《Improving Real-world Password Guessing Attacks via Bi-directional Transformers》(Usenix Security 2023)
摘要
- 提出了一个基于双向Transformer的猜测框架,称为PassBERT,将pre-training/finetuning范式应用于密码猜测攻击
- 准备一个预先训练好的密码模型,其中包含一般密码分布的知识。设计三种特定于攻击的微调方法来定制预训练密码模型:
- 条件密码猜测——在给定部分密码的情况下恢复完整密码
- 针对性的密码猜测——使用特定用户的个人信息破解密码
- 自适应的基于规则的密码猜测——为基本密码选择自适应的篡改规则,以生成规则转换的密码候选
- 微调模型在三种攻击中的性能分别比现有模型提高了14.53%、21.82%和4.86%
- 提出一个混合式密码强度计来减轻这三种攻击的风险
介绍
- 对密码猜测攻击进行了几十年的研究[20,26,32,57],数据驱动模型(Markov)和基于规则的工具(Hashcat)用于离线破解密码
- 大多数研究集中在没有目标密码先验信息的一般猜测攻击,但黑客经常收集额外的场景特定知识以进一步提高攻击能力(如侧信道攻击[29,63])——本文中称为真实世界猜测攻击
- 针对性的密码猜测(TPG)[10,35,45,55]
- 条件密码猜测(CPG)[37, 38]——在给定部分密码的情况下恢复完整密码(当攻击者以某种方式收集到部分密码,如通过监控摄像头的恶意监控或肩并肩的网上冲浪,CPG是可实现的)
- 自适应基于规则的密码猜测(ARPG)[37, 38]——单词(基本密码)自动选择自适应规则以生成规则转换的候选密码
- 所有的密码猜测攻击,无论是一般的还是基于现实世界的,都可以被概念化为对密码(即文本)的概率分布进行近似的努力——基于双向Transformer的猜测框架的天然适应性
- 先前的工作只是简单地将Transformer从NLP应用到一般的猜测攻击[22]和ARPG [37],没有一个能够超越SOTA。这表明需要进一步的设计
- 本文提出了一个基于字符的双向Transformer的猜测框架,称为PassBERT
- 使用未标记的密码预训练一个通用的密码模型
- 针对CPG、TPG和ARPG三种攻击模型,设计特定的微调方法——修改模型架构以适应特定攻击的输入和输出(标签)格式,使用相应的目标函数重新训练模型
- 实验结果:CPG攻击、TPG攻击和ARPG攻击中,微调模型的性能分别比现有模型提高了14.53%、21.82%和4.86%
- 通过消融实验分析预训练的效果:攻击模型由预训练的自然语言模型或随机变量初始化
- 两种预训练模型(根据密码或自然语言进行训练)在先验知识的帮助下,在CPG和ARPG中提供显著的收益,在目标攻击(TPG)中表现出边际收益
- 预训练的密码模型比预训练的自然语言模型具有更好的猜测性能,表明预训练在特定密码语料库上的有效性
- 推出亚秒级延迟的混合密码强度计(HPSM)
- 密码计中显示密码每个部分的强度,以便用户可以修改易受攻击的部分
- 提醒用户有针对性的猜测攻击的风险
- 突出显示输入密码的基本单词
- 可以结合密码泄露检查[23,47]来检测输入是否被公开泄露,一旦泄露,则输入可能会遭受ARPG攻击
相关工作
Password Guessing Attacks
- 一般密码猜测攻击
- 大部分在线猜测工作都在做针对性的猜测[10,24,55]
- 数据驱动模型[30,32,57]和基于规则的猜测工具[17,26]通常用于offline猜测
- 数据驱动的猜测模型通常基于观察到的密码来训练概率模型,包括马尔可夫[28,32],概率上下文无关文法(PCFG)[24,52,56,57,60],基于神经网络的模型(FLA)[30]和生成对抗网络(GAN)[39]。这些模型旨在通过猜测次数来估计强度[11]
- 基于规则的猜测工具是Hashcat [17,26,62]等将篡改规则(例如,“删除最后三个字符”)应用于单词,以产生规则转换的候选密码。基于规则的工具对它们的初始配置高度敏感[3,21,26],通常基于专家知识
- 具有额外信息的真实世界攻击
- CPG:[38,39]
- 在给定部分密码的情况下破解完整密码
- 当攻击者通过监控摄像头中的恶意记录或肩膀冲浪,或可能想要破解包含网站名称或其他子字符串的密码时,可以发起CPG,用户也可以利用CPG评估每个字符对最终安全性的影响
- 一个简单的实现是应用数据驱动模型产生大量的候选密码,过滤掉噪声密码
- Pasquini等人[38,39]基于Wasserstein自动编码器[48]提出了一种新的CPG方法
- TPG:[35,55]
- 攻击者已经收集了个人信息,如历史密码
- 鉴于电子邮件的密码泄露[7,9],失败登录尝试的限制,以及用户密码的重复使用率[45],TPG攻击正成为一个日益增长的安全问题
- Das等人[10]提出了第一个关于目标攻击的学术工作。随后的工作[24,35,55]调查了几种改进的目标猜测方法,如个人PCFG[24],TarGuess[55]和Pass2path[35]
- 2019年提出的Pass2path是最新最有效的定向猜测模型
- ARPG:[37]
- 攻击者自动为字典中的每个单词选择自适应规则,每个单词仅与所选择的规则相关联
- 相比之下,基于规则的猜测工具中的混淆规则不一定是有效的,并且该规则具有条件性质,应当考虑该条件性质以寻求最佳配置
- 本文期望自适应规则与给定单词很好地交互。因此,ARPG的目标是尽早找到目标密码
- ARPG可以减少专家配置规则顺序的偏见——攻击者可以收集广泛使用的规则来建立一个模型,捕捉单词和规则之间的适应关系
- 2021年,Pasquini等人[37]提出了第一个基于自适应规则的猜测框架,建立了一个CNN(卷积神经网络)模型,为每个单词选择自适应规则
- CPG:[38,39]
- Baselines:分别使用最先进的CWAE、Pass2path、ADaMs模型作为CPG、TPG和ARPG攻击的基线(三个模型在github都有开源代码)
Bi-directional Transformers
- 介绍略
- 本文选择了所有参数都可以学习的微调方法
Preliminaries
Workflow of Three Attacks
- 监督学习是一种广泛使用的机器学习任务,通过使用监督信号来学习从输入到输出的映射关系
- 本文将监督信号表示为一组数据x及其对应的一组标签y,然后训练监督模型,在训练期间,模型逐渐更新其参数使得输出尽可能接近给定实例x的标签
- 本文使用交叉熵损失函数。下表中总结了三个场景的监控信号
- CPG:信号是部分密码,但有完整的密码。CPG旨在训练该模型,使其能够在给定部分密码的情况下预测正确的密码。CPG的输出直接作为候选密码
- TPG:监控信号是通过动态规划算法(在[35]中实现)计算的具有最短编辑路径的密码。编辑路径是一系列原子编辑操作(在攻击设计中预定义),如(delete,8)、(delete,9)、(delete,10),将密码转换为其变体。给定一个泄露的密码,TPG模型可以以不同的置信度输出多个编辑路径。将编辑路径应用于泄漏的密码,以获得其变体作为候选密码
- ARPG:监督信号是具有命中规则(即规则集的子集)的密码。模型输出自适应规则,这些规则依次应用于密码以获得候选密码。自适应规则通常与单词更兼容,使得在早期命中(生成少量密码就命中)成为可能。使用HashCat的规则,作为ARPG使用的mangling规则

Threat Model
- 本文主要对真实世界猜测攻击[35,37,38]进行建模。攻击者收集特定于攻击的信息(例如,部分密码、历史密码或广泛使用的篡改规则),并且通常求助于监督学习来学习一组输入和相关联的一组输出之间的函数
Password Breach Datasets
- 选择了先前工作中使用的几个数据集[16,21,37,38,43,54,60]
- 用于目标猜测的数据集有电子邮件,而用于非目标猜测攻击的数据集是纯文本密码
- 密码预训练、CPG和ARPG使用由明文密码组成的数据集:Rockyou-2009,000Webhost(2016),Neopets(2016),Cit0day(2020),Rockyou-2021
- 对于TPG攻击,选择以下两个包含电子邮件的数据集:
- BreachCompilation (4iQ)(2017),包括LinkedIn、雅虎、MySpace、Twitter、Neopets等几个知名网站的集合
- Collection#1:一个credential数据库(2019)
- 基于相同的电子邮件地址合并账户[35]——同一个用户通常用相同的电子邮件注册;大多数用户(97.1%以上)的密码不超过10个
- 为了评估有针对性的猜测攻击,重点关注泄露来自同一用户的非重复密码
- 数据集清理:采用常用的清理策略[16,35,37,60]来过滤掉原始数据集中的哈希密码、非哈希密码和超过32个字符的异常长密码
伦理审查
- 不会确定泄露密码的确切用户,且重点放在用户密码的整个特征集合上
- 基于文献[46]中的以下特征,本文工作是符合伦理的:(1)公共数据(即,只使用公开可用的数据集,不与他人共享);(2)必要的数据(即,没有这些数据集就无法进行这项研究);(3)没有额外的危害(即,研究不会通过安全管理的数据识别任何个人信息)
Password Bi-directionality
- 密码也具有双向性,如下图所示。通过展示字符对其环境的自我关注来形象化这种双向性。从亮到暗的颜色对应从弱到强的连接
- 在双向上下文中,字符与其他字符的连接是不同的
- 顺序性:字符通常和其相邻的字符相关性更强
- 聚合:相关字符的内部序列(如“p@ssw0rd123”中的“p@ssw0rd”和“123”)
- 本文的假设是,捕获双向表示可以获得更好的密码候选,提高密码猜测效率

PassBERT Guessing Framework
Password Pre-training
- 预先训练的模型架构:
- 密码标记为一个字符序列,并附加符号表示开始和结束
- 最大密码长度为32个字符,并考虑总共99个有效字符,包括95个ASCII字符(表示为∑)和4个附加的开始、结束、占位符和未知字符符号
- 嵌入层通过总结其字符和位置嵌入将tokenized input转换成其输入嵌入
- 预训练流程:
- 多个transformer模块处理用于特征提取的输入嵌入,MLM为目标
- 删除了NSP目标,因为密码域中没有与下一句等价的内容
- 将训练集中的每个密码预处理成部分密码(表示为pivot)和相关的完整密码(表示为pwd)的形式
- 遵循BERT中的相同屏蔽比例
- 一个密码可以被预处理成多个pivot
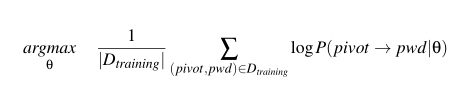
- 预训练数据集:
- 使用rock you-2021作为预训练数据集
- Rockyou-2021中随机抽取了6000万个密码
- 计算性能:RTX 2080 Ti的Ubuntu 20.04机器上训练,需要2天时间。存储预训练模型需要8.9MB
Password Fine-tuning
- 微调中需要修改架构修改并重新训练
- 保留预训练层,包括顶部输入层、嵌入层和几个transformer block
- 用特定的监督信号重新训练下游模型
- 预训练模型主要捕获输入密码的上下文嵌入——密码中每个字符的上下文信息的高维表示
- 当基于预训练来训练特定模型时,用来自预训练模型的情境化嵌入的参数来初始化特定模型的预训练层。当在没有预训练的情况下训练特定的模型时,预训练的层用随机变量初始化
PassBERT for Real-world Attack Models
消融实验设置:
- PassBERT:以密码做预训练的模型
- Vanilla BERT:公开的预训练模型
- *PassBERT:随机初始化的模型
Vanilla BERT为char level分词,替换unused token以增加大写字母
CPG
微调
- 输入为一个pivot,例如p***w0rd***
- CPG建模为掩蔽语言模型任务,预测丢失字符的条件概率
- pivot创建:
- 类似[38,39]
- 以一定的百分比(即50%)将每个字符随机替换为表示缺失字符的屏蔽符号。只保留那些包含至少四个可观察字符和至少五个屏蔽符号的生成的主元
- 将密码中的屏蔽比例从15%增加到更大的值(50%)
- 使用Rockyou-2009重新训练CPG模型
评估
实验设置:
- generate 1e7 candidate passwords per evaluation pivot, and classify the evaluation pivots into four classes by the number of passwords satisfying the pivot.
- We use Neopets and Cit0day as evaluation sets due to their large space. CWAE only generates 30 evaluation pivots for each pivot class, possibly inducing bias. We extract a total of 120 evaluation pivots for each class from evaluation sets for robust and convincing results.
评估标准:每个pivot类中120个评估pivot的平均破解率
结果:
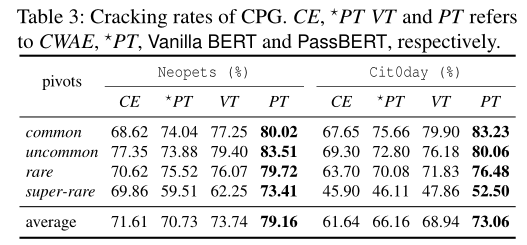
模型以递减的概率穷尽掩码位置中的字符来生成候选密码,CWAE可能存在较多的噪音
PassBERT的生成速度更快,因为一次就能生成所有的密码,而CWAE一次只能生成一个候选密码
TPG
- 训练TPG模型在密码泄露的情况下输出编辑路径
微调
使用序列标记机制[44]。为密码中的每个字符预测一个编辑操作。一个编辑操作序列构成编辑路径。在顺序标记机制中,每个字符位置只能输出一次编辑操作
定义操作:keep、delete、replace1(替换为一个字符)、replace2(替换为两个字符)
一个操作为一个二元组(op,str)。keep、del的str为空,replace1的str为一个字符,replace1的str为两个字符

为了模拟append操作,在密码末尾添加了三个占位符,因为大多数密码不会增加三位以上
限制:无法捕获一些转换
更改分类器,以获得密码中每个字符的编辑操作概率(分类器输出9122维向量)
输入:以p@ssw0rd123为例
- 输入转换为:[CLS] p @ s s w 0 r d 1 2 3 _ _ _ [SEP]
- 模型输出 the top edit path in the form of “[CLS] 1 1 1 1 1 1 1 1 10 1 1 9121 9122 _ [SEP]”, where each numeric value indicates an edit operation (op,str) from 9,122 operations.
- 最后根据token和编辑操作的映射,将该edit path转为实际的密码
以动态规划的方式,获得top 1000的edit path
评估
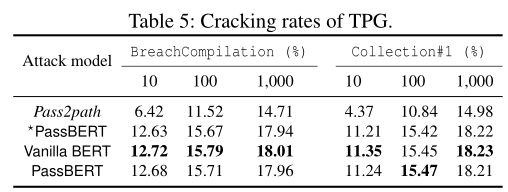
insight:

ARPG
- 字典中的每个单词仅与所选择的自适应混淆规则相关联以生成猜测
微调
攻击设计:
建立一个分类模型来输出一个0-1的连续值来衡量规则对单词的适应性
形式上,给定一个选择的规则集R、一个单词列表集W和一个目标密码集T。对于一个集合$(w_i,R_i)$,$w_i$为一个密码,$R_i$为一个规则列表,其中的$r_j$表明规则$r_j$下$w_i$是否能命中目标密码,列表的长度为规则集的大小
该任务可以被描述为多个二元分类任务

模型微调:
- 两个rule set:Generated和PasswordPro
- T为BreachCompilation,W为000webhost
- $R_i$为label
- 输入$w_i$做字符分词,之后使用$[CLS]$的embedding代表整个密码在分类器上做分类。由于0、1分布不均,采用focal loss来平衡
- 如果一个分类结果大于阈值,则认为可能存在对应规则转换的目标密码
评估
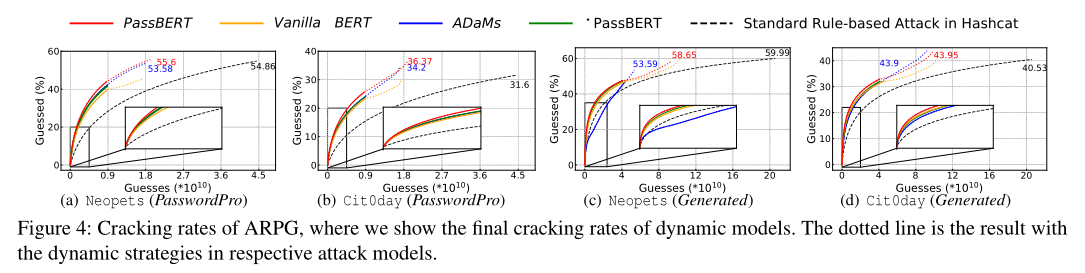
Hybrid Password Strength Meters
- 应用CPG模型来估计单个字符的强度——每次在密码中屏蔽一个字符,并在给定其余密码上下文的情况下估计它们各自的强度
- 使用TPG模型来估计在给定泄漏密码的情况下破解输入密码的猜测次数,并在猜测次数较小时(小于1000次)提醒用户
- 应用反向的ARPG模型来推断基本单词,例如,给定输入密码“p@ssw0rd123”,推断基本单词“p@ssw0rd”。然后通过密码泄露检查[47]检测基本单词是否已经被泄露,如果被泄露,则输入的密码就很容易受到ARPG攻击
- 反向训练:
- 通过“p@ssw0rd”获得用于产生“p@ssw0rd123”的自适应规则
- 将逆规则应用于目标密码以获得基本单词
- 当一些规则(例如,“删除最后一个字符”)由于“附加”的未知字符而不能直接反转时,在推断的单词中使用占位符
- 反向训练:
- 部署:
- 通过tensorflow.js将模型转换为浏览器可用的json格式的模型
- 只在服务器端部署基于python接口的反向ARPG,因为反向ARPG应该与密码泄露检查结合使用
讨论
略
结论
- 提出了一个基于双向Transformer的密码猜测框架
- 提供了一个现成的预训练密码模型,并设计了特定任务的微调方法来定制预训练密码模型,以适应CPG、TPG和ARPG三种特定模型。微调模型的性能分别比SOTA模型提高了14.53%、21.82%和4.86%
- 提出了一个具有亚秒延迟的混合密码强度计

