(word,1)
})
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
// cache默认持久化的操作,只能将数据保存到内存中,如果想要保存到磁盘文件,需要更改存储级别
//mapRDD.cache()
mapRDD.persist(StorageLevel.DISK_ONLY)
val groupRDD = mapRDD.groupByKey()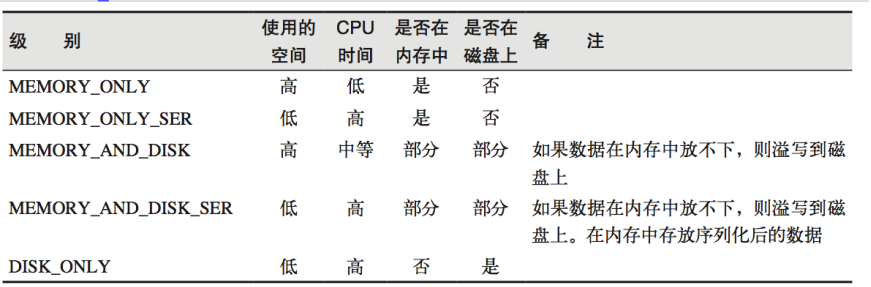
Spark会自动对一些Shuffle操作的中间数据做持久化操作(如reduceByKey)
检查点:
rdd.checkpoint(),同样必须执行Action操作才能触发- 需要落盘,因此需要指定检查点保存路径:
sc.setCheckpointDir("/checkpoint1") - 当作业执行完成后,检查点文件夹不会被删除,因此可以跨作业执行
- 需要落盘,因此需要指定检查点保存路径:
缓存和检查点的区别:
- cache:
- 数据临时存储在内存中进行数据重用,如果出现问题可以重头读取数据
- 在血缘关系中添加新的依赖
- persist:
- 数据临时存储在磁盘文件中进行数据重用
- 涉及到磁盘IO,性能较低
- 作业执行完毕,临时保存的数据文件会丢失
- checkpoint :
- 数据长久保存在磁盘文件中进行数据重用
- 涉及到磁盘IO,性能较低
- 为了保证数据安全,一般情况下会独立执行作业
- 为了提高效率,一般情况下需要和Cache联合使用
- 会切断血缘关系,重新建立新的血缘关系——checkpoint等同于改变数据源
- cache:
分区器
接上面的
HashPartitioner分区器直接决定RDD中分区的个数、RDD中每条数据经过Shuffle后进入哪个分 区
只有Key-Value类型的RDD才有分区器,非Key-Value类型的RDD分区的值是None
自定义分区器类:
继承Partitioner
重写方法numPartitions、getPartition
将分区器传入partitionBy函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
val rdd = sc.makeRDD(List(
("nba", "xxxxxxxxx"),
("cba", "xxxxxxxxx"),
("wnba", "xxxxxxxxx"),
("nba", "xxxxxxxxx"),
),3)
val partRDD: RDD[(String, String)] = rdd.partitionBy( new MyPartitioner )
partRDD.saveAsTextFile("output")
sc.stop()
}
/**
* 自定义分区器
* 1. 继承Partitioner
* 2. 重写方法
*/
class MyPartitioner extends Partitioner{
// 分区数量
override def numPartitions: Int = 3
// 根据数据的key值返回数据所在的分区索引(从0开始)
override def getPartition(key: Any): Int = {
key match {
case "nba" => 0
case "wnba" => 1
case _ => 2
}
}
}
RDD文件读取和保存
两个维度区分:文件格式、文件系统
- 文件格式:text文件、csv文件、sequence文件、object文件
- 文件系统:本地文件系统、HDFS、HBASE、数据库
text文件:
1
2
3
4// 读取输入文件
val inputRDD: RDD[String] = sc.textFile("input/1.txt")
// 保存数据
inputRDD.saveAsTextFile("output")sequence文件:Hadoop存储二进制形式key-value的一种平面文件(Flat File);
sequenceFile[keyClass, valueClass](path)1
2
3
4// 保存数据为 SequenceFile
dataRDD.saveAsSequenceFile("output")
// 读取 SequenceFile 文件
sc.sequenceFile[Int,Int]("output")object文件:将对象采用Java的序列化机制序列化后保存的文件,读取文件时要指定类型
objectFile[T: ClassTag](path)1
2
3
4// 保存数据
dataRDD.saveAsObjectFile("output")
// 读取数据
sc.objectFile[Int]("output").collect().foreach(println)
累加器
分布式共享只写变量
把Executor端的变量信息聚合到Driver端
在Driver中定义的变量,Executor的每个task会得到变量的一份新的副本,每个task更新相应副本的值后传回Driver进行merge
例如:其输出不是10!因为sum在foreach外定义,为driver中的变量,被序列化后传入多个executor,执行sum+=num。executor计算完后,没有返回给driver,即driver中的sum没有变化过——闭包保证了sum被传到executor,但无法传回,传回功能由累加器实现!
1
2
3
4
5
6
7val rdd = sc.makeRDD(List(1,2,3,4))
var sum = 0
rdd.foreach(
num => {
sum += num
}
)定义
sum为一个累加器而非普通的变量1
2
3
4
5
6
7val sumAcc = sc.longAccumulator("sum") // spark还有double、collection累加器sc.doubleAccumulator、sc.collectionAccumulator
rdd.foreach(
num => {
// 使用累加器
sumAcc.add(num)
}
)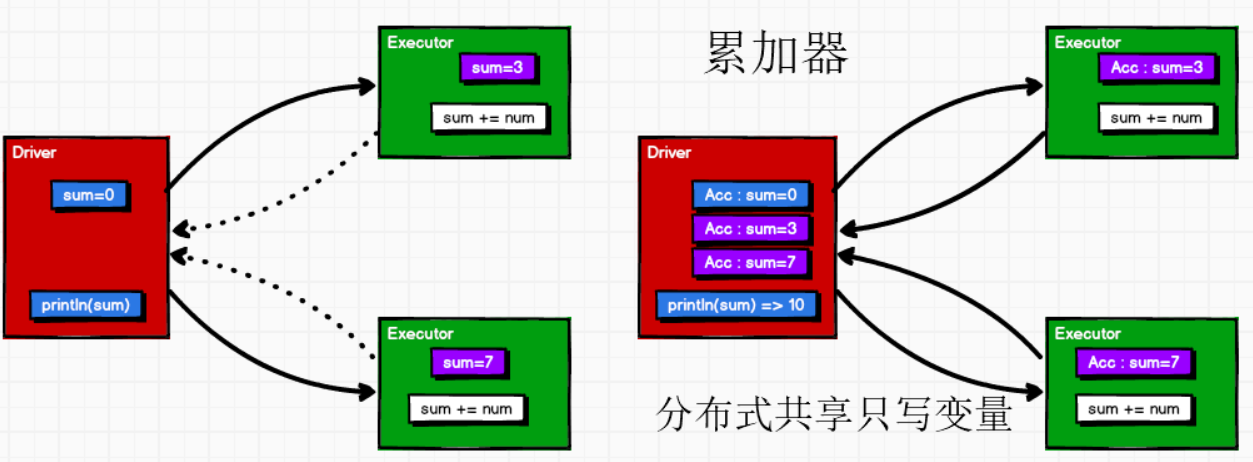
累加器一般放到行动算子中(转换算子中调用累加器,如果没有行动算子,那么不会执行)
自定义累加器:
创建累加器对象,向spark注册,行动算子中使用累加器
例如:实现wordcount的累加器(IN : 累加器输入的数据类型 String,OUT : 累加器返回的数据类型 mutable.Map[String, Long],即输出Map(spark -> 1, hello -> 2))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55val rdd_new = sc.makeRDD(List("hello", "spark", "hello"))
// 创建累加器对象
val wcAcc = new WordCountAccumulator()
// 向Spark进行注册
sc.register(wcAcc, "wordCountAcc")
rdd_new.foreach(
word => {
// 数据的累加(使用累加器)
wcAcc.add(word)
}
)
...
class WordCountAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] {
var map: mutable.Map[String, Long] = mutable.Map()
// 累加器是否为初始状态
override def isZero: Boolean = {
map.isEmpty
}
// 复制累加器
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {
new WordCountAccumulator
}
// 重置累加器
override def reset(): Unit = {
map.clear()
}
// 向累加器中增加数据 (In)
override def add(word: String): Unit = {
// 查询 map 中是否存在相同的单词
// 如果有相同的单词,那么单词的数量加 1
// 如果没有相同的单词,那么在 map 中增加这个单词
map(word) = map.getOrElse(word, 0L) + 1L
}
// 合并累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map1 = map
val map2 = other.value
// 两个 Map 的合并
map = map1.foldLeft(map2)(
(innerMap, kv) => {
innerMap(kv._1) = innerMap.getOrElse(kv._1, 0L) + kv._2
innerMap
}
)
}
// 返回累加器的结果 (Out)
override def value: mutable.Map[String, Long] = map
}
广播变量
分布式共享只读变量
- 高效分发较大的对象:向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用
- 例如,向所有节点发送一个较大的只读查询表,可以用广播变量
闭包数据以task为单位发送,此时一个executor中的每个task都要分配相应内存存储相同的闭包数据,使用广播变量可以减少内存消耗,此时广播变量存储在executor的内存中
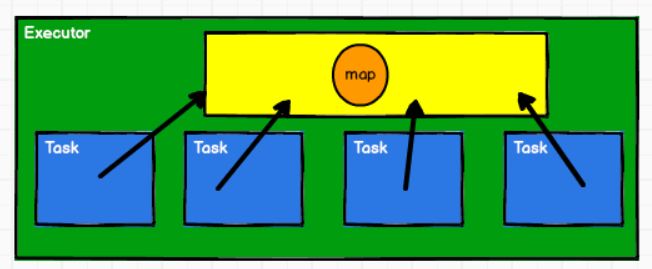
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16val rdd1 = sc.makeRDD(List( ("a",1), ("b", 2), ("c", 3), ("d", 4) ),4)
val list = List( ("a",4), ("b", 5), ("c", 6), ("d", 7) )
// 声明、封装广播变量
val broadcast: Broadcast[List[(String, Int)]] = sc.broadcast(list)
val resultRDD: RDD[(String, (Int, Int))] = rdd1.map {
case (key, num) => {
var num2 = 0
// 使用广播变量
for ((k, v) <- broadcast.value) {
if (k == key) {
num2 = v
}
}
(key, (num, num2))
}
}

