2021年《Glancing Transformer for Non-Autoregressive Neural Machine Translation》阅读笔记
摘要
- 最近关于非自回归神经机器翻译 (NAT) 的工作旨在通过并行解码提高效率而不牺牲质量
- 然而的NAT方法要么不如Transformer,要么需要多次解码,导致模型速度降低
- 本文提出了Glancing语言模型 (GLM)——学习single-pass并行生成模型的单词相互依赖。 通过GLM,开发用于机器翻译的Glancing Transformer (GLAT)
- 仅通过single-pass并行解码,GLAT 就能够生成具有 8×-15×speedup的高质量翻译
- 在多个WMT语言方向上的实验表明,GLAT优于之前所有的single-pass非自回归方法,几乎可以与Transformer相媲美,差距缩小到0.25-0.9个BLEU点
介绍
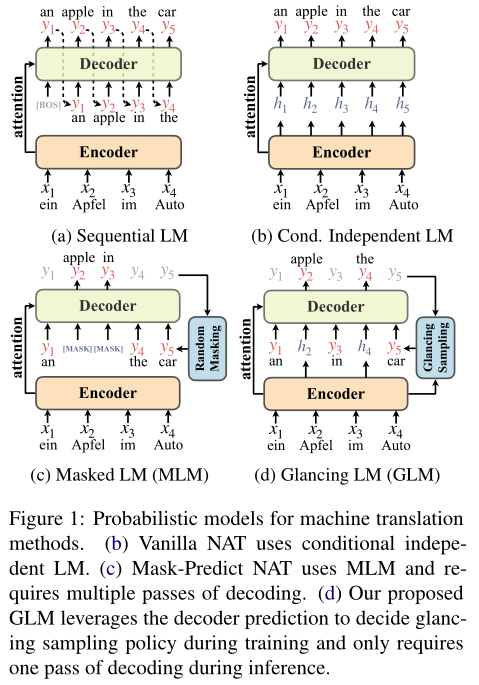
- Transformer一直是机器翻译中使用最广泛的架构,但Transformer的解码效率低下,因为概率模型采用顺序自回归分解(图 1a)
- 非自回归Transformer (NAT) 旨在并行解码目标token以加快生成速度,但vanilla NAT在翻译质量上仍然落后于Transformer;给定源语句,NAT假定目标token的条件独立(图 1b)。本文怀疑NAT的条件独立假设阻止了学习目标句子中的单词相互依赖性,而Transformer通过从左到右的解码明确捕获此依赖性
- 几种补救措施被提出,希望保持并行解码的同时,捕获单词的相互依赖性。共同想法是迭代解码目标token,同时使用掩码语言模型训练每一次解码(图 1c)。这些方法需要多次解码,生成速度明显低于普通NAT,并且使用single-pass生成,很大程度上落后于自回归Transformer
- 以上研究带来一个开放性的问题:完整的并行解码模型是否可以实现与Transformer相当的机器翻译性能——非自回归的,在推理阶段内只进行一次解码
- 本文提出了glancing language model(GLM),一种训练概率序列模型的新方法。 基于GLM,本文开发了glance Transformer (GLAT),仅通过一次解码就实现并行文本生成。它优于以前的NAT方法,在多种情况下实现与Transformer相当的性能
- GLM采用自适应扫视采样策略:
- 如果在GLAT训练过程中参考文本太难,导致无法拟合,它会扫视参考文本的某些片段
- 如果模型调优良好,它会自适应地降低扫视采样的百分比,确保模型可以学习以single-pass方式生成整个句子
- GLM 在两个方面与MLM不同:
- GLM提出了一种自适应扫视采样策略,使GLAT能够以一次迭代的方式生成句子,通过逐步训练而不是迭代推理来工作(见图 1d)
- 为实现自适应扫视采样,GLM在训练中进行两次解码:第一次解码与vanilla NAT相同,预测精度表示当前参考文本是否“难以”拟合;第二次解码,GLM根据第一次解码通过扫视采样得到参考词,并学习预测剩余未采样的词
- 只有第二次解码才会更新模型参数
- GLM没有使用[MASK]标记,直接使用来自编码器在相应位置的表示,这更自然,可以增强采样词和来自编码器的信号之间的交互
- GLM提出了一种自适应扫视采样策略,使GLAT能够以一次迭代的方式生成句子,通过逐步训练而不是迭代推理来工作(见图 1d)
- GLM采用自适应扫视采样策略:
- 实验结果表明:
- 与普通NAT相比,GLAT在baseline上获得显着的改进而不会损失推理速度
- GLAT与Mask-Predict等迭代方法相比取得了有竞争力的结果
- 与AT相比,GLAT将性能差距缩小在0.9BLEU点内
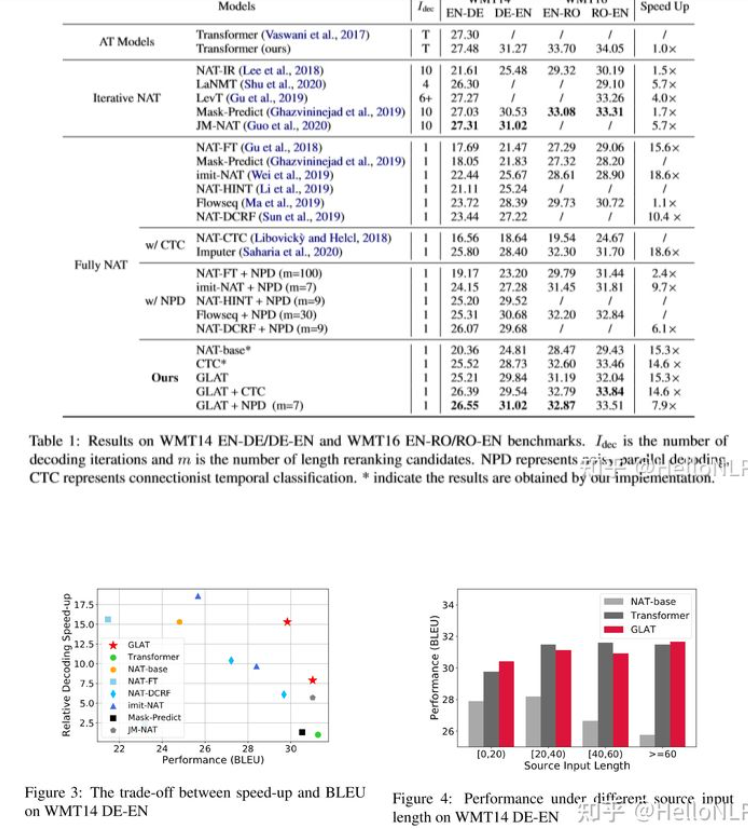
- 发现当WMT14 DE-EN上的参考长度小于20时,GLAT的性能优于AT——推测因为GLM可以捕获双向上下文来生成文本,而从左到右的模型只是单向的
机器翻译的概率模型
一个机器翻译任务正式定义为一个seq-to-seq的生成问题:给定源句$X={x_1,…,x_N}$,由条件概率$P(Y|X;\theta)$($\theta$为网络参数)生成目标句$Y={y_1,…y_T}$,不同方法以不同方式分解条件概率
Transformer:使用自回归分解来最大化以下似然
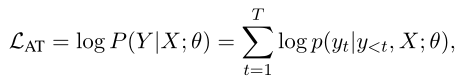
- 其中:$y_{<t}={[BOS],y_1,…,y_{t-1}}$
- AT训练中,在目标token上从左到右单向学习词间依赖,推理过程中,前一个预测的token被送入解码器以生成下一个token
vanilla NAT:由与Transformer相同的编码器和具有多头注意力层的并行解码器组成
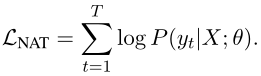
- 训练阶段,对目标句子使用条件独立分解,其对数似然为全对数似然$logP(Y|X;\theta)$的近似
- 推理阶段,编码器的表示被复制为解码器的输入,并行生成目标端的所有token——条件独立性假设一般不成立,因此NAT性能较差
多通道迭代解码
Multi-pass iterative decoding:Mask-Predict扩展了vanilla NAT,仍然使用条件独立因子分解,但使用随机掩码方案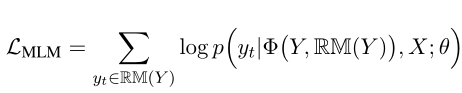
- 其中,$RM(Y)$为从$Y$中随机选择的词集合,$\phi()$用[MASK]替换Y中选定的token,例如$RM(Y)={y_2,y_3}$,$\phi(Y,RM(Y))={y_1,[MASK],[MASK],y_4,y_5}$
- 训练目标是学习一个模型$\theta$,该模型预测给定源句X和前一次迭代中生成的单词的掩码token
vanilla NAT打破了词的相互依赖性,MLM需要多次解码才能重新建立词的相互依赖性
Glancing Transformer
- GLAT相比vanilla NAT在于,通过GLM显式鼓励词间依赖的学习;相比使用MLM的迭代NAT在于,被训练用于single-pass并行解码
GLM(Glancing Language Model)
模型以最大化下式为目标:
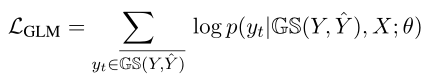
- 其中,$\hat{Y}$为初始的预测token;$GS(Y,\hat{Y})$为tokens的子集(经过glancing采样策略没有选中的tokens集合),glancing采样策略通过比较初始预测与真实token,从目标句子中选择这些词,如果网络的初始预测不太准确,则会选择更多token并馈送到解码器输入中,$GS(Y,\hat{Y})$是在目标Y中但未被选中的剩余token集合,训练损失根据这些剩余的tokens计算
GLAT使用与Transformer类似的编码器-解码器架构,编码器$f_{enc}$使用相同的多头注意力层,解码器$f_{dec}$包括多层多头注意,每一层关注编码器的表示与来自上一层解码器的输出
初始预测期间,解码器的输入$H={h_1,…,h_T}$使用软复制(
uniform copy or soft copy)复制编码器的输出,预测初始的tokens($\hat{Y}$)时使用argmax解码下式: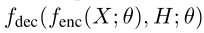
为计算损失$L_{GLM}$,需要对比初始预测和真实结果,以选择目标句子中的tokens(即$GS(Y,\hat{Y})$),使用相应的目标词嵌入替换$H$中的采样索引,此时$H’$为:
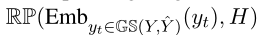
- 其中,$RP$示对相应的索引进行替换——如果对目标中的一个token进行了采样,则其词嵌入替换相应的h
- 词嵌入从解码器的softmax嵌入矩阵中获得
更新后的$H’$再次送入解码器以计算输出token概率,具体而言,此时剩余tokens的输出概率:
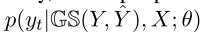
由
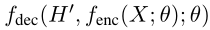
计算
Glancing采样策略
GLM需要从目标句子中,自适应地选择部分tokens。 这些选定的token提供了来自真实目标的“正确”信息,有助于训练解码器来预测其余的未选择token,因此直观上,该采样策略引导模型首先学习片段的生成,然后逐渐转向整个句子的生成
glancing采样策略在训练开始时选择许多单词,此时模型还没有很好地优化。 随着模型逐渐变得更好,采样策略将采样更少的单词,使模型能够学习整个句子的并行生成
glancing采样分为两个步骤:
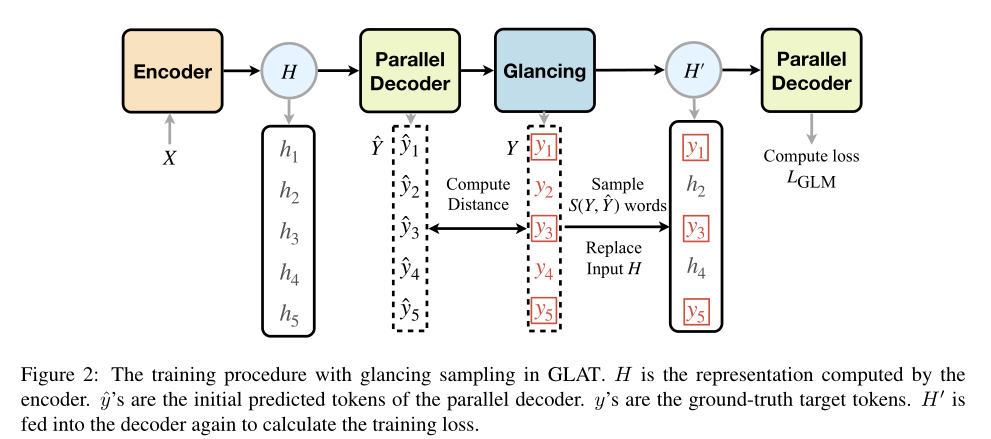
首先决定采样数S,从目标句子中随机选择S个单词,训练不佳时S会更大,并随训练过程减少——给定输入$X$,预测句子$\hat{Y}$,目标句子$Y$,glancing采样目的是获得一个从$Y$采样的词集合
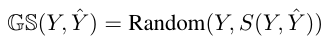
本文通过比较$Y$和$\hat{Y}$的差异,计算S(本文使用汉明距离,若两个句子不一样长,则可使用编辑距离):$S(Y,\hat{Y})=\lambda \cdot d(Y,\hat{Y})$,其中采样比例$\lambda$为超参数
推理
- GLAT只修改训练过程,推理过程是完全并行的,并且是single-pass
- 需要在解码之前决定输出长度,一种简单方法是使用编码器的表示来预测长度
- GLAT中长度预测按照Ghazvininejad et al. (2019) 的方法实现的: 将额外的[LENGTH] token添加到源输入,并使用[LENGTH] token的编码器输出来预测长度
- 本文还使用两种更复杂的方法来更好地确定输出长度:noisy parallel decoding (NPD) 和connectionist temporal classification (CTC)
- NPD (Gu et al., 2018) 首先预测m个目标长度候选,为每个目标长度候选生成argmax解码的输出序列。使用预训练的Transformer对序列进行排序,将最佳整体输出确定为最终输出
- CTC (Graves et al., 2006) 和 Libovicky` and Helcl (2018) 一样,将最大输出长度设置为源输入长度的两倍,并在生成后去除空白和重复token
实验
实验设置
- 在三个baseline上实验:WMT14EN-DE(4.5M翻译对)、WMT16EN-RO(610k翻译对)和IWSLT16DE-EN(150K翻译对)
- 遵循Vaswani等人(2017)中的描述,对WMT14EN-DE进行预处理‘;使用Lee等人(2018)中提供的WMT16EN-RO和IWSLT16DE-EN处理数据
- 对处理后的数据集,使用Vaswani等人(2017)的Transformer进行序列级知识蒸馏
- 5层编码和解码;$d_{model}$为256;dropout为0.1;优化器为adam,参数(0.9,0.999);WMT数据集的学习率,前4k步为5e-4,之后根据inverse square root schedule(VasWani等人,2017)逐步减少,IWSLT数据集的学习率,从3e-4到1e-5线性退火(同Lee等人,2018);$\lambda$为0.5到0.3的线性退火,或者为0.5的固定值
主要结果
- 主要结果如下,说明略
相关工作
- NAT
- NAT中引入CRF推理模块
- 迭代精炼,用多遍迭代解码,提高输出的效果
总结
- 为改善single-pass并行生成模型的性能,本文提出GLAT
- 实验结果表明,该方法能显著提高single-pass并行生成非自回归机器翻译的性能。相对于自回归模型,Glancing Transformer(GLAT)具有与之媲美的性能

